顾及地理空间分布的文本情感分类方法及装置
1.本发明涉及文本情感分析领域,具体涉及一种顾及地理空间分布的文本情感分类方法及装置。
背景技术:
2.情感分析也称为意见挖掘,是自然语言处理的经典任务,也是文本分类的任务之一。其目的是分析人们对于诸如时事、个人、商品、服务、组织等实体及其属性的情感类别或情感倾向。其在舆论检测,舆情分析,电影评论分析等领域有着广泛的应用。
3.由于情感分析在日常业务中的重要性,近年来涌现了大量有关情感分析的工作。其中图神经网络因为其在文本分类领域的高效而被广泛关注。例如gcn等一系列使用图神经网络进行文本分类的工作,都取得了较为理想的效果。但这些工作均只从文本语义以及词频的角度去考虑,采用语法依赖,外部知识补充,知识图谱等方式进行文本分类以提高性能。而忽略了文本本身地理空间分布特征的隐含信息。地理第一定律指出:“任何事物都是与其他事物相关的,只不过相近的事物关联更紧密“。例如餐厅评论文本,旅游景点推荐文本等,除了文本自身内容所蕴含的信息外,文本的位置信息也是值得关注的。
4.因此,传统的文本分类方法忽略了文本本身地理空间分布特征的隐含信息是亟待解决的技术问题。
技术实现要素:
5.为了解决传统文本分类方法忽略了文本本身地理空间分布特征的隐含信息的技术问题,本发明创新性地引入地理空间位置关系来建模文本与文本之间的信息,可以更加深入地捕获文本间的相似性,从而能够更好的对文本的情感进行分析预测。
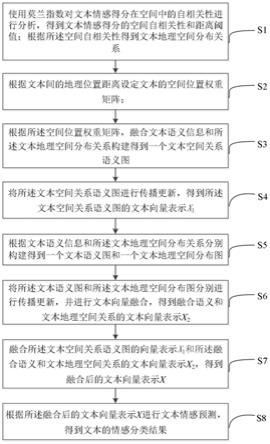
6.为了实现上述目的,本发明提供了一种顾及地理空间分布的文本情感分类方法,包括以下步骤:
7.根据文本间的地理位置距离设定文本的空间位置权重矩阵;
8.根据所述空间位置权重矩阵,融合文本语义信息和文本地理空间分布关系构建得到一个文本空间关系语义图;
9.将所述文本空间关系语义图进行传播更新,得到所述文本空间关系语义图的文本向量表示x1;
10.根据文本语义信息和文本地理空间分布关系分别构建得到一个文本语义图和一个文本地理空间分布图;
11.将所述文本语义图和所述文本地理空间分布图分别进行传播更新,并进行文本向量融合,得到融合语义与文本地理空间关系的文本向量表示x2;
12.将所述文本空间关系语义图的向量表示x1和所述融合语义与文本地理空间关系的文本向量表示x2进行融合,得到融合后的文本向量表示x;
13.根据所述融合后的文本向量表示x进行文本情感预测,得到文本的情感分类结果。
14.优选地,在所述根据文本间的地理位置距离设定文本的空间位置权重矩阵的步骤之前,还包括:
15.使用莫兰指数对文本情感得分在空间中的自相关性进行分析,得到文本情感得分的空间自相关性和距离阈值d
τ
;
16.根据所述空间自相关性得到文本地理空间分布关系。
17.优选地,所述使用莫兰指数对文本情感得分在空间中的自相关性进行分析,得到文本情感得分的空间自相关性和距离阈值d
τ
的步骤,包括:
18.将文本的情感得分作为莫兰指数的属性值a;
19.根据文本的经纬度坐标计算得到的文本间的空间距离;
20.将所述空间距离的倒数的平方作为莫兰指数的空间权重矩阵w
ij
;
21.根据莫兰指数计算公式计算得到文本情感得分的空间自相关性,以及距离阈值d
τ
;
22.所述莫兰指数计算公式为:
[0023][0024]
其中,i为莫兰指数值,其取值通常在[
‑
1,1]之间,越接近于1表示文本情感得分在空间上分布越聚集,即相关性越强;下标i与j表示的是第i个与第j个文本;表示属性值a的平均值;u表示文本集合;n表示文本的总数。
[0025]
优选地,所述根据文本间的地理位置距离设定文本的空间位置权重矩阵的步骤,包括:
[0026]
由文本的经纬度坐标计算文本间的空间距离;
[0027]
将所述空间距离的倒数进行归一化处理,作为文本间的空间位置权重矩阵。
[0028]
优选地,所述根据空间位置权重矩阵,融合文本语义信息和文本地理空间分布关系构建得到一个文本空间关系语义图的步骤,包括:
[0029]
统计单词与单词之间的共现情况,用tf
‑
idf计算结果作为边e
ww
的权重;
[0030]
统计单词与文本之间的共现情况,用pmi计算结果作为边e
wd
的权重;
[0031]
统计文本与文本之间的地理距离,若小于所述距离阈值d
τ
,则建立边e
dd
,并用空间位置权重矩阵作为边e
dd
的权重,否则不建立边,最终得到一个文本空间关系语义图。
[0032]
优选地,所述将文本空间关系语义图进行传播更新,得到所述文本空间关系语义图的文本向量表示x1的步骤,包括:
[0033]
分别设置所述文本空间关系语义图的参数矩阵w1,w2,w3,由于构建的为异构图,所有参数矩阵相互独立,且邻接矩阵分别为a1,a2,a3;
[0034]
其中,a1表示由单词之间的共现关系构建的邻接矩阵,a2表示单词与文本之间共现关系构成的邻接矩阵,a3为由地理空间分布关系构建的邻接矩阵,取值范围为[0,1],由经纬度坐标距离计算结果的倒数归一化得到;
[0035]
将所述文本空间关系语义图进行传播更新,根据公式得到每个节点更新后的向量表示x1;
[0036]
其中,表示第l层第i种类型关系下的向量表示,表示第i种类型关系下的归一
化后的邻接矩阵,w
i
表示第i个参数矩阵。
[0037]
优选地,所述根据文本语义信息和所述文本地理空间分布关系分别构建得到一个文本语义图和一个文本地理空间分布图的步骤,包括:
[0038]
根据单词,文本两类节点中的词共现关系和文本词频关系,构建一个文本语义图;
[0039]
文本作为唯一节点,文本与文本之间根据地理空间分布关系建立边:首先计算文本与文本之间的经纬度坐标的距离,若大于所述距离阈值d
τ
,则在文本与文本之间建立边,并将所述空间位置权重矩阵作为边权重;若小于距离阈值d
τ
,则不建立边;
[0040]
最终构建一个同构无向的文本地理空间分布图。
[0041]
优选地,所述将文本语义图和所述文本地理空间分布图分别进行传播更新,并进行文本向量融合,得到融合语义与文本地理空间关系的文本向量表示x2的步骤,包括:
[0042]
将所述文本语义图进行节点更新,得到文本语义图的文本向量表示;
[0043]
文本地理空间分布图将所述空间位置权重矩阵作为邻接矩阵a的值,通过图卷积算法进行节点更新,得到文本地理空间分布图的文本节点向量表示;
[0044]
将所述文本语义图的文本向量表示和所述文本地理空间分布图的文本节点向量表示,得到融合语义与文本地理空间关系的文本向量表示x2。
[0045]
此外,为了实现上述目的,本发明还提供了一种顾及地理空间分布的文本情感分类装置,包括以下模块:
[0046]
设定模块,用于根据文本间的地理位置距离设定文本的空间位置权重矩阵;
[0047]
构建模块,用于根据所述空间位置权重矩阵,融合文本语义信息和文本地理空间分布关系构建得到一个文本空间关系语义图;
[0048]
向量表示模块,用于将所述文本空间关系语义图进行传播更新,得到所述文本空间关系语义图的文本向量表示x1;
[0049]
所述构建模块,还用于根据文本语义信息和文本地理空间分布关系分别构建得到一个文本语义图和一个文本地理空间分布图;
[0050]
所述向量表示模块,还用于将所述文本语义图和所述文本地理空间分布图分别进行传播更新,分别得到所述文本语义图和所述文本地理空间分布的文本向量表示;
[0051]
融合模块,用于将所述文本语义图和所述文本地理空间分布的文本向量表示进行融合,得到融合语义和文本地理空间关系的文本向量表示x2;还用于融合所述文本空间关系语义图的向量表示x1和所述融合语义和文本地理空间关系的文本向量表示x2,得到融合后的文本向量表示x;
[0052]
预测分类模块,用于根据所述融合后的文本向量表示x进行文本情感预测,得到文本的情感分类结果。
[0053]
优选地,所述文本情感分类装置还包括:
[0054]
分析模块,用于使用莫兰指数对文本情感得分在空间中的自相关性进行分析,得到文本情感得分的空间自相关性和距离阈值d
τ
,并根据所述空间自相关性得到文本地理空间分布关系。
[0055]
本发明提供的技术方案所带来的有益效果是:
[0056]
本发明创新性地引入地理空间位置关系来建模文本与文本之间的信息,可以更加深入地捕获文本间的相似性,从而能够更好的对文本的情感进行分析预测,卷积神经网络
采用的数据量为161916,预测精确度为40.5%,本发明方法采用的数据量为10000,预测精确度为63.9%,实验数据验证了本发明相对于传统情感分类方法,在使用更少的数据量的情况下依然能够得到更好的效果。
附图说明
[0057]
下面将结合附图及实施例对本发明作进一步说明,附图中:
[0058]
图1是本发明一种顾及地理空间分布的文本情感分类方法的执行流程图;
[0059]
图2是本发明一种顾及地理空间分布的文本情感分类装置的结构图;
[0060]
图3是本发明向量空间分布图。
具体实施方式
[0061]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
[0062]
参考图1,图1是本发明一种顾及地理空间分布的文本情感分类方法的执行流程图;本实施例中,一种顾及地理空间分布的文本情感分类方法包括以下步骤:
[0063]
s1、使用莫兰指数对文本情感得分在空间中的自相关性进行分析,得到文本情感得分的空间自相关性和距离阈值d
τ
;根据所述空间自相关性得到文本地理空间分布关系;
[0064]
s2、根据文本间的地理位置距离设定文本的空间位置权重矩阵;
[0065]
s3、根据所述空间位置权重矩阵,融合文本语义信息和所述文本地理空间分布关系构建得到一个文本空间关系语义图;
[0066]
s4、将所述文本空间关系语义图进行传播更新,得到所述文本空间关系语义图的文本向量表示x1x1;
[0067]
s5、根据文本语义信息和所述文本地理空间分布关系分别构建得到一个文本语义图和一个文本地理空间分布图;
[0068]
s6、将所述文本语义图和所述文本地理空间分布图分别进行传播更新,并进行文本向量融合,得到融合语义与文本地理空间关系的文本向量表示x2;
[0069]
s7、将所述文本空间关系语义图的向量表示x1和所述融合语义与文本地理空间关系的文本向量表示x2进行融合,得到融合后的文本向量表示x;
[0070]
s8、根据所述融合后的文本向量表示x进行文本情感预测,得到文本的情感分类结果。
[0071]
在本实施例中,s1具体包括:
[0072]
s11、将文本的情感得分作为莫兰指数的属性值a;
[0073]
s12、根据文本的经纬度坐标计算得到的文本间的空间距离;
[0074]
s13、将所述空间距离的倒数的平方作为莫兰指数的空间权重矩阵w
ij
;
[0075]
s14、根据莫兰指数计算公式计算得到文本情感得分的空间自相关性,以及距离阈值d
τ
;具体地,s14中,所述莫兰指数计算公式为:
[0076][0077]
其中,i为莫兰指数值,其取值通常在[
‑
1,1]之间,越接近于1表示文本情感得分在
空间上分布越聚集,即相关性越强;下标i与j表示的是第i个与第j个文本;表示属性值a的平均值;u表示文本集合;n表示文本的总数。
[0078]
在本实施例中,s2具体包括:
[0079]
s21、由文本的经纬度坐标计算文本间的空间距离;
[0080]
s22、将所述空间距离的倒数进行归一化处理,作为文本间的空间位置权重矩阵。
[0081]
在本实施例中,s3具体包括:
[0082]
s31、统计单词与单词之间的共现情况,用tf
‑
idf计算结果作为边e
ww
的权重;
[0083]
s32、统计单词与文本之间的共现情况,用pmi计算结果作为边e
wd
的权重;
[0084]
s33、统计文本与文本之间的地理距离,若小于所述距离阈值d
τ
,则建立边e
dd
,并用空间位置权重矩阵作为边e
dd
的权重,否则不建立边,最终得到一个文本空间关系语义图。
[0085]
在本实施例中,s4具体包括:
[0086]
s41、分别设置所述文本空间关系语义图的参数矩阵w1,w2,w3,由于构建的为异构图,所有参数矩阵相互独立,且邻接矩阵分别为a1,a2,a3;
[0087]
其中,a1表示由单词之间的共现关系构建的邻接矩阵,a2表示单词与文本之间共现关系构成的邻接矩阵,a3为由地理空间分布关系构建的邻接矩阵,取值范围为[0,1],由经纬度坐标距离计算结果的倒数归一化得到;
[0088]
s42、将所述文本空间关系语义图进行传播更新,根据公式得到每个节点更新后的向量表示x1;
[0089]
其中,表示第l层第i种类型关系下的向量表示,表示第i种类型关系下的归一化后的邻接矩阵,w
i
表示第i个参数矩阵。
[0090]
在本实实施例中,s5具体包括:
[0091]
s51、根据单词,文本两类节点中的词共现关系和文本词频关系,构建一个文本语义图;
[0092]
s52、文本作为唯一节点,文本与文本之间根据地理空间分布关系建立边:具体地,首先计算文本与文本之间的经纬度坐标的距离,若大于所述距离阈值d
τ
,则在文本与文本之间建立边,并将所述空间位置权重矩阵作为边权重;若小于距离阈值d
τ
,则不建立边;
[0093]
s53、最终构建一个同构无向的文本地理空间分布图。
[0094]
在本实施例中,s6具体包括:
[0095]
s61、将所述文本语义图进行节点更新,得到文本语义图的文本向量表示;
[0096]
s62、文本地理空间分布图将所述空间位置权重矩阵作为邻接矩阵a的值,通过图卷积算法进行节点更新,得到文本地理空间分布图的文本节点向量表示;
[0097]
s63、将所述文本语义图的文本向量表示和所述文本地理空间分布图的文本节点向量表示,得到融合语义与文本地理空间关系的文本向量表示x2。
[0098]
此外,为了实施上述的一种顾及地理空间分布的文本情感分类方法,本实施还提供了一种顾及地理空间分布的文本情感分类装置。
[0099]
参考图2,本实施例一种顾及地理空间分布的文本情感分类装置包括以下模块:
[0100]
分析模块1,用于使用莫兰指数对文本情感得分在空间中的自相关性进行分析,得到文本情感得分的空间自相关性和距离阈值d
τ
,并根据所述空间自相关性得到文本地理空
间分布关系;
[0101]
设定模块2,用于根据文本间的地理位置距离设定文本的空间位置权重矩阵;
[0102]
构建模块3,用于根据所述空间位置权重矩阵,融合文本语义信息和所述文本地理空间分布关系构建得到一个文本空间关系语义图;
[0103]
向量表示模块4,用于将所述文本空间关系语义图进行传播更新,得到所述文本空间关系语义图的文本向量表示x1;
[0104]
所述构建模块3,还用于根据文本语义信息和所述文本地理空间分布关系分别构建得到一个文本语义图和一个文本地理空间分布图;
[0105]
所述向量表示模块4,还用于将所述文本语义图和所述文本地理空间分布图分别进行传播更新,分别得到所述文本语义图和所述文本地理空间分布的文本向量表示;
[0106]
融合模块5,用于将所述文本语义图和所述文本地理空间分布的文本向量表示进行融合,得到融合语义与文本地理空间关系的文本向量表示x2;还用于将所述文本空间关系语义图的向量表示x1和所述融合语义与文本地理空间关系的文本向量表示x2进行融合,得到融合后的文本向量表示x;
[0107]
预测分类模块6,用于根据所述融合后的文本向量表示x进行文本情感预测,得到文本的情感分类结果。
[0108]
为了证明本发明技术方案的有益效果,在本实施例中,进行了相关实验验证。
[0109]
参考图3,图3为本发明向量空间分布图,图3展示了通过本发明方法得到的向量表示在二维向量空间下的分布特征,图中灰色和黑色分别表示两种不同的情感极性。可以看到,经过该方法得到的向量能够很好的区分出不同的情感极性。灰色节点相对集中在左半部,而黑色节点相对集中在右半部。
[0110]
此外,本实施例还将本发明所用方法与传统方法进行了对比实验,对比实验结果如表1所示。本实验选择的参考方法为卷积神经网络(cnn),是深度学习中十分经典的模型,在深度学习各领域都有着极佳的表现。本实验采用的数据为yelp数据,该数据是美国的一个大众点评数据,主要为对一些餐饮和娱乐设施服务的点评打分,为英文数据集。该数据因为是口语化的评论所以分析难度相对较大,因此传统方法效果都欠佳。本发明所采用的方法在使用更少的数据量的情况下能够得到更好的效果,证明了本发明的实际效益。
[0111]
表1对比实验结果
[0112]
方法数据量精确度卷积神经网络(cnn)16191640.5%本发明所用方法1000063.9%
[0113]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0114]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
[0115]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1