知识驱动下的兵棋推演智能决策方法
intelligent decision based on a priori knowledge and dqn algorithms in wargame environment[j].electronics,2020,09(10):1
‑
21.
[0011]
4.彭希璐,王记坤,张昶,刘莹,刘改宁.面向智能决策的兵棋推演技术[c].2019第七届中国指挥控制大会,2019.
[0012]
5.田忠良,刘昊.智能算法在兵棋对抗推演中的应用[j].指挥控制与仿真,2021,43(1):40
‑
47.
技术实现要素:
[0013]
在兵棋推演中,智能体取得最优解往往存在诸多困难,因此,针对时间有限、任务目标固定的特定情景,为了快速高效完成兵棋推演智能决策任务,本发明提出了一套知识驱动下的兵棋推演智能决策框架,通过结合推演领域知识,并综合运用多种智能决策技术,完成能在指定想定下表现优异的智能体。为在时限任务中,针对具体想定实现智能体,本发明提出了一个知识驱动下的兵棋推演智能决策框架,将任务拆分成多个核心模块,结合战场知识并结合多种智能算法,实现指定任务下智能体效能的快速提升。对抗双方包括甲方和乙方,其中甲方为我方,乙方为对抗方。
[0014]
本发明公开的知识驱动下的兵棋推演智能决策方法,包括以下步骤:
[0015]
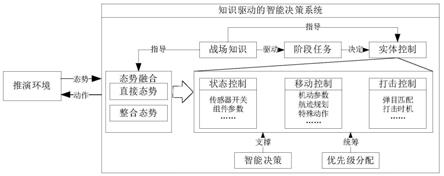
知识驱动下的兵棋推演智能决策框架如图1所示,该框架由智能决策系统与推演环境两部分组成。推演环境是兵棋推演的引擎,能够独立进行仿真推演,间隔仿真步长向智能决策系统传递态势信息,并从智能决策系统中接收新的动作指令;智能决策系统从环境中接收并处理态势信息,通过结合战场知识驱动每个阶段的任务进程,从而确定每个实体在阶段任务中的地位,此外,战场知识可以直接指导对抗实体在面对特殊情况下的控制方式,在多种智能决策技术的支撑和优先级分配机制的统筹管理下,返回当前状态下的执行动作。态势融合模块将直接态势和整合态势进行融合后,将融合后态势信息输入实体控制模块。实体控制模块包括状态控制,移动控制和打击控制。其中状态控制包括传感器开关,组件参数等,移动控制包括机动参数,航迹规划,特殊动作等,打击控制包括弹目匹配,打击时机等。知识驱动的智能决策系统将战场知识用于指导态势融合,并驱动阶段任务和指导实体控制模块。阶段任务模块中采用智能决策用于决定实体控制中的各模块。
[0016]
本发明。
附图说明
[0017]
图1本发明的知识驱动下的兵棋推演智能决策框架;
[0018]
图2本发明的态势融合分类;
[0019]
图3本发明的任务阶段转换;
[0020]
图4本发明的智能决策分类;
[0021]
图5本发明的推演想定示意图;
[0022]
图6本发明的态势融合;
[0023]
图7本发明的任务阶段转换;
[0024]
图8本发明的推演任务阶段转换;
[0025]
图9本发明的避弹场景示意图;
[0026]
图10本发明的水平航向角划分。
具体实施方式
[0027]
下面结合附图对本发明作进一步的说明,但不以任何方式对本发明加以限制,基于本发明教导所作的任何变换或替换,均属于本发明的保护范围。
[0028]
态势融合
[0029]
如图2所示,态势融合包括对直接态势的处理和对态势环境的整合。本实施例中,直接态势的处理包括对态势的数值转换、数值清洗和归一化等。数值转换是对数据单位的变换,比如角度与弧度、时速与秒速等,从而实现相关变量数值上的统一;数值清洗是针对非确定场景下的数据处理方式,在此情境下,甲方获取的敌方信息通常是模糊和不确定的,因此在采用情报前,本发明一方面结合知识和学习方法对该数据的真实性进行检测和甄别,另一方面补充缺失实体的信息,从而降低对系统决策的影响;归一化用于后接机器学习任务时,提前对数据的数值、维度进行规约,从而使得数据分布使用与机器学习任务,本实施例中使用的归一化方法包括最小
‑
最大归一化、z分数归一化和小数定标归一化等。态势环境的整合是针对系统中各模块需求在直接态势基础上二次整理的态势信息,比如对乙方意图的研判等。
[0030]
战场知识
[0031]
战场知识是基于人类经验的对抗规律和经验的整合,是专家经验在对抗领域的一种表现形式。专家经验被普遍应用于规划、工业实践和医学等领域,用于指导具体应用和实践。在面向任务的兵棋推演下,虽然推演规模大小不一,但是推演场景是相对固定的,在这种情况下,直接使用纯粹强化学习的方法进行训练,虽然在经过长期的参数调整和训练后甚至会发现人类未曾发现的新策略和战法,但是这种方式通常在时间和计算资源上耗费极大,且效果通常会不显著,因此,对推演任务进行拆解和阶段划分,将全局学习转化成阶段学习和小场景学习是一种可行的替代方案,这个过程需要战场知识。战场知识包含了对推演有意义的各种人类经验和统计规律,比如击毁特定目标需要的弹药数量、乙方目前布局可能存在的意图、特定想定下乙方的薄弱环节等。在知识驱动的智能决策系统中,战场知识存在于方方面面:战场知识指导态势融合,对整合态势进行归纳并给出结论;战场知识驱动阶段任务的推进,进而决定实体控制;此外,战场知识直接对实体控制进行指导和修正。
[0032]
阶段任务
[0033]
阶段任务是根据战场知识对推演节点进行的初步划分,在不同的阶段,受控实体的任务和状态会有差异,任务差异主要体现在目标点上,状态差异体现在状态参数上。阶段任务是该阶段相应实体执行的常态任务,在触发特殊事件时,允许实体任务和状态的改变,但是在特殊事件处理完毕后,会返回该任务状态,如图3所示,任务阶段a和任务阶段b互相转换,任务阶段b和触发事件互相转换。此外,不同的任务阶段之间存在状态转换,也允许循环转换的存在,如任务阶段a转换到任务阶段b,又从任务阶段b转换回任务阶段a。
[0034]
实体控制
[0035]
实体控制智能决策系统是在智能决策算法支持下,在优先级分配统筹下,通过战场知识指导的对抗单元控制。
[0036]
实体控制包括状态控制、移动控制和打击控制等。状态控制包括对传感器开关控
制和组件参数调节,传感器开关控制包括敌我识别开关、通信开关等,组件参数的调节包括通信频谱调节等;移动控制是特指对可移动实体的控制,包括机动参数控制(速度、航向等)、航迹规划和特殊动作(如规避返航动作);打击控制是与目标打击相关的控制,包括弹目匹配、打击时机选择等。
[0037]
状态控制以战场知识控制为主导,移动控制和打击控制通常是在智能决策和战场知识共同指导下实现。
[0038]
智能决策
[0039]
智能决策是各种智能算法组成的算法库,用以支持智能决策系统的各种规划,本实施例采用的算法包括强化学习算法、现代优化算法、运筹学方法等,见图4。强化学习算法包括无模型和基于模型的方法等,智能优化方法包括遗传算法,蚁群算法等,运筹学方法包括规划论方法等。
[0040]
强化学习的智能体随着时间变化同环境进行逐步交互,在每个时间步t,智能体从状态空间s中接收该时刻的状态st,根据策略分布π(a
t
|s
t
),从动作空间a中选择该时刻的执行动作a
t
,之后根据环境的动态性(奖赏函数r(s
t
,a
t
,s
t+1
)和状态转移函数p(s
t+1
|s
t
,a
t
)),环境返回一个奖赏值r
t+1
,并将状态转移到下一时刻s
t+1
。每次实验中直到终止状态智能体获得带折扣的累计奖赏值γ∈(0,1]。该智能体学习的目标是最大化返回期望值。在决策系统中,强化学习负责完成决策任务中专家经验不足的小场景任务。
[0041]
智能优化方法包括各种启发式优化算法,和运筹学算法结合,可以用于解决通用性问题。在智能决策系统中,特定目标的路径规划和避障、弹目匹配等问题可以由这些算法解决。
[0042]
优先级分配
[0043]
优先级分配是对决策系统各模块给出指令的统一安排和调度。在许多推演平台中,受控制体在同一时刻可接并执行多个状态控制指令,但是只能执行一条移动控制或者打击控制指令,这是和受控实体本身的特性相关的。在此情况下,当战场知识、阶段任务和智能决策模块对统一实体下达指令时,部分指令可能会存在冲突和冗余。因此,在系统内部确立固定的优先级顺序,可以保证整个系统输出动作的合理有效。
[0044]
实施例1
[0045]
本实施例以某兵棋推演赛事为案例,介绍本发明在兵棋推演中的具体应用形式。
[0046]
推演想定介绍
[0047]
推演想定图如图5所示,甲方目标(防守方):依托地面、海面和空中立体防空火力,守卫己方岛屿2个指挥所重点目标。
[0048]
乙方目标(进攻方):综合运用海空突击和支援保障力量,突破甲方防空体系,摧毁甲方2个指挥所重点目标。
[0049]
乙方设置6种装备共42个对抗单位,以完成突击、预警、侦察、干扰、护航等任务。甲方设置7种装备共30个对抗单位,以完成侦察、预警、防空、地面防卫等任务,同时为甲方配置态势感知装备和对地打击装备,可对乙方机场实施突击,威慑乙方难以投入全部装备进行进攻,增加防守胜率。
[0050]
表1乙方装备设置
[0051]
任务装备数量初始位置空中突击对地打击装备16架机场空海探测态势感知装备1架岛屿附近干扰压制干扰机1架机场掩护护航攻击装备20架机场舰艇防空舰艇2艘岛屿附近对空探测地面雷达1部乙方岛屿支援保障机场1个乙方岛屿
[0052]
表2甲方装备设置
[0053]
任务装备数量初始位置空中突击对地打击装备8架南岛机场空海探测态势感知装备1架南岛附近对空探测地面雷达2部每岛1部空中拦截攻击装备12架南岛机场舰艇防空舰艇1艘北岛附近地面防空防空装备3部北岛1,南岛2支援保障机场1个南岛保卫目标指挥所2个每岛1个
[0054]
想定分析
[0055]
本发明从乙方角度进行场景分析,并结合本发明智能推演框架整理相关模块和目标。
[0056]
在该想定场景中,乙方拥有干扰机,能够有效掩护我方战机靠近敌方目标,是该任务中的打击核心。因此,乙方只有在干扰机协同配合下,才能在面对甲方大量地防和海防时拥有情报优势,此外,态势感知装备作为主要的态势感知实体,是情报获取核心,在乙方前探进攻时,务必保护态势感知装备的生存。乙方的任务阶段划分应该以干扰机和态势感知装备态势为牵引,攻击装备、对地对地打击装备和海防单位为两个核心单元完成使命服务。
[0057]
1)态势融合
[0058]
在本想定中,乙方的态势融合内容见图6,直接态势包括甲方和乙方实体的探测信息,如批号,速度,坐标,航向,类型,军别和弹量等,该信息已经经过清洗整理,并提供归一化后数据供智能决策模块使用。整合态势是结合战场知识得到的统计信息,在本想定中,乙方核心关注:1)根据观测到甲方实体分布推测甲方的防御重点在南岛或北岛;2)根据甲方飞机位置判断甲方是否有偷袭我方机场能力;3)根据统计到的打击信息和实体变更信息,统计敌方剩余对空和对地打击能力。
[0059]
2)阶段任务划分
[0060]
根据前文对想定的理解,干扰机和态势感知装备是乙方的两个核心目标,因此,阶段划分以干扰机任务进程和态势感知装备有无为核心进行划分。乙方任务阶段划分如图7所示,对每个任务状态还可以细化为虚线框中的次级任务。在每个不同的任务阶段,实体控制的具体参数有区别,比如在前往目标点任务阶段中,任务实体集群以最大速度前往目标点,转换为抵达目标点状态后,受控实体降低速度,以减少在目标点徘徊的转弯半径。图7
中,乙方实体任务开始后,进入“态势感知装备存活且两个指挥所均存在”阶段,“态势感知装备存活且两个指挥所均存在”阶段还可分为“单元集结”、“前往目标点”和“抵达目标点”三个次级任务,“态势感知装备存活且两个指挥所均存在”阶段可进入“态势感知装备存活且只剩一个指挥所”和“态势感知装备击毁且两个指挥所均存在”的阶段,“态势感知装备存活且只剩一个指挥所”阶段和“态势感知装备击毁且两个指挥所均存在”阶段可进入“态势感知装备击毁且只剩一个指挥所”阶段,到达这个阶段后,进入“任务完成”阶段。
[0061]
3)智能决策下的实体控制
[0062]
乙方实体采用战场知识和智能决策结合的形式进行控制。以攻击装备控制为例,在本任务中,攻击装备控制的核心是移动控制和打击控制,如图8所示。针对移动控制中的不同子任务,采用不同的决策策略。
[0063]
航迹规划由战场知识确定:在该想定中,战斗机尽量保持在干扰机附近,其航迹随着干扰机任务阶段和位置的变化而变化。
[0064]
返航规划由路径规划算法确定:对于弹药用尽的实体,其返航过程可以看作一个有障碍物(障碍物指敌方有威胁对空对抗实体)的路径规划问题。
[0065]
避弹规划由q学习确定:由于对推演中拦截弹药逼近时,规避时机和规避动作的选取缺乏经验指导,采取小场景学习的方式,专门训练飞机对弹药的规避能力。场景如图9,乙方舰艇射程为145km,当乙方舰艇在不同距离发射弹药后,甲方飞机采取机动动作(规则或强化学习控制),通过飞机的机动,使得统计被击率尽可能降低。
[0066]
规则避弹的设置为:当飞机检测到乙方弹药来袭时(被锁定),采取反向机动的方式进行规避。
[0067]
基于q学习的避弹策略的奖励值设置为:若最后成功规避弹药,给予正奖励值,若最后规避弹药失败,给予负奖励。虽然该奖励值的设置具有稀疏性,在实际测试中,由于该训练片段时间相对短,该奖励值满足训练要求。
[0068][0069]
由于q学习动作空间为离散的,如图10所示,飞机的水平控制方向根据航向角大小被简化为八个角度:航向角取正北方为0度,每隔45度为一个动作方向。规则模型和训练约5000盘后的学习模型的表现见表3。
[0070]
表3避弹场景弹药命中率
[0071][0072][0073]
经过数据分析,学习后的模型的避弹策略为:当发现弹药来袭时,向远离弹药的方向进行机动,当弹药距离自己非常接近时(大约6km左右),飞机进行大角度全速规避。通过
学到的大角度规避动作,在弹药速度有所降低后,学习模型在中距离(125
‑
115km)上的表现超过规则模型,但是当弹药发射距继续缩小时,由于弹药的速度仍然保持高速,无论飞机采取何种末端规避动作,都很难摆脱弹药的袭击。
[0074]
针对打击控制任务,其核心是实现弹目匹配。目标打击的实现有两个途径:一方面可以由战场知识决定打击距离,并在打击决策时采用基于威胁度评估的弹目匹配等方法,将目标打击转化为通用的整数规划问题,进而用运筹学的方法解决;另一方面可以采用qmix等多智能体强化学习算法。qmix采用一个混合网络对单智能体局部值函数进行合并,并在训练学习过程中加入全局状态信息辅助,来提高算法性能。其中每个飞机的动作空间为:{无打击动作,打击敌方飞机1,
……
,打击敌方飞机n}。
[0075]
4)优先级分配
[0076]
在该想定下,由于乙方作为攻击方具备充足打击能力,因此在执行使命时,完成对敌方的打击相对于战损更为重要,在该环境下,一组简单的优先级分配为:打击>避弹>移动。在不同的想定下,通过调整各指令动作的优先级高低,可以迅速调控整个智能决策系统的执行风格,做出适应想定的最优动作。
[0077]
本发明的有益效果:
[0078]
针对在兵棋推演的全阶段使用强化学习算法出现的收敛性差和计算要求高的问题,为在有限时间内充分集合各智能决策方法的优势,本发明提出了一套知识驱动下的兵棋推演智能决策框架,通过结合战场知识,结合多种智能决策技术,从而实现特定兵棋推演想定下的有效决策。
[0079]
基于本发明框架在兵棋赛事中进行开发的智能体,在有100多支有效参赛队的联合对抗智能博弈兵棋推演挑战赛中取得第二名的成绩,验证了本发明方法的有效性。
[0080]
上述实施例为本发明的一种实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何背离本发明的精神实质与原理下所做的改变、修饰、代替、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1