一种分布式联邦学习协同计算方法及系统与流程
1.本技术涉及通信领域,尤其涉及一种分布式联邦学习协同计算方法及系统。
背景技术:
2.金属材料工件是机械加工过程中一些产品的重要组成部分,金属材料工件质量的优劣直接影响着企业产品的市场竞争力,因此对机械加工过程中的金属材料工件表面缺陷进行检测就显得非常重要。对于金属表面的缺陷检测,可以利用深度学习技术,从生产线上采集工件图像,再从图像中提取缺陷信息,通过学习金属工件表面缺陷特征,建立金属材料工件缺陷的网络检测与缺陷识别模型。常用的检测模型包括fast r
‑
cnn、faster r
‑
cnn、mask r
‑
cnn等。然而,在工业园区内,部分工厂存在数据规模有限、数据质量良莠不齐的问题。另外,由于行业竞争、隐私保护等问题,造成了数据难以在不同的企业之间共享、整合,导致这些工厂难以训练出高质量的检测模型。
3.联邦学习(federated learning,fl)是为应对人工智能实际应用时面对的数据隐私保护问题而诞生的一种人工智能学习框架。其核心目标是使各个参与方在无需直接交换数据的前提下,实现多个参与方之间的协同学习,建立共享的、全局有效的人工智能模型。在联邦学习框架下,参与方先在本地训练本地模型,再将本地模型的参数加密后上传至中心服务器,服务器对各个本地模型进行安全聚合后将更新后的全局模型参数发送给各个参与方,这一迭代过程一直重复至全局模型达到目标精度。在此过程中,参与方上传和下载的均是模型的参数,数据始终留在本地,可以很好地保护客户的数据隐私。
4.此外,联邦学习框架仍存在一些安全问题。模型聚合的集中式管理器可能容易受到各种威胁(例如,单点故障和ddos攻击),其故障(例如,扭曲所有本地模型更新)可能导致整个学习过程失败。尽管联邦学习很好地解决了各参与方数据量不足、隐私泄露等问题,分布式的联邦学习框架也能很好地解决联邦学习过程中的安全问题,但是目前的学术界很少关注分布式联邦学习的时延问题。考虑到不同的参与方在同一轮次的训练速度存在差异,先完成计算的参与方会进入消极等待时间,造成资源的浪费。同时,参与方与边缘服务器之间的网络连接是不稳定的,网络质量会因环境因素而不断变化,上传模型所需要的时间具有较大的不确定性,很可能延长模型聚合所需的时间。
5.因此,如何在减少每一轮联邦学习所需的时间的同时,提升每一轮全局模型的精度,降低全局模型达到目标精度的总时延,是个等待解决的问题。
技术实现要素:
6.基于此,本技术提供一种用于智能工厂的分布式联邦学习协同计算方法,保证了联邦学习过程的安全性,并利用深度强化学习(deep reinforcement learning,drl)技术解决了边缘服务器与参与方之间的关联及带宽资源分配问题以及参与方的计算资源分配问题。
7.为了达到上述目的,本技术提供了一种分布式联邦学习协同计算方法,具体包括
以下步骤:进行深度强化学习模型训练;响应于将训练好的深度强化学习模型分别部署至各边缘服务器,进行联邦学习;联邦学习结束。
8.如上的,其中,进行深度强化学习模型训练,具体包括以下子步骤:进行深度强化学习模型的网络参数和状态信息的初始化;各参与方根据深度强化学习模型初始化的网络参数和状态信息,进行各自本地模型的训练;响应于完成本地模型的模拟训练,生成带宽分配策略,并在每个时隙单步更新ac网络参数;响应于完成本地模型的模拟传输,生成关联策略和计算资源分配策略,并更新dqn网络参数;检测深度强化学习模型是否收敛或最大迭代次数;若未收敛或最大迭代次数,则开始下一轮迭代,重新进行本地模型的训练。
9.如上的,其中,将金属表面缺陷检测模型作为本地模型。
10.如上的,其中,初始化的状态信息具体包括:初始化actor网络、critic网络、dqn网络的参数及收敛精度,各参与方的位置坐标[x
k
,y
k
]、初始mini
‑
batch值cpu频率f
k
,各边缘服务器的位置坐标[x
m
,y
m
]及最大带宽b
m
,时隙长度δt和最大迭代次数i。
[0011]
如上的,其中,参与方进行本地模型的训练过程为,将本地数据集d
k
划分为若干个大小为的小批量b,并通过以下公式更新局部权重来训练小批量b,以此完成本地模型的训练,其中训练过程表示为:
[0012][0013]
其中,η表示学习率,表示每一个小批量b的损失函数的梯度,表示第i轮迭代中参与方k的本地模型。
[0014]
如上的,其中,在进行本地模型的模拟训练,还包括,确定第i轮本地训练时参与方k所需要的时间,第i轮本地训练时参与方k所需要的时间具体表示为:
[0015][0016]
其中,c
k
表示参与方k训练单个数据样本时的cpu周期数,τ表示参与方执行mbgd算法时的迭代次数,f
k
表示参与方k训练时的cpu周期频率,表示参与方k在第i轮执行本地训练时的mini
‑
batch值。
[0017]
如上的,其中,将当前快尺度状态空间作为ac网络的输入,得到快尺度动作空间,即带宽资源分配策略;快尺度状态空间s表示为:
[0018]
表示各参与方未完成传输的模型大小,表示每个时隙参与方上传模型的传输速率,t表示时隙,δt表示时隙长度;
[0019]
快尺度动作空间快尺度动作空间即为带宽资源分配策略,其中表示边缘服务器m每个时隙为参与方k分配的带宽。
[0020]
如上的,其中,将训练好的深度强化学习模型的各参数按照确定的带宽资源分配策略上传至边缘服务器的过程中,第i轮参与方k和边缘服务器m之间的可用上行数据传输速率表示为:
[0021][0022]
其中,p
k
表示参与方k的传输功率,表示加性高斯白噪声的功率谱密度,k示参与方k和边缘服务器m的信道增益,ψ0表示参考距离处的信道功率增益。
[0023]
如上的,其中,还包括,第i轮参与方k将深度强化学习模型参数上传到边缘服务器m所用的时间具体表示为:
[0024][0025]
其中,ξ表示金属表面缺陷检测模型的大小,表示第i轮参与方k和边缘服务器m之间的可用上行数据传输速率。
[0026]
一种分布式联邦学习协同计算系统,具体包括:深度强化学习单元以及联邦学习单元;其中深度强化学习单元,用于进行深度强化学习模型训练;联邦学习单元,用于根据深度强化学习模型生成的关联策略和计算即带宽资源分配策略进行联邦学习。
[0027]
本技术具体以下有益效果:
[0028]
(1)本实施例提供的分布式联邦学习协同计算方法及系统针对分布式联邦学习框架,打破了传统联邦学习对中心服务器的依赖,有效保证了联邦学习过程的隐私保护和安全性。
[0029]
(2)本实施例提供的分布式联邦学习协同计算方法及系统从两个角度实现联邦学习总时延最小化的设计目标,即同时考虑减少总迭代轮次和减少每一轮迭代所消耗的时间,充分利用了各参与方和边缘服务器的计算和通信资源,实现联邦学习的效用最大化。
[0030]
(3)本实施例提供的分布式联邦学习协同计算方法及系统考虑了各参与方计算量对模型精度的影响,调整了各参与方的本地模型在全局聚合过程中所占的权重,保证了聚合过程的公平性,有利于加速模型收敛。
附图说明
[0031]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
[0032]
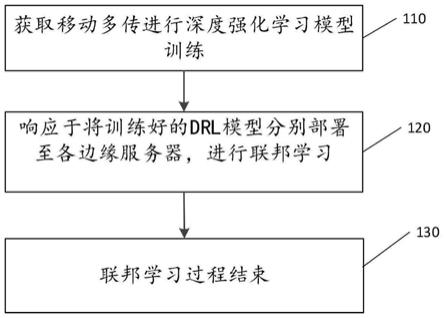
图1是本技术提出的分布式联邦学习协同计算方法的流程图;
[0033]
图2是本技术提出的分布式联邦学习协同计算系统的示意图。
具体实施方式
[0034]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0035]
本技术提出并解决了分布式联邦学习系统框架中总时延最小化的问题,即全局模型达到目标精度的总时延最小化的问题,着重考虑了系统中边缘服务器与参与方之间的关联与带宽资源分配问题以及参与方的计算资源分配问题。
[0036]
场景假设:本技术用集合k={1,2,
…
,k}表示联邦学习的所有参与方,参与方k的数据集的大小表示为d
k
,对于数据集中的每一个样本d
n
={x
n
,y
n
},x
n
表示输入的向量,y
n
表示向量x
n
对应的输出标签,用[x
k
,y
k
]表示参与方k的位置坐标;用集合m={1,2,
…
,m}表示所有作为边缘服务器的小基站,用[x
m
,y
m
]表示边缘服务器m的位置坐标。此外,用i={1,2,i,i}表示联邦学习的迭代轮次,表示第i轮迭代中参与方k与边缘服务器m建立了通信连接,反之则通信连接,反之则表示参与方k在第i轮执行本地训练时的mini
‑
batch值;用t={1,2,t,t}表示每一轮迭代的所有时隙,δt表示时隙长度,表示边缘服务器m每个时隙为参与方k分配的带宽;ω
i
表示第i轮的全局模型,表示第i轮迭代中参与方k的本地模型。
[0037]
其中,本技术所要解决的技术问题是如何解决最小化联邦学习过程的协同计算总时延问题,该问题具体表示为:
[0038][0039][0040][0041][0042][0043]
其中,c1表示每个参与方只能连接到一个边缘服务器;c2表示每个边缘服务器至少与一个参与方进行连接;c3表示每个边缘服务器分配的带宽不超过其最大带宽容量;c4表示参与方每轮的mini
‑
batch值不超过其数据量大小。表示第i轮本地训练时参与方k所需要的时间,其中表示边缘服务器m每个时隙为参与方k分配的带宽,
表示第i轮迭代中参与方k与边缘服务器m建立了通信连接,反之则参与方k的数据集的大小表示为dk。表示参与方k在第i轮执行本地训练时的mini
‑
batch值。b
m
表示各边缘服务器最大带宽。
[0044]
该问题中具有动态的限制条件和长期的目标,且系统的当前状态仅取决于上一轮迭代时的状态和采取的动作,满足马尔科夫性质,可以将该问题表述为马尔科夫决策过程(mdp),即mdp{s,a,γ,r}。其中,s表示状态空间,a表示动作空间,γ表示折扣因子,r表示奖励函数。同时,该问题的求解也转化为在不同状态下决定当前状态所对应的最优动作选择。
[0045]
进一步地,上述问题可转化为求解边缘服务器与参与方之间的关联及带宽资源分配问题以及参与方的计算资源分配问题。在该问题中,有三种决策变量,分别为其中和为离散变量,且只在不同聚合轮次之间发生变化,而为连续变量,且在每一个时隙之间都会产生变化,因此可以采用双时间尺度的深度强化学习,以聚合轮次i为慢时间尺度的时间间隔,采用dqn网络在慢时间尺度上生成当前状态下的关联策略和计算资源分配策略;以时隙长度δt为快时间尺度的时间间隔,采用actor
‑
critic(ac)网络在快时间尺度上对其进行单步更新,生成当前状态下的带宽资源分配策略。
[0046]
基于上述思想,本技术提供了如图1所示的分布式联邦学习协同计算方法的流程图,具体包括以下步骤。
[0047]
步骤s110:进行深度强化学习模型训练。
[0048]
其中,采用线下训练、线上执行的方式预先训练深度强化学习模型。训练深度强化学习模型(drl模型)具体为训练ac网络和dqn网络。其中drl模型训练包括以下子步骤:
[0049]
步骤s1101:进行drl模型的网络参数和状态信息的初始化。
[0050]
具体地,初始化的状态信息具体包括:初始化actor网络、critic网络、dqn网络的参数,初始关联策略,各参与方的位置坐标[x
k
,y
k
]、初始mini
‑
batch值cpu频率f
k
,各边缘服务器的位置坐标[x
m
,y
m
]及最大带宽b
m
,时隙长度δt和最大迭代次数i,模拟联邦学习过程时用的本地模型参数。
[0051]
步骤s1102:各参与方进行各自本地模型的训练。
[0052]
其中,按照步骤1101中初始化的网络参数和状态信息模拟联邦学习过程,即模拟各参与方按照dqn网络输出的mini
‑
batch值进行本地模型的训练。其中,模拟联邦学习过程的目的就是为了训练drl模型。
[0053]
优选地,各参与方使用小批量随机梯度下降法(mini
‑
batch gradient descent,mbgd)的优化方法来进行本地模型的训练。
[0054]
将本地数据集d
k
划分为若干个大小为的小批量b,并通过以下公式更新局部权重来训练小批量b,以此完成本地模型的训练,其中训练过程表示为:
[0055]
[0056]
其中,η表示学习率,表示每一个小批量b的损失函数的梯度,表示第i轮迭代中参与方k的本地模型。
[0057]
其中,在进行本地模型的模拟训练后,还包括,确定第i轮本地训练时参与方k所需要的时间,
[0058]
第i轮本地训练时参与方k所需要的时间具体表示为:
[0059][0060]
其中,c
k
表示参与方k训练单个数据样本时的cpu周期数,τ表示参与方执行mbgd算法时的迭代次数,f
k
表示参与方k训练时的cpu周期频率。
[0061]
步骤s1103:响应于完成模拟本地模型训练,生成带宽分配策略并模拟本地模型传输,同时在每个时隙单步更新ac网络参数。
[0062]
其中,模拟各参与方按照dqn网络输出的关联策略上传到相应的边缘服务器的过程,同时ac网络观察当前时隙的快尺度状态s,输出快尺度动作a(t),并采用贝尔曼方程更新ac网络参数。
[0063]
具体地,快尺度状态表示为表示为表示各参与方未完成传输的本地模型大小,其中ξ表示本地模型大小,表示每个时隙参与方上传本地模型的传输速率,
[0064]
具体地,第i轮参与方k和边缘服务器m之间的可用上行数据传输速率表示为:
[0065][0066]
其中,p
k
表示参与方k的传输功率,表示加性高斯白噪声的功率谱密度,表示参与方k和边缘服务器m的信道增益,ψ0表示参考距离处的信道功率增益。
[0067]
快尺度动作即为带宽资源分配策略,其中表示边缘服务器m每个时隙为参与方k分配的带宽。
[0068]
快尺度奖励函数r(t)表示为:
[0069][0070]
其中,μ(t)为调整奖励函数的参数。
[0071]
折扣因子γ:用来削减未来奖励对现在的影响,越远的奖励作用越小。快尺度状态s下选择快尺度动作a(t)获得的累积奖励可以定义为:
[0072][0073]
步骤s1104:响应于模拟本地模型传输,模拟全局模型聚合,生成下一轮的关联策略的和计算资源分配策略,并更新dqn网络参数。
[0074]
其中,用以下公式对每个参与方的本地模型参数进行加权,得到全局模型参数ω
i
并检测全局模型精度:
[0075][0076]
其中α+β=1表示调整权重占比的两个参数。
[0077]
由于在步骤s1103中的关联策略是预先初始化的,因此需要进行关联策略的更新。具体将当前慢尺度状态s作为dqn网络的输入,输出慢尺度动作a,即关联策略和计算资源分配策略,并采用贝尔曼方程更新dqn网络参数。
[0078]
其中,慢尺度状态表示为s=[t
k
,t
k,m
],表示各参与方本地训练所消耗的时间向量,表示各参与方上传模型所消耗的时间向量,其中表示参与方k将模型上传至边缘服务器m所消耗的时间。
[0079]
慢尺度动作表示为a=[a,b],表示各参与方和边缘服务器之间的关联向量,即更新后的关联策略,表示各参与方执行本地模型训练时的mini
‑
batch向量,即计算资源分配策略。
[0080]
慢尺度奖励函数r
i
表示为:
[0081][0082]
其中μ是一个调整奖励函数的参数,表示第i轮全局模型的精度。
[0083]
慢尺度状态s下选择慢尺度动作a获得的累积奖励可以定义为:
[0084][0085]
步骤s1105:检测drl模型是否收敛或达到最大迭代次数。
[0086]
若未收敛或达到最大迭代次数,则迭代次数加1,重复执行步骤s1102
‑
s1104,开始下一轮迭代,将全局模型作为各参与方的本地模型重新模拟本地模型训练。
[0087]
其中在下一次迭代过程中,利用上一次迭代生成的关联策略和下一次训练本地模型所需要的mini
‑
batch向量,然后在下一次迭代过程中根据ac网络在当前时隙观察到的快
尺度状态空间生成新的带宽分配策略、以及dqn在慢尺度状态空间生成新的关联策略、和计算资源分配策略。以此类推,不断更新带宽资源分配策略、关联策略、和计算资源分配策略。
[0088]
若收敛或达到最大迭代次数,则完成ac网络和dqn网络的训练,即完成了drl模型的训练,执行步骤s1106。
[0089]
步骤s1106:将训练好的drl模型的各参数发送至边缘服务器。
[0090]
其中,边缘服务器加载drl模型,即训练后的ac网络和dqn网络,用来生成当前状态下的关联策略和带宽及计算资源分配策略,完成drl模型的部署。
[0091]
步骤s120:响应于将训练好的drl模型分别部署至各边缘服务器,进行联邦学习。
[0092]
其中,由于drl模型是为了解决联邦学习时延最小化这个问题,因此在步骤s110中训练完成drl模型后,在步骤s120中将drl模型应用至联邦学习过程。
[0093]
其中步骤s120具体包括以下子步骤:
[0094]
步骤s1201:初始化本地模型。
[0095]
其中,由指定的参与方选取的合适的金属表面缺陷检测模型作为本地模型。
[0096]
具体地,将金属表面缺陷检测模型参数、学习率、初始mi n i
‑
batch值、金属表面缺陷检测模型的迭代次数通过边缘服务器广播至其他参与方,各参与方将金属表面缺陷检测模型作为本地模型,完成本地模型初始化。
[0097]
步骤s1202:响应于完成本地模型的初始化,各参与方根据当前状态下的计算资源分配策略进行本地模型训练。
[0098]
在本步骤中,当前状态下的计算资源分配策略为执行步骤s110后,训练完成的dqn网络所输出的计算资源分配策略。
[0099]
其中本地模型的训练方式按照现有方法进行训练,在此不进行赘述。
[0100]
步骤s1203:每个参与方根据关联策略和带宽资源分配策略将各自训练的本地模型参数分别上传至边缘服务器。
[0101]
具体地,其中此时的关联策略和带宽资源分配策略为执行步骤s110后,训练完成的ac网络和dqn网络所输出的关联策略和带宽资源分配策略。
[0102]
步骤s1204:对每个参与方上传的本地模型进行全局模型聚合,将全局模型参数以及计算资源分配策略发送至每个参与方。
[0103]
具体地,将所有参与方上传的本地模型聚合为一个全局模型。
[0104]
其中在聚合过程中,首先按照边缘服务器的位置信息选出临时充当中心服务器的边缘服务器,具体根据以下公式进行选取:
[0105][0106]
其中,[x
m
,y
m
]表示各边缘服务器的位置坐标,集合m={1,2,
…
,m}表示所有作为边缘服务器的小基站。
[0107]
进一步地,根据上述公式得到临时中心服务器后,临时中心服务器用以下公式对每个参与方的本地模型参数进行加权,最终得到全局模型参数ω
i
:
[0108]
[0109]
其中α+β=1表示调整权重占比的两个参数。
[0110]
其中,此时发送至各参与方的计算资源分配策略为执行步骤1202
‑
1203后的下一轮迭代所需的计算资源分配策略。由于在步骤s1202训练本地模型中各参与方本地训练所消耗的时间向量t
k
发生了改变,在步骤s1203中,各参与方上传模型所消耗的时间向量t
k,m
也发生了改变,因此在当前状态空间s=[t
k
,t
k,m
]也发生了变化,得到的关联策略a=[a,b]发生了变化,也发生了变化,即下一轮迭代所用的mini
‑
batch向量发生了改变,mini
‑
batch向量改变带来了计算资源分配策略的变化,即下一轮所用的计算资源分配策略发生了改变。
[0111]
步骤s1205:判断全局模型是否达到预设收敛精度或达到最大迭代次数。
[0112]
若全局模型未达到预设收敛精度或达到最大迭代次数,则迭代次数加1,重新执行步骤s1202,即重新进行本地模型的训练。
[0113]
重新进行本地模型的训练,就是根据步骤s1204中发送至各参与方的全局模型参与和计算资源分配策略重新进行本地模型的训练。
[0114]
具体地,将每个参与方收到的全局模型再次作为本地模型,并根据步骤s1204发送给各参与方的下一轮迭代需要的计算资源分配策略对本地模型进行再次训练。即重复执行步骤s1202
‑
1204。
[0115]
若全局模型达到预设收敛精度或达到最大迭代次数,则忽略步骤s1204中发送至各参与方的全局模型和计算资源分配策略,不再进行本地模型的训练,执行步骤s130。
[0116]
步骤s130:联邦学习过程结束。
[0117]
如图2所示,为本技术提供的分布式联邦学习协同计算系统,其中具体包括:深度强化学习模型训练单元210、联邦学习单元220。
[0118]
其中深度强化学习模型训练单元210,用于进行深度强化学习模型训练。
[0119]
联邦学习单元220与深度强化学习模型训练单元210连接,用于根据深度强化学习模型生成的关联策略和计算即带宽资源分配策略进行联邦学习。
[0120]
本技术具体以下有益效果:
[0121]
(3)本实施例提供的分布式联邦学习协同计算方法及系统针对分布式联邦学习框架,打破了传统联邦学习对中心服务器的依赖,有效保证了联邦学习过程的隐私保护和安全性。
[0122]
(4)本实施例提供的分布式联邦学习协同计算方法及系统从两个角度实现联邦学习总时延最小化的设计目标,即同时考虑减少总迭代轮次和减少每一轮迭代所消耗的时间,充分利用了各参与方和边缘服务器的计算和通信资源,实现联邦学习的效用最大化。
[0123]
(5)本实施例提供的分布式联邦学习协同计算方法及系统考虑了各参与方计算量对模型精度的影响,调整了各参与方的本地模型在全局聚合过程中所占的权重,保证了聚合过程的公平性,有利于加速模型收敛。
[0124]
以上所述实施例,仅为本技术的具体实施方式,用以说明本技术的技术方案,而非对其限制,本技术的保护范围并不局限于此,尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特殊进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的
本质脱离本技术实施例技术方案的精神和范围。都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应所述以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1