一种自加权融合局部和全局信息的多视图子空间聚类方法
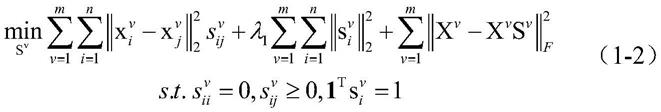
1.本发明涉及计算机视觉、模式识别和数据挖掘等技术领域,更具体地,涉及一种自加权融合局部和全局信息的多视图子空间聚类方法。
背景技术:
2.随着互联网技术的快速发展,人们获取数据的手段越来越多样化,使得大量无标签的数据不断产生。在当今大数据时代环境的影响下,如何对这些无标签的数据进行分析和处理从而揭示其内在规律成为各行各业广泛关注的问题。聚类做为一种无监督学习技术,在机器学习、计算机视觉和数据挖掘等领域被广泛使用。聚类试图对无标签的数据依据其数据自身的内在特性,将数据划分成若干个簇,即使得“簇内相似度”高且“簇间相似度”低。为下一步的数据分析提供基础。
3.传统的聚类方法通过挖掘单视图数据的内在结构来对数据进行划分。例如:k均值聚类、密度聚类、层次聚类、谱聚类、子空间聚类等方法。单视图数据由单一特征构成的数据。当单视图数据不足以全面描述对象时和/或严重损坏的情况下,会导致传统聚类方法的性能不佳。真实世界的数据通常具有多种表现形式,即每个对象被不同类型的特征进行表示,这些不同类型的特征被称为多视图数据。例如,一个物体通过主视图、侧视图和俯视图来共同描述物体的外部特征。同一段文字被翻译成不同国家的语言,如:中文,英文,日文等等。一张图片提取方向梯度直方图(histograms of oriented gradients,hog)、局部二值模式(local binary patterns,lbp)以及尺度不变特征变换(scale invariant feature transform,sift)等。多视图数据不仅拥有每个视图下特有的信息,还拥有视图之间的互补信息。使用多视图数据进行聚类发挥每个视图的优势,同时也规避自身视图的风险,从而获取更好的聚类性能。
4.现有的多视图聚类方法大致分为以下几类:基于k均值多视图聚类,基于矩阵分解多视图聚类,多视图图聚类和多视图子空间聚类。多视图图聚类和多视图子空间由于其良好的聚类性能和数学可解释性而受到广泛的关注。多视图图聚类通过采用不同的度量(二元相似度,余弦相似度,高斯核相似度)手段去度量不同样本之间的相似度,然后采用完整图或k近邻图其中一种去构造每个视图的图矩阵,然后将所有视图的图矩阵进行融合形成统一的图矩阵,最后对统一的图矩阵进行谱聚类或图割算法获得聚类结果。多视图子空间聚类通常使用自表示学习去得到每个视图的子空间表示,然后将所有视图的子空间表示进行融合形成统一的子空间表示,最后对统一的子空间表示进行谱聚类获得聚类结果。多视图图聚类在原始数据的局部层面上构建图矩阵,多视图子空间在原始数据的全局层面上构建相似度矩阵。将多视图图聚类和多视图子空间聚类进行结合来考虑原始数据的局部信息和全局信息,并引入秩约束直接对一致的子空间进行限制。在获取一致的子空间表示的同时,能够直接获得多视图数据的聚类结构,而无需再执行额外的聚类算法。
技术实现要素:
5.本发明提供一种自加权融合局部和全局信息的多视图子空间聚类方法,该方法在生成一致的相似度矩阵的同时也揭示了数据的聚类结构,从而获取良好的聚类效果。
6.为了达到上述技术效果,本发明的技术方案如下:
7.一种自加权融合局部和全局信息的多视图子空间聚类方法,包括以下步骤:
8.s1:采集多视图数据并进行预处理;
9.s2:通过图学习挖掘原始多视图数据的局部信息时加入自表示学习来挖掘原始多视图数据的全局信息从而获得高质量和高鲁棒性的相似度矩阵;
10.s3:采取自加权的方式将所有视图的相似度矩阵进行融合形成一致的相似度矩阵;
11.s4:对一致的相似度矩阵引入秩约束,使得一致的相似度矩阵中连通分量的个数等于聚类簇的个数,从而直接获得多视图聚类结果。
12.进一步地,所述步骤s1中,对采集的多视图数据进行预处理的过程是:
13.使用l2范数归一化操作对向量的每一个元素都除以得到一个新向量,l2范数归一化通常将数据向量每个维度的数据映射到(
‑
1,1)之间的区间即:
[0014][0015]
其中是第v个视图的i个样本的原始特征。是的第1个元素,是第v个视图的i个样本归一化后的特征,
·2表示向量的l2范数。
[0016]
进一步地,所述步骤s2中,通过自表示学习和图学习相结合的方式去计算多视图数据中每个视图数据对应的相似度矩阵:
[0017][0018]
其中和分别是第v个视图的第i个样本的原始特征和第j个样本的原始特征,表示第v视图的原始特征,m表示视图的数量,n表示样本的数量,d
v
表示第v视图的特征维度,是第v个视图的相似度矩阵,是s
v
的第i列向量,1是所有元素全为1的列向量,(
·
)
t
表示矩阵的转置,表示矩阵的frobenius范数的平方,表示向量的l2范数的平方,λ1是一个平衡参数。
[0019]
进一步地,所述步骤s3中,采取自加权的方式将所有视图的相似度矩阵进行融合形成一致的相似度矩阵:
[0020][0021]
其中表示一致的相似度矩阵,diag(
·
)表示矩阵的对角元素。
[0022]
进一步地,所述步骤s4中,引入秩约束使得一致的相似度矩阵具有理想的性质,从
而直接获得最终的聚类结果,形式如下:
[0023][0024]
其中,l
s
=d
‑
1/2(s+s
t
)是s的拉普拉斯矩阵,d是s的度矩阵,其中第i个对角元素为k是聚类簇的个数,rank(
·
)表示矩阵的秩。
[0025]
进一步地,所述步骤s4中,由于公式(1
‑
4)中存在秩约束rank(ls)=n
‑
k会使得该优化问题变得难以求解,根据ky fan’s定理,将秩约束转化为最小化问题其中σ
i
(l
s
)是l
s
的第i小特征值,l
s
的前k小的特征值均为0,即将使得l
s
的秩为n
‑
k,公式(1
‑
4)自然转化为如下形式:
[0026][0027]
其中,表示聚类指示矩阵,表示单位矩阵,tr(
·
)表示矩阵的秩,λ2是一个平衡参数。
[0028]
进一步地,所述步骤s4中,通过将公式(1
‑
2),(1
‑
3),(1
‑
5)集成在一起,得到一种自加权融合局部和全局信息的多视图子空间聚类方法的目标函数:
[0029][0030]
由于公式(1
‑
6)中存在多个变量和多个约束条件,只对其中一个变量进行求解,然后交替进行直到求得所有变量的最优解;
[0031]
固定s,f和wv,更新s
v
,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0032][0033]
对于公式(1
‑
7)的求解,采用两步逼近的求解方法来求s
v
的最优解;
[0034]
首先求得不带任何约束的封闭解,由于每个视图子空间表示s
v
是相互独立的,因此对每个s
v
进行单独的求解,故(1
‑
7)进一步转化为:
[0035][0036]
公式(1
‑
8)关于s
v
求导并令其等于0,求解得到:
[0037][0038]
其中,是矩阵的第i列第j行元素;
[0039]
将投影到一个受约束条件限制的空间中以此来求得s
v
的近似解,对于每一行,得到:
[0040][0041]
则得到公式(1
‑
10)的拉格朗日函数为:
[0042][0043]
其中α
i
和β
i
≥0是拉格朗日乘子,推导得到如下表达式:
[0044][0045]
固定s
v
,f和w
v
,更新s,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0046][0047]
因为上述问题重写为:
[0048][0049]
表示和表示h
i,:
为一个行向量,h
ij
是h
i,:
的第j个元素,然后将公式(1
‑
14)用向量表示如下:
[0050][0051]
当sv和f固定不变时,上述第二项和第三项是常数,表示将上述问题化简为:
[0052][0053]
公式(1
‑
16)求解过程与公式(1
‑
10)是一样的。
[0054]
固定s
v
,s和f,更新w
v
,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0055]
[0056]
进一步地,步骤s4中,定义首先定义s的辅助函数为:
[0057][0058]
通过对上述约束问题构造拉格朗日函数,然后拉格朗日函数对s求导,并令导数等于0:
[0059][0060]
其中有约束项s
ij
≥0,1
t
s
i
=1转化出的形式项,λ是拉格朗日乘子和:
[0061][0062]
如果对进行相同的运行,得到与公式(1
‑
19)相同的结果,因此权重w
v
的最优解是
[0063]
进一步地,固定s
v
,s和w
v
,更新f,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0064][0065]
最优解f由l
s
对应于k个最小特征值的k个特征向量构成,重复上述步骤直到和条件满足,停止计算。
[0066]
进一步地,步骤s1中采集多视图数据的方法是:对同一批物体采用不同的传感器进行数据采集;对同一批物体使用同一个传感器设备采集的数据使用不同的特征提取器以提取不同的特征。
[0067]
与现有技术相比,本发明技术方案的有益效果是:
[0068]
本发明方法首先对获取的多视图数据进行预处理。其次通过图学习挖掘原始多视图数据的局部信息时加入自表示学习来挖掘原始多视图数据的全局信息从而获得高质量和高鲁棒性的相似度矩阵。然后采取自加权的方式将所有视图的相似度矩阵进行融合形成一致的相似度矩阵。通过对一致的相似度矩阵引入秩约束,使得一致的相似度矩阵中连通分量的个数等于聚类簇的个数,从而直接获得多视图聚类结果。这避免了在获取一致的相似度矩阵之后,还需要执行额外的聚类步骤去获取聚类结果。的方法在生成一致的相似度矩阵的同时也揭示了数据的聚类结构,从而获取良好的聚类效果。
附图说明
[0069]
图1为本发明逻辑流程图;
[0070]
图2为本发明一实施例的示意图;
具体实施方式
[0071]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0072]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0073]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是理解的。
[0074]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0075]
如图1和图2所示,本实施例所提供的一种自加权融合局部和全局信息的多视图子空间聚类方法,使用100种植物叶片数据集(100leaves数据集)对本方法进行评测。包括以下步骤:
[0076]
s1:获取多视图数据;
[0077]
s2:对多视图数据进行预处理;
[0078]
s3:通过自表示学习和图学习相结合的方式去计算多视图数据中每个视图数据对应的相似度矩阵;
[0079]
s4:采取自加权的方式将所有视图的相似度矩阵进行融合形成一致的相似度矩阵;
[0080]
s5:引入秩约束使得一致的相似度矩阵具有理想的性质,从而直接获得最终的聚类结果。
[0081]
更具体的,在步骤s1中,获取多视图数据,包括由伦敦金斯顿大学在英国皇家植物园收集的100种植物叶片数据集(100leaves数据集),它包含1600个样本共100个类,每个样本分别给出形状描述符、小尺度边缘和纹理直方图共计三个视图数据。
[0082]
更具体的,在步骤s2中,对多视图数据进行预处理的方法包括:使用l2范数归一化操作对向量的每一个元素都除以得到一个新向量,l2范数归一化通常将数据向量每个维度的数据映射到(
‑
1,1)之间的区间即:
[0083][0084]
其中是第v个视图的i个样本的原始特征。是的第1个元素。是第v个视图的i个样本归一化后的特征。
·2表示向量的l2范数。
[0085]
更具体的,在步骤s3中,通过自表示学习和图学习相结合的方式去计算多视图数据中每个视图数据对应的相似度矩阵:
[0086][0087]
其中和分别是第v个视图的第i个样本的原始特征和第j个样本的原始特征。表示第v视图的原始特征。m表示视图的数量。n表示样本的数量。d
v
表
示第v视图的特征维度。是第v个视图的相似度矩阵。是s
v
的第i列向量。1是所有元素全为1的列向量。(
·
)
t
表示矩阵的转置。表示矩阵的frobenius范数的平方,表示向量的l2范数的平方。λ1是一个平衡参数。
[0088]
更具体的,在步骤s4中,采取自加权的方式将所有视图的相似度矩阵进行融合形成一致的相似度矩阵:
[0089][0090]
其中表示一致的相似度矩阵。diag(
·
)表示矩阵的对角元素。
[0091]
更具体的,在步骤s5中,引入秩约束使得一致的相似度矩阵具有理想的性质,从而直接获得最终的聚类结果。形式如下:
[0092][0093]
其中,l
s
=d
‑
1/2(s+s
t
)是s的拉普拉斯矩阵,d是s的度矩阵,其中第i个对角元素为k是聚类簇的个数。rank(
·
)表示矩阵的秩。
[0094]
由于公式(1
‑
4)中存在秩约束rank(ls)=n
‑
k会使得该优化问题变得难以求解。根据ky fan’s定理,将秩约束转化为最小化问题其中σ
i
(l
s
)是l
s
的第i小特征值。显然,l
s
的前k小的特征值均为0,即将使得l
s
的秩为n
‑
k。因此,问题(1
‑
4)自然转化为如下形式:
[0095][0096]
其中,表示聚类指示矩阵。表示单位矩阵。tr(
·
)表示矩阵的秩。λ2是一个平衡参数。
[0097]
通过将公式(1
‑
2),(1
‑
3),(1
‑
5)集成在一起,得到一种自加权融合局部和全局信息的多视图子空间聚类方法的目标函数:
[0098][0099]
以下是对公式(1
‑
6)的求解过程:由于公式(1
‑
6)中存在多个变量和多个约束条件,同时对所有变量求得最优解比较困难。提出一种有效的迭代优化算法来对公式(1
‑
6)进行求解。其主要思想是固定其他变量,只对其中一个变量进行求解,然后交替进行直到求得所有变量的最优解。
[0100]
(1.1)固定s,f和w
v
,更新s
v
,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0101][0102]
对于公式(1
‑
7)的求解,采用两步逼近的求解方法来求s
v
的最优解。
[0103]
(1.1.1)首先求得不带任何约束的封闭解。由于每个视图子空间表示s
v
是相互独立的,因此对每个s
v
进行单独的求解。故(1
‑
7)进一步转化为:
[0104][0105]
公式(1
‑
8)关于s
v
求导并令其等于0,求解得到:
[0106][0107]
其中,表示是矩阵的第i列第j行元素。
[0108]
(1.1.2)将投影到一个受约束条件限制的空间中以此来求得s
v
的近似解。对于每一行,得到:
[0109][0110]
则得到公式(1
‑
10)的拉格朗日函数为:
[0111][0112]
其中α
i
和β
i
≥0是拉格朗日乘子。然后根据kkt条件和一些必要的数学推导,很容易地得到如下表达式:
[0113][0114]
(1.2)固定s
v
,f和w
v
,更新s,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0115][0116]
因为上述问题重写为:
[0117][0118]
表示和表示h
i,:
为一个行向量,h
ij
是h
i,:
的第j个元素。然后将公式(1
‑
14)用向量表示如下:
[0119][0120]
当s
v
和f固定不变时,上述第二项和第三项是常数,表示将上述问题化简为:
[0121][0122]
公式(1
‑
16)求解过程与公式(1
‑
10)是一样的。
[0123]
(1.3)固定s
v
,s和f,更新w
v
,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0124][0125]
定理1:定义
[0126]
证明:首先定义s的辅助函数为:
[0127][0128]
通过对上述约束问题构造拉格朗日函数,然后拉格朗日函数对s求导,并令导数等于0。有:
[0129][0130]
其中有约束项s
ij
≥0,1
t
s
i
=1转化出的形式项,λ是拉格朗日乘子和
[0131]
如果对进行相同的运行,得到与公式(1
‑
19)相同的结果。因此权重w
v
的最优解是
[0132]
(1.4)固定s
v
,s和w
v
,更新f,通过移除无关项,公式(1
‑
6)转化成如下形式:
[0133]
[0134]
最优解f由l
s
对应于k个最小特征值的k个特征向量构成。
[0135]
(1.5)重复步骤(1.1),(1.2),(1.3)和(1.4)直到和条件满足,停止计算。
[0136]
给定多视图数据聚类簇的个数,通过在一致的相似度矩阵上引入秩约束,在生成一致的相似度矩阵的同时也揭示了数据的聚类结构,从而获取最终的聚类结果。将该聚类结果与样本真实的类别进行比较,本发明的准率为90%,说明本发明具有较高的准确性,在实践应用提供一定的实用价值。
[0137]
相同或相似的标号对应相同或相似的部件;
[0138]
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
[0139]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1