一种基于kettle的动态数据库连接和自动化数据同步方法
1.本发明涉及数据集成技术领域,具体涉及一种基于kettle的动态数据库连接和自动化数据同步方法。
背景技术:
2.kettle是一种数据etl工具,可以把数据从一个数据库系统同步到另外一个数据库系统中,本质上是数据清洗和迁移工具,但是缺乏动态数据库连接和自动化数据同步的手段。
技术实现要素:
3.本发明的目的在于提供一种基于kettle的动态数据库连接和自动化数据同步方法,可实现使用kettle工具进行etl数据同步过程中的数据库连接配置动态切换和整个etl流程的自动化,具有操作简单、准确率高、速度快、可移植性强等特点。
4.一种基于kettle的动态数据库连接和自动化数据同步方法,包括如下步骤:
5.步骤一、为kettle作业新建共享的db连接信息,
6.导入或打开kettle一个作业,在作业的菜单导航栏下,新建抽象的数据源层、数据中间层、数据目标层以及db连接信息,输入数据库连接属性并使用变量定义,共享该db连接信息;
7.步骤二、设计元数据文件,描述数据分层后不同数据源环境与数据库连接信息映射关系,
8.使用json格式的数据描述数据层、应用环境、数据库连接实例信息之间的层级;
9.步骤三、数据传递,
10.根据元数据文件描述,将三个参数传递到python程序,程序将这三个参数按照层级解析后,获取本次etl数据同步的数据源、数据中间层、数据目标层连信息后,生成连接属性key/value并写入<user_home>/.kettle/kettle.properties配置文件,从而完成数据库连接信息的切换步骤;share.xml中定义的变量将根据key值从该文件中获取value;
11.步骤四、使用jenkins实现数据流程自动化,
12.建立etl流程jenkinspipeline,在pipeline中建立gitcheckoutstage 1,switchenvstage 2,migration stage 3,在jenkins中完成作业的数据源动态切换,数据源切换,自动化调度作业。
13.优选的,所述步骤一中,所有新建的共享db连接信息存放在<user_home>/.kettle/share.xml文件中。
14.优选的,所述步骤二中,所述层级的关系为:层级一
‑
>层级二
‑
>层级三,其中层级一为数据层名称,层级二为本层下的应用环境,层级三为数据库连接实例信息。
15.优选的,所述步骤三中,share.xml中定义的变量将根据key值从该文件中获取value。
16.优选的,所述步骤四中,具体操作如下:
17.stage 1:获取最新的etljob作业和python脚本源程序;
18.stage 2:执行python程序,根据参数解析元数据描述文件,向kettle.properties配置文件写入本次同步的环境信息;
19.stage 3:调用kitchen脚本文件(.bat/.sh),执行kettle作业文件。
20.优选的,所述数据层有数据来源层、数据清洗层和数据目标层,数据来源层、数据清洗层和数据目标层都含有多个数据库连接环境。
21.本发明的优点在于:
22.1、kettle中数据库连接配置动态切换技术面向数据开发者,工具操作简单,对于专业性要求不高,etl数据同步业务场景发生变化后,源数据库和目标数据库的环境可以通过脚本快速切换同步环境配置,快捷方便,并可避免误操作
23.2.整个数据同步etl过程完全由pipeline控制任务节点,完全自动化,可节约人工人本,提高效率。
附图说明
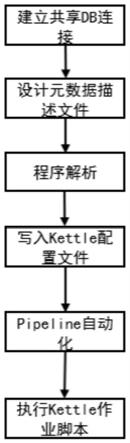
24.图1为本发明数据同步自动化设计流程图;
25.图2为本发明配置数据库连接信息界面图;
26.图3为本发明装置中元数据描述文件示意图;
27.图4为本发明装置中kettle.properties内容界面图;
具体实施方式
28.为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
29.如图1至图4所示,首先为kettle作业新建共享的db连接信息导入或打开kettle一个作业,在作业的菜单导航栏下,新建抽象的数据源层,数据中间层,数据目标层db连接信息,输入数据库连接属性并使用变量定义,共享该db连接信息,此时所有新建的共享db连接信息存放在<user_home>/.kettle/share.xml文件中。
30.设计元数据文件,描述数据分层后不同数据源环境与数据库连接信息映射关系,
31.使用json格式的数据描述数据层、应用环境、数据库连接实例信息之间的层级,关系为:层级一
‑
>层级二
‑
>层级三,层级一:数据层名称,层级二:本层下的应用环境,层级三:数据库连接实例信息,
32.数据传递,根据元数据文件描述,将三个参数传递到python程序,程序将这三个参数按照层级解析后,获取本次etl数据同步的数据源、数据中间层、数据目标层连信息后,生成连接属性key/value并写入<user_home>/.kettle/kettle.properties配置文件,从而完成数据库连接信息的切换步骤,share.xml中定义的变量将根据key从该文件中获取value。
33.使用jenkins实现数据流程自动化,建立etl流程jenkinspipeline,在pipeline中建立gitcheckoutstage 1,switchenvstage 2,migration stage 3,在jenkins中完成作业的数据源动态切换,数据源切换,自动化调度作业:
34.stage 1:获取最新的etljob作业和python脚本源程序,
35.stage 2:执行python程序,根据参数解析元数据描述文件,向kettle.properties配置文件写入本次同步的环境信息,
36.stage 3:调用kitchen脚本文件(.bat/.sh),执行kettle作业文件。
37.具体实施方式及原理:
38.(1)为kettle作业新建共享的db连接信息
39.导入或打开kettle一个作业,在作业的菜单导航栏下,新建抽象的数据源层,数据中间层,数据目标层db连接信息,输入数据库连接属性并使用变量定义,共享该db连接信息,如图2所示。所有新建的共享db连接信息存放在<user_home>/.kettle/share.xml文件中。
40.(2)设计元数据文件,描述数据分层后不同数据源环境与数据库连接信息映射关系,
41.使用json格式的数据描述数据层、应用环境、数据库连接实例信息之间的层级,
42.关系为:层级一
‑
>层级二
‑
>层级三,
43.层级一:数据层名称,
44.层级二:本层下的应用环境,
45.层级三:数据库连接实例信息。
46.如图3所示,数据层有src(数据来源层)、od(数据清洗层),dest(数据目标层)。来源层、清洗层和目标层都含有多个数据库连接环境(应用环境),比如dev(开发环境)test(测试环境),prod(生成环境)preprod(预生产环境)。每个应用环境下又有多个数据库连接实例。
47.(3)数据传递
48.根据元数据文件描述,将三个参数传递到python程序,程序将这三个参数按照层级解析后,获取本次etl数据同步的数据源、数据中间层、数据目标层连信息后,生成连接属性key/value并写入<user_home>/.kettle/kettle.properties配置文件,从而完成数据库连接信息的切换步骤,share.xml中定义的变量将根据key值从该文件中获取value
49.如图4所示,为kettle.properties配置文件,定义了数据源层、清洗层、目标层中实际环境的数据库的地址,端口,数据库名称,用户名,密码等相关全局变量的键值对(key/value)。
50.(4)使用jenkins实现数据流程自动化
51.建立etl流程jenkinspipeline,在pipeline中建立gitcheckoutstage 1,switchenvstage 2,migration stage 3,在jenkins中完成作业的数据源动态切换,数据源切换,自动化调度作业;
52.stage 1:获取最新的etljob作业和python脚本源程序,
53.stage 2:执行python程序,根据参数解析元数据描述文件,向kettle.properties配置文件写入本次同步的环境信息,
54.stage 3:调用kitchen脚本文件(.bat/.sh),执行kettle作业文件。
55.基于上述,本发明kettle中数据库连接配置动态切换技术面向数据开发者,工具操作简单,对于专业性要求不高,etl数据同步业务场景发生变化后,源数据库和目标数据库的环境可以通过脚本快速切换同步环境配置,快捷方便,并可避免误操作,整个数据同步
etl过程完全由pipeline控制任务节点,完全自动化,可节约人工人本,提高效率。
56.由技术常识可知,本发明可以通过其它的不脱离其精神实质或必要特征的实施方案来实现。因此,上述公开的实施方案,就各方面而言,都只是举例说明,并不是仅有的。所有在本发明范围内或在等同于本发明的范围内的改变均被本发明包含。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1