一种基于噪声注意力图指导的微光图像增强方法
1.本发明属于图像处理技术领域,具体属于rgb真彩色图像恢复技术,涉及一种基于噪声注意力图指导的微光图像增强方法。
背景技术:
2.当今,图像可以提供大量的动态信息,通过图像传递信息在人们生活中扮演越来越重要的角色。在微光条件下获取的图像具有低对比度,低亮度以及低信噪比的“三低特性”,严重限制了图像内容的识别和判读;同时也会影响后续的图像处理任务,如图像分割、目标识别和视频监控等。尽管通过延长摄像机的曝光时间可以在一定程度上提高图像亮度,但在此期间易产生大量的图像噪声,因此,如何提高在微光环境下获取到的图像的质量,是计算机视觉领域近年来一个研究热点。
3.早期微光图像增强方法主要基于直方图均衡化(he)和retinex理论。he图像增强是以累计分布函数为基础的直方图修改方法,将图像直方图调整为均衡分布以拉伸图像动态范围,从而提高图像对比度;该类方法操作简单、效率高,但生成的图像易受伪影影响、真实感不强。而基于视网膜理论方法试图通过将输入图像分解为反射分量和照明分量来照亮图像,反射分量是场景的固有属性,而照明分量受环境照度的影响;基于视网膜理论方法通常增强微光图像的照明分量,以近似对应的正常光图像。模型中的参数需人工设定,无法自适应处理图像的多样性,并且针对较高噪声的图像处理效果较差,存在局部细节曝光不足或曝光过度等情况。伴随着人工智能理论的快速发展,近年来基于深度学习的微光图像增强算法陆续提出。尽管,基于深度学习的方法一定程度上弥补了传统方法的不足,对某一类图像集取得较好的增强效果,但是大多数深度学习微光增强方法严重依赖于数据集质量,且多假定暗光区域没有噪声,或者不考虑噪声在不同照明区域的分布。
4.实际上,以上先验知识与真实图像存在偏差,且完备的现实图像数据集获取难度大,这些都导致现有深度学习模型不能有效地抑制真实图像噪声,难以产生令人满意的视觉质量。
技术实现要素:
5.本发明的目的是提供一种基于噪声注意力图指导的微光图像增强方法,解决了现有技术中存在的微光图像低可见度、噪声污染严重的问题。
6.本发明所采用的技术方案是,一种基于噪声注意力图指导的微光图像增强方法,按照以下步骤具体实施:
7.步骤1、构建噪声估计模块,该噪声估计模块的输入为原始微光图像,大小为h*w*3;该噪声估计模块的输出是大小为h*w*1的特征图;
8.步骤2、构建增强网络模块,该增强网络模块的输入数据是步骤1的输出特征与原始微光图像,大小为h*w*4;该增强网络模块的输出是增强后的图像,大小为h*w*3;
9.增强网络模块包含了编码器、residual block以及解码器,编码器在噪声注意力
图指导下提取图像的浅层特征;residual block在编码器的基础上继续提取图像深层特征,为图像恢复提供有效的高级语义信息;解码器是在语义信息中恢复高分辨率图像,并进行通道压缩,输出增强结果。
10.本发明的有益效果是,能够有效的将微光图像恢复到正常光照条件下获取的图像,并有效去除图像中的噪声。本发明能够有效对单张微光图像进行增强,在噪声注意力图指导下拥有良好的去噪性能,且不会出现颜色失真以及能保留原图纹理细节,在不同数据集上具有很好的泛化能力。
附图说明
11.图1是本发明方法的流程框图;
12.图2是本发明方法中构建的噪声估计模块的结构流程图;
13.图3是本发明方法中构建的编码器的结构流程图;
14.图4是本发明方法中构建的residual block的结构流程图;
15.图5是本发明方法中构建的解码器的结构流程图。
具体实施方式
16.下面结合附图和具体实施方式对本发明进行详细说明。
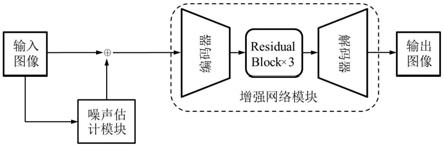
17.本发明主要基于噪声注意力图指导增强网络而提出的一种微光图像增强方法,整体思路为:首先,将原始微光图像输入噪声估计模块,噪声估计模块利用空间注意力机制有效地学习空间位置权重以聚焦原始微光图像不同区域中不同程度的噪声。将噪声估计模块得到的空间噪声位置权重和原始微光图像共同作为增强网络的输入,噪声估计模块得到的空间噪声位置权重用于指导增强网络更有效的去除图像中的噪声。增强网络在空间噪声位置权重图的指导下,对图像进行特征提取并恢复图像,并输出增强后的结果。
18.参照图1,本发明的方法基于噪声注意力图指导增强网络的微光图像增强网络(以下简称为网络),由噪声估计模块、增强网络模块组成。噪声估计模块利用空间注意力机制,将图像空间信息通过空间转换模型变换到另一个空间中提取关键位置信息,为每个位置生成权重掩码加权输出,从而将图像数据中噪声特征标记出来,为增强网络模块提供更有效的噪声信息。增强网络模块包含了编码器、3个residual block以及解码器,编码器以原始微光图像和噪声注意力图作为输入,在噪声注意力图的指导下提取图像的浅层特征。3个residual block用于提取图像深层特征,解码器采用反卷积将提取的语义信息恢复高分辨率图像,并输出增强结果。
19.本发明的方法,利用上述的网络框架及原理,按照以下步骤具体实施:
20.步骤1、构建噪声估计模块,该噪声估计模块的输入为原始微光图像,大小为h*w*3;该噪声估计模块的输出是大小为h*w*1的特征图。
21.参照图2,噪声估计模块主要作用就是对原始图像利用空间注意力机制,以权重的形式将图像数据中噪声特征标记出来。噪声估计模块的结构依次为:原始微光图像(input_image)作为输入图像
→
avg polling层(将avg polling层得到的特征图复制成3等份,每1等份分别输入不同的conv分支中)
→
conv分支层(包含3个相同结构的conv分支)
→
softmax层(将conv1分支与conv2分支的像素级相加,并采用softmax函数激活)
→
conv层(将
softmax层输出与conv3分支的像素级相加,并进行卷积)
→
interpolate层
→
输出特征。
22.其中,avg polling层为全局平均池化运算,用于增大感受野,便于获取更多的信息,卷积核大小为2*2,卷积步长为2,特征映射总数为3个;3个conv分支层均为卷积运算,获取三个代表不同信息的特征图,卷积核大小均为3*3,卷积步长均为1,特征映射总数均为32个;softmax层为softmax激活函数;conv层为卷积运算,卷积核大小为3*3,卷积步长为1,特征映射总数为1个;interpolate层为线性插值运算,将图像特征尺寸通过线性插值恢复至h*w。
23.步骤2、构建增强网络模块,该增强网络模块的输入数据是步骤1的输出特征与原始微光图像,大小为h*w*4;该增强网络模块的输出是增强后的图像,大小为h*w*3。
24.增强网络模块包含了编码器、residual block以及解码器三部分。编码器在噪声注意力图指导下提取图像的浅层特征;residual block在编码器的基础上继续提取图像深层特征,为图像恢复提供有效的高级语义信息,本发明实施例中循环运行3次residual block;解码器主要是在语义信息中恢复高分辨率图像,并进行通道压缩,输出增强结果。
25.参照图3,编码器的输入数据是步骤1的输出特征与原始微光图像,大小为h*w*4;编码器的输出的是提取的浅层图像特征,大小为h/6*w/6*128。
26.编码器的结构依次为:原始微光图像和步骤1的输出特征(input_image(feature))共同作为输入
→
conv1层
→
conv2层
→
conv3层
→
输出特征(output_feature)。
27.其中,conv1层、conv2层、conv3层均为卷积运算,卷积核大小均为3*3,卷积步长均为2,特征映射总数分别为32、64、128个。
28.参照图4,residual block的输入数据是编码器的输出特征,大小为h/6*w/6*128;residual block的输出是提取的深层图像特征,大小为h/6*w/6*128。
29.residual block的结构依次为:编码器的输出特征(input_feature)作为输入
→
bn层
→
relu层
→
第一个conv层
→
bn层
→
relu层
→
第二个conv层
→
输出特征(output_feature)。
30.其中,bn层为利用批量归一化函数对输入特征进行了归一化处理;relu层为激活函数处理;两个conv层均为卷积运算,卷积核大小均为3*3,卷积步长均为1。最后将输入的浅层特征与提取到的深层特征进行相加,共同作为residual block的输出。
31.参照图5,解码器的输入数据是residual block的输出特征,大小为h/6*w/6*128;解码器的输出为增强的图像,大小为h*w*3。
32.解码器的结构依次为:residual block的输出特征(input_feature)作为输入
→
deconv1层
→
deconv2层
→
deconv3层
→
输出图像(output_image),即成。
33.其中,deconv1、deconv2、deconv3层均为反卷积运算,卷积核大小均为3*3,反卷积步长均为2,特征映射总数分别为64、32、3个。
34.在训练基于噪声注意力图指导的微光图像增强网络时,考虑到l1损失函数在目标轮廓的对比度、均匀区域的平滑效果方面表现较好,同时ssim损失函数引入结构约束能够很好地恢复图像的结构和局部细节,感知损失函数能够约束真实图像和预测图像之间的差异,保持图像感知和细节的保真度。感知颜色损失旨在测量欧几里得空间中两幅图像之间的色差,促使网络生成与参考图像相似的颜色。本步骤中,将l1+ssim损失函数+感知损失函数+感知颜色函数组合在一起,作为基于噪声注意力图指导的微光图像增强网络的总损失
函数,表示为:
35.l
total
=(1
‑
λ
s
‑
λ
p
)l1+λ
s
l
ssim
+λ
p
l
perc
+λ
c
l
colour
36.式中,l1表示像素级别的l1范数损失,l
ssim
表示结构相似性损失,l
perc
表示感知损失,l
colour
表示感知颜色损失函数;λ
s
、λ
p
、λ
c
是相对应的系数,
37.取值区间为[0,1],优选λ
s
=0.2、λ
p
=0.1、λ
c
=0.1;
[0038]
l1范数损失公式为:其中的i
gt
代表真实图像,i
h
代表预测图像,l代表非零常数,取10
‑6;
[0039]
ssim结构相似性损失公式为μ
x
、μ
y
分别代表图像x、y的像素平均值;σ
xy
代表图像x、y乘积的标准差;分别代表图像x、y的方差;n代表图像样本总数,c1、c2为常量;
[0040]
感知损失函数公式为:
[0041][0042]
其中,i
gt
代表真实图像,i
h
代表预测图像,c
j
代表通道,h
j
和w
j
分别代表第j特征图的高度和宽度,代表在预先训练的vgg16模型中第j卷积层获得的特征图;
[0043]
感知颜色损失函数公式为l
colour
=δe(i
gt
,i
h
),i
gt
代表真实图像,i
h
代表预测图像,δe代表ciede2000颜色色差计算。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1