基于人脸感兴趣区域贡献度的跨数据集微表情识别方法
1.本发明属于图像识别技术领域,具体地说,涉及一种基于人脸感兴趣区域贡献度的跨数据集微表情识别方法。
背景技术:
2.表情是人类情绪状态的直观反映,通常可分为宏表情(macro-expression)和微表情(micro-expression)。过去数年来,学术界对于表情的识别研究主要集中在宏表情方面。与常规的宏表情不同,微表情是人类在经历情绪波动并试图掩盖内心情绪时不由自主流露出的一种快速且无意识的微小面部动作。它的特殊之处在于既无法被伪装,也没法被强行抑制。因此,微表情可以作为分析和判断人的真实情感和心理情绪的可靠依据,在临床诊断、谈判、教学评估、测谎和审讯等方面有着较强的实用价值和应用前景。
3.微表情的持续时间非常短,转瞬即逝,只有不到半秒钟。由微表情引起的脸部肌肉运动的幅度很小,只出现在几个较小的局部面部区域,并且通常不会在人脸的上半部和下半部同时出现。这使得微表情很难被人眼观察到,人工识别的准确率并不高。此外,人工识别微表情需要经过专业的培训并拥有丰富的分类经验,耗时费力,难以在现实场景中大规模推广和应用。基于社会的大量需求和技术的进步,最近几年,利用计算机视觉和模式识别技术实现微表情的自动鉴定,正日益受到科研人员的关注。
4.目前利用图像处理技术进行微表情识别的研究还相对较少,技术层面尚处在起步阶段。由于微表情和宏表情在持续时间、动作强度和出现的人脸区域等方面的不同,目前较为成熟的宏表情识别方法并不适用于微表情识别。
5.微表情自动识别的过程可分为两个阶段:首先是提取微表情特征,即从面部视频片段中提取有用的特征信息来描述视频片段所蕴含的微表情;然后是微表情分类,利用分类器对提取出的特征所属的情绪类别进行划分。这两个阶段中,特征的选择对于微表情识别尤为重要。因此,大多数微表情识别研究集中在特征提取部分,旨在通过设计可靠的微表情特征,来有效地描述微表情的细微变化,以便完成微表情识别任务。
6.要指出的是,微表情识别研究的发展很大程度上依赖于完善的人脸微表情数据集。通过回顾前人的研究工作,可以发现当前已存在的绝大多数微表情识别方法都是在训练样本和测试样本来自同一个数据集的情况下开发和评价的,此时可认为训练样本和测试样本遵循相同或相似的特征分布。但是显然,在现实应用中,训练样本和待识别样本往往来自两个完全不同的微表情数据集(分别称为源数据集和目标数据集),这两个数据集中的视频片段,在光照条件、拍摄设备、参数设置和背景环境等方面都会存在差异。因此,在这种情况下,由于异构的视频质量,训练样本和待识别样本会有很大的不同,使得它们的特征分布状态也存在较大的差异,导致现有微表情识别方法的识别效果大幅降低。
技术实现要素:
7.本发明针对现有技术中微表情识别时训练样本和待识别样本往往来自两个完全
不同的微表情数据集,特征分布状态也存在较大的差异,导致现有微表情识别方法的识别效果大幅降低的技术问题,提出了一种基于人脸感兴趣区域贡献度的跨数据集微表情识别方法,可以解决上述问题。
8.为实现上述发明目的,本发明采用下述技术方案予以实现:
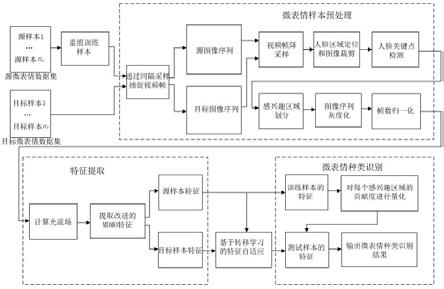
9.一种基于人脸感兴趣区域贡献度的跨数据集微表情识别方法,包括:
10.s1、微表情样本预处理步骤,包括:
11.s11、分别对源微表情数据集和目标微表情数据集进行采样,捕捉视频帧,分别按顺序排列得到源图像序列和目标图像序列;
12.s12、对所述源图像序列和目标图像序列进行降采样,调整图像的尺寸;
13.s13、对图像序列中人脸区域定位,以及对各图像序列进行面部图像裁剪,得到源面部图像序列和目标面部图像序列;
14.s14、对每个面部图像序列中的第一帧图像进行人脸地标点检测,得到描述人脸关键位置的q个特征点;
15.s15、利用所述特征点的坐标将面部图像划分成n个特定的互不重叠但又紧密相邻的感兴趣区域,其中,n<q,且q,n均为正整数;
16.s16、将各面部图像序列灰度化;
17.s2、提取主方向平均光流特征步骤,计算各面部图像序列的光流场,提取mdmo特征,其中mdmo特征为基于光流的主方向平均光流特征;
18.s3、根据源面部图像序列的特征分布特点,对目标样本的特征结构进行约束,目标样本是目标微表情数据集中的测试样本;
19.s4、对源面部图像序列的mdmo特征建立组稀疏模型,对每个感兴趣区域的贡献度进行量化;
20.s5、使用所述组稀疏模型对所述目标面部图像序列进行微表情种类识别,输出识别结果。
21.进一步的,步骤s13包括:
22.对每个图像序列中的第一帧图像进行人脸检测,以定位面部区域,以原始矩形包围框的中心点作为基准,对该图像的前脸选框按照同等比例向四周进行外扩,得到面部区域;
23.根据检测出的面部区域的位置和尺寸,对该图像序列中的其他图像进行区域裁剪操作,得到源面部图像序列和目标面部图像序列。
24.进一步的,步骤s15中根据人脸动作编码系统中的面部动作单元划分感兴趣区域,每个感兴趣区域都和面部动作单元相对应。
25.进一步的,步骤s16之后还包括:
26.s17、对各面部图像序列的帧数归一化,采用时间插值模型对每个面部图像序列的帧数进行归一化。
27.进一步的,步骤s2中计算各面部图像序列的光流场的方法为:
28.计算所述面部图像序列中除第一帧之外的每一帧fi(i>1)和第一帧f1之间的光流向量[v
x
,vy],并转换为极坐标(ρ,θ)的表达形式,其中v
x
和vy分别是光流运动速度的x分量和y分量,ρ和θ分别是光流运动速度的幅值和光流运动速度的角度。
[0029]
进一步的,步骤s2中提取mdmo特征的方法为:
[0030]
在每一帧fi(i>1)中,每一个感兴趣区域(k=1,2,
…
,n)中所有的光流向量,根据它们的角度分类为8个方向的bins,选择光流向量数量最多的bin作为主方向,记作bmax;
[0031]
计算所有属于bmax的光流向量的平均值,将其定义为的主方向光流,符号化为是光流运动速度的平均幅值,是光流运动速度的平均角度;
[0032]
通过一个原子光流特征ψi来表示每一帧fi(i>1):
[0033][0034]
ψi的维数是2n,一个m帧的微表情视频片段γ可被表示为一组原子光流特征:
[0035]
γ=(ψ2,ψ3,
…
,ψm)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0036]
对所有ψi(i>1)中的(k=1,2,
…
,n)取平均,即:
[0037][0038]
为第k个感兴趣区域的主方向平均光流向量;
[0039][0040]
对向量中的幅值做归一化处理:
[0041][0042]
将公式(5)中的代入公式(4)并替换掉其中的得到一个新的2n维行向量作为描述视频片段γ的mdmo特征:
[0043][0044]
进一步的,步骤s3中对目标面部图像序列的特征结构进行约束的方法为:
[0045]
源面部图像序列的mdmo特征为目标面部图像序列的mdmo特征为其中d为特征向量的维数,ns和n
t
分别是源样本的个数和目标样本的个数,源样本是源微表情数据集中的训练样本,对所述目标样本的特征变换满足以下两个要求:
[0046]
s31、源样本的特征在此过程中应保持不变,即需要满足下面的条件:
[0047][0048]
其中g是目标样本特征变换算子;
[0049]
s32、采用函数fg(xs,x
t
)作为公式(7)的正则项,得到目标函数:
[0050][0051]
其中λ是权重系数,用于调节目标函数中两项的平衡;
[0052]
目标样本特征变换算子g通过核映射和线性投影操作确定。
[0053]
进一步的,目标样本特征变换算子g的确定方法为:
[0054]
通过一个核映射算子φ将源样本从原始特征空间投影到希尔伯特空间;
[0055]
通过一个投影矩阵φ(c)∈r
∞
×d将源样本从希尔伯特空间变换回原始特征空间,g可以表示为g(
·
)=φ(c)
t
φ(
·
)的形式;
[0056]
公式(8)中的目标函数改写为:
[0057][0058]
最小化目标函数在希尔伯特空间内的最大均值差异距离mmd;把mmd当作正则项fg(xs,x
t
):
[0059][0060]
其中h代表希尔伯特空间,1s和1
t
分别是长度为ns和n
t
且元素全为1的列向量;
[0061]
将公式(10)中的mmd变换为如下形式,作为fg(xs,x
t
):
[0062][0063]
将公式(11)中的fg(xs,x
t
)带入公式(9),则目标函数变为:
[0064][0065]
公式(12)中所示的优化问题,可以通过计算核函数代替核空间中的内积运算,将其转换为可求解形式,包括:令φ(c)=[φ(xs),φ(x
t
)]p,其中线性系数矩阵则公式(12)被改写为如下形式,作为最终的目标函数:
[0066][0067]
其中四个核矩阵的计算公式为k
ss
=φ(xs)
t
φ(xs),k
st
=φ(xs)
t
φ(x
t
),k
ts
=φ(x
t
)
t
φ(xs)和k
tt
=φ(x
t
)
t
φ(x
t
);
[0068]
在公式(13)中添加了一个关于p的l1范数作为目标函数的约束项,即其中pi是p的第i列,p的稀疏性通过加权系数μ调节。
[0069]
进一步的,步骤s4中采用组作为稀疏表示单位,每个组由一个人脸感兴趣区域的mdmo特征矩阵构成,实现对每个人脸感兴趣区域的贡献度进行量化,包括:
[0070]
m个微表情训练样本对应的mdmo特征矩阵为x=[x1,
…
,xm]∈rd×m,其中d是特征向量的维度,d=2n;
[0071]
采用标签向量表示微表情的类别,包括:
[0072]
令l=[l1,
…
,lm]∈rc×m表示特征矩阵x对应的标签矩阵,其中c是微表情的种类数;l的第k列lk=[l
k,1
,
…
,l
k,c
]
t
(1≤k≤m)是一个列向量,其每个元素根据如下规则取值0或1:
[0073][0074]
上述这些标签向量是一组规范正交基,将其扩张成一个包含标签信息的向量空间,引入一个投影矩阵u来建立样本的特征空间和标签空间的联系,所述投影矩阵u通过求解目标函数来得到:
[0075][0076]
公式(15)中的u
t
x通过矩阵分解改写为其中n是人脸感兴趣区域的数量,n=36;xi是第i个感兴趣区域的mdmo特征矩阵;ui是xi对应的子投影矩阵;用置换公式(15)中的u
t
x,可以得到等价公式:
[0077][0078]
在公式(16)中为每个感兴趣区域引入一个加权系数βi,并添加一个有关βi的非负l1范数作为正则项,形成线性的组稀疏模型:
[0079][0080]
其中μ是一个权衡系数,决定着学习到的权重向量β中非零元素的个数;
[0081]
把所述组稀疏模型的的线性内核扩展为非线性内核,利用非线性映射φ:rd→
f把xi和ui映射到核空间f,也就是用和分别替换公式(17)中的xi和ui:
[0082][0083]
通过核函数取代核空间中的内积运算,在核空间f中,的每一列可以表示为即的线性组合,其中pj是线性系数向量;故可由表示,其中p=[p1,
…
,pc];
[0084]
将代入公式(18),并增加一个关于p的l1范数作为约束项,以确保pj的稀疏性并避免在优化目标函数时发生过拟合,得到组稀疏模型的最终形式:
[0085][0086]
其中是格拉姆矩阵;λ是加权系数,用于调节p的稀疏性;
[0087]
采用交替方向法求解公式(19)的优化问题,即:交替迭代更新参数p和βi的值,直到目标函数收敛。
[0088]
进一步的,步骤s5包括:
[0089]
对源微表情数据集中的训练样本,通过迭代学习到最优的参数值和后,采用组稀疏模型作为分类器对目标数据集中的测试样本进行标签向量的预测,即微表情的种类
识别;
[0090]
对于一个测试样本,设它的特征向量为x
t
∈r
72
×1,可通过求解下面的优化问题,来预测该样本的标签向量l
t
:
[0091][0092]
其中可通过组稀疏模型学习时选择的核函数进行计算;
[0093]
假定求得的标签向量为则该测试样本的微表情种类为其中表示的第k个元素。
[0094]
与现有技术相比,本发明的优点和积极效果是:
[0095]
本发明的基于人脸感兴趣区域贡献度的跨数据集微表情识别方法,通过根据源面部图像序列的特征分布特点,对目标样本的特征结构进行约束,缩小来自不同微表情数据集的训练样本和测试样本的mdmo特征分布差异,识别准确率更高,而且针对不同目标数据集和不同微表情类别的分类稳定性更好,对具有不同特点的测试样本均表现出较强的适应性,能够大幅度提升跨数据集微表情识别的性能。
[0096]
结合附图阅读本发明的具体实施方式后,本发明的其他特点和优点将变得更加清楚。
附图说明
[0097]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0098]
图1是本发明提出的基于人脸感兴趣区域贡献度的跨数据集微表情识别方法的一种实施例的原理方框图;
[0099]
图2是实施例一中对人脸感兴趣区域划分的示意图;
[0100]
图3是采用casmeii-》casme数据集对实施例一中方法的识别结果图;
[0101]
图4是采用casmeii-》smic-hs数据集对实施例一中方法的识别结果图;
[0102]
图5是采用smic-hs-》casme数据集对实施例一中方法的识别结果图;
[0103]
图6是采用smic-hs-》casmeii数据集对实施例一中方法的识别结果图;
[0104]
图7是采用smic-hs-》samm数据集对实施例一中方法的识别结果图。
具体实施方式
[0105]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0106]
需要说明的是,在本发明的描述中,术语“上”、“下”、“左”、“右”、“竖”、“横”、“内”、“外”等指示的方向或位置关系的术语是基于附图所示的方向或位置关系,这仅仅是为了便于描述,而不是指示或暗示所述装置或元件必须具有特定的方位、以特定的方位构造和操
作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0107]
实施例一
[0108]
本实施例提出了一种基于人脸感兴趣区域贡献度的跨数据集微表情识别方法,如图1所示,包括:
[0109]
s1、微表情样本预处理步骤,包括:
[0110]
s11、分别对源微表情数据集和目标微表情数据集进行采样,捕捉视频帧,分别按顺序排列得到源图像序列和目标图像序列;
[0111]
s12、对所述源图像序列和目标图像序列进行降采样,调整图像的尺寸;
[0112]
s13、对图像序列中人脸区域定位,以及对各图像序列进行面部图像裁剪,得到源面部图像序列和目标面部图像序列;
[0113]
s14、对每个面部图像序列中的第一帧图像进行人脸地标点检测,得到描述人脸关键位置的q个特征点;
[0114]
s15、利用所述特征点的坐标将面部图像划分成n个特定的互不重叠但又紧密相邻的感兴趣区域,其中,n<q,且q,n均为正整数;
[0115]
s16、将各面部图像序列灰度化;
[0116]
s2、提取主方向平均光流特征步骤,计算各面部图像序列的光流场,提取mdmo特征,其中mdmo特征为基于光流的主方向平均光流特征;
[0117]
s3、根据源面部图像序列的特征分布特点,对目标样本的特征结构进行约束,目标样本是目标微表情数据集中的测试样本;
[0118]
s4、对源面部图像序列的mdmo特征建立组稀疏模型,对每个感兴趣区域的贡献度进行量化;
[0119]
s5、使用所述组稀疏模型对所述目标面部图像序列进行微表情种类识别,输出识别结果。
[0120]
其中,微表情数据集中的样本指的是一个完整的带有某种情绪的微表情视频片段,包含起始帧(onset frame)、顶点帧(apex frame)和终止帧(offset frame)3个重要的视频帧。其中,起始(onset)指的是微表情开始出现的瞬间;顶点(apex)指的是微表情幅度最大的瞬间;终止(offset)指的是微表情消失的瞬间。
[0121]
步骤s11中,首先将人脸微表情视频片段转换为图像序列。对于一个微表情视频片段γ,通过设置采样间隔时间,从视频片段中截取连续的若干幅静态图像,即视频帧。
[0122]
然后通过间隔采样的方式减少冗余的帧数。假定原始帧速率为m帧/秒,视频时长为tvid秒,则该视频总共有m
×
tvid帧。设采样周期为tsam秒,则对应的帧数为m
×
tsam,这意味着每间隔m
×
tsam帧提取一帧。这样,在得到的图像序列中,仅包含[tvid/tsam]帧,其中[]是取整函数。
[0123]
步骤s12中,可对所有图像序列中的视频帧进行基于双三次插值(bicubic interpolation)的降采样处理,将视频帧的宽度统一调整到500像素,并保持纵横比不变。
[0124]
由于微表情视频片段的持续时间较短,头部在每个图像序列连续多帧中的位置移动(包括平移和旋转)幅度非常微小,已经大致对齐;同时,为了提升算法的效率,本实施例只对每个图像序列中的第一帧图像,采用masayuki tanaka提出的人脸检测子进行人脸检
测,以便定位面部区域。该检测算法不仅能够高精度地检测同一图像中出现的多张前脸(frontal face),而且能够同时检测出其各自对应的左眼、右眼、嘴巴和鼻子。特别是当输入图像旋转或者图像中人的头部倾斜时,检测效果依然优异。
[0125]
需要指出的是,该算法只能针对三颜色通道的图像进行检测,而samm数据集提供的是单颜色通道的灰度图像序列,因此在实际操作时,将其全部转换成三通道形式。此外,经过大量实验,发现不同数据集中的照明条件、背景复杂度和受试者的肤色、脸型等客观条件存在差异,会使得同一参数设置下的人脸检测算法无法对所有样本图像序列中的前脸区域进行精准定位,比如,有个别受试者经过检测确定的脸部区域中,缺失了一部分下巴。为解决这一问题,本实施例以原始矩形包围框的中心点为基准,对所有样本图像序列中的前脸选框按照同等比例向四周进行了适当的外扩,以确保得到合适大小的面部区域。
[0126]
对于每一个图像序列,根据第一帧中检测出的面部区域的位置和尺寸,对所有帧进行区域裁剪(crop)操作,形成新的面部图像序列。
[0127]
步骤s13包括:
[0128]
对每个图像序列中的第一帧图像进行人脸检测,以定位面部区域,以原始矩形包围框的中心点作为基准,对该图像的前脸选框按照同等比例向四周进行外扩,得到面部区域。本实施例中可采用masayuki tanaka检测子进行人脸检测,以定位面部区域。
[0129]
根据检测出的面部区域的位置和尺寸,对该图像序列中的其他图像进行区域裁剪操作,得到源面部图像序列和目标面部图像序列。
[0130]
如图2所示,为1个微表情数据集上使用dfrm算法进行人脸地标点检测的例子,其中“+”标记符代表检测出的关键特征点。步骤s14中采用依赖于纹理模型的dfrm算法(discriminative fitting of response map)对每个面部图像序列中的第一帧图像进行人脸地标点检测,以便得到描述人脸关键位置的q个特征点。本实施例中以得到66特征点为例进行说明。
[0131]
步骤s15中根据人脸动作编码系统中的面部动作单元划分感兴趣区域,每个感兴趣区域都和面部动作单元相对应。
[0132]
人脸感兴趣区域的划分有多种策略,但总的原则是既不能太稠密也不能太稠密。如果划分得过于稠密,有可能会引入冗余的信息;如果划分得过于稀疏,则又有可能遗漏有用的信息。
[0133]
由于微表情只涉及面部局部肌肉的收缩或者舒张运动,本实施例通过使用由dfrm算法获得的关键特征点的坐标,进一步将面部区域划分成36个特定的互不重叠但又紧密相邻的感兴趣区域,同时排除了一些无关区域。
[0134]
通过使用由dfrm算法获得的关键特征点的坐标,进一步将面部区域划分成n个特定的互不重叠但又紧密相邻的感兴趣区域,同时排除一些无关区域。本实施例中n取36,如图2所示,这些感兴趣区域的位置和大小由66个特征点唯一确定,划分依据是人脸动作编码系统(facial action coding system,facs)中的面部动作单元(action unit,au)。每个感兴趣区域都和部分面部动作单元相对应,能够较好地体现脸部肌肉运动产生的表观变化。所有感兴趣区域的组合可以表现几乎所有类型的微表情。
[0135]
步骤s16把全部的彩色样本图像序列转换为灰度图像序列,以避免其中的颜色信息受到光照的影响。
[0136]
步骤s16之后还包括:
[0137]
s17、对各面部图像序列的帧数归一化,采用时间插值模型对每个面部图像序列的帧数进行归一化。
[0138]
本实施例中可利用zhou等人提出的时间插值模型(temporal interpolation model,tim)对每个样本的帧数进行归一化,从由人脸图像序列建立的低维流形结构中插值所需的帧数,从而避免帧数过少或过多。
[0139]
步骤s2中计算各面部图像序列的光流场的方法为:
[0140]
计算所述面部图像序列中除第一帧之外的每一帧fi(i>1)和第一帧f1之间的光流向量[v
x
,vy],并转换为极坐标(ρ,θ)的表达形式,其中v
x
和vy分别是光流运动速度的x分量和y分量,ρ和θ分别是光流运动速度的幅值和光流运动速度的角度。
[0141]
步骤s2中提取经过改进的基于光流的主方向平均光流(mdmo)特征。
[0142]
作为一个优选的实施例,提取mdmo特征的方法为:
[0143]
使用基于hampel estimator的局部光流(robust local optical flow,rlof)算法计算灰度图像序列的光流场,从而定量估计受试者面部肌肉的运动。
[0144]
对于一个由高速摄像机拍摄的具有m帧的微表情图像序列(f1,f2,
…
,fm),考虑到相邻的两帧之间的变化非常微小,呈现的光流变化不太明显,因此,本实施例计算除第一帧之外的每一帧fi(i>1)和第一帧f1之间的光流向量[v
x
,vy](其中v
x
和vy分别是光流运动速度的x分量和y分量),并将笛卡尔形式的坐标转换为极坐标(ρ,θ)形式(其中ρ和θ分别是幅值和角度),便于后续的特征提取。
[0145]
在每一帧fi(i>1)中,每一个感兴趣区域(k=1,2,
…
,n)中所有的光流向量,根据它们的角度分类为8个方向的bins,选择光流向量数量最多的bin作为主方向,记作bmax;
[0146]
计算所有属于bmax的光流向量的平均值,将其定义为的主方向光流,符号化为是光流运动速度的平均幅值,是光流运动速度的平均角度;
[0147]
通过一个原子光流特征ψi来表示每一帧fi(i>1):
[0148][0149]
ψi的维数是2n,一个m帧的微表情视频片段γ可被表示为一组原子光流特征:
[0150]
γ=(ψ2,ψ3,
…
,ψm)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0151]
对所有ψi(i>1)中的(k=1,2,
…
,n)取平均,即:
[0152][0153]
为第k个感兴趣区域的主方向平均光流向量。上式表示对当前视频片段中所有帧(从第2帧开始)的相同位置处的感兴趣区域(均为第k个roi)的主方向光流向量取平均,得到第k个roi的主方向平均光流向量。
[0154][0155]
考虑到不同视频片段中主方向的幅值差异可能较大,对向量中的幅值做归一化
处理:
[0156][0157]
将公式(5)中的代入公式(4)并替换掉其中的得到一个新的2n维行向量作为描述视频片段γ的mdmo特征:
[0158][0159]
步骤s3采用迁移学习的方法来缩小来自不同微表情数据集的训练样本和测试样本的mdmo特征分布差异。
[0160]
假设目标样本的标签信息是全部未知的,需要根据源样本的特征分布特点,对目标样本的特征结构进行改造。
[0161]
步骤s3中对目标面部图像序列的特征结构进行约束的方法为:
[0162]
源面部图像序列的mdmo特征为目标面部图像序列的mdmo特征为其中d为特征向量的维数,ns和n
t
分别是源样本的个数和目标样本的个数,源样本是源微表情数据集中的训练样本,对所述目标样本的特征变换满足以下两个要求:
[0163]
s31、源样本的特征在此过程中应保持不变,即需要满足下面的条件:
[0164][0165]
其中g是目标样本特征变换算子;
[0166]
s32、g对目标样本特征进行变换后,得到的新的重构的目标样本特征和源样本的特征应该具有相同或相似的分布特点。为此,采用函数fg(xs,x
t
)作为公式(7)的正则项,得到目标函数:
[0167][0168]
其中λ是权重系数,用于调节目标函数中两项的平衡;
[0169]
目标样本特征变换算子g通过核映射和线性投影操作确定。
[0170]
优选的,目标样本特征变换算子g的确定方法为:
[0171]
首先通过一个核映射算子φ将源样本从原始特征空间投影到希尔伯特空间(hilbert space);然后再通过一个投影矩阵φ(c)∈r
∞
×d将源样本从希尔伯特空间变换回原始特征空间。基于此,g可以表示为g(
·
)=φ(c)
t
φ(
·
)的形式;
[0172]
公式(8)中的目标函数改写为:
[0173][0174]
为了消除源样本和目标样本之间的特征分布差异,可以最小化目标函数在希尔伯特空间内的最大均值差异距离mmd;把mmd当作正则项fg(xs,x
t
):
[0175]
[0176]
其中h代表希尔伯特空间,1s和1
t
分别是长度为ns和n
t
且元素全为1的列向量;然而,直接将mmd作为fg(xs,x
t
),需要学习最优的核映射算子φ,显然是十分困难的。为此,将公式(10)中的mmd变换为如下形式,作为fg(xs,x
t
):
[0177][0178]
可以证明,最小化公式(10)中的mmd等效于最小化公式(11)中的fg(xs,x
t
)。这样,fg(xs,x
t
)只需要学习最优的φ(c)即可,而φ(c)也是公式(9)中需要学习的变量。
[0179]
将公式(11)中的fg(xs,x
t
)带入公式(9),则目标函数变为:
[0180][0181]
公式(12)中所示的优化问题,可以通过计算核函数代替核空间中的内积运算,将其转换为可求解形式,包括:令φ(c)=[φ(xs),φ(x
t
)]p,其中线性系数矩阵则公式(12)被改写为如下形式,作为最终的目标函数:
[0182][0183]
其中四个核矩阵的计算公式为k
ss
=φ(xs)
t
φ(xs),k
st
=φ(xs)
t
φ(x
t
),k
ts
=φ(x
t
)
t
φ(xs)和k
tt
=φ(x
t
)
t
φ(x
t
);
[0184]
为防止在优化目标函数时出现过拟合,在公式(13)中添加了一个关于p的l1范数作为目标函数的约束项,即其中pi是p的第i列,p的稀疏性通过加权系数μ调节。
[0185]
步骤s4根据来自36个人脸感兴趣区域的72维mdmo特征及其微表情标签信息建立组稀疏模型,采用组作为稀疏表示单位,每个组由一个人脸感兴趣区域的mdmo特征矩阵构成,实现对每个人脸感兴趣区域的贡献度进行量化,包括:
[0186]
m个微表情训练样本对应的mdmo特征矩阵为x=[x1,
…
,xm]∈rd×m,其中d是特征向量的维度,d=2n;
[0187]
采用标签向量表示微表情的类别,包括:
[0188]
令l=[l1,
…
,lm]∈rc×m表示特征矩阵x对应的标签矩阵,其中c是微表情的种类数;l的第k列lk=[l
k,1
,
…
,l
k,c
]
t
(1≤k≤m)是一个列向量,其每个元素根据如下规则取值0或1:
[0189][0190]
上述这些标签向量是一组规范正交基,将其扩张成一个包含标签信息的向量空间,引入一个投影矩阵u来建立样本的特征空间和标签空间的联系,所述投影矩阵u通过求解目标函数来得到:
[0191]
[0192]
公式(15)中的u
t
x通过矩阵分解改写为其中n是人脸感兴趣区域的数量,n=36;xi是第i个感兴趣区域的mdmo特征矩阵;ui是xi对应的子投影矩阵;用置换公式(15)中的u
t
x,可以得到等价公式:
[0193][0194]
为了从数值上衡量每一个人脸感兴趣区域对于微表情发生的具体贡献,在公式(16)中为每个感兴趣区域引入一个加权系数βi,并添加一个有关βi的非负l1范数作为正则项,形成线性的组稀疏模型:
[0195][0196]
其中μ是一个权衡系数,决定着学习到的权重向量β中非零元素的个数;
[0197]
公式(17)中的正则项有两个好处。首先,在学习模型期间,对于微表情识别几乎没有贡献的感兴趣区域将会被舍弃(其对应的系数βi为0);其次,每一个被筛选出的感兴趣区域将会被分配一个正有理数的权值,用于衡量它的贡献度。
[0198]
为提高组稀疏模型的分类性能,进一步把所述组稀疏模型的的线性内核扩展为非线性内核,利用非线性映射φ:rd→
f把xi和ui映射到核空间f,也就是用和分别替换公式(17)中的xi和ui:
[0199][0200]
通过核函数取代核空间中的内积运算,在核空间f中,的每一列可以表示为即的线性组合,其中pj是线性系数向量;故可由表示,其中p=[p1,
…
,pc];
[0201]
将代入公式(18),并增加一个关于p的l1范数作为约束项,以确保pj的稀疏性并避免在优化目标函数时发生过拟合,得到组稀疏模型的最终形式:
[0202][0203]
其中是格拉姆矩阵;λ是加权系数,用于调节p的稀疏性;
[0204]
采用交替方向法求解公式(19)的优化问题,即:交替迭代更新参数p和βi的值,直到目标函数收敛。
[0205]
步骤s5包括:
[0206]
对源微表情数据集中的训练样本,通过迭代学习到最优的参数值和后,采用组稀疏模型作为分类器对目标数据集中的测试样本进行标签向量的预测,即微表情的种类识别;
[0207]
对于一个测试样本,设它的特征向量为x
t
∈r
2n
×1,可通过求解下面的优化问题,来预测该样本的标签向量l
t
:
[0208][0209]
其中可通过组稀疏模型学习时选择的核函数进行计算;
[0210]
假定求得的标签向量为则该测试样本的微表情种类为其中表示的第k个元素。
[0211]
为了验证本发明提出的基于人脸感兴趣区域贡献度量化(facial rois contribution quantification,简称frcq)的跨数据集微表情识别算法的有效性,本实施例在4个微表情数据集casme、casmeii、smic-hs和samm上,进行了大量两两一组的跨数据集微表情识别实验。其中一个充当源数据集,提供训练样本;另一个充当目标数据集,提供测试样本。
[0212]
本实施例将frcq算法和较为先进的三种微表情识别算法进行了比较,实验对比结果如图3至图7所示。三种对比方法均未对提取出的特征做任何变换,并且都使用了目前应用广泛的具有多项式核的支持向量机作为分类器。其中,对比方法1提取整个面部区域的lbp-top特征(简称lbp-top-whole+svm);对比方法2分别提取每个人脸roi(共36个)的lbp-top特征并连接成组合特征(简称lbp-top-rois+svm);对比方法3提取面部的原始mdmo特征(简称mdmo+svm)。
[0213]
由于篇幅和空间所限,这里仅展示其中一部分实验结果。在下面的叙述中,用符号“a-》b”来表示从源数据集a至目标数据集b的微表情识别实验。
[0214]
a.casmeii-》casme,如图3所示,为不同方法在从源数据集casme ii至目标数据集casme的跨数据集微表情识别实验中的对比结果。从上到下依次为混淆矩阵、f1-measure柱状图,从左至右的识别准确率分别为50%、20.31%、53.13%和67.19%。
[0215]
b.casmeii-》smic-hs,如图4所示,为不同方法在从源数据集casme ii至目标数据集smic-hs的跨数据集微表情识别实验中的对比结果。从上到下依次为混淆矩阵、f1-measure柱状图,从左至右的识别准确率分别为35.48%、26.45%、46.45%和49.03%。
[0216]
c.smic-hs-》casme,如图5所示,为不同方法在从源数据集smic-hs至目标数据集casme的跨数据集微表情识别实验中的对比结果。从上到下依次为混淆矩阵、f1-measure柱状图,从左至右的识别准确率分别为50.00%、46.88%、57.81%和62.50%。
[0217]
d.smic-hs-》casmeii,如图6所示,为不同方法在从源数据集smic-hs至目标数据集casme ii的跨数据集微表情识别实验中的对比结果。从上到下依次为混淆矩阵、f1-measure柱状图,从左至右的识别准确率分别为22.12%、27.43%、63.72%和71.68%。
[0218]
e.smic-hs-》samm,如图7所示,为不同方法在从源数据集smic-hs至目标数据集samm的跨数据集微表情识别实验中的对比结果。从上到下依次为混淆矩阵、f1-measure柱状图,从左至右的识别准确率分别为32.33%、43.61%、45.11%和51.13%。
[0219]
在上面的5组对比实验中,为定量比较和分析每种方法针对积极的(positive)、消极的(negative)和惊讶(surprise)的3类微表情的识别效果和整体识别效果,本实施例分别绘制了混淆矩阵和f1-measure柱状图,并给出了每种方法的整体识别准确率。
[0220]
通过观察给出的各个混淆矩阵,不难发现,和目前较为先进的“lbp-top或mdmo特征+支持向量机”的组合方法相比,本发明提出的frcq法对于3类微表情的识别准确率始终
保持在较高水平,类间的数值波动性很小。特别是在casme ii-》casme和smic-hs-》casme ii的两组实验中,frcq法针对3类微表情的识别准确率均超过了60%。而在整体识别准确率方面,frcq法在全部5组对比实验中都取得了所在组的最高值。
[0221]
在图3至图7所示的f1-measure柱状图中,4种识别方法各有所长,每种方法都有自己擅长分类的特定的微表情类别。但是除frcq法外,其余3种方法的f1-measure值均不够稳定,出现了不同程度的波动。这说明它们对目标数据集中微表情图像序列的自适应性不好,分类的优劣呈现一定的偶然性,并不适合对和源样本差异较大的目标样本进行分类。显然,frcq法的f1-measure值整体要高于其他方法,并且始终保持较高的数值。这表明其分类质量更高,对面部细节特征的微小差异区分度较好;同时分类性能更加稳定,鲁棒性更强,能够顺利完成跨数据集分类任务。
[0222]
本实施例在casme、casme ii、smic-hs和samm这4个自发的微表情数据集上进行了大量两两一组的跨数据集微表情识别实验,实验结果表明,本发明提出的识别策略是有效的,和目前已经存在的几种先进的识别方法相比,识别效果更佳:不仅识别准确率更高,而且针对不同目标数据集和不同微表情类别的分类稳定性更好,对具有不同特点的测试样本均表现出较强的适应性,能够大幅度提升跨数据集微表情识别的性能。
[0223]
本发明提出的微表情识别方案为大规模微表情视频片段的实时自动分析乃至自然场景下的实际应用提供了可能,在临床诊断、社交互动和国家安全等诸多领域具有重要的科学价值和广阔的应用前景。
[0224]
以上实施例仅用以说明本发明的技术方案,而非对其进行限制;尽管参照前述实施例对本发明进行了详细的说明,对于本领域的普通技术人员来说,依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明所要求保护的技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1