一种基于国产CPU和OS的人工智能加速卡调度方法及装置与流程
一种基于国产cpu和os的人工智能加速卡调度方法及装置
技术领域
1.本发明涉及技术资源调度领域,具体的说是一种基于国产cpu和os的人工智能加速卡调度方法及装置。
背景技术:
2.随着国内企业信息化和深度学习的发展,很多企业和政府在实际的业务中用到越来越多的人工智能技术。由于国产cpu和操作系统软硬件环境在指令集、操作系统层面的特殊性,应用gpu进行人工智能推理还具有一定的技术难度。比如人脸识别技术常被公司和政府机构用来做打卡、门禁、口罩检测等功能,随着摄像头数量的增加,如何快速准确的进行识别成为现在迫切需要解决的问题。
技术实现要素:
3.本发明针对目前技术发展的需求和不足之处,提供一种基于国产cpu和os的人工智能加速卡调度方法及装置。
4.首先,本发明提供一种基于国产cpu和os的人工智能加速卡调度方法,解决上述技术问题采用的技术方案如下:
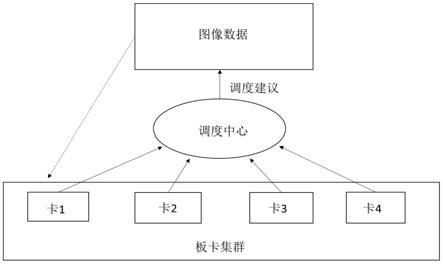
5.一种基于国产cpu和os的人工智能加速卡调度方法,其实现过程涉及基于国产cpu和os的服务器、部署于服务器的多张人工智能加速卡、部署于集群管理工具的调度中心;
6.首先,将服务器作为推送视频流的客户端,人工智能加速卡作为监听客户端端口的tcp服务端;
7.随后,建立tcp连接池,调度中心监控tcp连接池的剩余连接数;
8.最后,客户端需要处理数据时,向调度中心发起请求,调度中心根据用户选择的调度策略给客户端分配tcp连接,客户端即可通过分配的tcp连接将采集的图像发送至相应的人工智能加速卡。
9.具体的,所涉及调度策略包括最少资源占比策略、加速卡亲和策略;
10.(a)所述最少资源占比策略由人工智能加速卡的利用率和模型数来决定,采用以下分段函数对人工智能加速卡的利用率进行处理:
[0011][0012][0013]
其中,usage表示人工智能加速卡的利用率,其范围是0
‑
1,这里只用sin函数
部分,所以需要对利用率进行变换;当人工智能加速卡利用率大于80%时,速度会急速下降,系数是根据测试得到的;p表示人工智能加速卡的利用率;
[0014]
(b)采用加速卡亲和策略时,数据会依次发送给每张人工智能加速卡,人工智能加速卡在返回结果时会将计算时间返回给调度中心;调用中心会根据上一次的计算时间给出相应的概率,然后选取概率最大的人工智能加速卡作为目标加速卡;但当某张指定人工智能加速卡的利用率高于80%时,调度中心会为其更换目标加速卡;当所有人工智能加速卡利用率都高于80%时,调度中心会选择最初的概率最大的人工智能加速卡。
[0015]
更具体的,所涉及调度中心监控tcp连接池的剩余连接数,同时收集运行在人工智能加速卡的模型及其利用率;
[0016]
在开启人工智能加速卡的亲和策略时,所述调度中心还会收集人工智能加速卡处理数据的速度,以便根据人工智能加速卡的实际运行情况,合理分配资源。
[0017]
更具体的,所涉及调度中心监控tcp连接池的剩余连接数,当一段时间内tcp连接池的剩余连接数过多时,所述调度中心会减少tcp连接池的数目,反之则增加tcp连接池的数目。
[0018]
更具体的,所涉及调度中心每1min收集一次tcp连接池的剩余连接数,若是5分钟内剩余连接数的平均大于10,则将tcp连接池减少10,相应的,若是剩余连接数在5分钟内都为0,则增加10。
[0019]
其次,本发明提供一种基于国产cpu和os的人工智能加速卡调度装置,解决上述技术问题采用的技术方案如下:
[0020]
一种基于国产cpu和os的人工智能加速卡调度装置,其结构包括:
[0021]
基于国产cpu和os的服务器,作为推送视频流的客户端,用于将采集的图像发送给人工智能加速卡;
[0022]
多张人工智能加速卡,部署于服务器,用于监听客户端端口;
[0023]
调度中心,用于根据用户选择的调度策略给客户端分配tcp连接,使客户端采集的图像通过tcp连接发送给相应的人工智能加速卡。
[0024]
具体的,所涉及调度策略包括最少资源占比策略、加速卡亲和策略;
[0025]
(a)所述最少资源占比策略由人工智能加速卡的利用率和模型数来决定,采用以下分段函数对人工智能加速卡的利用率进行处理:
[0026][0027][0028]
其中,usage表示人工智能加速卡的利用率,其范围是0
‑
1,这里只用sin函数
部分,所以需要对利用率进行变换;当人工智能加速卡利用率大于80%时,速度会急速下降,系数是根据测试得到的;p表示人工智能加速卡的利用率;
[0029]
(b)采用加速卡亲和策略时,数据会依次发送给每张人工智能加速卡,人工智能加速卡在返回结果时会将计算时间返回给调度中心;调用中心会根据上一次的计算时间给出相应的概率,然后选取概率最大的人工智能加速卡作为目标加速卡;但当某张指定人工智能加速卡的利用率高于80%时,调度中心会为其更换目标加速卡;当所有人工智能加速卡利用率都高于80%时,调度中心会选择最初的概率最大的人工智能加速卡。
[0030]
更具体的,所涉及调度中心监控tcp连接池的剩余连接数,同时收集运行在人工智能加速卡的模型及其利用率;
[0031]
在开启人工智能加速卡的亲和策略时,所述调度中心还会收集人工智能加速卡处理数据的速度,以便根据人工智能加速卡的实际运行情况,合理分配资源。
[0032]
更具体的,所涉及调度中心监控tcp连接池的剩余连接数,当一段时间内tcp连接池的剩余连接数过多时,所述调度中心会减少tcp连接池的数目,反之则增加tcp连接池的数目。
[0033]
更具体的,所涉及调度中心每1min收集一次tcp连接池的剩余连接数,若是5分钟内剩余连接数的平均大于10,则将tcp连接池减少10,相应的,若是剩余连接数在5分钟内都为0,则增加10。
[0034]
本发明的一种基于国产cpu和os的人工智能加速卡调度方法及装置,与现有技术相比具有的有益效果是:
[0035]
(1)本发明实现了在国产cpu和os下基于人工智能加速卡的管理,有效的提高了数据处理速率;
[0036]
(2)本发明能够自动进行tcp连接池的扩充和伸缩,适应不同客户端并发的应用场景。
附图说明
[0037]
附图1是本发明的连接框图。
具体实施方式
[0038]
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
[0039]
实施例一:
[0040]
结合附图1,本实施例提出一种基于国产cpu和os的人工智能加速卡调度方法,其实现过程涉及基于国产cpu和os的服务器、部署于服务器的多张人工智能加速卡、部署于集群管理工具zookeeper或nacos的调度中心;
[0041]
首先,将服务器作为推送视频流的客户端,人工智能加速卡作为监听客户端端口的tcp服务端;
[0042]
随后,建立tcp连接池,调度中心监控tcp连接池的剩余连接数;
[0043]
最后,客户端需要处理数据时,向调度中心发起请求,调度中心根据用户选择的调
度策略给客户端分配tcp连接,客户端即可通过分配的tcp连接将采集的图像发送至相应的人工智能加速卡。
[0044]
这一调度过程中,需要补充的是:每个人工智能加速卡的初始tcp连接池大小为摄像头的个数,默认情况下用于检测、去重、关键点检测和提取特征的数据会分别发往运行此模型的人工智能加速卡。这是理论的情况,但在实际情况中,摄像头下并不是每时都有人脸,在没有人脸的情况下就只有检测服务在运行,若此时还只往一张人工智能加速卡发送数据的话,其他三张加速卡就会处于空闲状态,造成了资源的浪费。因此,调度中心会根据用户选择的调度策略给客户端分配tcp连接,从而提高人工智能加速卡处理数据的效率。
[0045]
本实施例中,用户可以选择的调度策略包括最少资源占比策略、加速卡亲和策略。其中:
[0046]
(a)所述最少资源占比策略由人工智能加速卡的利用率和模型数来决定,采用以下分段函数对人工智能加速卡的利用率进行处理:
[0047][0048][0049]
其中,usage表示人工智能加速卡的利用率,其范围是0
‑
1,这里只用sin函数部分,所以需要对利用率进行变换;当人工智能加速卡利用率大于80%时,速度会急速下降,系数是根据测试得到的;p表示人工智能加速卡的利用率;
[0050]
(b)采用加速卡亲和策略时,数据会依次发送给每张人工智能加速卡,人工智能加速卡在返回结果时会将计算时间返回给调度中心;调用中心会根据上一次的计算时间给出相应的概率,然后选取概率最大的人工智能加速卡作为目标加速卡;但当某张指定人工智能加速卡的利用率高于80%时,调度中心会为其更换目标加速卡;当所有人工智能加速卡利用率都高于80%时,调度中心会选择最初的概率最大的人工智能加速卡。
[0051]
本实施例中,调度中心监控tcp连接池的剩余连接数,同时收集运行在人工智能加速卡的模型及其利用率;
[0052]
在开启人工智能加速卡的亲和策略时,所述调度中心还会收集人工智能加速卡处理数据的速度,以便根据人工智能加速卡的实际运行情况,合理分配资源。
[0053]
本实施例中,调度中心每1min收集一次tcp连接池的剩余连接数,若是5分钟内剩余连接数的平均大于10,则将tcp连接池减少10,相应的,若是剩余连接数在5分钟内都为0,则增加10。
[0054]
实施例二:
[0055]
结合附图1,本实施例提出一种基于国产cpu和os的人工智能加速卡调度装置,其
结构包括:
[0056]
基于国产cpu和os的服务器,作为推送视频流的客户端,用于将采集的图像发送给人工智能加速卡;
[0057]
多张人工智能加速卡,部署于服务器,用于监听客户端端口;
[0058]
调度中心,用于根据用户选择的调度策略给客户端分配tcp连接,使客户端采集的图像通过tcp连接发送给相应的人工智能加速卡。
[0059]
上述调度装置工作过程中,需要补充的是:每个人工智能加速卡的初始tcp连接池大小为摄像头的个数,默认情况下用于检测、去重、关键点检测和提取特征的数据会分别发往运行此模型的人工智能加速卡。这是理论的情况,但在实际情况中,摄像头下并不是每时都有人脸,在没有人脸的情况下就只有检测服务在运行,若此时还只往一张人工智能加速卡发送数据的话,其他三张加速卡就会处于空闲状态,造成了资源的浪费。因此,调度中心会根据用户选择的调度策略给客户端分配tcp连接,从而提高人工智能加速卡处理数据的效率。
[0060]
本实施例中,用户可以选的的调度策略包括最少资源占比策略、加速卡亲和策略。其中:
[0061]
(a)所述最少资源占比策略由人工智能加速卡的利用率和模型数来决定,采用以下分段函数对人工智能加速卡的利用率进行处理:
[0062][0063][0064]
其中,usage表示人工智能加速卡的利用率,其范围是0
‑
1,这里只用sin函数部分,所以需要对利用率进行变换;当人工智能加速卡利用率大于80%时,速度会急速下降,系数是根据测试得到的;p表示人工智能加速卡的利用率;
[0065]
(b)采用加速卡亲和策略时,数据会依次发送给每张人工智能加速卡,人工智能加速卡在返回结果时会将计算时间返回给调度中心;调用中心会根据上一次的计算时间给出相应的概率,然后选取概率最大的人工智能加速卡作为目标加速卡;但当某张指定人工智能加速卡的利用率高于80%时,调度中心会为其更换目标加速卡;当所有人工智能加速卡利用率都高于80%时,调度中心会选择最初的概率最大的人工智能加速卡。
[0066]
本实施例中,调度中心监控tcp连接池的剩余连接数,同时收集运行在人工智能加速卡的模型及其利用率;在开启人工智能加速卡的亲和策略时,所述调度中心还会收集人工智能加速卡处理数据的速度,以便根据人工智能加速卡的实际运行情况,合理分配资源。
[0067]
本实施例中,调度中心监控tcp连接池的剩余连接数,当一段时间内tcp连接池的
剩余连接数过多时,所述调度中心会减少tcp连接池的数目,反之则增加tcp连接池的数目。具体的,调度中心每1min收集一次tcp连接池的剩余连接数,若是5分钟内剩余连接数的平均大于10,则将tcp连接池减少10,相应的,若是剩余连接数在5分钟内都为0,则增加10。
[0068]
综上可知,采用本发明的一种基于国产cpu和os的人工智能加速卡调度方法及装置,可以提高图像数据的处理效率。
[0069]
基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1