一种基于DDQN的触觉材料不平衡数据的分类方法
一种基于ddqn的触觉材料不平衡数据的分类方法
技术领域
1.本发明涉及触觉材料不平衡数据的分类方法,具体涉及一种基于ddqn的触觉材料不平衡数据的分类方法。
背景技术:
2.触觉材料分类成为近年来一个重要且快速发展的研究课题。同时,触觉材料的不平衡数据分类逐渐引起了人们的关注。不同材料样品数量的较大差异降低了许多方法的分类精度。不平衡数据出现在许多实际应用中,如机器人识别和远程操作系统。
3.近年来,人们提出了许多触觉材料的分类方法。其中,利用视觉信息进行分类是主要的分类方法之一。在触觉材料分类研究的开始时,人们采用了许多方法从图像中提取手工制作的特征进行分类。他们使用随机投影来压缩图像并获得图像特征,然后使用k阶最近邻方法对这些特征进行分类。此外,计算灰度共生矩阵也是一种很先进的方法。他们使用k阶最近邻来对从灰度共生矩阵中获得的特征进行分类。由于这些方法对图像信息进行了大量压缩,材料之间的差异变得非常小,以至于很难应用到不平衡的数据分类中。随着卷积神经网络(cnn)的发展,已经发展了许多基于cnn的触觉材料分类方法。2015年,mircea cimpoi等人使用cnn作为特征提取工具,将从cnn中间层的输出中提取的fisher-vector描述符定义为特征。但是基于cnn的方法的一个主要缺点是它们在不平衡的数据分类中忽略了具有少量样本的材料。
4.处理不平衡数据分类的两种主要方法是过采样技术smote和降采样技术nearmiss。但是这两种方法都不适用于触觉材料的不平衡数据分类。因为smote生成的材料新样本容易导致分类器过拟合。nearmiss由于降采样删除了一些样本,容易造成重要信息的丢失。此外,这两种方法都容易受到噪声的影响。2012年,mikel galar等人提出了将集成学习与过采样技术结合的方法smote+adaboost等,此后一些集成学习的代表方法如随机森林,smote+随机森林等方法也逐渐流行起来。
5.ddqn作为一种深度强化学习算法,在机器人决策和游戏领域非常流行。vgg19是牛津大学的视觉几何组(visual geometry group)在2015年提出的,它的提出证明了增加网络的深度在一定程度上影响网络的性能。
技术实现要素:
6.本发明提供了一种基于ddqn的触觉材料不平衡数据的分类方法,以解决现实场景中触觉数据采集时造成的数据不平衡的分类问题。
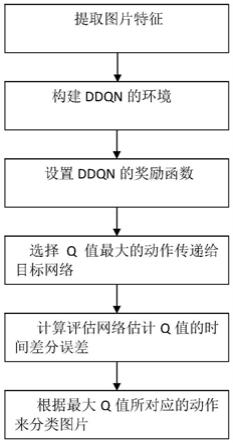
7.本发明采取的技术方案是:包括下列步骤:
8.(1)、利用vgg19处理图片,提取图片特征;
9.(2)、将vgg19提取的图片特征当作ddqn的状态,将它们的标签当作ddqn的动作,构建ddqn的环境;
10.(3)、根据不同材料训练集样本数目的不同设置ddqn的奖励函数;
11.(4)、ddqn的评估网络估计q值,并选择q值最大的动作传递给目标网络;
12.(5)、ddqn的目标网络计算评估网络估计q值的时间差分误差;
13.(6)、将评估网络估计q值的时间差分误差进行随机梯度下降优化参数,直至找到全局最优解,训练结束,保存训练好的网络,根据最大q值所对应的动作来分类图片。
14.本发明所述步骤(1)提取图片特征的具体途径是:
15.不平衡图片集的标签表示为其中m代表有m种材料,不平衡图片集表示为其中表示第li种材料的图片集,为标准图片集,它的图片数n为所有材料中图片数最少的,然后我们定义不平衡率σi为n除以第li种材料的图片数量,其中i=1,
…
,m,σi的变化范围是(0,1];
16.使用vgg19作为特征提取网络,vgg19由16个卷积层和3个全连接层组成,使用一层全局平均池化层来代替3个全连接层,全局平均池化层输出卷积得到的每个特征图中所有的像素的平均值,然后将这些平均值视为特征向量,将不平衡图片集中的图片输入到vgg19中,得到这些图片的特征{x1,
…
,xh},h是不平衡图片集中所有图片的数量,这些提取的特征将用于下一步构建ddqn的环境。
17.本发明所述步骤(2)构建ddqn环境的具体途径是,ddqn的环境是由状态和动作组成;
18.状态:在每一次迭代开始之前,随机打乱vgg19从不平衡图片集中提取的图片特征{x1,
…
,xh},然后将它们当作状态{s1,
…
,sh},使用这种方式将图片特征转换为状态序列;
19.动作:分类的目标是为每张图片找到正确的标签,将其定义为做出正确的动作,将图片的标签{l1,
…
,lm}作为动作空间,ddqn在状态s
t
下做出动作,然后状态s
t
转化为新的状态s
t+1
,t表示ddqn进行的第t步。
20.本发明所述步骤(3)设置奖励函数的具体途径是:
21.为不平衡图片集定义了一个奖励函数r,它随不平衡率σi变化,在状态s
t
,构成状态s
t
的特征的图片属于如果ddqn在第t步的动作a
t
为正确的动作即li,它将得到σi奖励,否则得到-σi奖励,奖励函数如下:
[0022][0023]
本发明所述步骤(4)中评估网络选择最大q值的动作的具体途径是:
[0024]
在ddqn中,建立基于神经网络的评估网络q
′
来估计动作值:q值;q值反应了在状态s,ddqn采取了动作a获得的未来奖励的估计;
[0025][0026]
其中的w
(t)
表示第t步评估网络q
′
的参数,g
t
表示在状态s做出动作a得到的奖励加上未来的奖励,用折扣因子γ来减小未来的奖励对现在动作选取的影响:
[0027]gt
=r
t
+γr
t+1
+γ2r
t+2
+γ3r
t+3
+
…
+γ
krt+k
[0028]rt
表示在第t步的状态s
t
做出动作a
t
后根据动作的对错和不平衡奖励函数得到的奖励,r
t+1
表示第t+1步的奖励,k表示在一次迭代中ddqn的所有步数;
[0029]
特别地,除了评估网络q
′
,ddqn还有另一个目标网络它的构造与评估网络q
′
相同,它的参数是每隔一段时间从评估网络q
′
复制过来的,给定状态s
t+1
,评估网络q
′
估计出采取所有动作所对应的q值,然后选出其中最大q值对应的动作:
[0030][0031]
其中的q(s
t+1
,a;w
(t)
)表示评估网络q
′
估计的q值,评估网络q
′
选出最大q值对应的动作a
*
后,将动作a
*
传递给目标网络用于计算评估q值的时间差分误差。
[0032]
本发明所述步骤(5)中目标网络计算时间差分误差具体途径是:
[0033]
目标网络将评估网络q
′
选出的最大q值所对应的动作a
*
用于计算时间差分目标(td target)y
t
,y
t
的计算公式如下:
[0034][0035]
r表示ddqn在上一个状态s
t
做出动作后根据不平衡奖励函数获得的奖励,w
(t-tmodc)
表示每隔c步评估网络q
′
的参数复制到目标网络来计算时间差分误差,计算的时间差分目标用于计算评估网络q
′
估计q值的时间差分误差δ
t
:
[0036]
δ
t
=q(s
t
,a;w
(t)
)-y
t
[0037]
所得的第t步的时间差分误差δ
t
将用于参数更新。
[0038]
本发明所述步骤(6)降低估计q值误差优化参数的具体途径是:
[0039]
将目标网络算出的时间差分目标与评估网络q
′
评估的q值做差求得的时间差分误差,用随机梯度下降的方法来减小这个误差,首先定义误差函数为:
[0040][0041]
再使用随机梯度下降方法降低误差,优化参数,其步骤为:
[0042][0043]
其中w
(t+1)
表示第t+1步的参数,随着训练的不断进行,不断使用梯度下降优化参数,直至找到全局最优解、即误差函数l(w)的值最小,训练结束保存训练好的网络,当新的图片输入到训练好的网络时,vgg19从图片中提取特征,ddqn的评估网络q
′
根据图片估计出每个动作对应的q值,选出其中最大q值所对应的动作就是图片的标签。
[0044]
ddqn作为一种深度强化学习算法,相比于现有的分类方法,它的评估网络和目标网络构成的对抗系统能使网络参数的训练更加迅速,防止过拟合的能力也更加突出。同时ddqn的表征能力要远远强于现有的分类方法,它将输入的特征映射到更高维的空间,分类效果更加显著。但是目前还没有研究将ddqn用于分类问题,在本发明中首次将ddqn用于分类问题。我们将分类问题看作决策过程,将数据的分类寻找正确的标签看作是在某个状态做出正确的动作。ddqn自身的优势完美地应用到了分类问题上,达到了非常不错的效果。
[0045]
研究发现ddqn的奖励机制非常适合分类不平衡数据,通过改变它的奖励,ddqn可以调整对不同材料的关注,避免忽略拥有少数训练样本的材料。在一般的方法中,用于分类
的特征在处理过程中总是混淆有噪声,影响分类器的性能。在方法里,引入了卷积神经网络vgg19处理图片,避免了噪声的干扰,保证提取的特征的鲁棒性。
[0046]
vgg19在分类图片和提取图片特征方面表现非常突出。ddqn的参数更新机制避免了过拟合现象的产生,保证了训练的网络的鲁棒性。本方法在分类触觉材料时只用了易采集的材料的图片,没有使用触觉信息如加速度摩擦力等,避免了使用复杂的触觉信息采集设备的数据采集过程。
[0047]
本发明的优点是:使用处理决策问题的深度强化学习方法ddqn来解决触觉材料不平衡数据的分类问题,并且分类精度要高于常用的不平衡数据的分类方法;与传统分类的cnn方法相比,只用了很小的时间代价,提高了分类精度;只用了图片就达到了很高的分类精度,避免了采集触觉信息的过程,可以应用于机器人识别,触觉远程呈现等领域。
附图说明
[0048]
图1是本发明的流程图;
[0049]
图2是本发明中vgg19提取触觉材料不平衡数据的特征并送入ddqn分类的流程图;
[0050]
图3是触觉材料不平衡数据分类的混淆矩阵图。
具体实施方式
[0051]
包括下列步骤:
[0052]
(1)、利用vgg19处理图片,提取图片特征:
[0053]
触觉材料不平衡数据分类的方法主要有两种,一种是只用视觉信息图片进行分类,一种是使用视觉信息图片和触觉信息如加速度摩擦力等进行分类,在本方法里,只使用了图片去分类触觉材料。不平衡图片集的标签可以表示为其中m代表有m种材料,不平衡图片集表示为其中表示第li种材料的图片集,不失一般性,定义为标准图片集,它的图片数n为所有材料中图片数最少的,定义不平衡率σi为n除以第li种材料的图片数量,其中i=1,
…
,m。σi的变化范围是(0,1];
[0054]
使用vgg19作为特征提取网络,vgg19由16个卷积层和3个全连接层组成,与使用大卷积核的网络(如alexnet)相比,其更深的卷积层和较小的卷积核确保提取的特征更具鲁棒性。然而,全连接层增加了计算复杂度,容易导致过拟合。因此,使用一层全局平均池化层来代替3个全连接层。全局平均池化层输出卷积得到的每个特征图中所有的像素的平均值,然后将这些平均值视为特征向量,将不平衡图片集中的图片输入到vgg19中,得到这些图片的特征{x1,
…
,xh},h是不平衡图片集中所有图片的数量,这些提取的特征将用于下一步构建ddqn的环境;
[0055]
(2)、将vgg19提取的图片特征当作ddqn的状态,将它们的标签当作ddqn的动作,构建ddqn的环境,ddqn的环境是由状态和动作组成:
[0056]
状态:在每一次迭代开始之前,随机打乱vgg19从不平衡图片集中提取的图片特征{x1,
…
,xh},然后将它们当作状态{s1,
…
,sh},使用这种方式将图片特征转换为状态序列;
[0057]
动作:分类的目标是为每张图片找到正确的标签,将其定义为做出正确的动作,将
图片的标签{l1,
…
,lm}作为动作空间,ddqn在状态s
t
下做出动作,然后状态s
t
转化为新的状态s
t+1
,t表示ddqn进行的第t步,在本发明中无特别指明,t均指第t步,下一步再通过设置ddqn的奖励函数来激励ddqn做出正确的决策;
[0058]
(3)、根据不同材料训练样本数目的不同设置ddqn的奖励机制:
[0059]
奖励在方法中很重要,因为通过调整它来改变ddqn对不同材料的重视,为不平衡图片集定义了一个奖励函数r,它随不平衡率σi变化。在状态s
t
,构成状态s
t
的特征的图片属于如果ddqn在第t步的动作a
t
为正确的动作即li,它将得到σi奖励,否则得到-σi奖励,奖励函数如下:
[0060][0061]
(4)、ddqn的评估网络估计q值,并选择q值最大的动作传递给目标网络:
[0062]
在ddqn中建立基于神经网络的评估网络q
′
来估计动作值:q值,q值反应了在状态s,ddqn采取了动作a获得的未来奖励的估计:
[0063][0064]
其中的w
(t)
表示第t步q网络的参数,g
t
表示在状态s做出动作a得到的奖励加上未来的奖励,用折扣因子γ来减小未来的奖励对现在动作选取的影响:
[0065]gt
=r
t
+γr
t+1
+γ2r
t+2
+γ3r
t+3
+
…
+γ
krt+k
[0066]rt
表示在第t步的状态s
t
做出动作a
t
后根据动作的对错和不平衡奖励函数得到的奖励,r
t+1
表示第t+1步的奖励,k表示在一次迭代中ddqn的所有步数;
[0067]
特别地,除了评估网络q
′
,ddqn还有另一个目标网络它的构造与评估网络q
′
相同,它的参数是每隔一段时间从评估网络q
′
复制过来的,给定状态s
t+1
,评估网络q
′
估计出采取所有动作所对应的q值,然后选出其中最大q值对应的动作:
[0068][0069]
其中的q(s
t+1
,a;w
(t)
)表示评估网络q
′
估计的q值,评估网络q
′
选出最大q值对应的动作a
*
后,将动作a
*
传递给目标网络用于计算评估q值的时间差分误差;
[0070]
(5)、ddqn的目标网络计算评估网络估计q值的时间差分误差:
[0071]
目标网络将评估网络q
′
选出的最大q值所对应的动作a
*
用于计算时间差分目标(td target)y
t
,y
t
的计算公式如下:
[0072][0073]
r表示ddqn在上一个状态s
t
做出动作后根据不平衡奖励函数获得的奖励,w
(t-tmodc)
表示每隔c步评估网络q
′
的参数复制到目标网络来计算时间差分误差,计算的时间差分目标用于计算评估网络q
′
估计q值的时间差分误差δ
t
:
[0074]
δ
t
=q(s
t
,a;w
(t)
)-y
t
[0075]
所得的第t步的时间差分误差δ
t
将用于参数更新。
[0076]
(6)、将目标网络算出的时间差分目标与评估网络q
′
评估的q值做差求得的时间差分误差,用随机梯度下降的方法来减小这个误差,定义误差函数为:
[0077][0078]
再使用随机梯度下降方法降低误差,优化参数,其步骤为:
[0079][0080]
其中w
(t+1)
表示第t+1步的参数,随着训练的不断进行,不断使用梯度下降优化参数,直至找到全局最优解即误差函数l(w)的值最小,训练结束保存训练好的网络,当新的图片输入到训练好的网络时,vgg19从图片中提取特征,ddqn的评估网络q
′
根据图片估计出每个动作对应的q值,根据最大q值所对应的动作来分类图片。
[0081]
下面通过仿真实验数据分析本发明所提出的一种基于ddqn的触觉材料不平衡数据的分类方法的对现有触觉材料数据库的适用性,仿真实验中采用的软件为pycharm软件,tensorflow框架。
[0082]
仿真实验:现有的触觉材料数据库均为数据平衡的数据库,为了更加接近现实场景中的分类问题,对现有的数据库进行训练样本的删减,使其成为不平衡的数据库。选用慕尼黑工业大学在2017年提出的ltm108数据库去评估基于ddqn的触觉材料的不平衡数据分类方法。ltm108数据库包含了108种材料,每种材料有20张图片。首先将每种材料的2张图片用于验证,2张图片用于测试。再将剩下的16张图片做调整,使其成为不平衡数据用于训练。定义了1:2:4:8的不平衡率,将108种材料随机选出27种材料将这16张图片删减至2张,再从剩下的材料里随机选出27种材料删减至4张图片,选出27种材料删减至8张图片,最后的27种材料不做删减,每种材料保持16张图片用于训练。将拥有2张图片的材料的图片集定义为标准集,不平衡比例σi就是标准集的图片数2除以其他图片集的图片数,2张图片用于训练和4张,8张,16张图片用于训练的材料的不平衡率σi分别是1,0.5,0.25,0.125。再根据σi的不同设置正确分类不同材料的奖励。这次实验使用了交叉验证确保方法的鲁棒性。在编程实现时,用一个全局平均池化层代替vgg19的三层全连接层,vgg19的其他层保持不变,vgg19使用的参数是在公开图片数据集imagenet预训练的参数,用vgg19提取出不平衡图片集的图片特征{x1,
…
,x
810
}。然后用这些特征以及它们所属材料的标签{l1,
…
,l
108
}定义ddqn的环境即ddqn的状态和动作,再根据不同材料用于训练的图片数定义奖励函数。实验中使用的折扣因子γ为0.1,每次用于训练批量大小是256,每次迭代ddqn的所有步数k设置为2000。实验使用python的框架tensorflow搭建ddqn网络,实验使用python的框架tensorflow搭建ddqn的评估网络和目标网络,两个网络的构造完全相同。它们都是由5层全连接层组成,这5层全连接层的神经元数分别是500,400,300,200,108,全连接层的激活函数均为relu,输入ddqn的状态和动作,定义好奖励函数,使用adam随机梯度下降方法去训练网络,直至误差函数达到最小时,训练结束保存好训练的网络。然后我们用训练好的网络去分类测试集,得到测试集的分类准确度即表1结果。
[0083]
图3展示了本发明所提出的基于ddqn的触觉材料不平衡数据分类方法分类ltm108数据库时的混淆矩阵。表1展示了ddqn与其他两种经典分类器在不平衡ltm108数据集的分类结果。
[0084]
表1 ddqn与其他两种经典分类器在不平衡ltm108数据集的分类结果
[0085][0086]
分析实验结果可知,本发明所提出的方法在小样本数据集(即训练集样本数本身就很少的样本集)不平衡比例最高达到8:1时的分类效果仍然显著,分类精度明显高于其他分类器。在实际场景中,对于样本采集难度较大的材料,即使样本数少也能进行较准确的分类;此外,本发明只用了触觉材料的视觉信息未加入触觉信息如加速度摩擦力等,避免了复杂的触觉信息的采集过程,但达到了视觉信息跟触觉信息融合的分类精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1