一种订单数据索引方法、系统、计算机设备以及存储介质与流程
1.本发明属于计算机技术领域,尤其是一种订单数据索引方法、系统、计算机设备以及存储介质。
背景技术:
2.随着移动互联网的发展,人们拥有日益增多的网络购物需求。电商平台随着交易量以及业务逻辑不断复杂,订单和客户逻辑关系会产生大量的数据,在传统数据技术模式下,一般使用关系型数据库管理系统mysql作为存储引擎。mysql在数据量级较小的情况下,可以满足业务的正常扭转。但是在现有的数据查询的方案中,数据量一旦过大,则会出现查询速度变慢,数据产品响应速度迟缓,造成用户订单卡死,数据分析卡死等情况。
技术实现要素:
3.有鉴于此,为至少部分解决上述技术问题之一,本发明实施例目的在于提供一种更为便捷、更为高效迅速的能够应对数据并发的订单数据索引方法、系统、设备以及存储介质。
4.第一方面,本技术的技术方案提供了一种订单数据索引方法,其步骤包括:
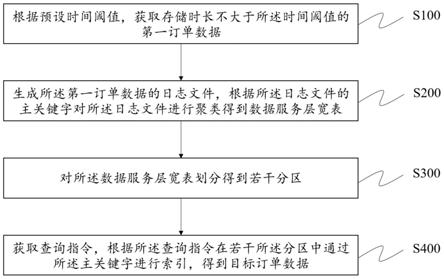
5.根据预设时间阈值,获取存储时长不大于所述时间阈值的第一订单数据;
6.生成所述第一订单数据的日志文件,根据所述日志文件的主关键字对所述日志文件进行聚类得到数据服务层宽表;
7.对所述数据服务层宽表划分得到若干分区;
8.获取查询指令,根据所述查询指令在若干所述分区中通过所述主关键字进行索引,得到目标订单数据。
9.在本技术方案的一种可行的实施例中,订单数据索引方法还包括:
10.获取存储时长大于所述时间阈值的第二订单数据,将所述第二订单数据进行离线清洗;
11.根据所述第二订单数据的第二字段属性与所述第一订单数据中第一字段属性的映射关系生成数据服务层宽表;
12.根据所述细节数据宽表中的订单数据进行聚类得到若干数据服务层宽表。
13.在本技术方案的一种可行的实施例中,所述生成所述第一订单数据的日志文件,根据所述日志文件的主关键字对所述日志文件进行聚类,包括以下步骤:
14.根据所述日志文件生成所述第一订单数据的原关键字,将所述原关键字与第一字符进行组合得到所述主关键字;
15.所述第一字符是通过所述第一订单数据的哈希值以及所述分区数量所计算得到的。
16.在本技术方案的一种可行的实施例中,在生成所述第一订单数据的日志文件,根据所述日志文件的主关键字对所述日志文件进行聚类得到数据服务层宽表这一步骤之前,
所述方法还包括:
17.获取所述第一订单数据,对所述第一订单数据进行脱敏处理;
18.所述脱敏处理包括以下步骤:
19.将所述第一订单数据中的用户信息替换成符号字符串;
20.根据所述映射关系对所述第一订单数据中的字段进行筛选。
21.在本技术方案的一种可行的实施例中,在所述将离线清洗后的所述第二订单数据与所述第一订单数据构建得到细节数据宽表这一步骤之后,所述方法还包括以下步骤至少之一:
22.将所述细节数据宽表中的订单数据进行规范化处理,统一所述订单数据的数据格式;
23.对所述细节数据宽表中的订单数据进行数据清洗,减少所述订单数据的空值以及脏数据。
24.在本技术方案的一种可行的实施例中,在所述根据预设时间阈值,获取存储时长不大于所述时间阈值的第一订单数据这一步骤之前,所述方法还包括:
25.通过正则表达式匹配数据表,所述数据表包括若干所述第一订单数据;
26.设置获取所述数据表的数据仓库参数。
27.在本技术方案的一种可行的实施例中,所述获取查询指令,根据所述查询指令在若干所述分区中通过所述主关键字进行索引,得到目标订单数据,包括以下步骤:
28.获取若干历史查询结果,获取所述历史查询结果中的高频字段;
29.根据所述高频字段构建索引表,根据所述索引表进行目标订单数据查询。
30.第二方面,本发明的技术方案还提供一种订单数据索引系统,该系统包括:
31.数据获取模块,用于根据预设时间阈值,获取存储时长不大于所述时间阈值的第一订单数据;
32.数据分类模块,用于生成所述第一订单数据的日志文件,根据所述日志文件的主关键字对所述日志文件进行聚类得到数据服务层宽表;对所述数据服务层宽表划分得到若干分区;
33.数据查询模块,用于获取查询指令,根据所述查询指令在若干所述分区中通过所述主关键字进行索引,得到目标订单数据。
34.第三方面,本发明的技术方案还提供一种订单数据索引的计算机设备,其包括:
35.至少一个处理器;
36.至少一个存储器,用于存储至少一个程序;
37.当至少一个程序被至少一个处理器执行,使得至少一个处理器运行第一方面中所述方法。
38.第四方面,本发明的技术方案还提供一种存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于运行第一方面所述一种订单数据索引方法。
39.本发明的优点和有益效果将在下面的描述中部分给出,其他部分可以通过本发明的具体实施方式了解得到:
40.本技术技术方案通过设置时间阈值,根据该时间阈值获取相应的订单数据,通过
订单数据的日志文件对海量的订单数据进行聚类划分得到数据服务层宽表,并构建相应的分区,分区中则包含了若干数据服务层宽表,然后根据查询指令,通过对分区中的主关键字进行检索比较,以获取目标订单数据;方案通过列式存储以及分布式计算服务来提高订单数量过大情况下的订单数据查询慢的效率,相对于传统数据库,可以做到秒级实时查询,查询速度更快且响应速度更快。
附图说明
41.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
42.图1为本发明实施例提供的一种订单数据索引方法的步骤流程图;
43.图2为本发明实施例提供的另一种订单数据索引方法的步骤流程图。
具体实施方式
44.下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
45.现有技术通常使用关系型数据库管理系统mysql作为存储引擎,虽然在传统的数据处理的场景中,mysql能够满足业务数据的正常扭转,但对于普遍存在的订单数据高并发的场景,由于数据量过于庞大,进而导致查询速度变慢,影响到数据产品响应速度,造成流程进度卡死以及数据分析卡死等情况。针对以上的情况,本技术提供了一种针对大数据可以进行快速地订单数据索引的技术方案。
46.第一方面,如图1所示,本技术的技术方案提供了一种订单数据索引方法,其主要步骤可以包括s100-s400:
47.s100、根据预设时间阈值,获取存储时长不大于时间阈值的第一订单数据;
48.其中,时间阈值为预先设置的订单数据的有效期限,在该有效期限内的数据为可用数据,在该有效期限之外的数据,则需要进行必要的同步加载以及清洗处理之后,与可用数据进行整合使用;具体地,实施例中首先从初步汇总了订单数据的存储空间或者存储容器中获取在有效期限内的订单数据;示例性地,实施例中可以采用开源的框架canal,同步数据库的增量数据到的实施例中数据;订单数据初步汇总的存储空间为mysql数据库,canal可以作为mysql slave,模拟mysql slave的交互协议向mysql mater发送dump协议,mysql mater收到canal发送过来的dump请求,开始推送二进制日志(binary log)给canal,然后canal解析binary log,再发送到存储目的地,该存储目的地包括但不限于mysql,kafka以及elastic search。以有效期限一年为例,实施例中通过canal同步订单相关表的binary log到kafka中。需要说明的是,实施例中,当获取的订单数据量较小时,可以通过kafka建立单分区topic,其中,topic是kafka数据写入操作的基本单元,可以指定副本。
49.s200、生成第一订单数据的日志文件,根据日志文件的主关键字对日志文件进行聚类得到数据服务层宽表;
50.其中,日志文件(binary log)是用于记录数据库里的数据修改记录;包括但不限于insert、update、delete、create、drop以及alter的相关语句。主关键字(primary key,主键)是数据表中的一个或多个字段,主键值用于唯一标识表中的某一条记录。在两个表的关系中,主关键字用来在一个表中引用来自于另一个表中的特定记录。数据服务层(data warehouse details,dwd)是业务层与数据仓库的隔离层;宽表指字段比较多的数据库表。通常是指业务主体相关的指标、纬度、属性关联在一起的一张数据库表。示例性地,实施例中将步骤s100中所获取的订单数据同步至kafka中,并通过flink数据流编程模型对订单数据进行必要的清洗和脱敏处理,然后再将清洗和脱敏后的订单数据聚进行汇总写入至hbase中,构建得到hbase中的数据dwd层,并进一步生成dwd宽表。
51.s300、对数据服务层宽表划分得到若干分区;
52.其中,分区(region)是hbase集群分布数据的最小单位;当实施例中数据表初写数据时,此时表只有一个region,当随着数据的增多,region开始变大,等到它达到限定的阀值大小时,变化把region分裂为两个大小基本相同的region,而这个阀值就是storefile的设定大小,在第一次分裂region之前,所有加载的数据都放在原始区域的服务器上,随着表的变大,region的个数也会相应的增加。此外,regionserver是hbase中比较核心模块,响应用户io请求,进行数据读写。
53.此外,实施例中还构建了数据基础层(data warehouse base,dws),用于存储客观数据,作为中间层或大量指标的数据层;基于dwb层上的基础数据,实施例可以整合汇总dwd宽表成为分析某一个主题域的服务数据层,并得到数据服务层(data warehouse service,dws)宽表;用于提供后续的业务查询,olap分析,数据分发等。可以理解的是,regionserver可以应用于实施例中任意一个宽表之中。
54.s400、获取查询指令,根据查询指令在若干分区中通过主关键字进行索引,得到目标订单数据;
55.具体地,在实施例的后端,根据用户为获取目标订单数据的查询指令,将利用phoenix对dws宽表进行查询;实施例中通过phoenix构建hbase的sql层,在hbase中查询phoenix创建的表的数据,如果对phoenix的表进行数据更新,则hbase的表也可以更新。在phoenix中进行一次数据的聚合查询,聚合查询结果的响应速度相较于现有技术的查询方法的响应速度更快。
56.在相关技术中的hbase中写入过程中,一个region由一个regionserver控制,region超过默认大小时,会分裂成两个较小的region,新的region会写入所有的新记录,但是新的region还是在同一个regionserver上,导致集群的资源分配不均衡,影响集群的性能。因此,实施例为了避免出现单个regionserver出现热点问题,进行了加盐处理,即在s200、生成第一订单数据的日志文件,根据日志文件的主关键字对日志文件进行聚类这一步骤中,可以包括步骤s210:
57.s210、根据日志文件生成第一订单数据的原关键字,将原关键字与第一字符进行组合得到主关键字;
58.其中,第一字符是通过第一订单数据的哈希值以及分区数量所计算得到的1byte
的字节,原关键字是指订单数据的原始主键;主关键字则是指通过加盐处理后得到的主键。具体地,实施例中的加盐过程的计算公式如下:
59.new_row_key=((byte)(hash(key)%buckets_number)+original_key
60.在该计算公式中,buckets_number是加盐形成的分桶的数量,original_key是数据原始的主键,数据产生的新主键会将数据写入到不同的region中,每个region的数据都是原来连续递增数据的子集,写入各个节点的数据达到负载均衡。
61.在一些可选的实施例中,为充分利用在有效期限之外的数据,本实施例的方法还包括步骤s500-s600:
62.s500:获取存储时长大于时间阈值的第二订单数据,将第二订单数据进行离线清洗;
63.如图2所示,示例性地,以时间阈值设置1年为例,实施例针对超过一年的订单相关数据,采用离线清洗的方式,将数据导入到hbase中,然后再根据未超过一年的订单数据进行同步。
64.具体地,实施例中通过离线清洗的方式采用sqoop+datax同步mysql的数据到hive数据仓库,然后在hive里面构建一张phoenix外部表,对原始数据采用与实时处理一致的业务处理逻辑,构建一张宽表,写入到phoenix外部表中;写入完成后,启动canal、kafka以及flink服务,实时写入数据到hbase。
65.s600:根据第二订单数据的第二字段属性与第一订单数据中第一字段属性的映射关系,根据离线清洗后的第二订单数据与第一订单数据生成数据服务层宽表;
66.具体地,通过步骤s500所得到的订单相关数据以及步骤s100所获取的订单数据在hbase中的dwd层进行汇总,在dwd层根据汇总的订单数据中的各个字段的内容生成数据映射关系,首先根据该映射关系将汇总前的两部分订单数据进行同步,以使得两部分订单数据表具有相同的字段属性以及字段记录内容,此外,映射关系还可以在后续业务处理时,如果需要这些信息,直接进行调用;示例性地,实施例可以将gps经纬度转换为省市区详细地址;例如,gps快速查询一般将地理位置知识库使用geohash映射;然后将需要比对的gps转换为geohash后跟知识库中geohash比对,查找出地理位置信息。
67.在一些可选的实施例中,在生成第一订单数据的日志文件,根据日志文件的主关键字对日志文件进行聚类得到数据服务层宽表这一步骤s200之前,实施例的方法还包括步骤s110:
68.s110、获取第一订单数据,对第一订单数据进行脱敏处理;其中,脱敏处理的处理过程包括但不限于将第一订单数据中的用户信息替换成符号字符串或者根据映射关系对第一订单数据中的字段进行筛选;
69.示例性地,实施例中对订单表的客户信息进行脱敏操作,将用户的前三位数字后4位数字保留,其余的位数用*号表示,对报表中不涉及的字段进行了过滤处理,在提高了处理流程的效率的同时也对方案中所涉及的用户进行了必要的隐私保护。
70.在一些可选择的实施例中,在将离线清洗后的第二订单数据与第一订单数据构建得到细节数据宽表这一步骤s600之后,实施例方法还包括s610和s620:
71.s610、对第一订单数据与第二订单数据进行规范化处理,统一订单数据的数据格式;
72.s620、对第一订单数据与第二订单数据进行数据清洗,减少订单数据的空值以及脏数据;
73.具体地,将有效期限内的数据以及经过清洗以及同步之后的未在有效期限内的数据汇总在dwd层,进行数据清洗和规范化的操作,数据清洗:去除空值、脏数据、超过极限范围的数据或记录。
74.在一些可选择的实施例中,获取查询指令,根据查询指令在若干分区中通过主关键字进行索引,得到目标订单数据这一步骤s400,可以包括步骤s410-s420:
75.s410、获取若干历史查询结果,获取历史查询结果中的高频字段;
76.s420、根据高频字段构建索引表,根据索引表进行目标订单数据查询;
77.具体地,实施例对于可以预见的某一些查询,常见的场景集是对几个字段进行过滤分组查询操作,与mysql等传统关系数据库不同,覆盖索引可以不需要通过索引去找到主键下的数据,索引里面就把预先设置好的字段保留在索引中;对于分布式数据库,索引可能与数据存储在不同的节点,跨界点查询影响查询的效率,通过覆盖索引,提高了查询的性能。
78.在一些可选择的实施例中,在根据预设的时间阈值,获取存储时长不大于时间阈值的第一订单数据这一步骤s100之前,实施例方法还可以包括步骤s001-s002:
79.s001、通过正则表达式匹配数据表,数据表包括若干第一订单数据;
80.具体地,实施例将mysql的binlog-format修改为row格式;然后修改instance.properties文件,修改canal.instance.filter.regex配置,新增需要同步的表,可以通过正则表达式来匹配订单“order”相关的表;通过修改canal.mq.partitionsnum和canal.mq.partitionhash来控制各个表的分区数和hash分区主键。
81.s002、设置获取数据表的数据仓库参数;
82.具体地,实施例还需要修改canal.properties,填写kafka集群参数配置、端口号、消息传输参数等。
83.第二方面,本发明的技术方案还提供一种订单数据索引系统,该系统包括:
84.数据获取模块,用于根据预设时间阈值,获取存储时长不大于时间阈值的第一订单数据;
85.数据分类模块,用于生成第一订单数据的日志文件,根据日志文件的主关键字对日志文件进行聚类得到数据服务层宽表;对数据服务层宽表划分得到若干分区;
86.数据查询模块,用于获取查询指令,根据查询指令在若干分区中通过主关键字进行索引,得到目标订单数据。
87.第三方面,本发明的技术方案还提供一种订单数据索引装置,其包括:至少一个处理器;至少一个存储器,用于存储至少一个程序;当至少一个程序被至少一个处理器执行,使得至少一个处理器运行第一方面中方法。
88.从上述具体的实施过程,可以总结出,本发明所提供的技术方案相较于现有技术存在以下优点或优势:
89.本技术方案通过列式存储以及分布式计算服务来提高订单数量过大情况下的订单数据查询慢的效率,相对于传统数据库,可以做到秒级实时查询,查询速度更快且响应速度更快。
90.在一些可选择的实施例中,在方框图中提到的功能/操作可以不按照操作示图提到的顺序发生。例如,取决于所涉及的功能/操作,连续示出的两个方框实际上可以被大体上同时地执行或所述方框有时能以相反顺序被执行。此外,在本发明的流程图中所呈现和描述的实施例以示例的方式被提供,目的在于提供对技术更全面的理解。所公开的方法不限于本文所呈现的操作和逻辑流程。可选择的实施例是可预期的,其中各种操作的顺序被改变以及其中被描述为较大操作的一部分的子操作被独立地执行。
91.此外,虽然在功能性模块的背景下描述了本发明,但应当理解的是,除非另有相反说明,功能和/或特征中的一个或多个可以被集成在单个物理装置和/或软件模块中,或者一个或多个功能和/或特征可以在单独的物理装置或软件模块中被实现。还可以理解的是,有关每个模块的实际实现的详细讨论对于理解本发明是不必要的。更确切地说,考虑到在本文中公开的装置中各种功能模块的属性、功能和内部关系的情况下,在工程师的常规技术内将会了解该模块的实际实现。因此,本领域技术人员运用普通技术就能够在无需过度试验的情况下实现在权利要求书中所阐明的本发明。还可以理解的是,所公开的特定概念仅仅是说明性的,并不意在限制本发明的范围,本发明的范围由所附权利要求书及其等同方案的全部范围来决定。
92.在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。
93.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
94.尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
95.以上是对本发明的较佳实施进行了具体说明,但本发明并不限于上述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本技术权利要求所限定的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1