基于用户行为的内容推荐的系统和方法与流程
基于用户行为的内容推荐的系统和方法
1.交叉申请
2.本技术要求2015年12月29日递交的发明名称为“基于用户行为的内容推荐的系统和方法(system and method for user-behavior based content recommendations)”的第14/982,842号美国非临时专利申请案的在先申请优先权,该在先申请的全部内容以引用的方式并入本文本中。
技术领域
3.本发明一般涉及管理多媒体内容,在具体实施例中,涉及预测用户最有意义的多媒体内容的技术和机制。
背景技术:
4.随着存储成本的降低,用户设备(user equipment,ue)现在能够存储大量多媒体内容(例如照片、视频、音乐)。因此,在ue上组织多媒体近来成为一项艰巨的任务。用户必须经常对成百上千的多媒体文件排序以找出他们想要使用的一份文件。
5.已经提出了若干种帮助用户找出多媒体的方法。传统图像搜索和理解方法试图找出多媒体内容中的对象。例如,脸部、地标、动物等对象可以位于多媒体内容中,然后可以根据识别的对象对多媒体内容分组。其它方法还可以考虑多媒体内容的元数据,例如捕获的时间和位置。
6.但是,多媒体内容通常使用传统方法自由分组和组织。大多数用户仍然需要搜索他们想要使用的内容。进一步地,传统方法通常需要大量处理和存储容量来分析多媒体内容。
技术实现要素:
7.本发明实施例描述了一种预测用户最有意义的媒体内容的系统和方法,从而大体上实现技术优势。
8.根据一实施例,提供了一种方法。所述方法包括:响应于用户请求多媒体操作,启用输入设备;在执行所述多媒体操作时通过所述输入设备记录所述用户的行为和交互线索;根据一种模型对所述行为和交互线索排序,从而为用户产生第一多媒体推荐标准;以及根据所述第一多媒体推荐标准向所述用户推荐多个多媒体文件。
9.根据另一实施例,提供了一种方法。所述方法包括:响应于用户查看多媒体文件,启用设备的前置摄像头;通过所述前置摄像头记录所述用户的行为和交互动作;分析所述行为和交互动作以产生多媒体线索;将权重分配给每个所述多媒体线索;根据所述用户的所述行为和交互动作来调整每个所述多媒体线索的所述权重;以及根据所述权重为多个多媒体文件生成图像分数。
10.根据另一实施例,提供了一种方法。所述方法包括:响应于用户请求多媒体操作,启用用户设备上的感应设备;对多媒体内容执行所述多媒体操作;响应于所述多媒体操作,
基本上在执行所述多媒体操作时通过所述感应设备确定所述用户的行为和交互线索;更新多媒体内容集合中的推荐,所述多媒体内容集合包括由所述确定的行为和交互线索表示的多媒体内容;以及向所述用户呈现所述更新的推荐。
11.在一些实施例中,所述方法还包括:响应于呈现所述更新的推荐,请求所述用户的反馈;将所述用户的所述反馈分类为正面反应或负面反应以产生反馈线索;以及根据所述反馈线索进一步更新所述多媒体内容集合中的所述推荐。
12.在一些实施例中,确定所述用户的所述行为和交互线索包括:在所述行为和交互线索中搜索多媒体子线索;以及将所述多媒体子线索分类为正面反应或负面反应。
13.在一些实施例中,搜索多媒体子线索包括响应于所述多媒体内容的查看时间,产生所述多媒体子线索。
14.在一些实施例中,搜索多媒体子线索包括响应于所述用户共享所述多媒体内容,产生所述多媒体子线索。
15.在一些实施例中,搜索多媒体子线索包括响应于所述用户编辑所述多媒体内容,产生所述多媒体子线索。
16.在一些实施例中,搜索多媒体子线索包括响应于所述用户放大所述多媒体内容,产生所述多媒体子线索。
17.在一些实施例中,搜索多媒体子线索包括响应于所述用户旋转所述用户设备以将所述用户设备的方向与所述多媒体内容的方向匹配,产生所述多媒体子线索。
18.在一些实施例中,确定所述用户的所述行为和交互线索包括:通过所述感应设备捕获所述用户的面部表情;以及识别所述用户的所述面部表情以产生所述行为和交互线索。
19.在一些实施例中,识别所述面部表情包括将所述用户的所述面部表情分类为正面的面部反应、负面的面部反应或无面部反应。
20.在一些实施例中,识别所述面部表情包括当所述用户注视所述用户设备的显示器上的热点时识别所述用户的视线。
21.在一些实施例中,确定所述用户的所述行为和交互线索包括:通过所述感应设备捕获周围活动;以及分析所述周围活动以产生所述行为和交互线索。
22.在一些实施例中,捕获所述周围活动包括在执行所述多媒体操作时通过所述感应设备捕获声音。
23.在一些实施例中,捕获所述周围活动包括:通过所述感应设备捕获视频;执行人脸识别以检测所述视频中的主体;以及将所述视频中的主体与所述用户设备上的联系人列表中的条目相关联。
24.在一些实施例中,所述多媒体操作包括捕获照片或视频。
25.在一些实施例中,所述多媒体操作包括显示照片或视频。
26.根据另一实施例,提供了一种方法。所述方法包括:在用户设备上提供多个多媒体内容;当用户访问所述多媒体内容时,通过感应设备捕获所述用户的行为和交互式动作;分析所述行为和交互式动作以产生多媒体线索;将权重分配给所述多媒体线索中的每个线索;根据所述权重和所述多媒体线索为所述多个多媒体内容中的每个内容生成分数;以及根据所述分数向所述用户呈现所述多媒体内容的推荐。
27.在一些实施例中,所述方法还包括:根据所述用户的所述行为和交互式动作调整所述多媒体线索中的每个线索的所述权重;以及归一化所述权重。
28.在一些实施例中,为所述多个多媒体内容中的每个内容生成所述分数包括:根据所述权重为所述多媒体线索中的每个线索计算和总计原始分数;计算相关性因子,并将其应用到所述原始分数;以及将学习因子应用到所述原始分数以产生所述分数。
29.在一些实施例中,产生所述分数包括根据以下公式计算所述分数:
[0030][0031]
其中,t是多媒体线索的总数量,wn是多媒体线索的所述权重,pn是多媒体线索的值,wc是相关性因子权重,pc是相关性因子值,f是所述学习因子。
[0032]
根据又一实施例,提供了一种设备。所述设备包括输入设备、处理器和计算机可读存储介质,所述计算机可读存储介质存储包括可由所述处理器执行的指令的程序,当执行所述指令时,所述处理器用于执行一种方法,所述方法包括:响应于用户查看多媒体文件,启用所述输入设备;在显示所述多媒体文件时通过所述输入设备记录所述用户的行为和交互线索;根据一种模型对所述行为和交互线索排序,从而为用户产生第一多媒体推荐标准;以及根据所述第一多媒体推荐标准向所述用户推荐多个多媒体文件。
[0033]
根据又一实施例,提供了一种设备。所述设备包括感应设备、存储多个多媒体内容的存储器、处理器以及存储待由所述处理器执行的程序的计算机可读存储介质。所述程序包括执行以下操作的指令:接收来自用户的执行多媒体操作的请求;在通过所述感应设备检索数据时执行所述多媒体操作;根据所述请求和所述检索到的数据来更新所述多媒体内容的子集的推荐;以及向所述用户呈现所述更新的推荐。
[0034]
根据又一实施例,提供了一种设备。所述设备包括感应设备、处理器以及计算机可读存储介质,计算机可读存储介质存储待由所述处理器执行的程序,所述程序包括执行方法的指令,所述方法包括:响应于用户请求多媒体操作,启用所述感应设备;在执行所述多媒体操作时通过所述感应设备确定所述用户的行为和交互线索;将所述行为和交互线索与所述多媒体操作相关联;根据一种模型对多媒体内容进行排序,所述模型包括所述行为和交互线索;以及根据所述多媒体内容的所述排序向所述用户呈现所述多媒体内容的子集的推荐。
[0035]
在一些实施例中,所述确定所述行为和交互线索的所述指令包括捕获和分析周围声音以产生所述行为和交互线索的指令。
[0036]
在一些实施例中,所述确定所述行为和交互线索的所述指令包括捕获和识别所述用户的面部表情以产生所述行为和交互线索的指令。
[0037]
在一些实施例中,所述确定所述行为和交互线索的所述指令包括搜索所述多媒体内容中的照片子线索并将所述照片子线索分类为正面反应或负面反应以产生所述行为和交互线索的指令。
[0038]
在一些实施例中,所述程序还包括执行以下操作的指令:向所述用户呈现所述多媒体内容;响应于呈现所述多媒体内容,请求所述用户的反馈;将所述用户的所述反馈分类为正面反应或负面反应以产生反馈线索;以及根据所述模型进一步对所述多媒体内容排
序,所述模型包括所述反馈线索和所述行为和交互线索。
[0039]
根据又一实施例,提供了一种设备。所述设备包括感应设备、存储多个多媒体内容的存储器、处理器以及计算机可读存储介质,计算机可读存储介质存储待由所述处理器执行的程序,所述程序包括执行以下操作的指令:接收用户的请求以执行多媒体操作;在通过所述感应设备检索数据时执行所述多媒体操作;根据所述请求和所述检索到的数据更新所述多媒体内容的子集的推荐;以及向所述用户呈现所述更新的推荐。
[0040]
在一些实施例中,所述程序还包括执行以下操作的指令:响应于呈现所述更新的推荐,请求所述用户的反馈;以及根据所述反馈进一步更新所述多媒体内容的所述子集的所述推荐。
[0041]
在一些实施例中,所述通过所述感应设备检索数据的所述指令包括通过所述感应设备感测所述用户的行为的指令。
[0042]
在一些实施例中,所述感应设备为麦克风或前置摄像头之一。
附图说明
[0043]
为了更完整地理解本发明及其优点,现在参考下文结合附图进行的描述,其中:
[0044]
图1a示出了图示示例性处理系统的框图;
[0045]
图1b示出了图示示例性推荐系统的框图;
[0046]
图2示出了包括多媒体图库的示例性用户接口;
[0047]
图3示出了执行多媒体推荐操作的示例性过程;
[0048]
图4示出了访问用户配置文件的示例性过程;
[0049]
图5a至图5b示出了确定和记录表示用户行为、交互和反馈的线索的各种示例性过程;
[0050]
图6示出了记录表示用户行为的线索的示例性过程;
[0051]
图7示出了将表示用户面部表情的线索分类的示例性过程;
[0052]
图8示出了确定和跟踪用户注视线索的示例性过程;
[0053]
图9示出了根据本发明实施例的通过执行多媒体操作的设备来确定和记录用户交互的示例性流程;
[0054]
图10a至图10d示出了检测照片子线索的各种示例性过程;
[0055]
图11示出了确定表示多媒体推荐的用户反馈的线索的示例性过程;
[0056]
图12示出了本发明一项实施例中的用户反馈来配置推荐引擎的示例性过程;
[0057]
图13示出了本发明一项实施例中的调整推荐引擎中的权重因子的示例性过程;以及
[0058]
图14示出了本发明一项实施例中的生成排序分数的示例性过程。
[0059]
除非另有指示,否则不同图中的对应标号和符号通常指代对应部分。绘制各图是为了清楚地说明实施例的相关方面,因此未必是按比例绘制的。
具体实施方式
[0060]
下文将详细论述本发明实施例的制作和使用。应了解,本文所揭示的概念可以在多种具体环境中实施,且所论述的具体实施例仅作为说明而不限制权利要求书的范围。进
一步的,应理解,可在不脱离由所附权利要求书界定的本发明的精神和范围的情况下,对本文做出各种改变、替代和更改。
[0061]
本文公开了一种预测用户最有意义的多媒体内容的系统和方法。随着低成本存储器的普及,用户设备现在能够存储上千照片、视频和歌曲。用户难以从这些大量的内容集合中找到对于他们最有意义的多媒体。因此,希望出现在本地且自动向用户提供有意义内容的技术。
[0062]
实施例提供了向设备的特定用户自动预测和建议(或确定、推荐等)有意义或相关多媒体的系统和方法。用户的行为和交互式输入通过传感器捕获并且在用户通过用户设备查看或捕获多媒体时进行分析以得到线索。分析这些输入以得到线索,使得用户设备可以了解到对用户最有意义的多媒体。来自用户的行为和交互式输入还可与传统检测-识别-分类方案结合起来以进一步完善向用户预测和推荐多媒体内容。行为和交互式输入的捕获以及分析以得到线索是可能的,因为现代用户设备经常有多个传感器集成在其中,例如前置后置摄像头和麦克风。
[0063]
各种实施例可以实现优点。向用户自动预测和建议有意义的多媒体允许用户保存他们最喜爱的内容并轻松地在用户设备上进行访问。例如,包含成千上万个多媒体文件的集合可以缩小到对用户有意义的仅几十个最喜爱的多媒体文件的推荐。用户对这些推荐的反馈可以用作用户设备的机器学习输入,从而允许进一步完善多媒体推荐。因此,用户设备对于特定用户偏好更具个性化。这种学习方法可以通过比传统检测-识别-分类方法相对较简单的方式来实施,从而允许在用户设备上进行本地实施并且避免依赖于云计算来获得处理或存储容量。
[0064]
图1a示出了执行本文所描述的方法的实施例处理系统100的框图,处理系统100可以安装在主机设备中。如图所示,处理系统100包括处理器102、存储器104和接口106至110,它们可以(或可以不)如图1所示排列。处理器102可以是用于执行计算和/或其它处理相关任务的任何组件或组件集合,存储器104可以是用于存储程序和/或指令以供处理器102执行的任何组件或组件集合。在一实施例中,存储器104包括非瞬时性计算机可读介质。接口106、108、110可以是允许处理系统100与其它设备/组件和/或用户进行通信的任何组件或组件集合。例如,接口106、108、110中的一个或多个接口可以用于将数据消息、控制消息或管理消息从处理器102传送给安装在主机设备和/或远程设备上的应用程序。再例如,接口106、108、110中的一个或多个接口可用于允许用户或用户设备(例如个人计算机(personal computer,pc)等)与处理系统100进行互动/通信。处理系统100可包括未在图1中描绘的其它组件,例如长期存储器(例如非易失性存储器等)。
[0065]
图1b示出了实施例多媒体推荐系统150的框图。多媒体推荐系统150包括主模块152、内容存储库154、线索存储库156、用户偏好存储库158、排序模型(或推荐引擎)160和用户接口162。主模块152通过排序模型160对存储在内容存储库154中的多媒体内容执行排序,并通过用户接口162向用户呈现多媒体内容。主模块152可以耦合到传感器控制器,以接收感应数据和/或控制(开启、停止、打开、关闭等)连接的传感器设备。
[0066]
多媒体内容可以根据与多媒体内容相关联的线索以及用户偏好来排序。线索可以存储在线索存储库156中并且与内容存储库154中的多媒体内容相关联。例如,在相关联的多媒体内容完全生成之前,为了响应于(或者实质上当)制作相关联的多媒体内容(时),可
以生成表示与多媒体内容(例如图片或视频)相关联的线索的元素或特征。在一些实施例中,内容存储库154、线索存储库156和用户偏好存储库158都可以共同位于同一数据库等存储库中。排序模型160可以根据线索和用户偏好来周期性地更新。
[0067]
图2示出了实施例多媒体图库200。多媒体图库200显示照片、视频和音乐。多媒体图库200划分为若干个视图,并且包括全照视图202和自动收藏视图204。全照视图202包含用户通过设备已经捕获的所有照片。虽然多媒体图库200示出了照片的四种视图,但是应当了解,多媒体图库200可以包含其它视图并且能够显示和自动推荐许多类型的多媒体内容。
[0068]
自动收藏视图204包含多媒体图库200基于用户的行为和交互式输入向用户推荐为有意义内容的照片。因此,全照视图202通常比自动收藏视图204包含更多的照片。例如,在示出的实施例中,多媒体图库200在全照视图202中有5508张照片,但其中只有89张照片在自动收藏视图204中自动推荐给用户。虽然多媒体图库200示为移动用户设备上的应用程序,但是应当了解,多媒体图库200及在其上执行的方法可以集成到各种各样的产品中,例如智能手机、平板电脑、摄像机和照片管理软件。
[0069]
自动收藏视图204可以通过分析用户的行为和交互式输入以得到线索来进行填充。可以在用户查看或捕获多媒体时分析用户面部表情或视线等行为线索。例如,当用户查看多媒体文件时检测用户面部表情中的微笑或皱眉可以提供重要线索,指示该多媒体文件对用户是有意义的。同样地,当用户查看多媒体内容时可以分析用户的视线,以确定照片中的“热点”,例如最喜爱的人或对象。
[0070]
用户的交互式线索还可以在用户查看多媒体内容时进行分析。例如,可以对用户查看特定多媒体内容所花的总时间进行计算和分析以确定该多媒体内容是否有意义。还可以考虑和分析其它交互式指标以获得子线索。这些指标可以包括确定用户是否已经共享、编辑、放大或定向多媒体内容。
[0071]
还可以在用户捕获多媒体,例如拍照或录视频时分析用户的环境或情景输入以获得线索。分析获得环境线索可以包括捕获和识别语音和背景噪声,以确定拍照或录视频时发生的事件。例如,当用户拍照时检测到背景里的生日歌,这可以是表示该照片对用户相对更有意义的环境线索。还可以使用人脸识别,以检测用户知道的照片或视频主体。例如,可以对捕获到的照片执行人脸识别,然后与用户的联系人列表或地址簿中的头像进行匹配。在这一示例中,检测照片中亲密家庭成员的存在可以是更有力地表示该照片对用户有意义的环境线索。
[0072]
多媒体图库200还可支持多个用户,使得可以向特定用户推荐有意义的多媒体。例如,可以检测到操作多媒体图库200的用户,并且自动收藏视图204填充有针对该用户的个性化推荐。当用户操作多媒体图库200时可以通过人脸或语音识别来检测用户。
[0073]
图3示出了实施例多媒体推荐方法300。多媒体推荐方法300可以在用户通过设备浏览或捕获多媒体内容时由该设备执行。例如,多媒体推荐方法300可以在用户操作多媒体图库200时执行。
[0074]
多媒体推荐方法300开始于获取用户设备上的传感器设备的状态(步骤302)。在一些实施例中,在呈现多媒体图库200时可以禁止访问设备上的传感器。例如,可以禁止在设备上访问麦克风。接着,确定操作模式(步骤304)。用户设备可以在捕获模式下进行操作,捕获多媒体内容,也可以在浏览模式下进行操作,查看多媒体内容。用户可以选择操作模式,
例如,用户可以选择他们想要浏览还是捕获多媒体。在一些实施例中,操作模式可以根据检测到的传感器设备的状态自动选择或限制。例如,可以禁止在设备上访问前置摄像头或后置摄像头。在这类实施例中,可以限制操作模式为浏览模式。在一些实施例中,可以在某些操作模式下禁止访问设备。例如,用户可以选择在捕获模式下禁用设备的前置摄像头,但在浏览模式下启用设备的前置摄像头。
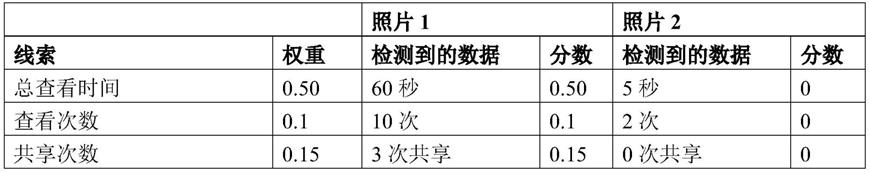
[0075]
接着,创建和/或打开用户配置文件(步骤306)。如果当前用户没有配置文件,可以在打开前先创建。用户配置文件可以包含允许多媒体内容基于对用户有意义的标准(例如根据接收到的用户反馈)推荐给用户的线索分析的偏好和结果。相应地,可以构建推荐标准为每个用户制定个性化的多媒体推荐。
[0076]
接着,在多媒体操作期间捕获用户的行为、交互和/或反馈(步骤308)。多媒体操作可以包括与多媒体内容的用户接口的交互(例如呈现、选择和浏览操作)和/或通过至少一个感应设备,例如摄像头、麦克风或其它适用传感器,捕获(例如产生或生成)多媒体内容。当用户正在捕获或查看多媒体内容时,行为和交互式输入可以通过从设备上的传感器接收数据来进行捕获,还可以基于用户与特定多媒体内容的交互来进行确定。当用户正在查看多媒体内容时,反馈可以通过向用户呈现多媒体推荐并提示他们反馈来进行捕获。当用户正在捕获或浏览多媒体内容时可以在后台周期性或连续地捕获行为、交互和/或反馈。在一些实施例中,稍后可以存储和分析捕获到的行为、交互和/或反馈的原始数据。在一些实施例中,可以实时分析数据。
[0077]
接着,在捕获到的用户行为、交互和/或反馈中确定线索(步骤310)。线索可以包括,例如用户在查看或捕获多媒体内容时微笑或皱眉的指示。在由设备上的传感器捕获的输入中确定行为和交互线索。例如,行为线索可以包括用户在查看或捕获特定多媒体内容时微笑或皱眉的指示。同样地,交互线索可以包括用户查看特定多媒体多次、共享多媒体、编辑多媒体等的指示。类似地,反馈线索可以包括用户同意或不同意多媒体推荐的指示。虽然已经结合特定类型的行为和交互线索描述了各种实施例,但是应当了解,可以捕获和确定各种各样的线索。
[0078]
最后,根据确定的线索向用户提供多媒体内容推荐(步骤312)。多媒体推荐可以根据为用户配置文件构建的并且包括确定的线索的模型来提供。可以在用户操作设备时通过机器习得的反馈来更新该模型。例如,更新该模型可以包括基于用户的使用模式调整各种线索的权重。
[0079]
图4示出了实施例用户配置文件访问方法400。用户配置文件访问方法400可以是发生在多媒体推荐方法300的步骤306中创建或打开用户配置文件时的操作的更细化说明。
[0080]
用户配置文件访问方法400开始于确定用户的脸部是否可识别(步骤402)。人脸识别可以用于识别用户的脸部并将其与已知脸部的数据库匹配。如果识别不了用户的脸部,那么为用户创建新的配置文件(步骤404)。一旦用户被识别或创建,则打开对应于识别用户的用户配置文件(步骤406)。一旦打开用户配置文件,则用户配置文件访问方法400结束。
[0081]
图5a示出了实施例行为和交互记录方法510。行为和交互记录方法510可以是发生在多媒体推荐方法300的步骤308中捕获用户行为、交互和反馈时的操作的更细化说明。可以在用户正捕获多媒体内容时执行行为和交互记录方法510。
[0082]
行为和交互记录方法510开始于在捕获多媒体内容时捕获周围线索(步骤512)。可
以对周围线索执行环境识别,以确定捕获到的多媒体内容是否更有可能对用户有意义。例如,如果用户在生日派对上捕获一张照片,则可以使用音频识别来检测周围线索中的生日歌,这表示捕获到的照片将比其它照片对用户更有意义的可能性相对较高。同样地,可以在用户通过后置摄像头捕获照片时通过前置摄像头捕获用户的面部表情。可以执行用户表情的人脸识别来检测用户的某些面部表情,例如微笑或大笑。某些面部反应可以表示捕获到的照片将比其它照片对用户更有意义的可能性相对较高。
[0083]
一旦捕获到周围线索,则根据环境模型和线索对多媒体内容排序(步骤514)。环境模型可以对各种周围线索排序和总计,为捕获到的照片或视频产生一个分数。一旦通过周围线索对多媒体内容排序,则行为和交互记录方法510结束。
[0084]
图5b示出了实施例行为和交互记录方法530。行为和交互记录方法530可以是发生在多媒体推荐方法300的步骤308中捕获用户行为、交互和反馈时的操作的更细化说明。行为和交互记录方法530可以在用户浏览或捕获多媒体内容时执行。
[0085]
行为和交互记录方法530开始于确定是否已经收集足够信息来生成对有意义多媒体的推荐(步骤532)。
[0086]
如果还没有收集充足信息,则在用户浏览多媒体时捕获用户的行为以检测行为线索(步骤534)。然后通过行为模型和行为线索对多媒体内容进行排序(步骤536)。行为模型可以基于各种行为线索的组合(例如通过加权的求和运算)为捕获到的照片或视频产生一个分数。
[0087]
还在用户浏览多媒体时捕获用户的交互以检测交互线索(步骤538)。然后通过交互模型和交互线索对多媒体内容进行排序(步骤540)。交互模型可以组合(例如排序和总计)各种交互线索,从而为捕获到的照片或视频产生一个分数。
[0088]
如果收集了充足信息,则生成多媒体推荐并向终端用户呈现以得到反馈(步骤542)。可以向用户呈现多媒体,并提示用户保存或丢弃推荐。然后通过后处理模型和反馈对多媒体内容进行排序(步骤544)。后处理模型可以对各种用户反馈排序和总计,从而为可能向用户呈现的其它多媒体内容产生一个分数。因此,用户反馈可用于机器学习过程。一旦捕获到用户的反馈、行为和/或交互线索并通过各种模型产生推荐,则行为和交互记录方法530结束。
[0089]
图6示出了实施例用户行为记录方法600。用户行为记录方法600可以是发生在行为和交互记录方法530的步骤534中捕获正在浏览多媒体的用户的行为时的操作的更详细说明。
[0090]
用户行为记录方法600开始于确定用户是否已经滑动到查看下一多媒体文件(步骤602)。如果用户滑动到下一多媒体文件,则在用户滑动时捕获和识别用户的面部表情(步骤604)。如果多媒体文件是一个视频,那么可以通过视频回放来捕获用户的面部表情。一旦捕获到且识别出用户的面部表情,那么对面部表情分类并加时间戳(步骤606)。例如,用户滑动到新照片时的用户表情可以分类为微笑或皱眉,并且该微笑或皱眉可以通过指示用户何时查看照片以及对照片微笑或皱眉的时间戳来进行保存。
[0091]
如果用户还没滑动到下一多媒体文件,那么用户行为记录方法600确定用户是否注视当前多媒体文件多于预定时间量ts(步骤608)。在一些实施例中,ts为约2秒。如果用户查看照片或视频多于预定时间量ts,那么确定屏幕和对应多媒体的热点(步骤610)。用户行
为记录方法600在确定多媒体热点之后或者在识别和分类用户的面部表情后结束。然后,在行为和交互记录方法530的步骤536中通过行为模型对用户行为记录方法600得到的行为线索进行排序。
[0092]
图7示出了实施例面部表情分类方法700。面部表情分类方法700可以是发生在用户行为记录方法600的步骤606中将面部表情分类时的操作的更详细说明。
[0093]
面部表情分类方法700开始于确定用户的脸部是否有正面的面部反应(步骤702)。正面的面部反应可以是用户正在看照片或视频时捕获到的大笑类表情等。如果检测到正面反应,则作为正面的面部反应线索与时间戳一起存储(步骤704)。该正面反应和时间戳与用户当前正在查看的多媒体内容相关联。
[0094]
如果没有检测到正面反应,那么面部表情分类方法700继续确定用户的脸部是否有负面的面部反应(步骤706)。负面的面部反应可以是用户正在查看照片或视频时捕获到的皱眉类表情等。如果发现负面反应,则作为负面的面部反应线索与时间戳一起存储(步骤708)。如果用户正在查看多媒体时检测到正面反应或者负面反应,那么“无面部反应”线索与时间戳一起存储(步骤710)。存储的表情可以与用户正在查看的多媒体内容相关联。一旦对面部反应线索或无面部反应线索进行存储和加时间戳,面部表情分类方法700结束。在行为和交互记录方法530的步骤536中,所产生的面部反应线索可以与通过行为模型进行排序的行为线索包含在一起。
[0095]
图8示出了实施例视线跟踪方法800。视线跟踪方法800可以是发生在用户行为记录方法600的步骤610中确定屏幕和对应照片的热点时的操作的更详细说明。
[0096]
视线跟踪方法800开始于搜索多媒体文件中的热点(步骤802)。热点可以是用户正在注视的多媒体文件中的位置。例如,用户可以看着包含若干人的照片中的某个人。跟踪用户的视线,直到检测到设备显示器上的热点。一旦检测到某热点,则多媒体文件与设备显示器上的热点位置进行协调(步骤804)。例如,如果用户正在看设备显示器的某个角落,那么可以将该图像与设备显示器进行协调以确定用户正在注视的图像中的特定主体或对象。一旦协调了照片或视频,则识别出该热点(步骤806)。热点识别可以包括,例如执行人脸识别以确定用户在热点中注视什么。一旦识别并确定出热点中的主体,则针对多媒体文件存储热点线索(步骤808)。在存储热点线索之后,视线跟踪方法800结束。在行为和交互记录方法530的步骤536中,所产生的热点线索可以与通过行为模型排序的行为线索包含在一起。
[0097]
图9示出了实施例用户交互记录方法900。用户交互记录方法900可以是发生在行为和交互记录方法500的步骤538中捕获正在浏览多媒体的用户的交互或线索时的操作的更详细说明。可以在用户正在设备上查看照片或视频时执行用户交互记录方法900。
[0098]
用户交互记录方法900开始于确定用户是否已滑动到新照片(步骤902)。如果用户滑动到新照片,那么读取照片元数据(步骤904)。一旦读取到照片元数据,则记录并存储用户花在查看照片的时间量(步骤906)。一旦存储了查看时间,则搜索用户与照片的交互以得到正面子线索(步骤908)。照片的正面子线索可以包括用户编辑、发布、共享或定向照片的指示,如将在下文更详细所述。一旦检测到正面子线索,那么可以存储该子线索(步骤910)。
[0099]
如果用户还没有滑动到新照片,那么用户交互记录方法900确定用户是否已滑动到新视频(步骤912)。一旦用户已滑动到新视频,则搜索用户与视频的交互以得到正面子线索(步骤914)。视频的正面子线索可以包括用户暂停或倒回视频的标记。一旦发现视频的正
面子线索,则存储视频的正面子线索(步骤916)。
[0100]
一旦存储了正面的照片或视频子线索,则用户交互记录方法900结束。在行为和交互记录方法530的步骤540中,从用户交互记录方法900产生的交互线索可以通过交互模型进行排序。
[0101]
图10a示出了实施例照片子线索检测方法1010。照片子线索检测方法1010可以是发生在用户交互记录方法900的步骤908中搜索用户与照片交互中的正面子线索时的操作的更详细说明。照片子线索检测方法1010可检测用户是否编辑过照片。
[0102]
照片子线索检测方法1010开始于确定用户是否已编辑过照片(步骤1012)。照片编辑可包括诸如裁剪照片或在图像处理套件中操作该照片等动作。如果照片的元数据指示该照片是由除用户设备的后置摄像头之外的设备捕获到的等情况下,可以检测到照片编辑。如果用户已编辑过该照片,那么存储照片的正面编辑反应线索(步骤1014)。如果用户还没有编辑过该照片,那么不存储编辑反应线索。在存储编辑反应线索之后,照片子线索检测方法1010结束。通过确定用户是否编辑过该照片,照片子线索检测方法1010因此估计照片是否对用户足够有意义,使得他们想要美化该照片。
[0103]
图10b示出了实施例照片子线索检测方法1030。照片子线索检测方法1030可以是发生在用户交互记录方法900的步骤908中搜索用户与照片交互中的正面子线索时的操作的更详细说明。照片子线索检测方法1030可检测用户是否共享过照片。
[0104]
照片子线索检测方法1030开始于确定用户是否共享过照片(步骤1032)。照片共享可以包括邮件发送该照片、通过sms发送该照片或者将该照片发表到社交媒体网站等动作。如果用户已经共享过该照片,那么存储照片的正面共享反应线索(步骤1034)。如果用户还没有共享该照片,那么不存储共享反应线索。在存储共享反应线索之后,照片子线索检测方法1030结束。通过确定用户是否共享过该照片,照片子线索检测方法1030因此估计照片是否对用户足够有意义,而使得他们想要与家人或朋友共享该照片。
[0105]
图10c示出了实施例照片子线索检测方法1050。照片子线索检测方法1050可以是发生在用户交互记录方法900的步骤908中搜索用户与照片交互中的正面子线索时的操作的更详细说明。照片子线索检测方法1050可检测用户是否放大过照片。
[0106]
照片子线索检测方法1050开始于确定用户是否放大过照片(步骤1052)。放大照片可以通过缩放设备显示器在缩放点放大等方式来实现。如果用户放大过该照片,那么存储该照片的正面放大反应线索(步骤1054)。如果用户还没有放大过该照片,那么不存储放大反应线索。在存储放大反应线索之后,照片子线索检测方法1050结束。通过确定用户是否放大过照片,照片子线索检测方法1050因此估计照片是否对用户足够有意义,而使得他们想要更清楚地查看该照片。
[0107]
图10d示出了实施例照片子线索检测方法1070。照片子线索检测方法1070可以是发生在用户交互记录方法900的步骤908中搜索用户与照片交互中的正面子线索时的操作的更详细说明。照片子线索检测方法1070可检测用户是否旋转过照片的方向。
[0108]
照片子线索检测方法1070开始于在最初查看照片时记录照片的方向(步骤1072)。例如,照片可能是在竖屏或横屏上进行拍摄的。在不同于设备显示器的方向上拍摄的照片可以在设备上显示时进行旋转。一旦已经记录最初的照片方向,则将其与用户设备显示器的当前方向进行比较,以确定照片是否在不同于用户设备显示器的方向上进行拍摄的(步
骤1074)。如果照片的最初方向和用户设备显示器的方向相同,那么照片子线索检测方法1070结束。
[0109]
如果照片的最初方向和用户设备显示器的方向不同,那么照片子线索检测方法1070继续确定用户是否旋转过用户设备以改变设备的显示方向(步骤1076)。确定方向旋转可以通过集成到用户设备中的加速计的感应变化等来实现。如果用户未旋转过设备以改变显示方向,那么照片子线索检测方法1070结束。
[0110]
如果用户旋转过设备来改变显示方向,那么照片子线索检测方法1070继续存储照片的正面的旋转反应线索(步骤1078)。一旦存储了正面的旋转反应线索,则照片子线索检测方法1070结束。通过确定用户是否旋转过设备以匹配照片的原始方向,照片子线索检测方法1070因此估计照片是否对用户足够有意义,而使得他们想要更清楚地查看该照片。
[0111]
图11示出了实施例用户反馈和预测方法1100。用户反馈和预测方法1100可以是发生在用户行为和交互记录方法530的步骤542中生成推荐并呈现给用户以得到反馈时的操作的更详细说明。
[0112]
用户反馈和预测方法1100开始于向用户呈现建议的多媒体(步骤1102)。一旦向用户呈现多媒体,则请求用户的反馈,并且分析该反馈以确定用户同意还是不同意该建议(步骤1104)。用户反馈可以是向用户呈现多媒体时覆盖在其上的喜欢或不喜欢按钮。如果用户同意该建议,那么存储该建议的正面反馈线索(步骤1106)。然而,如果用户不同意该建议,那么存储该建议的负面反馈线索(步骤1108)。一旦存储了多媒体的反馈线索,则用户反馈和预测方法1100结束。
[0113]
如上结合图2所述,自动收藏视图204可以根据特定用户的预测意义提供推荐。不同的输入线索对特定用户更有意义。通过向用户呈现多媒体建议以及接收用户反馈,用户反馈和预测方法1100允许用户设备来确定哪些线索对特定用户相对更有意义。例如,编辑或共享照片子线索(结合图10a至图10b所述)可能对第一类用户更有意义,而照片放大和定向子线索(结合图10c至图10d所述)可能对第二类用户更有意义。用户反馈和预测方法1100因此可以是学习哪些线索和子线索对特定用于更有意义的机器学习过程的一部分。线索和子线索对每个用户的意义性可以存储在与每个用户相关联的配置文件中,然后当用户操作设备时(结合图4所述)与用户配置文件一起进行加载。
[0114]
图12示出了实施例线索排序方法1200。线索排序方法1200可以是发生在根据如上论述的各种模型,例如图5a的步骤514或图5b的步骤536、540或544,对线索或子线索排序时的操作的更详细说明。
[0115]
线索排序方法1200开始于确定是否有充足的数据样本对用户的线索或子线索进行排序(步骤1202)。可以通过将数据样本数量与阈值数量进行比较来确定数据样本是否充足。如果有充足的数据样本,那么归一化线索的权重(步骤1204)。一旦归一化线索的权重,则分析设备上的多媒体文件,并且为每个多媒体文件生成一个分数(步骤1206)。在为每个多媒体文件生成分数之后,选择得分前5%的多媒体作为推荐,并添加到自动收藏视图中(步骤1208)。一旦自动收藏视图填充有推荐的多媒体,则将推荐的多媒体呈现给用户,并提示用户进行反馈(步骤1210)。呈现给用户的反馈提示可包括喜欢或不喜欢按钮等。一旦将推荐的多媒体呈现给用户,则线索排序方法1200确定用户是否已经对推荐的多媒体提出反馈(步骤1212)。如果用户没有提出反馈,那么线索排序方法1200结束。
[0116]
如果用户提出了反馈,那么线索排序方法1200继续将反馈用作学习输入并重复线索排序方法1200的步骤(步骤1212)。如上结合图11所述,不同的输入线索可能对特定用户更有意义。将反馈用作学习输入可以包括基于用户响应于在步骤1210中呈现的推荐多媒体而提出的反馈来确定哪些线索或子线索对特定用户更有意义。学习输入可以通过重复线索排序方法1200的步骤数次来进行完善,每次都有更新的学习输入。重复该过程可以更准确地确定对特定用户更有意义的线索和子线索。
[0117]
图13示出了实施例线索权重归一化方法1300。线索权重归一化方法1300可以是发生在线索排序方法1200的步骤1204中归一化线索的权重时的操作的更详细说明。
[0118]
线索权重归一化方法1300开始于读取标准权重表(步骤1302)。标准权重表可以由用户设备预定或存储在用户设备上,并且可以充当完善用于生成学习输入的反馈的起点。标准权重表包括期望从典型用户,例如“模型用户行为”,得到的行为和交互输入的权重,。一旦读取了标准权重,则计算输入线索中的所有可用反馈中的正面反馈的百分比(步骤1304)。在计算完正面反馈的百分比之后,与阈值t
f1
进行比较以确定正面反馈的百分比是否超过t
f1
(步骤1306)。在一些实施例中,阈值t
f1
为输入线索中约60%的正面反馈。
[0119]
如果输入线索中的正面反馈的百分比超过阈值t
f1
,那么降低线索的权重(步骤1308)。线索的权重可以通过将每个线索的权重降低预定义步长来进行降低。每个线索的预定步长可以根据该线索的权重的百分位来确定。例如,权重中前10%的线索可以比权重中前50%的线索多降低一步长。可以降低线索的权重,直到每个线索的权重大致等于与该线索的下一权重降低相关联的步长。
[0120]
在降低线索的权重之后,或者如果正面反馈在输入线索中的百分比小于阈值t
f1
,那么重新计算正面反馈的百分比,并且与阈值t
f2
进行比较以确定正面反馈的百分比是否小于该阈值(步骤1310)。在一些实施例中,阈值t
f2
为输入线索中约30%的正面反馈。如果输入线索中正面反馈的百分比小于阈值t
f2
,那么提高线索的权重(步骤1312)。线索的权重可以通过将每个线索的权重增加预定义步长来进行提高。每个线索的预定步长可以根据该线索的权重的百分位来确定。例如,权重中后10%的线索可以比权重后50%的线索多提高一步长。
[0121]
一旦调整了线索的权重,那么归一化线索的权重(步骤1314)。可以通过对所有权重求和,然后将每个权重除以该和来归一化权重。在归一化线索的权重之后,将线索用作反馈以更新或修改标准权重表中的权重(步骤1316)。特定用户的行为将可能不会精确地跟踪标准权重表中的模型用户行为。因此,特定用户行为与模型用户行为之间的差异会使预测有偏差。调整标准权重表中的权重会缓解这种偏差。一旦执行标准权重调整,则线索权重归一化方法1300结束。
[0122]
图14示出了实施例分数生成方法1400。分数生成方法1400可以是发生在线索排序方法1200的步骤1206中为每个照片或视频生成分数时的操作的更详细说明。
[0123]
分数生成方法1400开始于确定线索是一个二进制值还是一个字值(步骤1402)。当线索仅表示真值或假值时,该线索是二进制的,其与正面反应或负面反应是否相关联。二进制线索可以包括执行用户行为的人脸识别时正在检测的微笑或者皱眉等线索。如果线索是一个二进制值,那么对于正面结果赋值分数1给该线索,对于负面结果赋值分数0给该线索(步骤1404)。
[0124]
如果线索不是一个二进制值,那就是一个字值。线索在测量离散指标时是一个字值。字线索可以包括查看时间、视图数量、共享给社交媒体的数量等线索。如果线索是一个字值,那么计算线索的最大值(步骤1406)。通过确定所有考虑图像内的线索的最大值来计算线索的最大值。例如,通过测量每个考虑图像的查看时间来确定查看时间线索的最大值,然后将这些测量中最大的取值作为最大值。在一些实施例中,不是每次都计算最大值,而是定期计算并存储特定线索的最大值,然后在需要时进行检索。在计算或检索线索的最大值之后,通过将线索的当前值除以线索的最大值来归一化线索值(步骤1408)。例如,如果其中一个考虑线索是查看时间,而且查看时间的最大值确定为60秒,那么对于查看时间为45秒的照片,该照片的查看时间线索的归一化值会计算为:45
÷
60=0.75。
[0125]
一旦将分数赋值给每张照片或视频的每个线索,则通过将每个线索的归一化值乘以该线索的权重来计算原始分数(步骤1410)。继续上述照片的示例,如果查看时间线索的权重确定为0.5,那么照片的查看时间线索的原始分数会计算为:0.5
×
0.75=0.375。
[0126]
一旦为每个图像的每个线索计算出原始分数,则为照片或视频计算相关性分数(步骤1412)。通过将照片或视频的一个或多个线索与参考照片或视频进行对比来计算相关性分数。相关性分数有助于强化预测置信,以成为更高置信预测或用户反馈中的识别模式。接着,基于用户反馈为每个线索计算学习因子(步骤1414)。用户反馈可以是通过用户反馈和预测方法1100等获得的反馈。最后,通过将原始分数、相关性分数和学习因子求和来计算图像分数(步骤1414)。因此根据以下公式计算图像分数:
[0127][0128]
其中s
img
为图像分数,t为线索的总数量,wn为线索的权重,pn为线索的值,wc为相关性线索的权重,pc为相关性线索的值,f为学习因子。一旦计算出图像分数,则分数生成方法1400结束。然后对比图像分数,并且将得分最高的图像推荐给用户。
[0129]
下文示出的表1示出了两个使用实施例技术的示例图像的得分结果:
[0130][0131][0132]
表1
[0133]
可以在上面的图1中看出,根据两个示例照片的权重和值对其进行排序。照片1具
有较长的查看时间并且已经多次共享、查看、方向调整和放大。相应地,照片1的图像分数计算为0.99,表示该照片对用户有意义的可能性相对较高。相反地,照片2具有较少的查看时间并且很少共享、查看、方向调整和放大。相应地,照片2的图像分数计算为0.02,表示该照片对用户有意义的可能性相对较低。因此,会推荐照片1给用户,而不会推荐照片2给用户。
[0134]
尽管进行了详细的描述,但应理解,可在不脱离由所附权利要求书界定的本发明的精神和范围的情况下,对本文做出各种变更、替代和更改。此外,本发明的范围不限于本文中所描述的特定实施例,所属领域的普通技术人员将从本发明中容易了解到,过程、机器、制造、物质成分、构件、方法或步骤(包括目前存在的或以后将开发的)可执行与本文所述对应实施例大致相同的功能或实现与本文所述对应实施例大致相同的效果。相应地,所附权利要求范围旨在包括这些流程、机器、制造、物质成分、构件、方法或步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1