结合卷积神经网络和轻型自适应中值滤波视频降噪方法
1.本发明涉及视频处理技术领域,特别涉及一种结合卷积神经网络和轻型自适应中值滤波视频降噪方法,用于去除视频椒盐噪声。
背景技术:
2.视频图片在网络采集、传输及接收的全过程中,由于处在复杂的各种外部环境中,存在各种干扰,这些复杂的干扰因素都有可能会对图像形成噪声。而椒盐噪声是一种常见的图像脉冲污染,一般来说,被椒盐噪声污染的像素会被数字化成最大或最小强度。椒盐噪声污染产生的主要原因是图像采集和记录过程中出现的误差。例如,廉价、低成本的传感器广泛应用于监控摄像头,导致像素的a/d转换易出现故障,恶劣的天气和通信信道的质量不佳都会成为产生椒盐噪声的诱因。这些噪点对后续的图像识别,边缘检测,目标跟踪等任务都有很大的负面影响,因此在图像预处理过程中,抑制图像中椒盐噪声实现高质量图像的恢复是一个非常重要的环节。
3.对于椒盐噪声污染的图像,中值滤波被认为是最有效的降噪方法,但是中值滤波在没有考虑局部特征的情况下会导致图像模糊。因此,为了解决这一局限性,很多基于中值滤波的改进方法也被提出,例如加权中值滤波、中央加权中值滤波、方向加权中值滤波和开关中值滤波等,但以上方法在图像被低密度椒盐噪声污染时,可以较好的恢复图像,但无法很好处理图像被高密度椒盐噪声污染的情况。针对此问题,自适应中值滤波器被提出,它能够滤除高密度的椒盐噪声,但它不能很好的保留图像细节且以高计算时间为代价。
技术实现要素:
4.本发明要解决的技术问题是:提供一种结合卷积神经网络和轻型自适应中值滤波视频降噪方法,来有效抑制视频图像中的椒盐噪声,恢复出高质量的视频图像。
5.为实现上述目的,本发明首先针对传统自适应中值滤波因高密度椒盐噪声情况下需要自适应选择滤波模板而增加时间开销的问题,提出轻型自适应中值滤波算法。其次,将轻型自适应中值滤波算法看成一种神经网络操作,成为轻型自适应中值滤波层,并和降噪卷积神经网络进行结合。先利用轻型自适应中值滤波层对噪声视频图像进行滤波得到初步降噪视频图像,然后将初步降噪视频图像输入降噪卷积神经网络进行训练,使通过降噪卷积神经网络学习得到的模型从初步降噪视频图像中学习噪声的分布。最后将待降噪的噪声视频图像输入到轻型自适应中值滤波层和训练好的模型中,通过计算得到降噪后的视频图像。
6.进一步的,本发明提出的一种结合卷积神经网络和轻型自适应中值滤波视频降噪方法具体包括如下步骤:
7.步骤1:简化传统自适应中值滤波算法,得到轻型自适应中值滤波算法;
8.步骤2:将轻型自适应中值滤波算法看成一种神经网络操作,生成轻型自适应中值滤波层;
9.步骤3:获取训练数据集,所述训练数据集中的每一个训练样本包括一张噪声视频图像及其对应的无噪声视频图像,将所述训练数据集中的任意一张噪声视频图像y作为轻型自适应中值滤波层的输入,经过轻型自适应中值滤波层处理后得到初步降噪视频图像y
med
;
10.步骤4:构建降噪卷积神经网络;
11.步骤5:将l1范数作为所述降噪卷积神经网络的损失函数;
12.步骤6:将初步降噪视频图像y
med
作为所述降噪卷积神经网络的输入,将噪声视频图像y与其对应的无噪声视频图像x作为网络标签,对所述降噪卷积神经网络进行训练,得到初步降噪视频图像y
med
到噪声分布v的映射关系;
13.步骤7:对所述训练数据集中的所有噪声视频图像均执行完步骤3-步骤6的操作称为一轮迭代,取当轮迭代中所有噪声视频图像的初步降噪视频图像到其噪声分布的映射关系的算术平均数作为当轮迭代初步噪声视频图像与噪声分布的映射关系;当迭代次数达到预设值50时,停止训练,得到所述降噪卷积神经网络中最终的初步噪声视频图像与噪声分布的映射关系r
final
(*),进而得到训练好的降噪卷积神经网络。
14.步骤8:将待降噪的噪声视频图像通过轻型自适应中值滤波层得到初步降噪视频图像然后将初步降噪视频图像输入到训练好的降噪卷积神经网络得到噪声分布然后将初步降噪视频图像减去训练好的降噪卷积神经网络输出的噪声分布得到降噪后的视频图像
15.具体地,所述步骤1中的轻型自适应中值滤波算法为基于传统自适应中值滤波算法的简化算法。对噪声视频的每一帧图像利用轻型自适应中值滤波算法处理包括:
16.将椒盐噪声污染的任意一帧噪声视频图像作为当前待处理噪声视频图像y;
17.对于当前待处理噪声视频图像y中位于第i行第j列的像素点y
i,j
,选择以y
i,j
为中心的大小w=3
×
3的滤波模板s;
18.计算滤波模板s内所有像素的最大值中值和最小值
19.如果则表明y
i,j
不是噪声点,保留。否则用代替;
20.针对当前待处理噪声视频图像y中的每个像素点做上述同样的操作,最后输出初步降噪
21.视频图像y
med
。对于y
med
中的每个像素点有:
[0022][0023]
具体地,所述步骤2中轻型自适应中值滤波层以滑动窗口形式处理噪声视频图像所有像素的全部特征通道。
[0024]
具体地,所述步骤3中噪声视频图像y经过轻型自适应中值滤波层处理后的y
med
为:
[0025]ymed
=f(y)
[0026]
这里y为噪声视频图像,f(*)为对噪声视频图像y中每个像素执行轻型自适应中值滤波算法处理。
[0027]
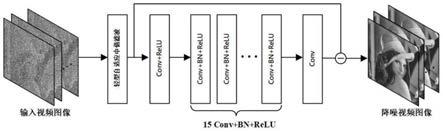
具体地,所述步骤4中所述降噪卷积神经网络包括17层,其中,第0层为卷积层与激活层的组合,第1层到15层的每层为卷积层、归一化层与激活层的组合,第16层为卷积层。
[0028]
具体地,所述步骤4中所述降噪卷积神经网络中所有卷积层的卷积核大小为3
×
3,步长为1,所有激活层采用relu函数,所有归一化层采用batch normalize函数。
[0029]
具体地,所述步骤5中的降噪卷积神经网络的损失函数l1范数为:
[0030][0031]
其中,xi′
为与噪声视频图像y对应的无噪声视频图像x的第i'个像素值,yi′
为噪声视频图像y的第i'个像素值,为y经过轻型自适应中值滤波层后输出的第i'个像素值,n为噪声视频图像y中的像素值的总个数,||*||1代表1-范数,r(*)表示与其噪声分布的映射关系。
[0032]
具体地,所述步骤8降噪后的视频图像为:
[0033][0034]
本发明提出了一种结合卷积神经网络和轻型自适应中值滤波视频降噪方法,用于去除图像椒盐噪声,将传统自适应中值滤波进行简化并将其视为一种卷积操作与卷积神经网络相结合。首先,简化传统自适应中值滤波算法,选择固定尺寸的滤波模板,缓解高密度噪声污染情况下自适应选择滤波模板尺寸增加时间开销的问题,同时也能滤除大部分噪声,且在弱噪声情况下能够尽量保留图像细节。然后将轻型自适应中值过滤的操作合并到卷积神经网络中,利用深层卷积神经网络有效挖掘图像特征的优点,训练成为一个可以统一处理各级椒盐噪声模型。此外,卷积神经网络模型非常适合部署在现代强大的gpu上,因此可以利用gpu来提高运行性能。实验结果表明,本发明提出的方法可以实现盲椒盐去噪,且在高密度椒盐噪声的干扰下也能有效恢复出高质量的图像。
附图说明
[0035]
图1为本发明实施例中降噪流程图;
[0036]
图2为本发明实施例中轻型自适应中值滤波算法的原理图;
[0037]
图3为本发明实施例中结合卷积神经网络和轻型自适应中值滤波的全卷积神经网络结构示意图。
具体实施方式
[0038]
下面根据附图和实施例详细阐述此发明,并对本发明的技术方案进行清楚的描述。此处所选的实施例仅用于解释该发明,并不能够限定此发明。
[0039]
针对现有基于中值滤波的图像椒盐降噪方法无法很好恢复被高密度椒盐噪声污染的视频图像。本发明提供了一种用于视频图像椒盐降噪的结合卷积神经网络和轻型自适应中值滤波全卷积神经网络的方法,以解决上述相关技术问题。本发明将传统自适应中值滤波算法进行简化,缓解高密度噪声污染情况下自适应选择滤波模板尺寸增加时间开销的问题,同时也能滤除大部分噪声,且在弱噪声情况下能够尽量保留图像细节。然后将简化的
轻型自适应中值滤波视为一种卷积操作与卷积神经网络相结合,利用深层卷积神经网络有效挖掘图像特征的优点,训练成为一个可以统一处理各级椒盐噪声的模型。下面采用示例性的实施例进行详细说明。
[0040]
基于上述思想,本实施例提供了一种结合卷积神经网络和轻型自适应中值滤波视频降噪方法,用于去除图像椒盐噪声,其工作流程如图1所示,具体包括如下步骤:
[0041]
步骤1:简化传统自适应中值滤波算法,得到轻型自适应中值滤波算法,如图2所示,对噪声视频的每一帧图像利用轻型自适应中值滤波算法处理包括:
[0042]
将椒盐降噪污染的任意一帧噪声视频图像作为当前待处理图像y;
[0043]
对于当前待处理图像y中位于第i行第j列的像素点y
i,j
,选择以y
i,j
为中心的大小w=3
×
3的滤波模板s;
[0044]
计算滤波模板s内所有像素的最大值中值和最小值
[0045]
如果则表明y
i,j
不是噪声点,保留。否则用代替y
i,j
;
[0046]
针对当前待处理图像y的每个像素做上述同样的操作。
[0047]
步骤2:将轻型自适应中值滤波算法看成一种神经网络操作,生成轻型自适应中值滤波层;
[0048]
进一步地,所述步骤2中的轻型自适应中值滤波层以移动窗口的方式应用于每个元素的不同特征通道。例如,一个由rgb通道组成的输入图像,对应3个特征通道,对于输入图像所有像素的每个特征通道,采用轻型自适应中值滤波算法进行滤波。
[0049]
步骤3:获取训练数据集,所述训练数据集中的每一个训练样本包括一张噪声视频图像及其对应的无噪声视频图像,将所述训练数据集中的任意一张噪声视频图像y作为轻型自适应中值滤波层的输入,经过轻型自适应中值滤波层处理后得到初步降噪视频图像y
med
;
[0050]
进一步地,所述步骤3中噪声视频图像y经过轻型自适应中值滤波层处理后的初步降噪视频图像y
med
,可表示为:
[0051]ymed
=x+v
[0052]
这里v为噪声视频图像y中的真实噪声分布。
[0053]
步骤4:构建降噪卷积神经网络;
[0054]
进一步地,所述步骤4中降噪卷积神经网络包括17层,第0层为轻型自适应中值滤波层,第0层为卷积层与激活层的组合,第1层到15层的每层为卷积层,归一化层与激活层的组合,第16层为卷积层。
[0055]
进一步地,所述步骤4中降噪卷积神经网络中所有卷积层的卷积核大小为3
×
3,步长为1,所有激活层采用relu函数,所有归一化层采用batch normalize函数。
[0056]
步骤5:选择降噪卷积神经网络的训练损失函数为l1范数,所述训练损失函数l1范数的表达式为:
[0057][0058]
其中xi′
为噪声视频图像y对应的无噪声视频图像x的第i'个像素值,yi′
为噪声视
频图像y的第i'个像素值,为y经过轻型自适应中值滤波层后输出的第i'像素值,n为噪声视频图像y中的像素值的总个数,||*||1代表1范数,r(*)表示与噪声分布的映射关系。
[0059]
步骤6:将初步降噪视频图像y
med
作为降噪卷积神经网络的输入,将噪声视频图像y与对应的无噪声视频图像作为网络标签,对降噪卷积神经网络进行训练,得到初步降噪视频图像y
med
到噪声分布v的映射关系。
[0060]
步骤7:对所述训练数据集中的所有噪声视频图像均执行完步骤3-步骤6的操作称为一轮迭代,取当轮迭代中所有噪声视频图像的初步降噪视频图像到其噪声分布的映射关系的算术平均数作为当轮迭代初步噪声视频图像与噪声分布的映射关系;当迭代次数达到预设值50时,停止训练,得到所述降噪卷积神经网络中最终的初步噪声视频图像与噪声分布的映射关系r
final
(*),进而得到训练好的降噪卷积神经网络,如图3所示。
[0061]
步骤8:将待降噪的噪声视频图像通过轻型自适应中值滤波层得到初步降噪视频图像然后将初步降噪视频图像输入到训练好的降噪卷积神经网络模型得到噪声分布然后将初步降噪视频图像减去训练好的降噪卷积神经网络输出的噪声分布得到降噪后的视频图像。降噪后的视频图像为:
[0062][0063]
以下结合具体实例,对本实施例进行进一步地说明。
[0064]
第一步:选择添加椒盐噪声的视频数据库vot2019作为训练数据集,其中噪声水平(一张视频图片中受污染的像素个数占总像素的百分比)的范围为0.1~0.7。
[0065]
第二步:通过上述步骤2-7的计算方法,训练得到用于椒盐噪声去除的降噪卷积神经网络模型。
[0066]
第三步:选择无人机视频数据库dtb70中一张图像作为无噪声视频图像,然后添加70%噪声水平的椒盐噪声形成噪声视频图像,经过轻型自适应中值滤波层处理后得到初步降噪视频图像,然后将初步降噪视频图像输入到第二步得到的模型中,得到此时的噪声分布,然后将初步降噪视频图像减去降噪卷积神经网络输出的噪声分布得到降噪后的视频图像。
[0067]
为了进一步说明本发明方法的优越性,分别利用传统中值滤波和传统自适应中值滤波对同样的噪声视频图像进行降噪。采用峰值信噪比psnr作为降噪后视频图像的质量评价,psnr的值如表1所示。从表1可知,本发明所公开的方法的psnr值最高,降噪效果最好。
[0068]
表1不同降噪方法的psnr值
[0069][0070]
以上所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1