一种语音转写中结合用户文本的快速热词提取方法、装置、电子设备及存储介质与流程
1.本发明涉及语音技术领域,尤其涉及一种语音转写中结合用户文本的快速热词提取方法、装置、电子设备及存储介质。
背景技术:
2.在通用的语音识别技术中,由于行业领域数据较少的问题,在训练声学模型、语言模型时受到训练语料不足的限制,无法涵盖不同用户、不同行业的行业用词,特别是对专有名词、同音字词转写往往很难达到用户的期望结果,通用的语音识别技术只能转写为发音类似且在声学模型、语言模型训练语料中出现频率较高的字词,以至于得到错误的转写结果。
3.随着业界语音技术的不断突破以及近年来人们认知水平和需求的提高,大家对语音识别技术提出了越来越多的挑战,例如用户希望在自己行业领域中的语音识别效果也能接近通用语音的识别效果,并且避免进行声学模型、语言模型训练等费时而又繁琐的技术操作。
4.针对上述行业领域语音转写错误问题,除了添加大量用户行业领域的语料数据进行声学模型、语言模型训练来提高语音转写引擎的转写正确率,还可以通过设置语音转写热词库的方法,让语音转写引擎更倾向于识别出用户当前热词库中的热词,从而极大地提高一些不常见词或用户行业用词的转写正确率,提高用户满意度。
5.传统的设置语音转写热词库的方法,往往只能人工统计整理一个行业领域的热词库,并且该热词库不能区分高频词和低频词,无法区分不同热词的权重,另外由于人工统计整理它有耗时、效率低、热词覆盖面广度无法保证等问题。
6.正因如此,目前市面上通过设置热词来提高语音转写正确率的较少,一直受到用户热词提取相关技术问题的困扰。
技术实现要素:
7.本发明的目的是针对现有技术中存在的不足,提供一种语音转写中结合用户文本的快速热词提取方法、装置、电子设备及存储介质。
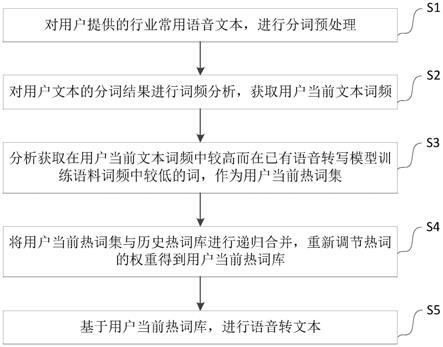
8.为实现上述目的,在第一方面,本发明提供了一种语音转写中结合用户文本的快速热词提取方法,包括以下步骤:
9.1)对用户提供的行业语音文本即用户文本,进行分词预处理;
10.2)对用户文本的分词预处理结果进行词频分析,获取用户当前文本词频;
11.3)分析获取在用户当前文本词频中大于设置的词频阈值n1,而在已有语音转写模型训练语料词频中小于设置的词频阈值n2的词,作为用户当前热词集;
12.4)将用户当前热词集与历史热词库进行递归合并,重新调节热词的权重得到用户当前热词库;
13.5)基于用户当前热词库,进行语音转文本。
14.优选的,所述步骤1)中分词预处理包括以下步骤:
15.所述分词预处理操作通过jieba分词工具完成,在分词预处理操作之前根据用户需求添加自定义词典,确保用户文本中的特殊词在分词处理时不被拆分,并根据用户需求设置停用词;
16.对用户文本合并汇总后,通过jieba分词工具进行分词处理,生成分词后的用户文本文件。
17.优选的,所述步骤2)中获取用户当前文本词频的具体步骤如下:
18.将所述分词后的用户文本文件通过语言模型训练工具srilm生成词频统计文件。
19.优选的,所述步骤3)中确定用户当前热词集的具体步骤如下:
20.分析筛选出用户当前文本词频统计文件中满足预置条件的词,即在用户当前文本词频中词频高于词频阈值n1而在语音转写模型训练语料词频中词频低于词频阈值n2的词,作为用户当前热词集。
21.优选的,所述步骤4)中重新获取用户当前热词库的具体步骤如下:
22.在用户当前热词集中去除与历史热词库中重复的热词;
23.将用户当前文本词频统计文件与历史文本词频统计文件合并,计算用户当前热词集与历史热词库所有热词在合并的文本词频统计文件中的出现概率;
24.根据用户当前热词集与历史热词库所有热词在合并的文本词频统计文件中的出现概率,进行递归合并得到该用户当前热词库,如果用户没有历史热词库,则用户当前热词集即为用户当前热词库;
25.然后依据用户当前热词库热词的出现概率自动重新调节热词权重,且用户自定义特殊热词的热词权重。
26.优选的,所述步骤5)中进行语音转文本的具体步骤如下:
27.导入含有用户当前热词库中的热词的语音,语音转写引擎更倾向于识别出用户当前热词库中的热词。
28.在第二方面,本发明提供了一种语音转写中结合用户文本的快速热词提取装置,包括:
29.用户文本预处理模块,用于对用户提供的行业语音文本即用户文本,进行分词预处理;
30.用户当前文本词频获取模块,用于对用户文本的分词预处理结果进行词频分析,获取用户当前文本词频;
31.用户当前热词集获取模块,用于分析获取在用户当前文本词频中大于设置的词频阈值n1,而在已有语音转写模型训练语料词频中小于设置的词频阈值n2的词,作为用户当前热词集;
32.用户当前热词库获取模块,用于将用户当前热词集与历史热词库进行递归合并,重新调节热词的权重得到用户当前热词库;
33.语音转写模块,用于基于用户当前热词库,进行语音转文本。
34.优选的,所述用户当前热词库获取模块用于在用户当前热词集中去除与历史热词库中重复的热词;
35.将用户当前文本词频统计文件与历史文本词频统计文件合并,计算用户当前热词集与历史热词库所有热词在合并的文本词频统计文件中的出现概率;
36.根据用户当前热词集与历史热词库所有热词在合并的文本词频统计文件中的出现概率,进行递归合并得到该用户当前热词库,如果用户没有历史热词库,则用户当前热词集即为用户当前热词库;
37.然后依据用户当前热词库热词的出现概率自动重新调节热词权重,且用户自定义特殊热词的热词权重;
38.并通过语音转写模块导入含有用户当前热词库中的热词的语音,语音转写引擎更倾向于识别出用户当前热词库中的热词。
39.在第三方面,本发明提供了一种电子设备,所述电子设备包括:
40.存储器,用于存储指令;
41.处理器,用于调用所述存储器存储的指令执行权利要求1-6中任一项所述的一种语音转写中结合用户文本的快速热词提取方法。
42.在第四方面,本发明提供了一种存储介质,所述存储介质存储有计算机可执行指令,所述计算机可执行指令执行权利要求1-6中任一项所述的一种语音转写中结合用户文本的快速热词提取方法。
43.有益效果:本发明可根据用户提供的行业常用语音文本,快速提取热词,极大提高语音转写正确率;由于本发明获取的热词库是包含热词出现概率的信息,可依据所有热词的出现概率自动调节热词权重;由于本发明支持用户的当前热词集与历史热词库进行递归合并,用户可在使用过程中持续便捷地添加热词。
附图说明
44.图1是本发明实施例的语音转写中结合用户文本的快速热词提取方法的流程示意图。
具体实施方式
45.下面将结合本实施例中的附图,对本实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例,不能理解为对本发明的限制。基于本技术中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本技术保护的范围。
46.如图1所示,本发明实施例提供了一种语音转写中结合用户文本的快速热词提取方法,包括:
47.步骤s1:对用户提供的行业语音文本,进行分词预处理。分词预处理操作通过jieba分词工具完成,在分词操作之前根据用户需求添加自定义词典 user_dict.txt,确保用户文档中的特殊词在分词处理时不被拆分,并根据用户需求设置停用词。
48.其中jieba分词时采用精确模式,将句子最精确地切开,无冗余,生成分词后的用户文本文件user_text。
49.步骤s2:对用户文本的分词结果进行词频分析,获取用户当前文本词频。将分词后的用户文本文件user_text通过语言模型训练工具srilm生成词频统计文件
gram语言模型,即n,此处只对单个词语分析即设置为1元;
ꢀ‑
write指向输出文件,此处为unigram.counts。
64.用户当前热词集获取模块用以分析获取在用户当前文本词频中较高而在已有语音转写模型训练语料词频中较低的词,作为用户当前热词集。分析筛选出用户当前文本词频统计文件unigram.counts中满足预置条件的词,即在用户当前文本词频中词频高于词频阈值n1而在语音转写模型训练语料词频中词频低于词频阈值n2的词,作为用户当前热词集。
65.其中词频阈值n1可根据用户文本词数的量级自定义调节数值,词频阈值 n2可根据语音转写模型训练语料词频统计文件unigram.counts词数的量级自定义调节数值。
66.用户当前热词库获取模块用以将用户当前热词集与历史热词库进行递归合并,重新调节热词的权重得到用户当前热词库。
67.在用户当前热词集中去除与历史热词库中重复的热词;
68.将用户当前文本词频统计文件unigram.counts与历史文本词频统计文件 unigram.counts合并,计算用户当前热词集与历史热词库所有热词在合并的文本词频统计文件中的出现概率;
69.根据用户当前热词集与历史热词库所有热词在合并的文本词频统计文件中的出现概率,进行递归合并得到该用户当前热词库,如果用户没有历史热词库,则用户当前热词集即为用户当前热词库;
70.然后依据用户当前热词库热词的出现概率自动重新调节热词权重,且用户可自定义特殊热词的热词权重。
71.语音转写模块用以基于用户当前热词库,进行语音转文本。导入含有用户当前热词库中的热词的语音,语音转写引擎更倾向于识别出用户当前热词库中的热词,从而极大地提高一些不常见词或用户行业用词的转写正确率,提高用户满意度。
72.基于以上实施例,本领域技术人员可以理解,本发明还提供了一种语音转写中结合用户文本的快速热词提取电子设备,包括:存储器、处理器、输入/输出(input/output,i/o)接口。其中,存储器,用于存储指令。处理器,用于调用存储器存储的指令执行本发明实施例的一种语音转写中结合用户文本的快速热词提取方法。其中,处理器分别与存储器、i/o接口连接。存储器可用于存储程序和数据,包括本发明实施例中涉及的用于一种语音转写中结合用户文本的快速热词提取方法的程序,处理器通过运行存储在存储器的程序从而执行电子设备的各种功能应用以及数据处理。
73.上述实施例与的本发明的一种语音转写中结合用户文本的快速热词方法对应的实施例相类似,此处不再赘述。
74.本发明还提供的一种存储介质,该存储介质的存在形式可以是只读存储器,磁盘或光盘等。存储介质存储有计算机可执行指令,计算机可执行指令在由处理器执行时,执行上文所述的任何方法。
75.以上对本技术所提供的一种语音转写中结合用户文本的快速热词提取方法和装置,进行了详细介绍,但不应理解为对本发明专利范围的限制;同时,对于本领域的一般技术人员来说,其它未具体描述的部分,属于现有技术或公知常识。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1