一种基于实体属性的知识图谱事实补全方法
1.本发明涉及知识图谱补全领域,具体涉及一种基于实体属性的对知识图谱进行事实补全的方法。
背景技术:
2.知识图谱是结构化的语义知识库,能够记录世界中的实体及其之间的关系,为海量数据的存储提供了一种较好的组织和管理手段,比如dbpedia、yago、freebase、nell等著名的开源知识图谱。知识图谱是人工智能领域的重要研究内容之一,目前已经在搜索引擎、智能对话、用户推荐等众多领域得到了广泛的实际应用,渗透到了金融、医疗、教育等众多行业。
3.知识图谱中存储的一个事实通常可以表示为一个三元组的形式,即(头实体,关系,尾实体),其中头实体和尾实体分别对应知识图谱中的两个节点,关系对应连接这两个节点的边。但是由于知识图谱存储的事实通常是从互联网上海量、异构、动态的数据资源中自动挖掘出来的,而这些数据无法包含所有事实,因此构建的知识图谱通常是不完整的。知识图谱中缺失的事实给实际应用带来了很多挑战,比如由于事实的不完整加大了推理的难度,降低了应用的覆盖性和准确性,导致给用户的推荐不精准、智能搜索的答案不全面等问题。因此,兴起了知识图谱补全任务,即基于现有知识图谱中的事实补全缺失事实。根据知识图谱中的元素可以将知识图谱补全分为事实预测(factprediction)、关系预测(relationprediction)、链接预测(linkprediction)三个子任务。事实预测,即为给定头实体、关系和尾实体,预测(头实体,关系,尾实体)是否成立;关系预测,即为给定头实体和尾实体,预测他们之间存在的关系;链接预测,即为给定关系和一个头实体(尾实体),预测该实体通过该关系链接的尾实体(头实体)。使用这三种子任务中的任一种都可以对知识图谱中缺失的事实进行补全。
4.进行知识图谱事实预测的方法中,基于路径的方法一般抽取三元组(头实体,关系,尾实体)中头实体和尾实体之间的路径并提取路径特征(路径表示),然后通过建立路径特征与关系的联系,判断头实体和尾实体之间是否存在该关系,如果存在则将该三元组看作缺失的事实并补全。该方法具有较强的可解释性,并且对路径信息的学习可以同时考虑实体和关系,并能建模他们之间存在的显式及隐式的模式。
5.在基于路径的知识图谱补全方法中,如何利用实体间路径的信息进行预测是一个重要研究点。现有的方法着重研究如何使用路径上实体和关系的信息获取路径的特征,以此提高路径表示的准确性,从而提升根据路径信息判断实体间关系的平均精度均值(meanaverageprecision)。
6.由于知识库中实体数量较大,因此直接使用实体本身会导致模型学习的路径表示较为稀疏,这能够拉大不同路径的差异性,易于区分不同的路径(判别性好)。但是这会导致模型难以提取相似路径之间的共同特征,因此很难将从一些路径中学到的知识用于指导相似路径进行相似的推理(泛化性差),导致预测的平均精度均值低。为了在保持模型判别能
力的同时提高泛化能力,以提升模型预测的平均精度均值,现有的方法致力于使用实体的类型信息代替实体本身去学习路径的表示。这是因为不同的实体一般具有不同的类型信息,且实体的类型信息可以表示实体在路径中所表示的语义,因此实体的类型兼具判别性和泛化性,从而可以提升模型预测的平均精确度。
7.然而,如何提升模型预测的平均精度均值,补全更可信的知识还存在很多挑战。第一,并不是知识图谱中的所有实体都能获得对应的实体类型,而且获得的实体类型也许只能部分地刻画实体信息,导致实体的信息表达不够全面,提取的路径特征不够准确,影响预测的平均精度均值。第二,实体与不同关系相连时一般会表达不同的语义(对应不同的类型),实体的不同类型具有不同的抽象层次,因此如何准确选择路径中能够代表实体所表达语义并且具有合适的抽象层次的实体类型是一个难点。选择代表实体所表达语义的类型才会使得提取的路径特征准确,选择抽象层次合适的类型才会使得路径的特征兼具判别性和泛化性(选择语义更抽象的类型,则模型的泛化性更好;选择语义更具体的类型,则模型的判别性更好),从而才能提升模型根据提取的路径特征预测实体间关系的精确度。
技术实现要素:
8.本发明要解决的技术问题是:针对路径中实体语义信息不全面以及实体语义信息选择难度大,导致路径特征提取不够准确的问题,提出一种基于实体属性的知识图谱事实补全方法。该方法将知识图谱中与实体相连的关系作为该实体除了实体类型之外的另一种语义信息:实体属性,并同时捕获正反向路径序列上实体表达的语义所对应的属性信息和类型信息作为实体的语义信息,从而更全面更准确的提取路径的特征,提高知识图谱事实预测的平均精度均值,补全更可靠的事实。
9.为解决上述技术问题,本发明的技术方案是:构建由数据预处理模块、事实预测网络、事实补全模块构成的基于路径的知识图谱事实补全系统。根据用户需要进行补全的知识图谱(包含实体集合、关系集合、以及事实集合),数据预处理模块准备训练数据(训练样本的数据集合和训练样本的标签集合)、验证数据(验证样本的数据集合和验证样本的标签集合)、以及补全数据(补全样本的数据集合),输出给事实预测网络。事实预测网络由嵌入层、关系编码器、实体编码器、路径编码器、预测器五部分构成。事实预测网络使用数据预处理模块输出的训练数据采用adam方法进行训练,得到网络权重参数,事实预测网络使用数据预处理模块输出的验证数据进行验证,保存最优的网络权重参数。训练好的事实预测网络对数据预处理模块输出的补全数据进行预测,得到补全样本的预测概率集合,事实补全模块根据预测概率集合判断是否需要将补全样本补全到知识图谱中。
10.本发明主要包括以下步骤:
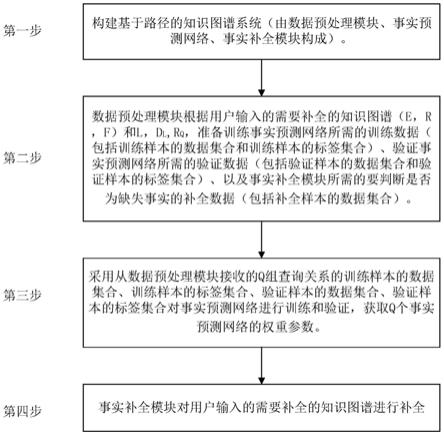
11.第一步:构建基于路径的知识图谱事实补全系统。该系统由数据预处理模块、事实预测网络、事实补全模块构成。
12.数据预处理模块与事实预测网络相连,接收用户输入的知识图谱,对用户输入的知识图谱进行预处理,得到训练事实预测网络所需的训练数据(包括训练样本的数据集合和训练样本的标签集合)、验证事实预测网络所需的验证数据(包括验证样本的数据集合和验证样本的标签集合)、以及事实补全模块所需的要判断是否为缺失事实的补全数据(包括补全样本的数据集合),输出给事实预测网络,并将补全样本的数据集合输出给事实补全模
块。数据预处理模块由路径抽取函数f
extractpath
和路径预处理函数f
preprocesspaths
构成,其中f
extractpath
从知识图谱中抽取每个样本的实体之间的路径信息,f
preprocesspaths
将每个样本的实体间路径信息处理为事实预测网络需要的数据结构。将知识图谱中的实体集合、关系集合、事实集合分别记为e={e
i
},r={r
j
}和将实体的属性集合记为a={a
v
},将实体的类型集合记为l={l
o
},其中1≤i≤|e|,1≤i1≤|e|,1≤i2≤|e|,1≤j≤|r|,1≤v≤|a|,1≤o≤|l|,|e|、|r|、|a|、|l|分别表示实体的总数、关系的总数、属性的总数和类型的总数。将r
j
′
记为r
j
的反关系,表示若则根据e、r、f、a、l,数据预处理模块获取训练样本集合s
*
、训练样本的标签集合y
*
、验证样本集合s
#
、验证样本的标签集合y
#
、以及补全样本集合u。对于样本集合(包括训练样本集合s
*
、验证样本集合s
#
、补全样本集合u)中的每个样本(包括训练样本、验证样本、补全样本),数据预处理模块先使用f
extractpath
从知识图谱中抽取样本的实体对之间的正向路径集合,然后使用f
preprocesspaths
处理该正向路径集合输出样本的数据集合,构成训练样本的数据集合、验证样本的数据集合、补全样本的数据集合。
13.事实预测网络由嵌入层、关系编码器、实体编码器、路径编码器、预测器五个部分组成。其中,嵌入层包含3个嵌入矩阵,分别为关系的嵌入矩阵w
r
、实体属性的嵌入矩阵w
a
、实体类型的嵌入矩阵w
l
;关系编码器用于提取每条路径的关系序列特征,由一个lstm网络构成,记为lstm
r
;实体编码器用于提取每条路径的实体序列特征(包括每条路径上实体的属性信息序列的特征和类型信息序列的特征),由实体画像注意力网络和实体序列编码网络两个子网络构成,其中实体画像注意力网络由结构相同的实体属性注意力网络和实体类型注意力网络构成,实体属性注意力网络由4个全连接层构成,实体类型注意力网络由4个全连接层构成,而实体序列编码网络由两个lstm网络(分别记为lstm
a
和lstm
l
)及4个全连接层构成;路径编码器由结构相同的正向路径注意力网络和反向路径注意力网络构成,其中正向路径注意力网络由2个全连接层f
p
和构成,反向路径注意力网络由2个全连接层f
′
p
和构成,分别用于聚合每个样本的所有正向路径的特征和所有反向路径的特征;预测器由4个全连接层f1,f2,f3和f4构成,用于预测每个样本属于事实的概率。事实预测网络从数据预处理模块得到样本数据集合(包括训练样本的数据集合、验证样本的数据集合、补全样本的数据集合),提取样本数据集合中每个样本的路径特征,然后计算出每个样本属于事实的概率,组成预测概率集合(包括训练样本的预测概率集合、验证样本的预测概率集合、补全样本的预测概率集合)。其中,(1)嵌入层接收数据预处理模块的数据,将每个关系、实体属性、实体类型、实体属性分别使用w
r
、w
a
、w
l
转化为向量表示,然后将每个样本的每条路径的关系序列转化为向量表示(即每个样本的正向路径集合中每条正向路径的关系序列的嵌入和反向路径集合中每条反向路径的关系序列的嵌入)输出给关系编码器,将每个样本的每条路径上实体的属性信息序列和实体的类型信息序列转化为向量表示(即每个样本的每条正向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入,和每个样本的每条反向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入)输出给实体编码器,将每个样本的查
询关系和反向查询关系转化为向量表示(即每个样本的查询关系的嵌入、每个样本的反向查询关系的嵌入)也输出给实体编码器;(2)关系编码器接收嵌入层输出的每个样本的正向路径集合中每条正向路径的关系序列的嵌入和反向路径集合中每条反向路径的关系序列的嵌入,对这些嵌入进行编码,得到每个样本的每条正向路径的关系表示和每条反向路径的关系表示,将每个样本的每条正向路径的关系表示和每条反向路径的关系表示输出给实体编码器和路径编码器;(3)实体编码器接收来自关系编码器的每个样本的每条正向路径的关系表示和每条反向路径的关系表示,还接收来自嵌入层的每个样本的查询关系的嵌入、每个样本的反向查询关系的嵌入、每个样本的每条正向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入、每个样本的每条反向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入,对这些嵌入进行编码,得到每个样本的每条正向路径的实体表示和每条反向路径的实体表示,将每个样本的每条正向路径的实体表示和每条反向路径的实体表示输出给路径编码器;(4)路径编码器接收来自关系编码器的每个样本的每条正向路径的关系表示和每条反向路径的关系表示,以及来自实体编码器的每个样本的每条正向路径的实体表示和每条反向路径的实体表示,对这些表示进行编码,得到每个样本的正向路径表示和反向路径表示,将每个样本的正向路径表示和反向路径表示输出给预测器;(5)预测器接收来自路径编码器的每个样本的正向路径表示和反向路径表示,对这些表示进行编码,得到每个样本的预测结果(即每个样本属于事实的概率),将每个样本的预测结果组成预测概率集合。事实预测网络根据数据预处理模块输出的训练样本的标签集合和事实预测网络预测的训练样本的预测概率集合,进行训练并更新网络参数;事实预测网络根据数据预处理模块输出的验证样本的标签集合和事实预测网络预测的验证样本的预测概率集合,进行验证并保存最优的网络参数。如果输入事实预测网络的样本数据集合是补全样本的数据集合,则事实预测网络将计算得到的补全样本的预测概率集合输出给事实补全模块。
14.事实补全模块与数据预处理模块和事实预测网络相连接。事实补全模块接收数据预处理模块输出的补全样本的数据集合和训练好的事实预测网络输出的补全样本的预测概率集合z,根据每个补全样本的预测概率判断补全样本的数据集合中补全样本集合u里的每个补全样本是否是需要补全的事实,如果补全样本是需要补全的事实,则将补全样本u
w
(u
w
∈u)添加到知识图谱的事实集合中,即令f
new
=f∪u
w
,f
new
为补全后的知识图谱的事实集合。
15.第二步:数据预处理模块根据用户输入的需要补全的知识图谱(包括e、r、f)和l、d
l
、r
q
,准备训练事实预测网络所需的训练数据(包括训练样本的数据集合和训练样本的标签集合)、验证事实预测网络所需的验证数据(包括验证样本的数据集合和验证样本的标签集合)、以及事实补全模块所需的要判断是否为缺失事实的补全数据(包括补全样本的数据集合)。
16.2.1数据预处理模块接收用户输入的需要补全的知识图谱(包括实体集合e、关系集合r、事实集合f)、实体的类型集合l和每个实体对应的类型信息的字典d
l
(字典的key为实体,value为实体对应的类型集合),以及需要补全的查询关系集合r
q
={r
q
|r
q
∈r}(1≤q≤q,q为r
q
中元素的个数)。
17.2.2数据预处理模块使用路径抽取函数f
extractpath
和路径预处理函数f
preprocesspaths
准备训练和验证事实预测网络需要的训练样本的数据集合和训练样本的标签集合、验证样本的数据集合和验证样本的标签集合,具体地:
18.2.2.1令存储所有训练样本的集合存储所有训练样本的标签集合存储所有训练样本的所有正向路径的关系序列的集合存储所有训练样本的所有反向路径的关系序列的集合存储所有训练样本的所有正向路径的实体属性信息序列集合存储所有训练样本的所有正向路径的实体类型信息序列集合存储所有训练样本的所有反向路径的实体属性信息序列集合存储所有训练样本的所有反向路径的实体类型信息序列集合
19.2.2.2令存储所有验证样本的集合存储所有验证样本的标签集合存储所有验证样本的所有正向路径的关系序列的集合存储所有验证样本的所有反向路径的关系序列的集合存储所有验证样本的所有正向路径的实体属性信息序列集合存储所有验证样本的所有正向路径的实体类型信息序列集合存储所有验证样本的所有反向路径的实体属性信息序列集合存储所有验证样本的所有反向路径的实体类型信息序列集合
20.2.2.3令q=1;
21.2.2.4如果q≤q,转2.2.5获取查询关系r
q
下的样本数据,否则说明全部样本数据均已经处理,转2.2.18。
22.2.2.5设置负样本数目与正样本数目的比值为k
n|p
,k
n|p
为正整数,且1≤k
n|p
≤10。设置样本数量阈值为k
q
,k
q
为正整数,且其中表示以r
q
为关系的事实,即为关系的事实,即表示集合的元素数目。令查询关系r
q
的样本集合为令查询关系r
q
的样本标签集合为令查询关系r
q
下所有样本的所有正向路径的关系序列的集合查询关系r
q
下所有样本的所有反向路径的关系序列的集合查询关系r
q
下所有样本的所有正向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有正向路径的实体类型信息序列集合查询关系r
q
下所有样本的所有反向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有反向路径的实体类型信息序列集合
23.2.2.6令k=1;
24.2.2.7如果k≤k
q
,转2.2.8获取查询关系r
q
下单个样本的数据,否则说明查询关系r
q
下的所有样本的数据已经获取,转2.2.14。
25.2.2.8随机从实体集合e中选择两个实体和即1≤k1≤|e|,1≤k2≤|e|。构造样本s
k
,且若则s
k
为正样
本,令s
k
的标签y
k
=1,若则s
k
为负样本,令s
k
的标签y
k
=0。构造样本s
k
时需要控制最终s
q
内正负样本的比例为1:k
n|p
(即每构造一个正样本,就构造k
n|p个
负样本)。
26.2.2.9令s
k
的所有正向路径的关系序列的集合s
k
的所有反向路径的关系序列的集合s
k
的所有正向路径的实体属性信息序列集合s
k
的所有正向路径的实体类型信息序列集合s
k
的所有反向路径的实体属性信息序列集合s
k
的所有反向路径的实体类型信息序列集合
27.2.2.10f
extractpath
采用随机游走方法(见文献“lao,n.;mitchell,t.;and cohen,w.w.2011.random walk inference and learning in a large scale knowledge base.in emnlp.acl.”,lao等人:大规模知识库中的随机游走推理和学习)抽取样本s
k
的实体到实体的n条正向路径,放到s
k
的正向路径集合中,其中1≤n≤n,第n条路径p
n
由实体和关系交替构成,m为路径p
n
的长度,实体为路径p
n
上第t步的实体,r
t
∈r(1≤t≤m)为路径p
n
上第t步的关系。即采用f
extractpath
函数处理得到到的n条正向路径的集合
28.2.2.11f
preprocesspaths
将样本s
k
的正向路径集合处理为事实预测网络需要的数据结构,得到样本s
k
的查询关系r
q
、反向查询关系r
′
q
,样本s
k
的所有正向路径的关系序列的集合所有反向路径的关系序列的集合所有正向路径的实体属性信息序列集合和实体的类型信息序列集合所有反向路径的实体的属性信息序列集合和实体的类型信息序列集合具体为:
29.2.2.11.1令n=1;
30.2.2.11.2如果n≤n,转2.2.11.3处理样本s
k
的第n条路径的数据,否则说明样本s
k
的全部路径均已经处理,转2.2.11.14。
31.2.2.11.3获取中第n条路径p
n
的反向路径p
′
n
,
32.2.2.11.4将p
n
分为正向关系序列和正向实体序列和正向实体序列
33.2.2.11.5将p
′
n
分为反向关系序列和反向实体序列和反向实体序列
34.2.2.11.6获取上所有实体的属性信息,方法是:
35.2.2.11.6.1令t=1;
36.2.2.11.6.2如果t≤m+1,转2.2.11.6.3获取上的第t步实体的属性信息,否则说明上所有实体的属性信息均已经获取,转2.2.11.7。
37.2.2.11.6.3获取上的第t步实体e
t
的属性集合a
t
,1≤v
t
≤|a
t
|,|a
t
|为a
t
中属性的个数。本发明提出的任意一个实体的属性信息是从知识图谱中与该实体相连的关系获得的,分为两种情况进行处理:
38.2.2.11.6.3.1如果e
t
既不是也不是那么e
t
的属性集合就是以e
t
作为头实体的所有事实构成的邻居事实集合中的关系的集合,即中的关系的集合,即转2.2.11.6.4。
39.2.2.11.6.3.2如果e
t
是或者那么e
t
的属性集合就是以e
t
作为头实体的所有事实去掉包含和作为实体的所有事实构成的邻居事实集合中的关系的集合,即中的关系的集合,即其中表示以和分别作为头实体和尾实体的事实,即分别作为头实体和尾实体的事实,即转2.2.11.6.4。
40.2.2.11.6.4对a
t
内的属性进行排序。方法是将a
t
内的全部属性根据其在中出现的频次从高到低进行排序,频次高的属性排序在前。具体地,将e
t
的第v
t
个属性在出现的次数记为若属性和的次数满足则属性排序在之前,最后将e
t
的属性集合记为意味着意味着
41.2.2.11.6.5令t=t+1,转2.2.11.6.2;
42.2.2.11.7将上获得的所有实体的属性信息记为
43.2.2.11.8将上所有实体的属性信息记为为的逆序,即的逆序,即
44.2.2.11.9获取上所有实体的类型信息,方法是:
45.2.2.11.9.1令t=1;
46.2.2.11.9.2如果t≤m+1,转2.2.11.9.3获取上的第t步实体的类型信息,否则说明上所有实体的类型信息均已经获取,转2.2.11.10。
47.2.2.11.9.3令e
t
的类型集合l
t
为字典d
l
中键e
t
对应的值,即令l
t
=d
l
[e
t
],l
t
可以表示为1≤o
t
≤|l
t
|,为l
t
中的第o
t
个类型,|l
t
|为l
t
中类型的个数。
[0048]
2.2.11.9.4令t=t+1,转2.2.11.9.2;
[0049]
2.2.11.10将上获得的所有实体的类型信息记为
[0050]
2.2.11.11将上所有实体的类型信息记为为的逆序,即的逆序,即
[0051]
2.2.11.12将2.2.11.4中获得的正向路径p
n
的关系序列加入集合即令将2.2.11.5中获得的反向路径p
′
n
的关系序列加入集合即令将2.2.11.7获得的正向路径p
n
的实体属性序列加入集合即令将2.2.11.10获得的正向路径p
n
的实体类型序列加入集合即令将2.2.11.8获得的反向路径p
′
n
的实体属性序列加入集合即令将2.2.11.11获得的反向路径p
′
n
的实体类型序列加入集合即令
[0052]
2.2.11.13令n=n+1,转2.2.11.2。
[0053]
2.2.11.14将下述信息作为f
preprocesspayhs
处理样本s
k
的正向路径集合的结果:样本s
k
的查询关系r
q
、反向查询关系r
′
q
,样本s
k
的所有正向路径的关系序列的集合的所有正向路径的关系序列的集合所有反向路径的关系序列的集合所有正向路径的实体属性信息序列集合和实体的类型信息序列集合和实体的类型信息序列集合所有反向路径的实体的属性信息序列集合和实体的类型信息序列集合转2.2.12。
[0054]
2.2.12将样本s
k
和s
k
的标签分别加入样本集合s
q
和样本的标签集合y
q
中,即令s
q
=s
q
∪{s
k
},令y
q
=y
q
∪{y
k
};将2.2.11.14中获得的f
preprocesspaths
处理样本s
k
的正向路径集合的结果作为元素添加到查询关系r
q
下的样本的数据集合中,即令下的样本的数据集合中,即令
[0055]
2.2.13令k=k+1,转2.2.7。
[0056]
2.2.14此时查询关系r
q
下所有样本为s
q
={s1,
…
,s
k
,
…
,s
k
},查询关系r
q
下所有样本的标签集合为y
q
={y1,
…
,y
k
,
…
,y
k
},查询关系r
q
下所有样本的所有正向路径的关系序列的集合查询关系r
q
下所有样本的所有反向路径的关系序列的集合下所有样本的所有反向路径的关系序列的集合查询关系r
q
下所有样本的所有正向路径的实体属性信息序列集合下所有样本的所有正向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有正向路径的实体类型信息序列集合下所有样本的所有正向路径的实体类型信息序列集合查询关系r
q
下所有样本的所有反向路径的实体属性信息序列集合下所有样本的所有反向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有反向路径的实体类型信息序列集合下所有样本的所有反向路径的实体类型信息序列集合将s
q
、y
q
、按照a:c的比例分为查询关系r
q
下的训练数据s
q*
、y
q*
、和验证数据s
q#
、y
q#
、
a和c为正数,一般a>c,且a+c=10,优选a:c=7:3。
[0057]
2.2.15将查询关系r
q
下的所有训练数据作为元素加入总的训练数据中,即令s
*
=s
*
∪{s
q*
},y
*
=y
*
∪{y
q*
},},
[0058]
2.2.16将查询关系r
q
下的所有验证数据作为元素加入总的验证数据中,即令s
#
=s
#
∪{s
q#
},y
#
=y
#
∪{y
q#
},},
[0059]
2.2.17令q=q+1,转2.2.4。
[0060]
2.2.18此时所有训练样本的标签集合为y
*
={y1,
…
,y
q
,
…
,y
q
},所有的训练样本的集合为s
*
={s
1*
,
…
,s
q*
,
…
,s
q*
},所有训练样本的所有正向路径的关系序列的集合},所有训练样本的所有正向路径的关系序列的集合所有训练样本的所有反向路径的关系序列的集合所有训练样本的所有反向路径的关系序列的集合所有训练样本的所有正向路径的实体属性信息序列集合所有训练样本的所有正向路径的实体属性信息序列集合所有训练样本的所有正向路径的实体类型信息序列集合所有训练样本的所有正向路径的实体类型信息序列集合所有训练样本的所有反向路径的实体属性信息序列集合所有训练样本的所有反向路径的实体属性信息序列集合所有训练样本的所有反向路径的实体类型信息序列集合所有训练样本的所有反向路径的实体类型信息序列集合s
*
、s
*
′
r
、s
*
′
a
、s
*
′
l
构成所有训练样本的数据集合;所有验证样本的标签集合为y
#
={y
1#
,
…
,y
q#
,
…
,y
q#
},所有的验证样本的集合为s
#
={s
1#
,
…
,s
q#
,
…
,s
q#
},所有验证样本的所有正向路径的关系序列的集合},所有验证样本的所有正向路径的关系序列的集合所有验证样本的所有反向路径的关系序列的集合有验证样本的所有反向路径的关系序列的集合所有验证样本的所有正向路径的实体属性信息序列集合所有正向路径的实体属性信息序列集合所有验证样本的所有正向路径的实体类型信息序列集合向路径的实体类型信息序列集合所有验证样本的所有反向路径的实体属性信息序列集合的实体属性信息序列集合所有验证样本的所有反向路径的实体类型信息序列集合类型信息序列集合s
#
、s
′
#r
、s
′
#a
、s
′
#l
构成所有验证样本的数据集合,转2.3。
[0061]
2.3数据预处理模块使用路径抽取函数f
extractpath
和路径预处理函数f
preprocesspaths
准备事实补全模块所需的要判断是否为缺失事实的补全样本的数据集合,具体地:
[0062]
2.3.1令存储所有补全样本的集合存储所有补全样本的所有正向路径的关系序列的集合存储所有补全样本的所有反向路径的关系序列的集合存储所有补全样本的所有正向路径的实体属性信息序列集合存储所有补全样本的所有
正向路径的实体类型信息序列集合存储所有补全样本的所有反向路径的实体属性信息序列集合存储所有补全样本的所有反向路径的实体类型信息序列集合
[0063]
2.3.2令q=1;
[0064]
2.3.3如果q≤q,转2.3.4获取查询关系r
q
下的补全样本数据,否则说明全部补全样本数据均已经处理,转2.3.14。
[0065]
2.3.4准备需要判断是否为缺失事实的查询关系r
q
下的所有补全样本的集合u
q
,u
q
为没有被f包含的关系为r
q
的三元组的集合,即的三元组的集合,即简记为1≤w≤|u
q
|,|u
q
|为u
q
中元素的个数,即查询关系r
q
下的补全样本的总数)。
[0066]
2.3.5令查询关系r
q
下所有补全样本的所有正向路径的关系序列的集合令查询关系r
q
下所有补全样本的所有反向路径的关系序列的集合令查询关系r
q
下所有补全样本的所有正向路径的实体属性信息序列集合令查询关系r
q
下所有补全样本的所有正向路径的实体类型信息序列集合令查询关系r
q
下所有补全样本的所有反向路径的实体属性信息序列集合令查询关系r
q
下所有补全样本的所有反向路径的实体类型信息序列集合
[0067]
2.3.6令w=1;
[0068]
2.3.7若w≤|u
q
|,转2.3.8获取查询关系r
q
下补全样本u
w
的数据,否则说明u
q
中每个补全样本的数据均已经获取,转2.3.12。
[0069]
2.3.8采用步骤2.2.10所述的f
extractpath
函数处理得到样本u
w
的实体到实体的n
u
条正向路径信息,放到u
w
的正向路径集合中,其中中的第n
u
条路径1≤n
u
≤n
u
。
[0070]
2.3.9采用步骤2.2.11所述的路径预处理函数f
preprocesspaths
处理u
w
的正向路径集合得到样本u
w
的查询关系r
q
、反向查询关系r
′
q
,样本u
w
的所有正向路径的关系序列的集合所有反向路径的关系序列的集合所有正向路径的实体属性信息序列集合和实体的类型信息序列集合所有反向路径的实体的属性信息序列集合和实体的类型信息序列集合
[0071]
2.3.10将作为元素添加到查询关系r
q
下补全样本的数据集合中,即令合中,即令
[0072]
2.3.11令w=w+1,转2.3.7。
[0073]
2.3.12此时u
q
中每个补全样本的数据均已经获取,查询关系r
q
下所有补全样本
的路径信息为:查询关系r
q
下所有补全样本的所有正向路径的关系序列的集合查询关系r
q
下所有补全样本的所有反向路径的关系序列的集合查询关系r
q
下所有补全样本的所有正向路径的实体属性信息序列集合查询关系r
q
下所有补全样本的所有正向路径的实体类型信息序列集合查询关系r
q
下所有补全样本的所有反向路径的实体属性信息序列集合查询关系r
q
下所有补全样本的所有反向路径的实体类型信息序列集合将该查询关系r
q
下的所有补全样本的数据作为元素加入总的补全样本的数据中,即令u=u∪{u
q
},},
[0074]
2.3.13令q=q+1,转2.3.3。
[0075]
2.3.14此时所有补全样本的集合为u={u1,
…
,u
q
,
…
,u
q
},所有补全样本的所有正向路径的关系序列的集合所有补全样本的所有反向路径的关系序列的集合所有补全样本的所有正向路径的实体属性信息序列集合所有补全样本的所有正向路径的实体类型信息序列集合所有补全样本的所有正向路径的实体类型信息序列集合所有补全样本的所有反向路径的实体属性信息序列集合所有补全样本的所有反向路径的实体属性信息序列集合所有补全样本的所有反向路径的实体类型信息序列集合所有补全样本的所有反向路径的实体类型信息序列集合且u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
构成所有补全样本的数据集合。转2.4。
[0076]
2.4将步骤2.2得到的s
*
、输出给事实预测网络作为q组查询关系的训练样本的数据集合,将步骤2.2得到的y
*
输出给事实预测网络作为q组查询关系的训练样本的标签集合,将步骤2.2得到的s
#
、输出给事实预测网络作为q组查询关系的验证样本的数据集合,将步骤2.2得到的y
#
输出给事实预测网络作为q组查询关系的验证样本的标签集合,将步骤2.3得到的u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
输出给事实预测网络作为q组查询关系的补全样本的数据集合;并将补全样本的数据集合输出给事实补全模块。
[0077]
第三步:采用从数据预处理模块接收的q组查询关系的训练样本的数据集合、训练样本的标签集合、验证样本的数据集合、验证样本的标签集合对事实预测网络进行训练和验证,获取q个事实预测网络的权重参数(注意:不同的查询关系为不同的子任务,训练得到不同的事实预测网络权重参数)。
[0078]
具体方法如下:
[0079]
3.1令q=1;
[0080]
3.2如果q≤q,则转步骤3.3,否则说明所有查询关系的事实预测网络均已训练结
束,得到了q个训练好的事实预测网络,即转步骤3.8。
[0081]
3.3初始化查询关系r
q
对应的事实预测网络的权重参数,方法为:
[0082]
3.3.1初始化嵌入矩阵的权重。首先将关系、实体的属性、实体的类型分别对应的3个嵌入矩阵w
r
、w
a
、w
l
随机初始化为遵循标准正态分布的50维的向量,即各个嵌入矩阵的维度分别为:关系总数目|r|
×
50、实体属性的总数目|a|
×
50、实体类型的总数目|l|
×
50。虽然本发明所述的实体属性实际上属于知识图谱中的关系(即集合a=r),但是其作为对实体语义信息的刻画,应该具有与路径上的关系不同的含义,因此实体属性的嵌入和关系的嵌入使用不同的嵌入矩阵。
[0083]
3.3.2设置lstm网络的参数。lstm
r
、lstm
a
和lstm
l
网络的隐藏单元的维度均为150维,且lstm
r
的隐藏单元和记忆单元均使用全零初始化。
[0084]
3.3.3初始化全连接层的权重矩阵和偏置向量的权重。每个全连接层均包含一个权重矩阵和一个偏置向量,权重矩阵的维度为全连接层的输出维度
×
全连接层的输入维度,偏置向量的维度为全连接层的输出维度。下面介绍全连接层的输入维度和输出维度,以确定全连接层对应的权重矩阵和偏置向量的维度。实体属性注意力网络中全连接层的输入维度分别为200,150,50,50,输出维度分别为150,50,50,1;实体类型注意力网络中全连接层的输入维度分别为200,150,50,50,输出维度分别为150,50,50,1;实体序列编码网络中全连接层50,输出维度分别为150,50,50,1;实体序列编码网络中全连接层的输入维度均为150,输出维度均为150维。路径编码器中全连接层f
p
,f
′
p
,和的输入维度分别为300,300,100,100,输出维度分别为100,100,1,1。预测器中全连接层f1,f2,f3,f4的输入维度分别为300,300,600,300,输出维度分别为300,300,300,1。
[0085]
3.4设置事实预测网络的训练参数:使用adam优化算法(见文献“diederik p kingma and jimmy ba.2014.adam:a method for stochastic optimization.arxiv preprint arxiv:1412.6980(2014),diederik等人:adam:一种随机优化方法”)进行网络的优化,并使用默认参数(学习率learningrate=0.001,一阶矩估计的指数衰减率β1=0.9,二阶矩估计的指数衰减率β2=0.999,防止除以零的最小值参数∈=1e
‑8),批数据尺寸batchsize=16。
[0086]
3.5从s
*
、y
*
、中取出关于查询关系r
q
的训练数据s
q*
、y
q*
、从s
#
、y
#
、中取出关于查询关系r
q
的验证数据s
q#
、y
q#
、
[0087]
3.6迭代计算事实预测网络输出的预测概率与真实标签之间的差距,最小化损失并更新网络的参数,直到满足迭代次数要求,得到权重参数。具体方法如下:
[0088]
3.6.1令训练迭代参数epoch=1,令事实预测网络对查询关系r
q
的验证数据进行预测的平均精确度(averageprecision)的值ap
q#
=0;初始化迭代阈值epochnum,epochnum是[1,30]内的整数;
[0089]
3.6.2如果epoch≤迭代阈值epochnum,转3.6.2.1对查询关系r
q
的事实预测网络
进行新一次的迭代训练,否则说明查询关系r
q
的事实预测网络已经满足迭代次数要求,训练结束,转3.7。
[0090]
3.6.2.1令批处理次数b=1,令已训练样本数目processednum=0;
[0091]
3.6.2.2如果转3.6.2.2.1使用s
q*
中第b个batch的训练数据对进行训练,其中|s
q*
|为训练样本集合s
q*
的样本数目,否则说明s
q*
中的所有训练样本已经参与过计算,该次训练迭代结束,转3.6.2.3计算在验证数据s
q#
上的预测结果;
[0092]
3.6.2.2.1事实预测网络的嵌入层从s
q*
中读取c个样本作为第b个batch的训练数据,即一个批次的训练数据,记为样本训练批次集合s
q*,b
={s1,
…
,s
c
,
…
,s
c
},1≤c≤c,其中c=min(batchsize,|s
q*
|
‑
processednum),表示取batchsize和|s
q*
|
‑
processednum中的最小值。从y
q*
、中取出与s
q*,b
的这c个样本对应的数据,分别记为标签训练批次集合y
q*,b
={y1,
…
,y
c
,
…
,y
c
},正向路径关系序列训练批次集合},正向路径关系序列训练批次集合反向路径关系序列训练批次集合正向路径实体属性信息序列训练批次集合和正向路径实体类型信息序列训练批次集合反向路径实体属性信息序列训练批次集合反向路径实体属性信息序列训练批次集合和反向路径实体类型信息序列训练批次集合
[0093]
3.6.2.2.2采用事实预测网络预测方法f
predict
,对第b个batch的数据,对第b个batch的数据和查询关系r
q
、查询关系的反关系r
′
q
进行计算,得到第b个batch的数据的预测概率集合其中是该批次数据中样本s
c
的预测概率,具体为:
[0094]
3.6.2.2.2.1事实预测网络的嵌入层读取r
q
、r
′
q
,以及使用关系的嵌入矩阵w
r
、实体属性的嵌入矩阵w
a
、实体类型的嵌入矩阵w
l
分别将数据中的关系、实体属性、实体类型映射为各自的向量表示,得到r
q
、r
′
q
、、分别对应的向量形式(即批次数据的查询关系的嵌入反向查询关系的嵌入正向路径的关系序列的嵌入反向路径的关系序列的嵌入正向路径的实体属性序列的嵌入正向路径的实体类型序列的嵌入反向路径的实体属性序列的嵌入反向路径的实体类型序列的嵌入),将发送给关系编码器和实体编码器。
[0095]
3.6.2.2.2.2关系编码器提取路径的关系特征。关系编码器从嵌入层接收和计算该批次数据的所有正向路径的关系表示和所有反向路径的关系表示并传给实体编码器和路径编码器。正向路径的关系表示的获取与反向路径的关系表示的获取方式相
同,方法是:
[0096]
3.6.2.2.2.2.1将(维度为cn
×
m
×
50,即cn条正向路径的关系序列的嵌入,其中每条正向路径的关系序列的嵌入维度为m
×
50)作为关系编码器中lstm
r
的一次输入,并使用lstm
r
输出的最后的隐状态,记为(维度为cn
×
150),作为这cn条正向路径的关系表示(每条正向路径的关系表示为150维)。
[0097]
3.6.2.2.2.2.2将(维度为cn
×
m
×
50,即cn条反向路径的关系序列的嵌入,其中每条反向路径的关系序列的嵌入维度为m
×
50)作为关系编码器中lstm
r
的一次输入,并使用lstm
r
输出的最后的隐状态,记为(维度为cn
×
150),作为这cn条反向路径的关系表示(每条反向路径的关系表示为150维)。
[0098]
3.6.2.2.2.2.3将该批次数据的所有正向路径的关系表示和所有反向路径的关系表示输出给实体编码器和路径编码器。
[0099]
3.6.2.2.2.3实体编码器提取每条路径的实体特征。实体编码器从嵌入层接收3.6.2.2.2.3实体编码器提取每条路径的实体特征。实体编码器从嵌入层接收从关系编码器接收和计算所有正向路径的实体表示和所有反向路径的实体表示,并传给路径编码器。正向路径的实体表示的获取与反向路径的实体表示的获取方式相同,具体的过程为:
[0100]
3.6.2.2.2.3.1实体序列编码网络对正向路径的实体属性序列嵌入和正向路径的实体类型序列嵌入进行编码,由于属性和类型属于两种信息,因此使用两个长短时记忆循环网络(即lstm
a
和lstm
l
)分别进行编码,来捕获正向路径上实体序列的属性表示和类型表示,具体为:
[0101]
3.6.2.2.2.3.1.1使用正向路径的关系表示对lstm
a
和lstm
l
进行初始化:
[0102]
3.6.2.2.2.3.1.1.1将输入到全连接层得到lstm
a
的第一隐藏状态将输入到全连接层得到lstm
a
的第一细胞状态
[0103]
3.6.2.2.2.3.1.1.2将输入到全连接层得到lstm
l
的第一隐藏状态将输入到全连接层得到lstm
l
的第一细胞状态
[0104]
3.6.2.2.2.3.1.2令t=1。
[0105]
3.6.2.2.2.3.1.3如果1≤t≤m+1,则将t、和传给实体画像注意力网络,转第3.6.2.2.2.3.1.4步聚合数据中所有正向路径上第t步实体的属性信息和类型信息;否则说明数据中所有正向路径上实体的属性信息和类型信息已经聚合,转3.6.2.2.2.3.1.8。
[0106]
3.6.2.2.2.3.1.4实体画像注意力网络(分为实体属性注意力网络和实体类型注意力网络)对批次数据的所有正向路径中的第t步实体的全部属性或全部类型的嵌入进行聚合,作为对实体的语义信息的刻画。具体的计算过程为:
[0107]
3.6.2.2.2.3.1.4.1从(维度为(c*n)
×
(m+1)
×
|a
t
|
×
50)中取出批数据中所有正向路径的第t步实体的属性嵌入,记为(维度为(c*n)
×
|a
t
|
×
50);
[0108]
3.6.2.2.2.3.1.4.2将和级联,将级联后的和经过全连接层得到指导第t步属性注意力的引导变量
[0109]
3.6.2.2.2.3.1.4.3实体属性注意力网络将批数据中所有正向路径的第t步实体的属性嵌入进行聚合,方法为:
[0110]
3.6.2.2.2.3.1.4.3.1令v
t
=1;
[0111]
3.6.2.2.2.3.1.4.3.2若v
t
≤|a
t
|,转3.6.2.2.2.3.1.4.3.3获取数据中所有正向路径上第t步实体的第v
t
个属性的权重,否则说明数据中所有正向路径上第t步实体的每个属性的权重均已经获取,转3.6.2.2.2.3.1.4.3.6;
[0112]
3.6.2.2.2.3.1.4.3.3将中批数据所有正向路径的第t个实体的第v
t
个属性的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的属性嵌入将输入到全连接层得到属性引导第二变量
[0113]
3.6.2.2.2.3.1.4.3.4将和相加,将相加后的和经过relu函数(见文献“nair v,hinton g e.rectified linear units improve restricted boltzmann machines[c].international conference on machine learning,2010:807
‑
814.”,nair和hinton:纠正线性单位改进受限的博尔茨曼机器)激活后输入到全连接层得到批数据所有正向路径中第t步实体的第v
t
个属性的权重
[0114]
3.6.2.2.2.3.1.4.3.5令v
t
=v
t
+1,转3.6.2.2.2.3.1.4.3.2;
[0115]
3.6.2.2.2.3.1.4.3.6将权重进行归一化,得到归一化后批数据所有正向路径第t步实体的所有属性的权重集合
[0116]
3.6.2.2.2.3.1.4.3.7使用聚合批数据所有正向路径第t步实体的所有属性的表示,得到聚合后的批数据所有正向路径第t步实体的属性表示径第t步实体的所有属性的表示,得到聚合后的批数据所有正向路径第t步实体的属性表示即将(维度为(c*n)
×
|a
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.1.4.4;
[0117]
3.6.2.2.2.3.1.4.4从(维度为(c*n)
×
(m+1)
×
|l
t
|
×
50)中取出批数据中所有正向路径的第t步实体的类型嵌入,记为(维度为(c*n)
×
|l
t
|
×
50);
[0118]
3.6.2.2.2.3.1.4.5将和级联,将级联后的和经过全连接层得到指导第t步类型注意力的引导变量
[0119]
3.6.2.2.2.3.1.4.6实体类型注意力网络将批数据中所有正向路径的第t步实体的类型嵌入进行聚合,方法为:
[0120]
3.6.2.2.2.3.1.4.6.1令o
t
=1;
[0121]
3.6.2.2.2.3.1.4.6.2若o
t
≤|l
t
|,转3.6.2.2.2.3.1.4.6.3获取数据中所有正向路径上第t步实体的第o
t
个类型的权重,否则说明数据中所有正向路径上第t步实体的每个类型的权重均已经获取,转3.6.2.2.2.3.1.4.6.6;
[0122]
3.6.2.2.2.3.1.4.6.3将中批数据所有正向路径的第t个实体的第o
t
个类型的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的类型嵌入将输入到全连接层得到类型引导第二变量
[0123]
3.6.2.2.2.3.1.4.6.4将和相加,将相加后的和经过relu激活后输入全连接层得到批数据所有正向路径中第t步实体第o
t
个类型的权重
[0124]
3.6.2.2.2.3.1.4.6.5令o
t
=o
t
+1,转3.6.2.2.2.3.1.4.6.2;
[0125]
3.6.2.2.2.3.1.4.6.6将权重进行归一化,得到归一化后批数据中所有正向路径第t步实体的所有类型的权重集合
[0126]
3.6.2.2.2.3.1.4.6.7使用聚合批数据所有正向路径第t步实体的所有类型的表示,得到聚合后的批数据所有正向路径第t步实体的类型表示第t步实体的所有类型的表示,得到聚合后的批数据所有正向路径第t步实体的类型表示即(维度为(c*n)
×
|l
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.1.5;
[0127]
3.6.2.2.2.3.1.5将作为lstm
a
第t步的输入,得到lstm
a
第t步的输出维度为(c*n)
×
150;
[0128]
3.6.2.2.2.3.1.6将作为lstm
l
第t步的输入,得到lstm
l
第t步的输出维度为(c*n)
×
150;
[0129]
3.6.2.2.2.3.1.7令t=t+1,转3.6.2.2.2.3.1.3;
[0130]
3.6.2.2.2.3.1.8将和相加(即分别为t=m+1时lstm
a
和lstm
l
的输出),得到批数据中所有正向路径的实体表示维度为(c*n)
×
150。转3.6.2.2.2.3.2;
[0131]
3.6.2.2.2.3.2实体序列编码网络对反向路径的实体属性序列嵌入和反向路径的实体类型序列嵌入进行编码,分别使用lstm
a
和lstm
l
来捕获反向路径上实体序列的属性表示和类型表示,方法是:
[0132]
3.6.2.2.2.3.2.1使用反向路径的关系表示对lstm
a
和lstm
l
进行初始化:
[0133]
3.6.2.2.2.3.2.1.1将输入到全连接层得到lstm
a
的第二隐藏状态
将输入到全连接层得到lstm
a
的第二细胞状态
[0134]
3.6.2.2.2.3.2.1.2将输入到全连接层得到lstm
l
的第二隐藏状态将输入到全连接层得到lstm
l
的第二细胞状态
[0135]
3.6.2.2.2.3.2.2令t=1。
[0136]
3.6.2.2.2.3.2.3如果1≤t≤m+1,将t、和传给实体画像注意力网络,转第3.6.2.2.2.3.2.4步聚合数据中所有反向路径上第t步实体的属性信息和类型信息;否则说明数据中所有反向路径上实体的属性信息和类型信息已经聚合,转3.6.2.2.2.3.2.8。
[0137]
3.6.2.2.2.3.2.4实体画像注意力网络对批次数据的所有反向路径中的第t步实体的全部属性或全部类型的嵌入进行聚合,作为对实体的语义信息的刻画。具体过程为:
[0138]
3.6.2.2.2.3.2.4.1从(维度为(c*n)
×
(m+1)
×
|a
t
|
×
50)中取出批数据中所有反向路径的第t步实体的属性嵌入,记为(维度为(c*n)
×
|a
t
|
×
50);
[0139]
3.6.2.2.2.3.2.4.2将和级联,将级联后的和经过全连接层得到指导第t步属性注意力的引导变量
[0140]
3.6.2.2.2.3.2.4.3实体属性注意力网络将批数据中所有反向路径的第t步实体的属性嵌入进行聚合,方法为:
[0141]
3.6.2.2.2.3.2.4.3.1令v
t
=1;
[0142]
3.6.2.2.2.3.2.4.3.2若v
t
≤|a
t
|,转3.6.2.2.2.3.2.4.3.3获取数据中所有反向路径上第t步实体的第v
t
个属性的权重,否则说明数据中所有反向路径上第t步实体的每个属性的权重均已经获取,转3.6.2.2.2.3.2.4.3.6;
[0143]
3.6.2.2.2.3.2.4.3.3将中批数据所有反向路径的第t个实体的第v
t
个属性的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的属性嵌入将输入到全连接层得到属性引导第二变量
[0144]
3.6.2.2.2.3.2.4.3.4将和相加,将相加后的和经过relu激活后输入全连接层得到批数据所有反向路径中第t步实体第v
t
个属性的权重
[0145]
3.6.2.2.2.3.2.4.3.5令v
t
=v
t
+1,转3.6.2.2.2.3.2.4.3.2;
[0146]
3.6.2.2.2.3.2.4.3.6将权重进行归一化,得到归一化后批数据所有反向路径第t步实体的所有属性的权重集合
[0147]
3.6.2.2.2.3.2.4.3.7使用聚合批数据所有反向路径第t步实体的所有属性的表示,得到聚合后的批数据所有反向路径第t步实体的属性表示
即将(维度为(c*n)
×
|a
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.2.4.4;
[0148]
3.6.2.2.2.3.2.4.4从(维度为(c*n)
×
(m+1)
×
|l
t
|
×
50)中取出批数据中所有反向路径的第t步实体的类型嵌入,记为(维度为(c*n)
×
|l
t
|
×
50);
[0149]
3.6.2.2.2.3.2.4.5将和级联,将级联后的和经过全连接层得到指导第t步类型注意力的引导向量
[0150]
3.6.2.2.2.3.2.4.6实体类型注意力网络将批数据中所有反向路径的第t步实体的类型嵌入进行聚合,方法为:
[0151]
3.6.2.2.2.3.2.4.6.1令o
t
=1;
[0152]
3.6.2.2.2.3.2.4.6.2若o
t
≤|l
t
|,转3.6.2.2.2.3.2.4.6.3获取数据中所有反向路径上第t步实体的第o
t
个类型的权重,否则说明数据中所有反向路径上第t步实体的每个类型的权重均已经获取,转3.6.2.2.2.3.2.4.6.6;
[0153]
3.6.2.2.2.3.2.4.6.3将中批数据中所有反向路径的第t个实体的第o
t
个类型的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的类型嵌入将输入到全连接层得到类型引导第二变量
[0154]
3.6.2.2.2.3.2.4.6.4将和相加,将相加后的和经过relu激活后输入全连接层得到批数据所有反向路径中第t步实体第o
t
个类型的权重
[0155]
3.6.2.2.2.3.2.4.6.5令o
t
=o
t
+1,转3.6.2.2.2.3.2.4.6.2;
[0156]
3.6.2.2.2.3.2.4.6.6将权重进行归一化,得到归一化后批数据中所有反向路径第t步实体的所有类型的权重集合
[0157]
3.6.2.2.2.3.2.4.6.7使用聚合批数据所有反向路径第t步实体的所有类型的表示,得到聚合后的批数据所有反向路径第t步实体的类型表示径第t步实体的所有类型的表示,得到聚合后的批数据所有反向路径第t步实体的类型表示即(维度为(c*n)
×
|l
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.2.5;
[0158]
3.6.2.2.2.3.2.5将作为lstm
a
第t步的输入,得到lstm
a
第t步的输出维度为(c*n)
×
150;
[0159]
3.6.2.2.2.3.2.6将作为lstm
l
第t步的输入,得到lstm
l
第t步的输出维度为(c*n)
×
150;
[0160]
3.6.2.2.2.3.2.7令t=t+1,转3.6.2.2.2.3.2.3;
[0161]
3.6.2.2.2.3.2.8将和相加(即分别为t=m+1时lstm
a
和lstm
l
的输出),得到批数据中所有反向路径的实体表示维度为(c*n)
×
150,转3.6.2.2.2.3.2.9;
[0162]
3.6.2.2.2.3.2.9将3.6.2.2.2.3.1.8中批数据所有正向路径的实体表示和3.6.2.2.2.3.2.8中批数据所有反向路径的实体表示的传给路径编码器,转3.6.2.2.2.4。
[0163]
3.6.2.2.2.4路径编码器从关系编码器接收和从实体编码器接收和分别使用正向路径注意力网络和反向路径注意力网络计算批数据中所有样本的正向路径的表示和反向路径的表示,具体步骤为:
[0164]
3.6.2.2.2.4.1将批数据的所有正向路径的关系表示和所有正向路径的实体表示级联,得到批数据的所有正向路径的路径表示,记为维度为(c*n)
×
300,批数据里每条路径的维度为300;
[0165]
3.6.2.2.2.4.2将批数据的所有反向路径的关系表示和所有反向路径的实体表示级联,得到批数据的所有反向路径的路径表示,记为维度为(c*n)
×
300,批数据里每条路径的维度为300;
[0166]
3.6.2.2.2.4.3使用正向路径注意力网络聚合中所有样本的n条正向路径的表示,方法为:
[0167]
3.6.2.2.2.4.3.1令n=1;
[0168]
3.6.2.2.2.4.3.2若n≤n,转3.6.2.2.2.4.3.3获取数据中所有样本的第n条正向路径的权重,否则说明数据中所有样本的每条正向路径的权重均已经获取,转3.6.2.2.2.4.3.5;
[0169]
3.6.2.2.2.4.3.3将中所有样本的第n条路径的表示记为(维度为c
×
300)。将经过f
p
和两层全连接层(f
p
之后会经过relu函数激活)后得到的值作为第n条正向路径的权重
[0170]
3.6.2.2.2.4.3.4令n=n+1,转3.6.2.2.2.4.3.2;
[0171]
3.6.2.2.2.4.3.5将批数据中所有样本的所有正向路径的权重进行归一化,得到归一化后批数据中所有样本的所有正向路径的权重
[0172]
3.6.2.2.2.4.3.6使用聚合批数据中样本的正向路径的表示,得到该批数据所有样本的正向路径表示即(维度为(c*n)
×
300)聚合后得到(维度为c
×
300),转3.6.2.2.2.4.4;
[0173]
3.6.2.2.2.4.4使用反向路径注意力网络聚合中所有样本的n条反向路径的
表示,方法为:
[0174]
3.6.2.2.2.4.4.1令n=1;
[0175]
3.6.2.2.2.4.4.2若n≤n,转3.6.2.2.2.4.4.3获取数据中所有样本的第n条反向路径的权重,否则说明数据中所有样本的每条反向路径的权重均已经获取,转3.6.2.2.2.4.4.5;
[0176]
3.6.2.2.2.4.4.3将中所有样本的第n条路径的表示记为(维度为c
×
300)。将经过f
′
p
和两层全连接层(f
′
p
之后会经过relu函数激活)后得到的值作为第n条反向路径的权重
[0177]
3.6.2.2.2.4.4.4令n=n+1,转3.6.2.2.2.4.4.2;
[0178]
3.6.2.2.2.4.4.5将批数据中所有样本的所有反向路径的权重进行归一化,得到归一化后批数据中所有样本的所有反向路径的权重
[0179]
3.6.2.2.2.4.4.6使用聚合批数据中样本的反向路径的表示,得到该批数据所有样本的反向路径表示即(维度为(c*n)
×
300)聚合后得到(维度为c
×
300),转3.6.2.2.2.4.5;
[0180]
3.6.2.2.2.4.5将和传输给预测器,转3.6.2.2.2.5;
[0181]
3.6.2.2.2.5预测器从路径编码器接收和计算该批数据中所有样本的预测概率,方法为:
[0182]
3.6.2.2.2.5.1将输入到全连接层f1中,将输入到全连接层f2中,然后将全连接层f1和f2的输出进行拼接,得到该批数据中所有样本的路径表示维度为c
×
600,其中该批数据中每个样本的路径表示维度为600。
[0183]
3.6.2.2.2.5.2将输入到全连接层f3中,然后将f3的输出经过relu函数激活后输入到全连接层f4中,得到所有样本的路径的新表示
[0184]
3.6.2.2.2.5.3将输入sigmoid函数中得到该批次所有数据的预测概率集合有数据的预测概率集合是该批次数据中样本s
c
的预测概率,的预测概率,转3.6.2.2.3。
[0185]
3.6.2.2.3使用步骤3.6.2.2.1得到的标签集合y
q*,b
和步骤3.6.2.2.2.5.3事实预测网络的预测概率集合计算该批次数据s
q*,b
的损失值loss。方法如下式,其中表示该批次数据中查询关系r
q
的正样本集合,表示该批次数据中查询关系r
q
的正样本集合和负样本集合,如果s
q*,b
中的样本s
c
的标签y
c
=1,则样本否则
[0186][0187]
3.6.2.2.4使用adam优化算法对损失值loss最小化,以反向传播训练网络参数,事实预测网络中的参数(三个嵌入矩阵w
r
、w
a
、w
l
,3个lstm网络(lstm
r
、lstm
a
和lstm
l
)和20个全连接层的权重矩阵和偏置向量)都得到一次更新。
[0188]
3.6.2.2.5令processednum=processednum+c,b=b+1,转3.6.2.2。
[0189]
3.6.2.3令批处理次数b=1,令已预测的验证样本数目predictednum=0,令验证样本的预测概率集合
[0190]
3.6.2.4如果转3.6.2.4.1对s
q#
中第b个batch的验证数据进行预测,其中|s
q#
|为验证样本集合s
q#
的样本数目,否则说明已经对s
q#
中的所有验证样本进行预测,转3.6.2.5;
[0191]
3.6.2.4.1事实预测网络的嵌入层从步骤3.5中得到的s
q#
中读取c
#
个样本作为第b个batch的验证数据,即一个批次的验证数据,记为样本验证批次集合1≤c
#
≤c
#
,其中c
#
=min(batchsize,|s
q#
|
‑
predictednum)。从步骤3.5得到的y
q#
、、中取出与s
q#,b
的这c
#
个样本对应的数据,分别记为标签验证批次集合正向路径关系序列验证批次集合反向路径关系序列验证批次集合正向路径实体属性信息序列验证批次集合和正向路径实体类型信息序列验证批次集合息序列验证批次集合反向路径实体属性信息序列验证批次集合和反向路径实体类型信息序列验证批次集合
[0192]
3.6.2.4.2采用步骤3.6.2.2.2中所述的事实预测网络预测方法f
predict
,对第b个batch的验证数据和查询关系r
q
、查询关系的反关系r
′
q
进行计算,得到第b个batch的验证数据的预测概率集合即其中是该批次数据中样本的预测概率。将加入中,即令
[0193]
3.6.2.4.3令predictednum=predictednum+c
#
,b=b+1,转3.6.2.4。
[0194]
3.6.2.5使用验证数据集合s
q#
的标签集合y
q#
和事实预测网络的预测概率集合计算事实预测网络对验证数据进行预测的平均精确度,记为若则令则令并保存事实预测网络的参数,转3.6.2.6;若则不用保存事实预测网络的参数,直接转3.6.2.6。
[0195]
3.6.2.6令epoch=epoch+1,转3.6.2;
[0196]
3.7令q=q+1,转3.2;
[0197]
3.8计算该基于路径的知识图谱补全系统进行事实预测的平均精度均值map,3.8计算该基于路径的知识图谱补全系统进行事实预测的平均精度均值map,转第四步。
[0198]
第四步:事实补全模块对用户输入的需要补全的知识图谱进行补全,方法是:
[0199]
4.1事实补全模块从数据预处理模块接收补全样本的数据集合u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
,令补全样本集合u对应的所有补全样本的预测概率集合
[0200]
4.2令q=1;
[0201]
4.3如果q≤q,转4.3.1预测查询关系r
q
下所有补全样本属于事实的概率,否则说明所有查询关系下的补全样本均已预测,转4.4。
[0202]
4.3.1从r
q
中取出查询关系r
q
,根据r
q
选择第三步中训练好的事实预测网络
[0203]
4.3.2从u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
中中取出关于查询关系r
q
的补全数据u
q
、u
′
qr
、u
′
qa
、u
′
ql
。
[0204]
4.3.3令u
q
对应的补全样本的预测概率集合为
[0205]
4.3.4使用训练好的事实预测网络预测u
q
中所有样本属于事实的概率,得到u
q
中所有样本属于事实的预测概率集合z
q
,具体地:
[0206]
4.3.4.1令批处理次数b=1,令已预测补全样本的数目predictednum=0;
[0207]
4.3.4.2如果转4.3.4.2.1对u
q
中第b个batch的补全数据进行预测,否则说明已经对u
q
中的所有补全样本进行预测,转4.3.5;
[0208]
4.3.4.2.1事实预测网络的嵌入层从u
q
读取c
u
个样本作为第b个batch的补全数据,即一个批次的补全数据,记为样本补全批次集合1≤c
u
≤c
u
,其中c
u
=min(batchsize,|u
q
|
‑
predictednum)。从中取出与u
q,b
的这c
u
个样本对应的数据,分别记为正向路径关系序列补全批次集合反向路径关系序列补全批次集合正向路径实体属性信息序列补全批次集合和正向路径实体类型信息序列补全批次集合息序列补全批次集合反向路径实体属性信息序列补全批次集合和反向路径实体类型信息序列补全批次集合
[0209]
4.3.4.2.2采用步骤3.6.2.2.2中所述的事实预测网络预测方法f
predict
,对第b个batch的补全数据和查询关系r
q
、查询关系的反关系r
′
q
进行计算,得到第b个batch经过训练好的事实预测网络预测得到的补全数据的预测概率集合率集合其中是该批次数据中样本的预测概率。
[0210]
4.3.4.2.3事实补全模块从事实预测网络接收批次数据的预测概率集合将加入到r
q
下的补全样本的预测概率集合z
q
中,即令
[0211]
4.3.4.2.4令predictednum=predictednum+c
u
,b=b+1,转4.3.4.2。
[0212]
4.3.5将z
q
作为元素加入到所有补全样本的预测概率集合中,即z=z∪{z
q
};
[0213]
4.3.6令q=q+1,转4.3;
[0214]
4.4根据所有补全样本集合u(u={u1,
…
,u
q
,
…
,u
q
})的预测概率集合z(z={z1,
…
,z
q
,
…
,z
q
}),判断样本是否是需要补全的事实,得到补全后的知识图谱,具体地:
[0215]
4.4.1将补全后的知识图谱的事实集合记为f
new
,令f
new
=f;
[0216]
4.4.2设置阈值δ(0.5≤δ≤1),令q=1;
[0217]
4.4.3如果q≤q,则转4.4.4补全查询关系r
q
下的缺失事实,否则说明所有查询关系下的缺失事实均已补全,转4.5。
[0218]
4.4.4令w=1;
[0219]
4.4.5如果w≤|u
q
|,则转4.4.6判断补全样本u
w
是否为缺失事实,否则说明查询关系r
q
下的缺失事实均已补全,转4.4.8。
[0220]
4.4.6u
q
中第w个样本u
w
代表三元组u
w
的预测概率为z
q
中的第w个预测概率z
w
,若预测概率z
w
≥δ,则在用户提供的知识图谱中将实体和使用r
q
连接,即将添加到事实集合f
new
中,
[0221]
4.4.7令w=w+1,转4.4.5;
[0222]
4.4.8令q=q+1,转4.4.3;
[0223]
4.5将用户提供的知识图谱中的事实集合f更新为f
new
,即完成了对用户提供的知识图谱的补全。
[0224]
采用本发明可以达到以下技术效果:
[0225]
1.本发明的第一步构建了一个完整的基于路径的知识图谱补全系统,以补全知识图谱中缺失的事实,融合了数据预处理模块、事实预测网络和事实补全模块。该系统可以针对用户输入的需要补全的知识图谱,在第二步中构造训练集训练事实预测网络。事实预测网络由嵌入层、关系编码器、实体编码器、路径编码器、预测器五个部分组成,其中前四个模块同时编码正向路径和反向路径上的特征,预测器则根据正向和反向路径表示进行预测,提升了事实预测网络预测的平均精度均值,提升了事实补全模块补全事实的可信度。
[0226]
2.本发明在第三步事实预测网络的实体编码器中提取实体的表示时提出了使用实体的属性对实体的语义信息进行刻画,实体的属性即在知识图谱中与该实体相连的边。事实预测网络的实体编码器使用实体属性注意力和实体类型注意力两个网络聚合实体的属性表示和类型表示,丰富了路径上实体的语义信息,提升了路径上实体表示的准确性,进一步提升了路径表示的准确性和事实预测的平均精度均值。
[0227]
3.本发明第三步训练事实预测网络时将输出的预测值与真值不断拟合,得到了可以准确预测实体间是否存在某个关系的事实预测网络,从而可以对补全样本是否是知识图谱中缺失的事实进行更准确的判断,使得补全到知识图谱中的事实可信度更高。
附图说明:
[0228]
图1为本发明整体流程图。
[0229]
图2为本发明第一步构建的基于路径的知识图谱补全系统逻辑结构图。
[0230]
图3为图2中的事实预测网络的逻辑结构图。
[0231]
图4为本发明第四步补全知识图谱中缺失事实的流程图。
具体实施方式:
[0232]
图1为本发明整体流程图。如图1所示,本发明包括以下步骤:
[0233]
第一步:构建基于路径的知识图谱事实补全系统。该系统如图2所示,由数据预处理模块、事实预测网络、事实补全模块构成。
[0234]
数据预处理模块与事实预测网络相连,接收用户输入的知识图谱,对用户输入的知识图谱进行预处理,得到训练事实预测网络所需的训练数据(包括训练样本的数据集合和训练样本的标签集合)、验证事实预测网络所需的验证数据(包括验证样本的数据集合和验证样本的标签集合)、以及事实补全模块所需的要判断是否为缺失事实的补全数据(包括补全样本的数据集合),输出给事实预测网络,并将补全样本的数据集合输出给事实补全模块。数据预处理模块由路径抽取函数f
extractpath
和路径预处理函数f
preprocesspaths
构成,其中f
extractpath
从知识图谱中抽取每个样本的实体之间的路径信息,f
preprocesspaths
将每个样本的实体间路径信息处理为事实预测网络需要的数据结构。将知识图谱中的实体集合、关系集合、事实集合分别记为e={e
i
},r={r
j
}和将实体的属性集合记为a={a
v
},将实体的类型集合记为l={l
o
},其中1≤i≤|e|,1≤i1≤|e|,1≤i2≤|e|,1≤j≤|r|,1≤v≤|a|,1≤o≤|l|,|e|、|r|、|a|、|l|分别表示实体的总数、关系的总数、属性的总数和类型的总数。将r
′
j
记为r
j
的反关系,表示若则根据e、r、f、a、l,数据预处理模块获取训练样本集合s
*
、训练样本的标签集合y
*
、验证样本集合s
#
、验证样本的标签集合y
#
、以及补全样本集合u。对于样本集合(包括训练样本集合s
*
、验证样本集合s
#
、补全样本集合u)中的每个样本(包括训练样本、验证样本、补全样本),数据预处理模块先使用f
extractpath
从知识图谱中抽取样本的实体对之间的正向路径集合,然后使用f
preprocesspaths
处理该正向路径集合输出样本的数据集合,构成训练样本的数据集合、验证样本的数据集合、补全样本的数据集合。
[0235]
事实预测网络如图3所示,由嵌入层、关系编码器、实体编码器、路径编码器、预测器五个部分组成。其中,嵌入层包含3个嵌入矩阵,分别为关系的嵌入矩阵w
r
、实体属性的嵌入矩阵w
a
、实体类型的嵌入矩阵w
l
;关系编码器用于提取每条路径的关系序列特征,由一个lstm网络构成,记为lstm
r
;实体编码器用于提取每条路径的实体序列特征(包括每条路径上实体的属性信息序列的特征和类型信息序列的特征),由实体画像注意力网络和实体序列编码网络两个子网络构成,其中实体画像注意力网络由结构相同的实体属性注意力网络和实体类型注意力网络构成,实体属性注意力网络由4个全连接层构成,实体类型注意力网络由4个全连接层构成,而实体序列编码网络由两个lstm网络(分别记为lstm
a
和lstm
l
)及4个全连接层构成;路
径编码器由结构相同的正向路径注意力网络和反向路径注意力网络构成,其中正向路径注意力网络由2个全连接层f
p
和构成,反向路径注意力网络由2个全连接层f
′
p
和构成,分别用于聚合每个样本的所有正向路径的特征和所有反向路径的特征;预测器由4个全连接层f1,f2,f3和f4构成,用于预测每个样本属于事实的概率。事实预测网络从数据预处理模块得到样本数据集合(包括训练样本的数据集合、验证样本的数据集合、补全样本的数据集合),提取样本数据集合中每个样本的路径特征,然后计算出每个样本属于事实的概率,组成预测概率集合(包括训练样本的预测概率集合、验证样本的预测概率集合、补全样本的预测概率集合)。其中,(1)嵌入层接收数据预处理模块的数据,将每个关系、实体属性、实体类型、实体属性分别使用w
r
、w
a
、w
l
转化为向量表示,然后将每个样本的每条路径的关系序列转化为向量表示(即每个样本的正向路径集合中每条正向路径的关系序列的嵌入和反向路径集合中每条反向路径的关系序列的嵌入)输出给关系编码器,将每个样本的每条路径上实体的属性信息序列和实体的类型信息序列转化为向量表示(即每个样本的每条正向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入,和每个样本的每条反向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入)输出给实体编码器,将每个样本的查询关系和反向查询关系转化为向量表示(即每个样本的查询关系的嵌入、每个样本的反向查询关系的嵌入)也输出给实体编码器;(2)关系编码器接收嵌入层输出的每个样本的正向路径集合中每条正向路径的关系序列的嵌入和反向路径集合中每条反向路径的关系序列的嵌入,对这些嵌入进行编码,得到每个样本的每条正向路径的关系表示和每条反向路径的关系表示,将每个样本的每条正向路径的关系表示和每条反向路径的关系表示输出给实体编码器和路径编码器;(3)实体编码器接收来自关系编码器的每个样本的每条正向路径的关系表示和每条反向路径的关系表示,还接收来自嵌入层的每个样本的查询关系的嵌入、每个样本的反向查询关系的嵌入、每个样本的每条正向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入、每个样本的每条反向路径上实体的属性信息序列的嵌入和实体的类型信息序列的嵌入,对这些嵌入进行编码,得到每个样本的每条正向路径的实体表示和每条反向路径的实体表示,将每个样本的每条正向路径的实体表示和每条反向路径的实体表示输出给路径编码器;(4)路径编码器接收来自关系编码器的每个样本的每条正向路径的关系表示和每条反向路径的关系表示,以及来自实体编码器的每个样本的每条正向路径的实体表示和每条反向路径的实体表示,对这些表示进行编码,得到每个样本的正向路径表示和反向路径表示,将每个样本的正向路径表示和反向路径表示输出给预测器;(5)预测器接收来自路径编码器的每个样本的正向路径表示和反向路径表示,对这些表示进行编码,得到每个样本的预测结果(即每个样本属于事实的概率),将每个样本的预测结果组成预测概率集合。事实预测网络根据数据预处理模块输出的训练样本的标签集合和事实预测网络预测的训练样本的预测概率集合,进行训练并更新网络参数;事实预测网络根据数据预处理模块输出的验证样本的标签集合和事实预测网络预测的验证样本的预测概率集合,进行验证并保存最优的网络参数。如果输入事实预测网络的样本数据集合是补全样本的数据集合,则事实预测网络将计算得到的补全样本的预测概率集合输出给事实补全模块。
[0236]
事实补全模块与数据预处理模块和事实预测网络相连接。事实补全模块接收数据预处理模块输出的补全样本的数据集合和训练好的事实预测网络输出的补全样本的预测
概率集合z,根据每个补全样本的预测概率判断补全样本的数据集合中补全样本集合u里的每个补全样本是否是需要补全的事实,如果补全样本是需要补全的事实,则将补全样本u
w
(u
w
∈u)添加到知识图谱的事实集合中,即令f
new
=f∪u
w
,f
new
为补全后的知识图谱的事实集合。
[0237]
第二步:数据预处理模块根据用户输入的需要补全的知识图谱(包括e、r、f)和l、d
l
、r
q
,准备训练事实预测网络所需的训练数据(包括训练样本的数据集合和训练样本的标签集合)、验证事实预测网络所需的验证数据(包括验证样本的数据集合和验证样本的标签集合)、以及事实补全模块所需的要判断是否为缺失事实的补全数据(包括补全样本的数据集合)。
[0238]
2.1数据预处理模块接收用户输入的需要补全的知识图谱(包括实体集合e、关系集合r、事实集合f)、实体的类型集合l和每个实体对应的类型信息的字典d
l
(字典的key为实体,value为实体对应的类型集合),以及需要补全的查询关系集合r
q
={r
q
|r
q
∈r}(1≤q≤q,q为r
q
中元素的个数)。
[0239]
2.2数据预处理模块使用路径抽取函数f
extractpath
和路径预处理函数f
preprocesspaths
准备训练和验证事实预测网络需要的训练样本的数据集合和训练样本的标签集合、验证样本的数据集合和验证样本的标签集合,具体地:
[0240]
2.2.1令存储所有训练样本的集合存储所有训练样本的标签集合存储所有训练样本的所有正向路径的关系序列的集合存储所有训练样本的所有反向路径的关系序列的集合存储所有训练样本的所有正向路径的实体属性信息序列集合存储所有训练样本的所有正向路径的实体类型信息序列集合存储所有训练样本的所有反向路径的实体属性信息序列集合存储所有训练样本的所有反向路径的实体类型信息序列集合
[0241]
2.2.2令存储所有验证样本的集合存储所有验证样本的标签集合存储所有验证样本的所有正向路径的关系序列的集合存储所有验证样本的所有反向路径的关系序列的集合存储所有验证样本的所有正向路径的实体属性信息序列集合存储所有验证样本的所有正向路径的实体类型信息序列集合存储所有验证样本的所有反向路径的实体属性信息序列集合存储所有验证样本的所有反向路径的实体类型信息序列集合
[0242]
2.2.3令q=1;
[0243]
2.2.4如果q≤q,转2.2.5获取查询关系r
q
下的样本数据,否则说明全部样本数据均已经处理,转2.2.18。
[0244]
2.2.5设置负样本数目与正样本数目的比值为k
n|p
,k
n|p
为正整数,且1≤k
n|p
≤10。设置样本数量阈值为k
q
,k
q
为正整数,且其中表示以r
q
为关系的事实,即为关系的事实,即表示集
合的元素数目。令查询关系r
q
的样本集合为令查询关系r
q
的样本标签集合为令查询关系r
q
下所有样本的所有正向路径的关系序列的集合查询关系r
q
下所有样本的所有反向路径的关系序列的集合查询关系r
q
下所有样本的所有正向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有正向路径的实体类型信息序列集合查询关系r
q
下所有样本的所有反向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有反向路径的实体类型信息序列集合
[0245]
2.2.6令k=1;
[0246]
2.2.7如果k≤k
q
,转2.2.8获取查询关系r
q
下单个样本的数据,否则说明查询关系r
q
下的所有样本的数据已经获取,转2.2.14。
[0247]
2.2.8随机从实体集合e中选择两个实体和即1≤k1≤|e|,1≤k2≤|e|。构造样本s
k
,且若则s
k
为正样本,令s
k
的标签y
k
=1,若则s
k
为负样本,令s
k
的标签y
k
=0。构造样本s
k
时需要控制最终s
q
内正负样本的比例为1:k
n|p
(即每构造一个正样本,就构造k
n|p个
负样本)。
[0248]
2.2.9令s
k
的所有正向路径的关系序列的集合s
k
的所有反向路径的关系序列的集合s
k
的所有正向路径的实体属性信息序列集合s
k
的所有正向路径的实体类型信息序列集合s
k
的所有反向路径的实体属性信息序列集合s
k
的所有反向路径的实体类型信息序列集合
[0249]
2.2.10f
extractpath
采用随机游走方法抽取样本s
k
的实体到实体的n条正向路径,放到s
k
的正向路径集合中,其中1≤n≤n,第n条路径p
n
由实体和关系交替构成,m为路径p
n
的长度,实体为路径p
n
上第t步的实体,r
t
∈r(1≤t≤m)为路径p
n
上第t步的关系。即采用f
extractpath
函数处理得到到的n条正向路径的集合
[0250]
2.2.11f
preprocesspaths
将样本s
k
的正向路径集合处理为事实预测网络需要的数据结构,得到样本s
k
的查询关系r
q
、反向查询关系r
′
q
,样本s
k
的所有正向路径的关系序列的集合所有反向路径的关系序列的集合所有正向路径的实体属性信息序列集合和实体的类型信息序列集合所有反向路径的实体的属性信息序列集合和实体的类型信息序列集合具体为:
[0251]
2.2.11.1令n=1;
[0252]
2.2.11.2如果n≤n,转2.2.11.3处理样本s
k
的第n条路径的数据,否则说明样本s
k
的全部路径均已经处理,转2.2.11.14。
[0253]
2.2.11.3获取中第n条路径p
n
的反向路径p
′
n
,
[0254]
2.2.11.4将p
n
分为正向关系序列和正向实体序列和正向实体序列
[0255]
2.2.11.5将p
′
n
分为反向关系序列和反向实体序列和反向实体序列
[0256]
2.2.11.6获取上所有实体的属性信息,方法是:
[0257]
2.2.11.6.1令t=1;
[0258]
2.2.11.6.2如果t≤m+1,转2.2.11.6.3获取上的第t步实体的属性信息,否则说明上所有实体的属性信息均已经获取,转2.2.11.7。
[0259]
2.2.11.6.3获取上的第t步实体e
t
的属性集合a
t
,1≤v
t
≤|a
t
|,|a
t
|为a
t
中属性的个数。本发明提出的任意一个实体的属性信息是从知识图谱中与该实体相连的关系获得的,分为两种情况进行处理:
[0260]
2.2.11.6.3.1如果e
t
既不是也不是那么e
t
的属性集合就是以e
t
作为头实体的所有事实构成的邻居事实集合中的关系的集合,即中的关系的集合,即转2.2.11.6.4。
[0261]
2.2.11.6.3.2如果e
t
是或者那么e
t
的属性集合就是以e
t
作为头实体的所有事实去掉包含和作为实体的所有事实构成的邻居事实集合中的关系的集合,即中的关系的集合,即其中表示以和分别作为头实体和尾实体的事实,即分别作为头实体和尾实体的事实,即转2.2.11.6.4。
[0262]
2.2.11.6.4对a
t
内的属性进行排序。方法是将a
t
内的全部属性根据其在中出现的频次从高到低进行排序,频次高的属性排序在前。具体地,将e
t
的第v
t
个属性在出现的次数记为若属性和的次数满足则属性排序在之前,最后将e
t
的属性集合记为意味着意味着
[0263]
2.2.11.6.5令t=t+1,转2.2.11.6.2;
[0264]
2.2.11.7将上获得的所有实体的属性信息记为
[0265]
2.2.11.8将上所有实体的属性信息记为为的逆序,即的逆序,即
[0266]
2.2.11.9获取上所有实体的类型信息,方法是:
[0267]
2.2.11.9.1令t=1;
[0268]
2.2.11.9.2如果t≤m+1,转2.2.11.9.3获取上的第t步实体的类型信息,否则说明上所有实体的类型信息均已经获取,转2.2.11.10。
[0269]
2.2.11.9.3令e
t
的类型集合l
t
为字典d
l
中键e
t
对应的值,即令l
t
=d
l
[e
t
],l
t
可以表示为1≤o
t
≤|l
t
|,为l
t
中的第o
t
个类型,|l
t
|为l
t
中类型的个数。
[0270]
2.2.11.9.4令t=t+1,转2.2.11.9.2;
[0271]
2.2.11.10将上获得的所有实体的类型信息记为
[0272]
2.2.11.11将上所有实体的类型信息记为为的逆序,即的逆序,即
[0273]
2.2.11.12将2.2.11.4中获得的正向路径p
n
的关系序列加入集合即令将2.2.11.5中获得的反向路径p
′
n
的关系序列加入集合即令将2.2.11.7获得的正向路径p
n
的实体属性序列加入集合即令将2.2.11.10获得的正向路径p
n
的实体类型序列加入集合即令将2.2.11.8获得的反向路径p
′
n
的实体属性序列加入集合即令将2.2.11.11获得的反向路径p
′
n
的实体类型序列加入集合即令
[0274]
2.2.11.13令n=n+1,转2.2.11.2。
[0275]
2.2.11.14将下述信息作为f
preprocesspaths
处理样本s
k
的正向路径集合的结果:样本s
k
的查询关系r
q
、反向查询关系r
′
q
,样本s
k
的所有正向路径的关系序列的集合的所有正向路径的关系序列的集合所有反向路径的关系序列的集合所有正向路径的实体属性信息序列集合和实体的类型信息序列集合和实体的类型信息序列集合所有反向路径的实体的属性信息序列集合和实体的类型信息序列集合转2.2.12。
[0276]
2.2.12将样本s
k
和s
k
的标签分别加入样本集合s
q
和样本的标签集合y
q
中,即令s
q
=s
q
∪{s
k
},令y
q
=y
q
∪{y
k
};将2.2.11.14中获得的f
preprocesspaths
处理样本s
k
的正向路径集合的结果作为元素添加到查询关系r
q
下的样本的数据集合中,即令下的样本的数据集合中,即令
[0277]
2.2.13令k=k+1,转2.2.7。
[0278]
2.2.14此时查询关系r
q
下所有样本为s
q
={s1,
…
,s
k
,
…
,s
k
},查询关系r
q
下所有样
本的标签集合为y
q
={y1,
…
,y
k
,
…
,y
k
},查询关系r
q
下所有样本的所有正向路径的关系序列的集合查询关系r
q
下所有样本的所有反向路径的关系序列的集合下所有样本的所有反向路径的关系序列的集合查询关系r
q
下所有样本的所有正向路径的实体属性信息序列集合下所有样本的所有正向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有正向路径的实体类型信息序列集合下所有样本的所有正向路径的实体类型信息序列集合查询关系r
q
下所有样本的所有反向路径的实体属性信息序列集合下所有样本的所有反向路径的实体属性信息序列集合查询关系r
q
下所有样本的所有反向路径的实体类型信息序列集合下所有样本的所有反向路径的实体类型信息序列集合将s
q
、y
q
、按照a:c的比例分为查询关系r
q
下的训练数据s
q*
、y
q*
、和验证数据s
q#
、y
q#
、、a和c为正数,一般a>c,且a+c=10,优选a:c=7:3。
[0279]
2.2.15将查询关系r
q
下的所有训练数据作为元素加入总的训练数据中,即令s
*
=s
*
∪{s
q*
},y
*
=y
*
∪{y
q*
},},
[0280]
2.2.16将查询关系r
q
下的所有验证数据作为元素加入总的验证数据中,即令s
#
=s
#
∪{s
q#
},y
#
=y
#
∪{y
q#
},},
[0281]
2.2.17令q=q+1,转2.2.4。
[0282]
2.2.18此时所有训练样本的标签集合为y
*
={y1,
…
,y
q
,
…
,y
q
},所有的训练样本的集合为s
*
={s
1*
,
…
,s
q*
,
…
,s
q*
},所有训练样本的所有正向路径的关系序列的集合},所有训练样本的所有正向路径的关系序列的集合所有训练样本的所有反向路径的关系序列的集合所有训练样本的所有反向路径的关系序列的集合所有训练样本的所有正向路径的实体属性信息序列集合所有训练样本的所有正向路径的实体属性信息序列集合所有训练样本的所有正向路径的实体类型信息序列集合所有训练样本的所有正向路径的实体类型信息序列集合所有训练样本的所有反向路径的实体属性信息序列集合所有训练样本的所有反向路径的实体属性信息序列集合所有训练样本的所有反向路径的实体类型信息序列集合所有训练样本的所有反向路径的实体类型信息序列集合s
*
、s
*
′
r
、s
*
′
a
、s
*
′
l
构成所有训练样本的数据集合;所有验证样本的标签集合为y
#
={y
1#
,
…
,y
q#
,
…
,y
q#
},所有的验证样本的集合为s
#
={s
1#
,
…
,s
q#
,
…
,s
q#
},所有验证样本的所有正向路径的关系序列的集合},所有验证样本的所有正向路径的关系序列的集合所有验证样本的所有反向路径的关系序列的集合有验证样本的所有反向路径的关系序列的集合所有验证样本的所有正向路径的实体属性信息序列集合所有正向路径的实体属性信息序列集合所有验证样本的所有正向路径的实体类型信息序列集合向路径的实体类型信息序列集合所有验证样本的所有反向路径
的实体属性信息序列集合的实体属性信息序列集合所有验证样本的所有反向路径的实体类型信息序列集合类型信息序列集合s
#
、s
′
#r
、s
′
#a
、s
′
#l
构成所有验证样本的数据集合,转2.3。
[0283]
2.3数据预处理模块使用路径抽取函数f
extractpath
和路径预处理函数f
preprocesspaths
准备事实补全模块所需的要判断是否为缺失事实的补全样本的数据集合,具体地:
[0284]
2.3.1令存储所有补全样本的集合存储所有补全样本的所有正向路径的关系序列的集合存储所有补全样本的所有反向路径的关系序列的集合存储所有补全样本的所有正向路径的实体属性信息序列集合存储所有补全样本的所有正向路径的实体类型信息序列集合存储所有补全样本的所有反向路径的实体属性信息序列集合存储所有补全样本的所有反向路径的实体类型信息序列集合
[0285]
2.3.2令q=1;
[0286]
2.3.3如果q≤q,转2.3.4获取查询关系r
q
下的补全样本数据,否则说明全部补全样本数据均已经处理,转2.3.14。
[0287]
2.3.4准备需要判断是否为缺失事实的查询关系r
q
下的所有补全样本的集合u
q
,u
q
为没有被f包含的关系为r
q
的三元组的集合,即的三元组的集合,即简记为1≤w≤|u
q
|,|u
q
|为u
q
中元素的个数,即查询关系r
q
下的补全样本的总数)。
[0288]
2.3.5令查询关系r
q
下所有补全样本的所有正向路径的关系序列的集合令查询关系r
q
下所有补全样本的所有反向路径的关系序列的集合令查询关系r
q
下所有补全样本的所有正向路径的实体属性信息序列集合令查询关系r
q
下所有补全样本的所有正向路径的实体类型信息序列集合令查询关系r
q
下所有补全样本的所有反向路径的实体属性信息序列集合令查询关系r
q
下所有补全样本的所有反向路径的实体类型信息序列集合
[0289]
2.3.6令w=1;
[0290]
2.3.7若w≤|u
q
|,转2.3.8获取查询关系r
q
下补全样本u
w
的数据,否则说明u
q
中每个补全样本的数据均已经获取,转2.3.12。
[0291]
2.3.8采用步骤2.2.10所述的f
extractpath
函数处理得到样本u
w
的实体到实体的n
u
条正向路径信息,放到u
w
的正向路径集合中,其中中的第n
u
条路径1≤n
u
≤n
u
。
[0292]
2.3.9采用步骤2.2.11所述的路径预处理函数f
preprocesspaths
处理u
w
的正向路径集合得到样本u
w
的查询关系r
q
、反向查询关系r
′
q
,样本u
w
的所有正向路径的关系序列的集合所有反向路径的关系序列的集合所有正向路径的实体属性信息序列集合
和实体的类型信息序列集合所有反向路径的实体的属性信息序列集合和实体的类型信息序列集合
[0293]
2.3.10将作为元素添加到查询关系r
q
下补全样本的数据集合中,即令合中,即令
[0294]
2.3.11令w=w+1,转2.3.7。
[0295]
2.3.12此时u
q
中每个补全样本的数据均已经获取,查询关系r
q
下所有补全样本下所有补全样本的路径信息为:查询关系r
q
下所有补全样本的所有正向路径的关系序列的集合查询关系r
q
下所有补全样本的所有反向路径的关系序列的集合查询关系r
q
下所有补全样本的所有正向路径的实体属性信息序列集合查询关系r
q
下所有补全样本的所有正向路径的实体类型信息序列集合查询关系r
q
下所有补全样本的所有反向路径的实体属性信息序列集合查询关系r
q
下所有补全样本的所有反向路径的实体类型信息序列集合将该查询关系r
q
下的所有补全样本的数据作为元素加入总的补全样本的数据中,即令u=u∪{u
q
},},
[0296]
2.3.13令q=q+1,转2.3.3。
[0297]
2.3.14此时所有补全样本的集合为u={u1,
…
,u
q
,
…
,u
q
},所有补全样本的所有正向路径的关系序列的集合所有补全样本的所有反向路径的关系序列的集合所有补全样本的所有正向路径的实体属性信息序列集合所有补全样本的所有正向路径的实体类型信息序列集合所有补全样本的所有正向路径的实体类型信息序列集合所有补全样本的所有反向路径的实体属性信息序列集合所有补全样本的所有反向路径的实体属性信息序列集合所有补全样本的所有反向路径的实体类型信息序列集合所有补全样本的所有反向路径的实体类型信息序列集合且u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
构成所有补全样本的数据集合。转2.4。
[0298]
2.4将步骤2.2得到的s
*
、输出给事实预测网络作为q组查询关系的训练样本的数据集合,将步骤2.2得到的y
*
输出给事实预测网络作为q组查询关系的训练样本的标签集合,将步骤2.2得到的s
#
、输出给事实预测网络作为q组查询关系的验证样本的数据集合,将步骤2.2得到的y
#
输出给事实预测网络作为q组查询关系的验证样本的标签集合,将步骤2.3得到的u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
输出
给事实预测网络作为q组查询关系的补全样本的数据集合;并将补全样本的数据集合输出给事实补全模块。
[0299]
第三步:采用从数据预处理模块接收的q组查询关系的训练样本的数据集合、训练样本的标签集合、验证样本的数据集合、验证样本的标签集合对事实预测网络进行训练和验证,获取q个事实预测网络的权重参数(注意:不同的查询关系为不同的子任务,训练得到不同的事实预测网络权重参数)。
[0300]
具体方法如下:
[0301]
3.1令q=1;
[0302]
3.2如果q≤q,则转步骤3.3,否则说明所有查询关系的事实预测网络均已训练结束,得到了q个训练好的事实预测网络,即转步骤3.8。
[0303]
3.3初始化查询关系r
q
对应的事实预测网络的权重参数,方法为:
[0304]
3.3.1初始化嵌入矩阵的权重。首先将关系、实体的属性、实体的类型分别对应的3个嵌入矩阵w
r
、w
a
、w
l
随机初始化为遵循标准正态分布的50维的向量,即各个嵌入矩阵的维度分别为:关系总数目|r|
×
50、实体属性的总数目|a|
×
50、实体类型的总数目|l|
×
50。虽然本发明所述的实体属性实际上属于知识图谱中的关系(即集合a=r),但是其作为对实体语义信息的刻画,应该具有与路径上的关系不同的含义,因此实体属性的嵌入和关系的嵌入使用不同的嵌入矩阵。
[0305]
3.3.2设置lstm网络的参数。lstm
r
、lstm
a
和lstm
l
网络的隐藏单元的维度均为150维,且lstm
r
的隐藏单元和记忆单元均使用全零初始化。
[0306]
3.3.3初始化全连接层的权重矩阵和偏置向量的权重。每个全连接层均包含一个权重矩阵和一个偏置向量,权重矩阵的维度为全连接层的输出维度
×
全连接层的输入维度,偏置向量的维度为全连接层的输出维度。下面介绍全连接层的输入维度和输出维度,以确定全连接层对应的权重矩阵和偏置向量的维度。实体属性注意力网络中全连接层的输入维度分别为200,150,50,50,输出维度分别为150,50,50,1;实体类型注意力网络中全连接层的输入维度分别为200,150,50,50,输出维度分别为150,50,50,1;实体序列编码网络中全连接层50,输出维度分别为150,50,50,1;实体序列编码网络中全连接层的输入维度均为150,输出维度均为150维。路径编码器中全连接层f
p
,f
′
p
,和的输入维度分别为300,300,100,100,输出维度分别为100,100,1,1。预测器中全连接层f1,f2,f3,f4的输入维度分别为300,300,600,300,输出维度分别为300,300,300,1。
[0307]
3.4设置事实预测网络的训练参数:使用adam优化算法进行网络的优化,并使用默认参数(学习率learningrate=0.001,一阶矩估计的指数衰减率β1=0.9,二阶矩估计的指数衰减率β2=0.999,防止除以零的最小值参数∈=1e
‑8),批数据尺寸batchsize=16。
[0308]
3.5从s
*
、y
*
、中取出关于查询关系r
q
的训练数据s
q*
、y
q*
、从s
#
、y
#
、中取出关于查询关系r
q
的验证数据s
q#
、y
q#
、
[0309]
3.6迭代计算事实预测网络输出的预测概率与真实标签之间的差距,最小化损失并更新网络的参数,直到满足迭代次数要求,得到权重参数。具体方法如下:
[0310]
3.6.1令训练迭代参数epoch=1,令事实预测网络对查询关系r
q
的验证数据进行预测的平均精确度(averageprecision)的值ap
q#
=0;初始化迭代阈值epochnum,epochnum是[1,30]内的整数;
[0311]
3.6.2如果epoch≤迭代阈值epochnum,转3.6.2.1对查询关系r
q
的事实预测网络进行新一次的迭代训练,否则说明查询关系r
q
的事实预测网络已经满足迭代次数要求,训练结束,转3.7。
[0312]
3.6.2.1令批处理次数b=1,令已训练样本数目processednum=0;
[0313]
3.6.2.2如果转3.6.2.2.1使用s
q*
中第b个batch的训练数据对进行训练,其中|s
q*
|为训练样本集合s
q*
的样本数目,否则说明s
q*
中的所有训练样本已经参与过计算,该次训练迭代结束,转3.6.2.3计算在验证数据s
q#
上的预测结果;
[0314]
3.6.2.2.1事实预测网络的嵌入层从s
q*
中读取c个样本作为第b个batch的训练数据,即一个批次的训练数据,记为样本训练批次集合s
q*,b
={s1,
…
,s
c
,
…
,s
c
},1≤c≤c,其中c=min(batchsize,|s
q*
|
‑
processednum),表示取batchsize和|s
q*
|
‑
processednum中的最小值。从y
q*
、中取出与s
q*,b
的这c个样本对应的数据,分别记为标签训练批次集合y
q*,b
={y1,
…
,y
c
,
…
,y
c
},正向路径关系序列训练批次集合},正向路径关系序列训练批次集合反向路径关系序列训练批次集合正向路径实体属性信息序列训练批次集合和正向路径实体类型信息序列训练批次集合反向路径实体属性信息序列训练批次集合反向路径实体属性信息序列训练批次集合和反向路径实体类型信息序列训练批次集合
[0315]
3.6.2.2.2采用事实预测网络预测方法f
predict
,对第b个batch的数据,对第b个batch的数据和查询关系r
q
、查询关系的反关系r
′
q
进行计算,得到第b个batch的数据的预测概率集合其中是该批次数据中样本s
c
的预测概率,具体为:
[0316]
3.6.2.2.2.1事实预测网络的嵌入层读取r
q
、r
′
q
,以及使用关系的嵌入矩阵w
r
、实体属性的嵌入矩阵w
a
、实体类型的嵌入矩阵w
l
分别将数据中的关系、实体属性、实体类型映射为各自的向量表示,得到r
q
、r
′
q
、、分别对应的向量形式(即批次数据的查询关系的嵌入反向查询关系的嵌入正向路径的关系序列的嵌入反向路径的关系序列的嵌入正向路径的实体属性序列的嵌入正向路径的实体类型序列的嵌入反向路径的实体属
性序列的嵌入反向路径的实体类型序列的嵌入),将发送给关系编码器和实体编码器。
[0317]
3.6.2.2.2.2关系编码器提取路径的关系特征。关系编码器从嵌入层接收和计算该批次数据的所有正向路径的关系表示和所有反向路径的关系表示并传给实体编码器和路径编码器。正向路径的关系表示的获取与反向路径的关系表示的获取方式相同,方法是:
[0318]
3.6.2.2.2.2.1将(维度为cn
×
m
×
50,即cn条正向路径的关系序列的嵌入,其中每条正向路径的关系序列的嵌入维度为m
×
50)作为关系编码器中lstm
r
的一次输入,并使用lstm
r
输出的最后的隐状态,记为(维度为cn
×
150),作为这cn条正向路径的关系表示(每条正向路径的关系表示为150维)。
[0319]
3.6.2.2.2.2.2将(维度为cn
×
m
×
50,即cn条反向路径的关系序列的嵌入,其中每条反向路径的关系序列的嵌入维度为m
×
50)作为关系编码器中lstm
r
的一次输入,并使用lstm
r
输出的最后的隐状态,记为(维度为cn
×
150),作为这cn条反向路径的关系表示(每条反向路径的关系表示为150维)。
[0320]
3.6.2.2.2.2.3将该批次数据的所有正向路径的关系表示和所有反向路径的关系表示输出给实体编码器和路径编码器。
[0321]
3.6.2.2.2.3实体编码器提取每条路径的实体特征。实体编码器从嵌入层接收3.6.2.2.2.3实体编码器提取每条路径的实体特征。实体编码器从嵌入层接收从关系编码器接收和计算所有正向路径的实体表示和所有反向路径的实体表示,并传给路径编码器。正向路径的实体表示的获取与反向路径的实体表示的获取方式相同,具体的过程为:
[0322]
3.6.2.2.2.3.1实体序列编码网络对正向路径的实体属性序列嵌入和正向路径的实体类型序列嵌入进行编码,由于属性和类型属于两种信息,因此使用两个长短时记忆循环网络(即lstm
a
和lstm
l
)分别进行编码,来捕获正向路径上实体序列的属性表示和类型表示,具体为:
[0323]
3.6.2.2.2.3.1.1使用正向路径的关系表示对lstm
a
和lstm
l
进行初始化:
[0324]
3.6.2.2.2.3.1.1.1将输入到全连接层得到lstm
a
的第一隐藏状态将输入到全连接层得到lstm
a
的第一细胞状态
[0325]
3.6.2.2.2.3.1.1.2将输入到全连接层得到lstm
l
的第一隐藏状态将输入到全连接层得到lstm
l
的第一细胞状态
[0326]
3.6.2.2.2.3.1.2令t=1。
[0327]
3.6.2.2.2.3.1.3如果1≤t≤m+1,则将t、和传给实体画像注意力网络,转第3.6.2.2.2.3.1.4步聚合数据中所有正向路径上第t步实体的属性信息和类型信息;否则
说明数据中所有正向路径上实体的属性信息和类型信息已经聚合,转3.6.2.2.2.3.1.8。
[0328]
3.6.2.2.2.3.1.4实体画像注意力网络(分为实体属性注意力网络和实体类型注意力网络)对批次数据的所有正向路径中的第t步实体的全部属性或全部类型的嵌入进行聚合,作为对实体的语义信息的刻画。具体的计算过程为:
[0329]
3.6.2.2.2.3.1.4.1从(维度为(c*n)
×
(m+1)
×
|a
t
|
×
50)中取出批数据中所有正向路径的第t步实体的属性嵌入,记为(维度为(c*n)
×
|a
t
|
×
50);
[0330]
3.6.2.2.2.3.1.4.2将和级联,将级联后的和经过全连接层得到指导第t步属性注意力的引导变量
[0331]
3.6.2.2.2.3.1.4.3实体属性注意力网络将批数据中所有正向路径的第t步实体的属性嵌入进行聚合,方法为:
[0332]
3.6.2.2.2.3.1.4.3.1令v
t
=1;
[0333]
3.6.2.2.2.3.1.4.3.2若v
t
≤|a
t
|,转3.6.2.2.2.3.1.4.3.3获取数据中所有正向路径上第t步实体的第v
t
个属性的权重,否则说明数据中所有正向路径上第t步实体的每个属性的权重均已经获取,转3.6.2.2.2.3.1.4.3.6;
[0334]
3.6.2.2.2.3.1.4.3.3将中批数据所有正向路径的第t个实体的第v
t
个属性的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的属性嵌入将输入到全连接层得到属性引导第二变量
[0335]
3.6.2.2.2.3.1.4.3.4将和相加,将相加后的和经过relu函数激活后输入到全连接层得到批数据所有正向路径中第t步实体的第v
t
个属性的权重
[0336]
3.6.2.2.2.3.1.4.3.5令v
t
=v
t
+1,转3.6.2.2.2.3.1.4.3.2;
[0337]
3.6.2.2.2.3.1.4.3.6将权重进行归一化,得到归一化后批数据所有正向路径第t步实体的所有属性的权重集合
[0338]
3.6.2.2.2.3.1.4.3.7使用聚合批数据所有正向路径第t步实体的所有属性的表示,得到聚合后的批数据所有正向路径第t步实体的属性表示径第t步实体的所有属性的表示,得到聚合后的批数据所有正向路径第t步实体的属性表示即将(维度为(c*n)
×
|a
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.1.4.4;
[0339]
3.6.2.2.2.3.1.4.4从(维度为(c*n)
×
(m+1)
×
|l
t
|
×
50)中取出批数据中所有正向路径的第t步实体的类型嵌入,记为(维度为(c*n)
×
|l
t
|
×
50);
[0340]
3.6.2.2.2.3.1.4.5将和级联,将级联后的和经过全连接层得
到指导第t步类型注意力的引导变量
[0341]
3.6.2.2.2.3.1.4.6实体类型注意力网络将批数据中所有正向路径的第t步实体的类型嵌入进行聚合,方法为:
[0342]
3.6.2.2.2.3.1.4.6.1令o
t
=1;
[0343]
3.6.2.2.2.3.1.4.6.2若o
t
≤|l
t
|,转3.6.2.2.2.3.1.4.6.3获取数据中所有正向路径上第t步实体的第o
t
个类型的权重,否则说明数据中所有正向路径上第t步实体的每个类型的权重均已经获取,转3.6.2.2.2.3.1.4.6.6;
[0344]
3.6.2.2.2.3.1.4.6.3将中批数据所有正向路径的第t个实体的第o
t
个类型的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的类型嵌入将输入到全连接层得到类型引导第二变量
[0345]
3.6.2.2.2.3.1.4.6.4将和相加,将相加后的和经过relu激活后输入全连接层得到批数据所有正向路径中第t步实体第o
t
个类型的权重
[0346]
3.6.2.2.2.3.1.4.6.5令o
t
=o
t
+1,转3.6.2.2.2.3.1.4.6.2;
[0347]
3.6.2.2.2.3.1.4.6.6将权重进行归一化,得到归一化后批数据中所有正向路径第t步实体的所有类型的权重集合
[0348]
3.6.2.2.2.3.1.4.6.7使用聚合批数据所有正向路径第t步实体的所有类型的表示,得到聚合后的批数据所有正向路径第t步实体的类型表示第t步实体的所有类型的表示,得到聚合后的批数据所有正向路径第t步实体的类型表示即(维度为(c*n)
×
|l
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.1.5;
[0349]
3.6.2.2.2.3.1.5将作为lstm
a
第t步的输入,得到lstm
a
第t步的输出维度为(c*n)
×
150;
[0350]
3.6.2.2.2.3.1.6将作为lstm
l
第t步的输入,得到lstm
l
第t步的输出维度为(c*n)
×
150;
[0351]
3.6.2.2.2.3.1.7令t=t+1,转3.6.2.2.2.3.1.3;
[0352]
3.6.2.2.2.3.1.8将和相加(即分别为t=m+1时lstm
a
和lstm
l
的输出),得到批数据中所有正向路径的实体表示维度为(c*n)
×
150。转3.6.2.2.2.3.2;
[0353]
3.6.2.2.2.3.2实体序列编码网络对反向路径的实体属性序列嵌入和反向路径的实体类型序列嵌入进行编码,分别使用lstm
a
和lstm
l
来捕获反向路径上实体序列的属性表示和类型表示,方法是:
[0354]
3.6.2.2.2.3.2.1使用反向路径的关系表示对lstm
a
和lstm
l
进行初始化:
[0355]
3.6.2.2.2.3.2.1.1将输入到全连接层得到lstm
a
的第二隐藏状态将输入到全连接层得到lstm
a
的第二细胞状态
[0356]
3.6.2.2.2.3.2.1.2将输入到全连接层得到lstm
l
的第二隐藏状态将输入到全连接层得到lstm
l
的第二细胞状态
[0357]
3.6.2.2.2.3.2.2令t=1。
[0358]
3.6.2.2.2.3.2.3如果1≤t≤m+1,将t、和传给实体画像注意力网络,转第3.6.2.2.2.3.2.4步聚合数据中所有反向路径上第t步实体的属性信息和类型信息;否则说明数据中所有反向路径上实体的属性信息和类型信息已经聚合,转3.6.2.2.2.3.2.8。
[0359]
3.6.2.2.2.3.2.4实体画像注意力网络对批次数据的所有反向路径中的第t步实体的全部属性或全部类型的嵌入进行聚合,作为对实体的语义信息的刻画。具体过程为:
[0360]
3.6.2.2.2.3.2.4.1从(维度为(c*n)
×
(m+1)
×
|a
t
|
×
50)中取出批数据中所有反向路径的第t步实体的属性嵌入,记为(维度为(c*n)
×
|a
t
|
×
50);
[0361]
3.6.2.2.2.3.2.4.2将和级联,将级联后的和经过全连接层得到指导第t步属性注意力的引导变量
[0362]
3.6.2.2.2.3.2.4.3实体属性注意力网络将批数据中所有反向路径的第t步实体的属性嵌入进行聚合,方法为:
[0363]
3.6.2.2.2.3.2.4.3.1令v
t
=1;
[0364]
3.6.2.2.2.3.2.4.3.2若v
t
≤|a
t
|,转3.6.2.2.2.3.2.4.3.3获取数据中所有反向路径上第t步实体的第v
t
个属性的权重,否则说明数据中所有反向路径上第t步实体的每个属性的权重均已经获取,转3.6.2.2.2.3.2.4.3.6;
[0365]
3.6.2.2.2.3.2.4.3.3将中批数据所有反向路径的第t个实体的第v
t
个属性的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的属性嵌入将输入到全连接层得到属性引导第二变量
[0366]
3.6.2.2.2.3.2.4.3.4将和相加,将相加后的和经过relu激活后输入全连接层得到批数据所有反向路径中第t步实体第v
t
个属性的权重
[0367]
3.6.2.2.2.3.2.4.3.5令v
t
=v
t
+1,转3.6.2.2.2.3.2.4.3.2;
[0368]
3.6.2.2.2.3.2.4.3.6将权重进行归一化,得到归一化后批数据所有反向路径第t步实体的所有属性的权重集合
[0369]
3.6.2.2.2.3.2.4.3.7使用聚合批数据所有反向路径第t步实体的所有属性的表示,得到聚合后的批数据所有反向路径第t步实体的属性表示步实体的所有属性的表示,得到聚合后的批数据所有反向路径第t步实体的属性表示即将(维度为(c*n)
×
|a
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.2.4.4;
[0370]
3.6.2.2.2.3.2.4.4从(维度为(c*n)
×
(m+1)
×
|l
t
|
×
50)中取出批数据中所有反向路径的第t步实体的类型嵌入,记为(维度为(c*n)
×
|l
t
|
×
50);
[0371]
3.6.2.2.2.3.2.4.5将和级联,将级联后的和经过全连接层得到指导第t步类型注意力的引导向量
[0372]
3.6.2.2.2.3.2.4.6实体类型注意力网络将批数据中所有反向路径的第t步实体的类型嵌入进行聚合,方法为:
[0373]
3.6.2.2.2.3.2.4.6.1令o
t
=1;
[0374]
3.6.2.2.2.3.2.4.6.2若o
t
≤|l
t
|,转3.6.2.2.2.3.2.4.6.3获取数据中所有反向路径上第t步实体的第o
t
个类型的权重,否则说明数据中所有反向路径上第t步实体的每个类型的权重均已经获取,转3.6.2.2.2.3.2.4.6.6;
[0375]
3.6.2.2.2.3.2.4.6.3将中批数据中所有反向路径的第t个实体的第o
t
个类型的嵌入记为(维度为(c*n)
×
50),将输入到全连接层得到变换后的类型嵌入将输入到全连接层得到类型引导第二变量
[0376]
3.6.2.2.2.3.2.4.6.4将和相加,将相加后的和经过relu激活后输入全连接层得到批数据所有反向路径中第t步实体第o
t
个类型的权重
[0377]
3.6.2.2.2.3.2.4.6.5令o
t
=o
t
+1,转3.6.2.2.2.3.2.4.6.2;
[0378]
3.6.2.2.2.3.2.4.6.6将权重进行归一化,得到归一化后批数据中所有反向路径第t步实体的所有类型的权重集合
[0379]
3.6.2.2.2.3.2.4.6.7使用聚合批数据所有反向路径第t步实体的所有类型的表示,得到聚合后的批数据所有反向路径第t步实体的类型表示径第t步实体的所有类型的表示,得到聚合后的批数据所有反向路径第t步实体的类型表示即(维度为(c*n)
×
|l
t
|
×
50)聚合后得到(维度为(c*n)
×
50),转3.6.2.2.2.3.2.5;
[0380]
3.6.2.2.2.3.2.5将作为lstm
a
第t步的输入,得到lstm
a
第t步的输出维度为(c*n)
×
150;
[0381]
3.6.2.2.2.3.2.6将作为lstm
l
第t步的输入,得到lstm
l
第t步的输出维度为(c*n)
×
150;
[0382]
3.6.2.2.2.3.2.7令t=t+1,转3.6.2.2.2.3.2.3;
[0383]
3.6.2.2.2.3.2.8将和相加(即分别为t=m+1时lstm
a
和lstm
l
的输出),得到批数据中所有反向路径的实体表示维度为(c*n)
×
150,转3.6.2.2.2.3.2.9;
[0384]
3.6.2.2.2.3.2.9将3.6.2.2.2.3.1.8中批数据所有正向路径的实体表示和3.6.2.2.2.3.2.8中批数据所有反向路径的实体表示的传给路径编码器,转3.6.2.2.2.4。
[0385]
3.6.2.2.2.4路径编码器从关系编码器接收和从实体编码器接收和分别使用正向路径注意力网络和反向路径注意力网络计算批数据中所有样本的正向路径的表示和反向路径的表示,具体步骤为:
[0386]
3.6.2.2.2.4.1将批数据的所有正向路径的关系表示和所有正向路径的实体表示级联,得到批数据的所有正向路径的路径表示,记为维度为(c*n)
×
300,批数据里每条路径的维度为300;
[0387]
3.6.2.2.2.4.2将批数据的所有反向路径的关系表示和所有反向路径的实体表示级联,得到批数据的所有反向路径的路径表示,记为维度为(c*n)
×
300,批数据里每条路径的维度为300;
[0388]
3.6.2.2.2.4.3使用正向路径注意力网络聚合中所有样本的n条正向路径的表示,方法为:
[0389]
3.6.2.2.2.4.3.1令n=1;
[0390]
3.6.2.2.2.4.3.2若n≤n,转3.6.2.2.2.4.3.3获取数据中所有样本的第n条正向路径的权重,否则说明数据中所有样本的每条正向路径的权重均已经获取,转3.6.2.2.2.4.3.5;
[0391]
3.6.2.2.2.4.3.3将中所有样本的第n条路径的表示记为(维度为c
×
300)。将经过f
p
和两层全连接层(f
p
之后会经过relu函数激活)后得到的值作为第n条正向路径的权重
[0392]
3.6.2.2.2.4.3.4令n=n+1,转3.6.2.2.2.4.3.2;
[0393]
3.6.2.2.2.4.3.5将批数据中所有样本的所有正向路径的权重进行归一化,得到归一化后批数据中所有样本的所有正向路径的权重
[0394]
3.6.2.2.2.4.3.6使用聚合批数据中样本的正向路径的表
示,得到该批数据所有样本的正向路径表示即(维度为(c*n)
×
300)聚合后得到(维度为c
×
300),转3.6.2.2.2.4.4;
[0395]
3.6.2.2.2.4.4使用反向路径注意力网络聚合中所有样本的n条反向路径的表示,方法为:
[0396]
3.6.2.2.2.4.4.1令n=1;
[0397]
3.6.2.2.2.4.4.2若n≤n,转3.6.2.2.2.4.4.3获取数据中所有样本的第n条反向路径的权重,否则说明数据中所有样本的每条反向路径的权重均已经获取,转3.6.2.2.2.4.4.5;
[0398]
3.6.2.2.2.4.4.3将中所有样本的第n条路径的表示记为(维度为c
×
300)。将经过f
′
p
和两层全连接层(f
′
p
之后会经过relu函数激活)后得到的值作为第n条反向路径的权重
[0399]
3.6.2.2.2.4.4.4令n=n+1,转3.6.2.2.2.4.4.2;
[0400]
3.6.2.2.2.4.4.5将批数据中所有样本的所有反向路径的权重进行归一化,得到归一化后批数据中所有样本的所有反向路径的权重
[0401]
3.6.2.2.2.4.4.6使用聚合批数据中样本的反向路径的表示,得到该批数据所有样本的反向路径表示即(维度为(c*n)
×
300)聚合后得到(维度为c
×
300),转3.6.2.2.2.4.5;
[0402]
3.6.2.2.2.4.5将和传输给预测器,转3.6.2.2.2.5;
[0403]
3.6.2.2.2.5预测器从路径编码器接收和计算该批数据中所有样本的预测概率,方法为:
[0404]
3.6.2.2.2.5.1将输入到全连接层f1中,将输入到全连接层f2中,然后将全连接层f1和f2的输出进行拼接,得到该批数据中所有样本的路径表示维度为c
×
600,其中该批数据中每个样本的路径表示维度为600。
[0405]
3.6.2.2.2.5.2将输入到全连接层f3中,然后将f3的输出经过relu函数激活后输入到全连接层f4中,得到所有样本的路径的新表示
[0406]
3.6.2.2.2.5.3将输入sigmoid函数中得到该批次所有数据的预测概率集合有数据的预测概率集合是该批次数据中样本s
c
的预测概率,的预测概率,转3.6.2.2.3。
[0407]
3.6.2.2.3使用步骤3.6.2.2.1得到的标签集合y
q*,b
和步骤3.6.2.2.2.5.3事实预
测网络的预测概率集合计算该批次数据s
q*,b
的损失值loss。方法如下式,其中表示该批次数据中查询关系r
q
的正样本集合,表示该批次数据中查询关系r
q
的正样本集合和负样本集合,如果s
q*,b
中的样本s
c
的标签y
c
=1,则样本否则否则
[0408][0409]
3.6.2.2.4使用adam优化算法对损失值loss最小化,以反向传播训练网络参数,事实预测网络中的参数(三个嵌入矩阵w
r
、w
a
、w
l
,3个lstm网络(lstm
r
、lstm
a
和lstm
l
)和20个全连接层的权重矩阵和偏置向量)都得到一次更新。
[0410]
3.6.2.2.5令processednum=processednum+c,b=b+1,转3.6.2.2。
[0411]
3.6.2.3令批处理次数b=1,令已预测的验证样本数目predictednum=0,令验证样本的预测概率集合
[0412]
3.6.2.4如果转3.6.2.4.1对s
q#
中第b个batch的验证数据进行预测,其中|s
q#
|为验证样本集合s
q#
的样本数目,否则说明已经对s
q#
中的所有验证样本进行预测,转3.6.2.5;
[0413]
3.6.2.4.1事实预测网络的嵌入层从步骤3.5中得到的s
q#
中读取c
#
个样本作为第b个batch的验证数据,即一个批次的验证数据,记为样本验证批次集合1≤c
#
≤c
#
,其中c
#
=min(batchsize,|s
q#
|
‑
predictednum)。从步骤3.5得到的y
q#
、、中取出与s
q#,b
的这c
#
个样本对应的数据,分别记为标签验证批次集合正向路径关系序列验证批次集合反向路径关系序列验证批次集合正向路径实体属性信息序列验证批次集合和正向路径实体类型信息序列验证批次集合息序列验证批次集合反向路径实体属性信息序列验证批次集合和反向路径实体类型信息序列验证批次集合
[0414]
3.6.2.4.2采用步骤3.6.2.2.2中所述的事实预测网络预测方法f
predict
,对第b个batch的验证数据和查询关系r
q
、查询关系的反关系r
′
q
进行计算,得到第b个batch的验证数据的预测概率集合即其中是该批次数据中样本的预测概率。将加入中,即令
[0415]
3.6.2.4.3令predictednum=predictednum+c
#
,b=b+1,转3.6.2.4。
[0416]
3.6.2.5使用验证数据集合s
q#
的标签集合y
q#
和事实预测网络的预测概率集合
计算事实预测网络对验证数据进行预测的平均精确度,记为若则令则令并保存事实预测网络的参数,转3.6.2.6;若则不用保存事实预测网络的参数,直接转3.6.2.6。
[0417]
3.6.2.6令epoch=epoch+1,转3.6.2;
[0418]
3.7令q=q+1,转3.2;
[0419]
3.8计算该基于路径的知识图谱补全系统进行事实预测的平均精度均值map,3.8计算该基于路径的知识图谱补全系统进行事实预测的平均精度均值map,转第四步。
[0420]
第四步:事实补全模块对用户输入的需要补全的知识图谱进行补全,如图4所示,具体方法是:
[0421]
4.1事实补全模块从数据预处理模块接收补全样本的数据集合u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
,令补全样本集合u对应的所有补全样本的预测概率集合
[0422]
4.2令q=1;
[0423]
4.3如果q≤q,转4.3.1预测查询关系r
q
下所有补全样本属于事实的概率,否则说明所有查询关系下的补全样本均已预测,转4.4。
[0424]
4.3.1从r
q
中取出查询关系r
q
,根据r
q
选择第三步中训练好的事实预测网络
[0425]
4.3.2从u、u
r
、u
′
r
、u
a
、u
l
、u
′
a
、u
′
l
中中取出关于查询关系r
q
的补全数据u
q
、u
′
qr
、u
′
qa
、u
′
ql
。
[0426]
4.3.3令u
q
对应的补全样本的预测概率集合为
[0427]
4.3.4使用训练好的事实预测网络预测u
q
中所有样本属于事实的概率,得到u
q
中所有样本属于事实的预测概率集合z
q
,具体地:
[0428]
4.3.4.1令批处理次数b=1,令已预测补全样本的数目predictednum=0;
[0429]
4.3.4.2如果转4.3.4.2.1对u
q
中第b个batch的补全数据进行预测,否则说明已经对u
q
中的所有补全样本进行预测,转4.3.5;
[0430]
4.3.4.2.1事实预测网络的嵌入层从u
q
读取c
u
个样本作为第b个batch的补全数据,即一个批次的补全数据,记为样本补全批次集合1≤c
u
≤c
u
,其中c
u
=min(batchsize,|u
q
|
‑
predictednum)。从中取出与u
q,b
的这c
u
个样本对应的数据,分别记为正向路径关系序列补全批次集合反向路径关系序列补全批次集合正向路径实体属性信息序列补全批次集合和正向路径实体类型信息序列补全批次集合息序列补全批次集合反向路径实体属性信息序列补全批次集合和反向路径实体类型信息序列补全批次集合
[0431]
4.3.4.2.2采用步骤3.6.2.2.2中所述的事实预测网络预测方法f
predict
,对第b个batch的补全数据和查询关系r
q
、查询关系的反关系r
q
′
进行计算,得到第b个batch经过训练好的事实预测网络预测得到的补全数据的预测概率集合率集合其中是该批次数据中样本的预测概率。
[0432]
4.3.4.2.3事实补全模块从事实预测网络接收批次数据的预测概率集合将加入到r
q
下的补全样本的预测概率集合z
q
中,即令
[0433]
4.3.4.2.4令predictednum=predictednum+c
u
,b=b+1,转4.3.4.2。
[0434]
4.3.5将z
q
作为元素加入到所有补全样本的预测概率集合中,即z=z∪{z
q
};
[0435]
4.3.6令q=q+1,转4.3;
[0436]
4.4根据所有补全样本集合u(u={u1,
…
,u
q
,
…
,u
q
})的预测概率集合z(z={z1,
…
,z
q
,
…
,z
q
}),判断样本是否是需要补全的事实,得到补全后的知识图谱,具体地:
[0437]
4.4.1将补全后的知识图谱的事实集合记为f
new
,令f
new
=f;
[0438]
4.4.2设置阈值δ(0.5≤δ≤1),令q=1;
[0439]
4.4.3如果q≤q,则转4.4.4补全查询关系r
q
下的缺失事实,否则说明所有查询关系下的缺失事实均已补全,转4.5。
[0440]
4.4.4令w=1;
[0441]
4.4.5如果w≤|u
q
|,则转4.4.6判断补全样本u
w
是否为缺失事实,否则说明查询关系r
q
下的缺失事实均已补全,转4.4.8。
[0442]
4.4.6u
q
中第w个样本u
w
代表三元组u
w
的预测概率为z
q
中的第w个预测概率z
w
,若预测概率z
w
≥δ,则在用户提供的知识图谱中将实体和使用r
q
连接,即将添加到事实集合f
new
中,
[0443]
4.4.7令w=w+1,转4.4.5;
[0444]
4.4.8令q=q+1,转4.4.3;
[0445]
4.5将用户提供的知识图谱中的事实集合f更新为f
new
,即完成了对用户提供的知识图谱的补全。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1