一种检索式个性化对话方法与系统
1.本发明涉及人工智能领域,尤其涉及一种检索式个性化对话方法与系统。
背景技术:
2.不论是在工业界还是学术界,开放领域的对话机器人是近年来自然语言处理领域的一个热门话题。一般来说,构建开放域对话机器人有两种途径:检索式和生成式。前者通常通过检索引擎,召回几个回答候选者的,然后从这些候选者中选择适当的响应。而后者直接利用诸如编码器-解码器的模型来生成响应文本。检索式聊天机器人在诸多工业界产品中有广泛应用,例如微软的小冰和阿里小蜜。
3.尽管目前的检索式开放领域对话机器人有很多不错的进展,但在这个行业的发展中仍然受到一些问题的制约。在这些众多的制约问题中,不能维持一致的人格是一个广为提及的。这是因为在用户与机器人的互动过程中,如果机器人不能维持一个一致的人格,会给用户带来很强的不可预知感和不信任感,这直接降低了用户体验。
4.因此,让聊天机器人保持一致的人格成为了一项至关重要的研究任务。在以往的研究中,很多研究者提出了很多方法来让聊天机器人保持一致的人格。例如,一些早期的工作(例如,speaker model)尝试使用可训练的用户向量来为用户的个性化特征进行建模。而近期的一些研究者尝试使用预先定义好的人格描述来让模型学习到用户的个性化特征,这些定义好的人格一般有两种形式:1.几个描述用户喜好的句子;2.用户个性化属性的键值对。
5.当前诸多对用户个性化进行建模的方式存在以下问题:
6.1.虽然我们知道在用户的对话历史中存在这大量的用户个性化信息,但是当前的方法都没有直接从用户的对话历史中去对用户个性化信息进行建模;
7.2.使用基于用户向量的方法只是对每一个用户训练了一个用户向量,虽然这个向量一定程度上能帮助模型区分用户,但其中是否包含用户的个性化信息很难解释;
8.3.使用基于预定义个性化的方法需要大规模的对用户个性数据的标注,这样的数据标注需要大量的人力,成本非常高。另外,在真实的应用场景中,用户可能不愿意填写详细的个性化信息;
9.4.用户的个性化信息可能随着时间而变化,不论是基于用户向量的方式还是基于预定义个性化描述的方法都很难支持用户个性化信息的更新。
技术实现要素:
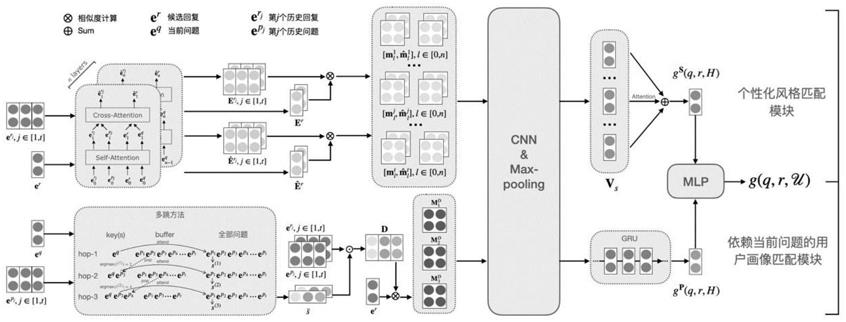
10.为此,本发明首先提出一种检索式个性化对话方法,首先构建个性化风格匹配模块,使用用户的历史回复来捕获个性化语言特征,对于所有历史回答r= {rj},j∈[1,t],通过表示层、匹配层、聚合层三个计算步骤,获得风格匹配特征向量gs(q,r,h);然后,设计依赖当前问题的用户画像匹配模块,通过构建依赖当前问题的用户画像d、在回答候选者和依赖当前问题的用户画像之间进行匹配、聚合匹配特征三个步骤,实现从对话历史记录h自
动生成依赖当前问题的用户画像d,并获得所述用户画像匹配向量g
p
(q,r,h)来衡量用户画像和回答候选者之间的一致性;最后通过融合模块将所述风格匹配特征向量gs(q,r,h)和所述用户画像匹配向量g
p
(q,r,h)组合起来以计算最终匹配得分g(q,r,u)。最终将匹配得分最高的回复作为最终回复返回。
[0011]
所述表示层利用n个注意力模块,获得当前回答候选r和每个历史回复rj,j∈ [1,t]的多粒度表示和e={e0,
…
,en},对于任意第j个历史回复rj,首先通过预训练词向量来初始化单词表示然后,通过将词向量输入n个注意力来获得回复rj的深层的上下文表示形式:
[0012][0013][0014]
其中e
pj
以与e
rj
相同的方式获得,最终获得n+1个交叉注意的表示形式相同的方式获得,最终获得n+1个交叉注意的表示形式对于响应候选r,以相同的方式先通过预训练词向量获得初始化单词表示,再将其输入n个注意力来获得回复rj的深层的上下文表示形式下文表示形式和
[0015]
所述匹配层对于第j个响应rj,计算相似性矩阵和
[0016]
l∈[0,n],
[0017]
其中d是词向量的维度,对于t个历史回复r={r1,
…rt
},可以得到多个相似性矩阵和之后,将多个相似性矩阵连接起来以形成t个历史回复与回复候选者之间的最终匹配矩阵:
[0018][0019]
这里f
stack
(
·
)r指的是在一个新的维度上连接向量,中的l是文本序列的最大长度。
[0020]
所述聚合层使用2d-cnn从堆栈的匹配矩阵ms中提取匹配特征,然后将提取的特征向量使用多层感知器线性映射到较低维度,由此获得匹配特征矩阵向量使用多层感知器线性映射到较低维度,由此获得匹配特征矩阵接下来使用自注意力机制得到当前矩阵与每一个历史回复的特征矩阵的权重,并将它们加权相加在一起,得到用于衡量候选回答的风格一致性的风格匹配特征向量gs(q,r,h)。
[0021]
所述构建依赖当前问题的用户画像d步骤计算当前问题q与历史问题p= {p1,
…
,p
t
}的相关性,以获得相关性向量s,所述相关性向量s由词级相关性向量 s1和句子级相关性向量s2组成,给定用户的t个历史帖子p={pj},j∈[1,t]和当前查询q,首先通过使用预训练词向量来初始化其向量表示形式e
p
={e
p1
,
…ept
}和 eq,然后,将这些表示形式输入一个注意力模块中,以增强它们的序列语义依赖性:
j∈[1,t],对于t个历史问题,有将加到
[0022]
在词级别,对于t个历史回复,获得它的匹配矩阵在词级别,对于t个历史回复,获得它的匹配矩阵这里和都是可训练的参数,用softmax函数来获得词级别的相关度得分s1;
[0023]
在句子级别,首先对词维度进行均值池化以获得句子表示形式,使用余弦相似度来计算句级别的相关度得分:
[0024][0025]
这里
[0026]
最后有合并了词级别和句级别的相关度得分:s=α
·
s1+(1-α)
·
s2,α是一个可训练的参数,其被初始化为0.5;
[0027]
进而,对于每一次计算当前问题与历史问题的相似度,把历史回复中最相似的那个问题提取出来,然后将它的向量表示与当前问题的向量表示融合得到注意力键ki,在第一次计算时,k1=eq,对于每一次计算相似度,获得相关度得分矩阵s=s(i),在k次计算后得到s={s
(1)
,
…
,s
(k)
},将这些分数加权累加:这里并给每个历史问题对应的回复赋值同样的权重,从而得到依赖当前问题的用户画像d:这里这里
[0028]
所述在回答候选者和依赖当前问题的用户画像之间进行匹配步骤中,构造三个匹配矩阵:
[0029][0030][0031][0032]
这里d是词向量的维度,和是通过使用单层注意力模块得到的融合上下文语义的向量表示:
[0033][0034][0035]
同时,和通过交叉注意力得到的向量表示:
[0036][0037]
[0038]
之后,将三个匹配矩阵连接在一起:m
p
包含了多个角度的用户个性化特征。
[0039]
所述聚合匹配特征步骤中,使用2d cnn和最大池化来从匹配特征矩阵m
p
中提取匹配特征,然后利用单层gru来捕获对话历史问答对的时序信息,最后将 gru的最终隐藏状态用作依赖当前问题的用户画像匹配向量g
p
(q,r,h)。
[0040]
所述融合模块将所述风格匹配特征向量gs(q,r,h)和所述用户画像匹配向量 g
p
(q,r,h)连接在一起获得最终的匹配向量g(q,r,u),g(q,r,u)= m(gs(q,r,h),g
p
(q,r,h)),m(
·
)是一个将两个特征匹配向量聚合起来的函数,例如,在本文中这个函数是一个多层感知机(mlp)。其中u表示这个从用户对话历史中学到的隐式用户个性化信息,并使用一个多层感知器和sigmoid激活函数来把这个匹配向量映射为匹配最终的相关性得分;
[0041]
使用交叉熵损失函数训练整个模型:
[0042][0043]
本发明所要实现的技术效果在于:
[0044]
在用户的对话历史中发现个性化信息,利用用户对话历史中的历史回复对用户的个性化语言特征,直接从用户的对话历史对用户的个性化进行建模;通过构造一个依赖于当前问题的用户个性化画像,来挖掘用户说话风格与用户喜好之间的相互关系,能够辨别模型学到的用户个性化信息的源头,能够提供一定的解释性;最终融合这两部分用户个性化信息来对候选回复进行排序,得到最合适的个性化回复。
附图说明
[0045]
图1算法整体框架;
具体实施方式
[0046]
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
[0047]
本发明提出了一种检索式个性化对话方法。由于影响用户个性化表达方式的因素有两个:(1)无论对话上下文如何,用户都具有个性化的语言风格,这种语言风格通常取决于用户的知识背景和习惯用语;(2)用户做出回复的方式还受到当前问题与用户个人喜好和观点之间的内在联系的影响。
[0048]
本发明方法分别从这两个因素对用户个性化信息进行建模,来得到一个隐式用户个性化信息表示。使用u来表示这个从用户对话历史中学到的隐式用户个性化信息表示。u由两部分组成:(1)上下文无关的用户的个性化语言风格的隐式表示;和(2)依赖于当前问题的用户个人兴趣喜好关系的隐式表示。由此,我们可以定义候选回答r和u的匹配程度为:
[0049]
g(q,r,u)=m(gs(q,r,h),g
p
(q,r,h)),
[0050]
其中gs和g
p
表示候选答案r相与两个部分的匹配得分。
[0051]
图1显示了本文方法的模型结构。具体地,我们首先构建一个个性化风格匹配模块,该模块旨在使用用户的历史回复来捕获个性化语言特征,并获得风格匹配特征向量gs(q,r,h),该匹配特征向量用于衡量候选回答的风格一致性。然后,我们设计了一个依赖当前问题的用户画像匹配模块,该模块学习与当前问题相关的用户画像,并获得匹配向量g
p
(q,r,h)来衡量用户画像和回答候选者之间的一致性。在这个模块中,用户对话历史记录中的问答对都被重新加权,其中权重是通过一种的多跳方法获得的。这两个匹配模块中,两个隐式个性化特征与当前候选回答分别进行匹配,在融合模块中,我们将两个匹配特征组合起来以计算最终匹配得分g(q,r,u)。
[0052]
个性化风格匹配模块:
[0053]
具体地,给定用户u和候选回答r,个性化风格匹配模块旨在获得风格匹配特征向量gs(q,r,h),该特征向量衡量当前回答候选r与历史回答之间的风格一致性。对于所有历史回答r={rj},j∈[1,t],个性化风格匹配模块包含以下三个步骤:
[0054]
(1)表示,(2)匹配和(3)聚合。我们将在下面详细介绍每一层。
[0055]
在表示层,我们利用n个注意力模块,来获得当前回答候选r和每个历史回复 rj,j∈[1,t]的多粒度表示和e={e0,
…
,en}。以第j个历史回复rj为例,我们首先通过预训练词向量来初始化单词表示然后,通过将词向量输入 n个注意力来获得回复rj的深层的上下文表示形式:
[0056][0057]
其中e
pj
以与e
rj
相同的方式获得。通过这种方式,我们可以获得n+1个交叉注意的表示形式其中包含历史回复和相应问题之间的上下文语境信息。对于响应候选r,我们以相同的方式获得和和
[0058]
匹配层旨在获得个性化匹配矩阵ms,该矩阵以多种粒度衡量候选答案与每个历史答案之间的语义相似性。具体来说,对于第j个响应rj,我们通过以下公式计算相似性矩阵和
[0059][0060]
其中d是词向量的维度.对于t个历史回复r={r1,
…rt
},我们可以得到和之后,我们获得多个相似性矩阵,然后将它们连接起来以形成t个历史回复与回复候选者之间的最终匹配矩阵:
[0061][0062]
这里f
stack
(
·
)r指的是在一个新的维度上连接向量.中的l是文本序列的最大长度。
[0063]
在聚合层中,我们使用2d-cnn从堆栈的匹配矩阵ms中提取匹配特征。然后将提取的特征向量使用多层感知器线性映射到较低维度。我们由此获得匹配特征矩阵我们接下来使用自注意力机制得到当前矩阵与每一个历史回复的特征矩阵的权重,并将它
们加权相加在一起,得到用于衡量候选回答的风格一致性的向量gs。
[0064]
依赖当前问题的用户画像匹配模块:
[0065]
依赖当前问题的用户画像匹配模块旨在获得匹配向量g
p
(q,r,h),该特征向量衡量回答候选r是否是当前问题q的最合适回答。具体地,我们通过三个步骤从对话历史记录h自动生成依赖当前问题的用户画像d,然后进行匹配:(1) 首先构建依赖当前问题的用户画像d;(2)然后在回答候选者和依赖当前问题的用户画像之间进行匹配;(3)最后聚合匹配特征,得到匹配向量g
p
(q,r,h)。
[0066]
为了得到用户画像d,我们计算当前问题q与历史问题p={p1,
…
,p
t
}的相关性,以获得相关性向量s,该向量衡量当前问题和每个历史问题之间的相关性。相关性向量s由词级相关性向量s1和句子级相关性向量s2组成。具体地,给定用户的t个历史帖子p={pj},j∈[1,t]和当前查询q,我们首先通过使用预训练词向量来初始化其向量表示形式e
p
={e
p1
,
…ept
}和eq。然后,我们将这些表示形式输入一个注意力模块中,以增强它们的序列语义依赖性:
[0067][0068]
对于t个历史问题,我们有我们将加到这样,
[0069]
在词级别,对于t个历史回复,我们通过以下公式获得它的匹配矩阵
[0070][0071]
这里和都是可训练的参数。我们通过提取匹配向量矩阵中最大值来获取最重要的矩阵,然后这些向量被线性映射到较低维度,我们用softmax函数来获得词级别的相关度得分s1。
[0072]
在句子级别,我们首先对词维度进行均值池化以获得句子表示形式,我们接下来使用余弦相似度来计算句级别的相关度得分:
[0073][0074]
这里我们接下来合并了词级别和句级别的相关度得分:
[0075]
s=α
·
s1+(1-α)
·
s2,
[0076]
这里的α是一个可训练的参数,其被初始化为0.5。
[0077]
为了丰富当前提问的语义信息,我们还设计了一种多跳方法来把历史问题中的相关语义信息加入当前问题。具体地,对于每一次计算当前问题与历史问题的相似度,我们都会把历史回复中最相似的那个问题提取出来,然后将它的向量表示与当前问题的向量表示融合得到注意力键ki。在第一次计算时,k1=eq。对于每一次计算相似度,我们获得相关度得分矩阵s=s(i)。这样,在k次计算后,我们得到s={s
(1)
,
…
,s
(k
)}。我们接下来将这些分数加权累加:
[0078]
[0079]
这里我们随后给每个历史问题对应的回复赋值同样的权重,从而得到依赖当前问题的用户画像d:
[0080][0081]
这里eh={(e
pj
,e
rj
)},j∈[1,t]。
[0082]
为了完备地衡量答案候选r和用户画像d之间的相关性,我们构造了三个匹配矩阵:
[0083][0084][0085][0086]
这里d是词向量的维度。和是通过使用单层注意力模块得到的融合上下文语义的向量表示:
[0087][0088][0089]
同时,和通过交叉注意力得到的向量表示:
[0090][0091][0092]
之后,我们将三个匹配矩阵连接在一起:
[0093][0094]mp
包含了多个角度的用户个性化特征。
[0095]
为了有效地聚合这些匹配特征,我们使用2d cnn和最大池化来从匹配矩阵 m
p
中提取匹配特征。然后,我们利用单层gru来捕获对话历史问答对的时序信息。我们将gru的最终隐藏状态用作依赖当前问题的用户画像匹配向量 g
p
(q,r,h)。
[0096]
融合模块:
[0097]
通过以上两个模块,我们能够获得两个匹配特征向量:(1)个性化风格匹配特征向量gs(q,r,h)和(2)依赖当前问题的用户画像匹配向量g
p
(q,r,h)。然后,我们将两个匹配向量连接在一起获得最终的匹配向量g(q,r,u)。接下来,我们使用一个多层感知器和sigmoid激活函数来把这个匹配向量映射为匹配最终的相关性得分。
[0098]
我们使用交叉熵损失函数训练整个模型。
[0099]
。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1