一种基于先验知识的人脸表情识别方法
facialexpression recognition[j].ieee access,2020,8:131988-132001.)将数据集标定过程中的投票结 果作为先验知识,将其与标签平滑损失函数结合,从而得到更符合人类直觉的预测分布。在这 个问题上,shen j(she j,hu y,shi h,et al.dive into ambiguity:latent distribution mining andpairwise uncertainty estimation for facial expression recognition[c]//proceedings of theieee/cvf conference on computer vision and pattern recognition.2021:6248-6257.)目前取得 了最好的表现,提出的方法在辅助多分支的框架帮助下,在标签维度中充分利用了潜在分布来 提升性能,而在样本维度中,通过学习语义特征之间的关系来估计样本的模糊性程度。同时表 情中的先验知识如动作单元也能作为先验知识来提升表情识别的性能。
[0006]
对于遮挡和姿态问题,往往会引入注意力模块,将注意力专注于未遮挡的部分,从而减小 遮挡对性能的影响,但是该类算法因为基于裁剪区域和裁剪块,在模型训练上需要花费大量的 时间。li y(li y,zeng j,shan s,et al.occlusion aware facial expression recognition using cnn withattention mechanism[j].ieee transactions on image processing,2018,28(5):2439-2450.)考虑到 不同的感兴趣区域,提出了基于块的注意力网络和基于全局和局部的注意力网络,前者只专注 于局部的面部块,而后者将局部表示和全局表示融合以提升性能。文献2 wang k(wang k,pengx,yang j,et al.region attention networks for pose and occlusion robust facial expressionrecognition[j].ieee transactions on image processing,2020,29:4057-4069.)提出了区域自注意 力网络,可以自适应地捕获各个区域的重要性,并且定义了区域偏差损失函数,以鼓励关注更 重要的人脸区域。
技术实现要素:
[0007]
针对人脸表情识别领域中的表情模糊性问题,目前的研究在如何定义模糊性程度上存在复 杂且多阶段的缺陷。本发明的目的是提出一种基于先验知识的人脸表情识别方法,利用更简单、 更高效的框架来降低表情模糊性问题带来的影响,从而实现更好的分类结果。
[0008]
为达上述目的,本发明采用的技术方案如下:
[0009]
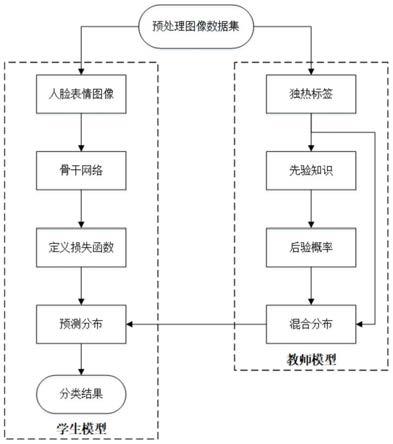
一种基于先验知识的人脸表情识别方法,具体步骤包括:
[0010]
步骤1,对图像数据集进行预处理,所述图像数据集中包括对应的真实标签数据;
[0011]
步骤2,将预处理后的图像的先验分布转化为类别的平均分布,再将对应的独热标签作为 索引从中提取先验知识,然后将先验知识转化为特定于每个数据集的后验概率,并将标签分布 和后验概率加权求和得到混合分布,以用于后续步骤指导学生模型更好地预测与人类直觉更一 致的结果;
[0012]
步骤3,将经预处理后的人脸表情图像输入至预训练好的学生模型网络中,进行特征提取;
[0013]
步骤4,将提取到的与表情高相关的特征通过全连接层输出预测分布,再经平滑处理后通 过分类器最终得到表情分类结果。
[0014]
进一步地,所述步骤1中,预处理具体为:通过旋转和缩放的方法扩充图像数据集,并对 数值归一化。
[0015]
进一步地,所述步骤2中,提取先验知识的方法为:
[0016]
步骤21,预处理后的图像数据集中每张图像x的先验分布为其中代表 v
x
为c
×
1阶矩阵,c为图像数据集的类别数,且∑v
x
=1;代表图像集,代表图像集对 应的独热标签;
[0017]
步骤22,对于每个独热标签y的平均分布为:
[0018][0019]
其中,是指图像集中独热标签y的样本子集,为子集的样本数;
[0020]
步骤23,将独热标签y作为索引,将每个独热标签y的平均分布转化为先验知识 po(k|x)=d
yk
,其中x代表图像,为当独热标签为y时,被分类为类别k的概率。
[0021]
进一步地,所述步骤2中,采用朴素贝叶斯公式将先验知识转化为特定于每个数据集的后 验概率:
[0022][0023]
其中a事件代表图像的独热标签为y,b事件代表图像被预测为类别k,p(a)为数据集的 分布,p(bk|a)代表已知图像的独热标签为y且图像被预测为类别k的概率,即先验知识po(k|x),p(a|bk)为推理过程中模型的预测结果,即后验概率pe(k|x)。
[0024]
进一步地,所述步骤2中,混合分布的计算方法为:
[0025]
pf(k|x)=(1-α)pe(k|x)+αq(k|x)
[0026]
其中α控制分布之间的权重,pe(k|x)为后验概率,q(k|x)为真实标签分布。
[0027]
进一步地,所述步骤3中,学生模型网络的训练步骤包括:步骤31,将训练集输入学生模 型网络中,获取学生模型网络的输出结果;步骤32,基于学生模型网络的输出结果和真实标 签数据确定交叉熵损失函数,损失函数中包括步骤2得到的混合分布;步骤33,利用所述交 叉熵损失函数对学生模型网络进行迭代训练。
[0028]
进一步地,所述步骤4中,将预测分布p(k|x),经过温度系数t平滑处理后得到
[0029]
进一步地,所述步骤4中,学生模型网络的损失函数为:
[0030]
l=(1-β)l
ce
+βlf[0031]
其中l
ce
为交叉熵函数,β控制损失函数之间的权重,lf为教师-学生模型损失函数:
[0032][0033]
其中,kl为相对熵,pf(k|x)为混合分布,为混合分布pf(k|x)经过温度系数t平滑 处理后得到的,x为图像,代表图像集。
[0034]
本发明提出的一种基于先验知识的人脸表情识别方法,利用了预先得到的先验知识,以更 简单高效且不用预训练的虚拟教师指导学生模型,在几乎不增加模型训练成本的情况下,进一 步提升了人脸表情识别的性能,同时在一定程度上解决了人脸表情识别中常见的表情模糊性问 题,得到了更趋于现实的预测。本发明能够在有效压缩学生模型的同时,也能让学生模型在低 复杂度的情况下在方面的性能获得进一步提升。
附图说明
[0035]
图1为本发明方法的流程图;
[0036]
图2为本发明与现有方法的性能对比,(a)raf-db数据集,(b)ferplus数据集,(c)affectnet 数据集。
[0037]
图3为统计分布、对照组分布和本发明分布的对比图。
[0038]
图4为三个人脸表情识别数据集上的2d特征可视化图。
具体实施方式
[0039]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方案做进一 步地详细描述。
[0040]
人脸表情的模糊性问题可归咎于人类注释者的强主观性和表情之间固有的强关联性。对于 前者,可以通过独热标签分布代替独热标签或是通过学习的方式赋予不同样本特定的权重来减 弱强主观性的影响;对于后者,可以通过现有的动作单元等先验知识来挖掘表情之间的关联性 和不同点,从而更好地提取到表情图像后的真实情感。
[0041]
本实施例提供了一种基于先验知识的人脸表情识别方法,如图1所示,具体步骤为:
[0042]
对原始人脸表情数据集通过改变尺寸、随机裁剪、随机水平翻转和随机擦除、数值归一化 等进行预处理,将输入图像尺寸统一为224
×
224
×
3。将预处理后的人脸图像数据集定义为 其中代表图像集,代表图像集对应的独热标签,输入图像x的独热标签 的分布为其中c为类别的数量,类别包含惊讶、害怕、 厌恶、高兴、伤心、生气、中立和蔑视八类基本表情。
[0043]
为了得到更趋于现实的分布,本实施例利用ferplus数据集的先验知识,人脸图像 x的先验表情分布是由数据集官方训练的注释者的投票结果计算得到的,其中代表 v
x
为c
×
1阶矩阵,并且∑v
x
=1。
[0044]
对于每个表情类别y的平均分布为:
[0045][0046]
其中,是指图像集中独热标签为y的样本子集,为子集的样本数。
[0047]
将预处理后的人脸表情数据集的独热标签y作为索引,向通过以上步骤计算得到的统计数 据中提取到先验知识po(k|x)=d
yk
,其中x代表图像,为当独热标签为y时,被分类 为表情k的概率,如表1所示。
[0048]
表1 ferplus数据集的统计数据
[0049] 惊讶害怕厌恶高兴伤心生气中立蔑视惊讶0.7880.0890.0030.0360.0100.0140.0580.002害怕0.1690.6590.0130.0120.0730.0270.0430.004厌恶0.0170.0080.6210.0170.0890.1250.0900.033高兴0.0230.0020.0020.9180.0050.0040.0430.003伤心0.0090.0160.0110.0130.7480.0230.1700.010生气0.0600.0230.0350.0250.0320.7410.0750.009中立0.0170.0040.0070.0330.1140.0260.7780.021蔑视0.0100.0060.0600.0210.0430.0340.1480.678
[0050]
为了将先验知识应用到不同的人脸表情识别数据集中,将先验知识转化为特定于每个数据 集的后验概率pe(k|x),采用了朴素贝叶斯公式:
[0051][0052]
其中a事件代表图像的独热标签为y,b事件代表图像被预测为类别k,p(a)为数据集的 分布,p(bk|a)代表已知图像的独热标签为y且图像被预测为类别k的概率,即先验知识 po(k|x),p(a|bk)为推理过程中模型的预测结果,即后验概率pe(k|x)。
[0053]
考虑到独热标签中的信息,将独热标签和后验概率加权求和得到混合分布:
[0054]
pf(k|x)=(1-α)pe(k|x)+αq(k|x)
[0055]
其中α控制分布之间的权重,pe(k|x)为后验概率,q(k|x)为真实标签分布。
[0056]
将resnet-18、resnet50-ibn、shufflenetv1和mobilenetv2四个骨干网络在大型人脸数 据集ms-celeb-1m数据集进行预训练,指导的损失函数为交叉熵损失函数;
[0057]
将预处理好的人脸表情图像输入至预训练好的骨干网络中,进行特征提取。
[0058]
将提取到的与表情高相关的特征通过全连接层输出预测分布p(k|x),经过温度系数t平滑 处理后得到
[0059]
定义教师-学生损失函数:
[0060][0061]
其中kl为相对熵,也即kullback-leibler散度,为pf(k|x)经过温度系数t平滑 处理后得到的,x为图像,代表图像集。
[0062]
学生模型中的总损失函数为:
[0063]
l=(1-β)l
ce
+βlf[0064]
其中l
ce
为交叉熵函数,β控制损失函数之间的权重。
[0065]
在教师模型的指导下,教师-学生损失函数可以减弱交叉熵函数易导致的过度自信的预测结 果,因此学生模型的预测分布经过分类器输出更趋于真实情感的分类结果。
[0066]
本实施例的有益效果可以通过如下实验来验证:
[0067]
一、模型精度
[0068]
1、不同骨干网络的对比
[0069]
根据本实施例提出的教师-学生框架,将使用resnet-18、resnet-50ibn、shufflenetv1和 mobilenetv2四种骨干网络训练后的模型与基准模型进行对比,如表2所示,在raf-db、 ferplus和affectnet这三个人脸图像数据集均得到可观的提升,分别平均提升了3.10%、2.76% 和3.62%的准确率。
[0070]
表2不同骨干网络准确率的对比
[0071][0072]
2、与现有方法的对比
[0073]
根据本实施例提出的教师-学生框架,训练后的模型在raf-db、ferplus和affectnet这 三个人脸图像数据集均得到可观的结果,并与现有的人脸表情识别方法进行了对比。
[0074]
图2给出了本发明与
背景技术:
中提到的现有方法的性能对比。为了对比的公平性,除vo th 提出的方法的骨干网络为vgg16以外,其余的方法的骨干网络都为resnet-18。本发明是用 在ms-celeb-1m人脸识别数据集上进行预训练的,在超参数t=5,α=0.50,β=0.55的设定下, 达到最好的结果。如图2中的(a)图所示,本发明在raf-db数据集上达到89.90%的准确率, 相比提升1%以上;(b)图显示本发明在ferplus数据集上以相比于vgg16更轻量的resnet-18 得到了更高的准确率;而(c)图则说明本发明在affectnet数据集上得到了将近2%准确率的 提升。由此可看出本发明在模型精度上的优越性。
[0075]
二、可视化结果
[0076]
1、预测分布和相关性
[0077]
根据以上具体方案训练后,得到的模型可以输出更趋于真实的预测分布。统计分布为注释 者的投票结果,对照组为只用交叉熵损失函数训练的基准模型,以kl散度作为相似度的度量 标准。
[0078]
如图3所示,在raf-db随机采样两张人脸表情图像,可以得到其统计分布、对照组
和本 发明的预测分布。计算得到的统计分布和本发明输出的预测分布的kl散度相对于统计分布和 对照组的kl散度明显降低,可看出本发明可以得到更真实的预测分布,且能够解决基准模型 过度自信预测的问题。
[0079]
2、2d特征的可视化
[0080]
通过强迫模型输出分布与实际分布一致,可以减小类内的差异。
[0081]
本实施例利用t-sne算法分析了本发明在raf-db、ferplus和affectnet三个数据集上 训练后的resnet-18的特征嵌入。
[0082]
如图4所示,可看到与基准模型相比,本发明显著地降低了类内的差异。此外,在教师模 型的指导下,类间的距离也进一步扩大,更好地区分了表情之间的差异。
[0083]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所 做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1