一种用于同城快递订单的智能信息提取方法与流程
1.本发明涉及自然语言处理邻域,尤其涉及到一种用于快递订单信息提取方法。
背景技术:
2.近年来物流快递行业迅速发展。用户在快递订单中需要手动填入关键信息,耗时费力,效率低下,用户体验不好。在现实场景中,自动提取文本中的关键信息,填入相应字段,具有实际应用价值。常见的快递订单信息提取方法有基于字典或规则的方法、基于机器学习的方法、基于深度学习的方法。本发明采用基于集成模型的方法,输入自然语言文本,输出格式化的预定义订单关键要素信息。本发明提供了一种方法,允许用户在信息栏输入或粘贴一段文字,模型自动完成关键信息的提取并录入。
技术实现要素:
3.有鉴于此,本发明采用基于集成模型的方法,输入自然语言文本,输出格式化的预定义订单关键要素信息。本发明提供了一种方法,允许用户在信息栏输入或粘贴一段文字,模型自动完成关键信息的提取并录入。减轻人工逐一录入信息的繁琐,提高信息录入效率,增强用户体验。
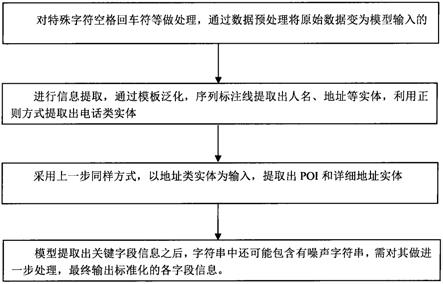
4.本发明采用基于集成模型的方法,分为数据预处理模块、信息提取模块、信息后处理模块。输入数据经过数据预处理模块,由原始数据转换为模型输入的格式。接着,信息提取模块对输入文本进行解析,提取出相应的关键信息。然后,信息后处理模块对提取到的信息进行处理加工,转换成规范的结构化数据并输出。最终,输出姓名,poi,详细地址,联系方式等标准化关键信息。
5.(1).数据预处理。用户输入字符长度近80%集中在10~50之间,符合正态分布。用户输入较随意,除正常文本外,还存在大量非正常文本(占比在10~20%之间),包括空白字符,表情符,推广链接,聊天记录,这对模型泛化能力提出了更高要求和挑战。原始输入数据经常含有噪声字符串,数据预处理将原始数据变为模型输入的数据格式。
6.(2).信息提取。上一步预处理后的数据作为模型的输入,通过模型预测,进一步自动提取出相应字段信息。
7.(3).数据后处理。模型提取出关键字段信息之后,字符串中还可能包含有噪声字符串,需对其做进一步处理,最终输出标准化的各字段信息。
8.1.数据预处理
9.下单信息用户的输入为键盘输入文字或粘贴数据,其可能包含有噪声,如字符画、全半角标点等影响后续模型的字符。数据预处理模块的目的将输入的文本进行清洗、规范化。具体的,在本方法中包括如下:
10.a.将英文标点统一转换为中文标点;
11.b.去重emoji、字符画等字符;
12.c.去除两个以上连续的空白字符;
13.d.将回车符用中文分号代替,空格用用逗号代替;
14.e.对字符串进行长度判断,实际小于2的字符串,不包含与订单相关信息,因此小于2的字符串直接滤除。
15.2.信息提取模块
16.信息提取模块作为方法的核心模块之一,目的是完成对各预定义字段的信息提取。快递地址一般是省、市、县、区、街道、小区、楼号、门牌号、机构名的组合。
17.考虑到领域数据的特殊性,我们尝试加入领域知识。通过统计元数据,我们确定加入的领域知识有省、市、县(区)、机构名、食物名等专有名词,不仅包含专有名词的标注名称,还包括专有名词的别称,如“北大”为“北京大学”的别称。
18.信息提取模块原理图如图所示。
19.用户输入快递订单信息经常为关键信息的机械罗列,核心算法模块我们采用序列标注常见算法,条件随机场(crf)算法。
20.给定x,y均为线性链表示的随机变量序列,若在给随机变量序列x的条件下,随机变量序列y的条件概率分布构成条件随机场,即满足马尔可夫性,则称为p(y|x)为线性链条件随机场。
21.模型的输入表2所示,词,词性,其中第一列为字,第二列为词性。为了消除分词错误的影响,我们采用字输入的方式。
22.模板泛化 利用知识词典,将输入文本中的实体词用槽位代替。其中,省市区县类实体采用知识字典形式进行替换,电话和邮编采用正则匹配方式进行替换。实体词与槽位映射关系如表所示:
23.表1实体名称-槽位对应表
24.实体名称槽位省#province{n}#市#city{n}#区县#county{n}#电话#tel{n}#邮编#postcode{n}#
25.序列标注
26.标签我们采用二级标签,第一级采用bioes表示,其中b实体词的开始位置,i表示实体词的中间字或词,e表示实体词的结束位置,s表示单字实体,o表示为非实体字或词。二级标签采用实体类别的英文表示。例如,地址类实体标签分别为:b-address,i-address,e-address,s-address,o。
27.表2序列标注示例
28.字词性序列标签#province{n}#nspb-address#city{n}#nsci-address#county{n}#nscui-address七nsi-address一nsi-address
路nsi-address龙nri-address鼎nri-address大nsi-address厦nsi-address;w0张nrb-name三nre-name;w0#tel{n}#num0;w0邮n0编n0:w0#postcode{n}#npc0
29.信息提取
30.通过模型预测输出的标签,我们可以获得地址类和人名类实体,然后再用同样的方法,以地址类实体作为输入,输出poi和详细地址。通过以上pipline结构,我们依次获得人名、电话、poi、详细地址等结构化信息。
31.3.数据后处理
32.经过信息提取模块,输入数据由非结构化数据变为结构化数据,数据后处理的目的使各字段的数据标准化。具体如下:
33.a.抽取的各项统一去除连续两个以上空格以及“@”“,”“:”“?”“*”“¥”“&”“!”“#”“$
”“……”“
^”“(”“)”“【”“】”“《”“》”等字符;
34.b.电话号码项去除
“‑”
、空格等字符;
35.c.poi、详细地址项去除城市,防止实际应用中对定位的干扰。
附图说明
36.下面结合附图和实施例对本发明作进一步描述:
37.图1为本发明的流程图。
具体实施方式
38.本发明采用基于集成模型的方法,分为数据预处理模块、信息提取模块、信息后处理模块。输入数据经过数据预处理模块,由原始数据转换为模型输入的格式。接着,信息提取模块对输入文本进行解析,提取出相应的关键信息。然后,信息后处理模块对提取到的信息进行处理加工,转换成规范的结构化数据并输出。最终,输出姓名,poi,详细地址,联系方式等标准化关键信息。
39.(1).数据预处理。用户输入字符长度近80%集中在10~50之间,符合正态分布。用户输入较随意,除正常文本外,还存在大量非正常文本(占比在10~20%之间),包括空白字
符,表情符,推广链接,聊天记录,这对模型泛化能力提出了更高要求和挑战。原始输入数据经常含有噪声字符串,数据预处理将原始数据变为模型输入的数据格式。
40.(2).信息提取。上一步预处理后的数据作为模型的输入,通过模型预测,进一步自动提取出相应字段信息。
41.(3).数据后处理。模型提取出关键字段信息之后,字符串中还可能包含有噪声字符串,需对其做进一步处理,最终输出标准化的各字段信息。
42.1.数据预处理
43.下单信息用户的输入为键盘输入文字或粘贴数据,其可能包含有噪声,如字符画、全半角标点等影响后续模型的字符。数据预处理模块的目的将输入的文本进行清洗、规范化。具体的,在本方法中包括如下:
44.a.将英文标点统一转换为中文标点;
45.b.去重emoji、字符画等字符;
46.c.去除两个以上连续的空白字符;
47.d.将回车符用中文分号代替,空格用用逗号代替;
48.e.对字符串进行长度判断,实际小于2的字符串,不包含与订单相关信息,因此小于2的字符串直接滤除。
49.2.信息提取模块
50.信息提取模块作为方法的核心模块之一,目的是完成对各预定义字段的信息提取。快递地址一般是省、市、县、区、街道、小区、楼号、门牌号、机构名的组合。
51.考虑到领域数据的特殊性,我们尝试加入领域知识。通过统计元数据,我们确定加入的领域知识有省、市、县(区)、机构名、食物名等专有名词,不仅包含专有名词的标注名称,还包括专有名词的别称,如“北大”为“北京大学”的别称。
52.信息提取模块原理图如图所示。
53.用户输入快递订单信息经常为关键信息的机械罗列,核心算法模块我们采用序列标注常见算法,条件随机场(crf)算法。
54.给定x,y均为线性链表示的随机变量序列,若在给随机变量序列x的条件下,随机变量序列y的条件概率分布构成条件随机场,即满足马尔可夫性,则称为p(y|x)为线性链条件随机场。
55.模型的输入如表2所示,词,词性,其中第一列为字和槽位,第二列为词性。为了消除分词错误的影响,我们采用字输入的方式。
56.模板泛化 利用知识词典,将输入文本中的实体词用槽位代替。其中,省市区县类实体采用知识字典形式进行替换,电话和邮编采用正则匹配方式进行替换。实体词与槽位映射关系如表所示:
57.表1实体名称-槽位对应表
58.实体名称槽位省#province{n}#市#city{n}#区县#county{n}#电话#tel{n}#
邮编#postcode{n}#
59.序列标注
60.标签我们采用二级标签,第一级采用bioes表示,其中b实体词的开始位置,i表示实体词的中间字或词,e表示实体词的结束位置,s表示单字实体,o表示为非实体字或词。二级标签采用实体类别的英文表示。例如,地址类实体标签分别为:b-address,i-address,e-address,s-address,o。
61.表2序列标注示例
62.字词性序列标签#province{n}#nspb-address#city{n}#nsci-address#county{n}#nscui-address七nsi-address一nsi-address路nsi-address龙nri-address鼎nri-address大nsi-address厦nsi-address;w0张nrb-name三nre-name;w0#tel{n}#num0;w0邮n0编n0:w0#postcode{n}#npc0
63.信息提取
64.通过模型预测输出的标签,我们可以获得地址类和人名类实体,然后再用同样的方法,以地址类实体作为输入,输出poi和详细地址。通过以上pipline结构,我们依次获得人名、电话、poi、详细地址等结构化信息。
65.3.数据后处理
66.经过信息提取模块,输入数据由非结构化数据变为结构化数据,数据后处理的目的使各字段的数据标准化。具体如下:
67.a.抽取的各项统一去除连续两个以上空格以及“@”“,”“:”“?”“*”“¥”“&”“!”“#”“$
”“……”“
^”“(”“)”“【”“】”“《”“》”等字符;
68.b.电话号码项去除
“‑”
、空格等字符;
69.c.poi、详细地址项去除城市,防止实际应用中对定位的干扰。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1