用于检测占用者疾病症状的系统和方法与流程
1.本公开涉及用于检测占用者疾病症状的系统和方法。在一些实施例中,系统和方法能够检测公共或拥挤场所或诸如公共交通工具或乘坐共享的共享移动中的人的疾病症状。
背景技术:
2.传染病能够在拥挤场所(诸如餐馆、竞技场、公共建筑等)中更容易传播。共享移动服务也是如此,诸如公交车、火车、出租车以及叫车和乘坐共享服务。目前的技术无法充分向此类场所和服务的所有者和/或占用者提供有关清洁度的信息。如果服务提供者或占用者掌握了关于占用者的潜在疾病的知识,就可以做出更好的决定来帮助遏制传染病的传播。
技术实现要素:
3.在实施例中,提供用于检测占用者疾病症状的系统。系统包括用户界面、被配置成维持可视化应用和来自图像源的图像数据的存储器以及处理器。处理器与存储器和用户界面通信。处理器被编程为接收来自图像源的图像数据,该图像数据包括与占用者正占用的区域相关联的背景图像。处理器进一步被编程为:执行被配置成检测在图像数据内的占用者的人类检测模型;执行被配置成基于检测到的占用者的运动识别图像数据内的检测到的占用者的基于图像的疾病症状的活动识别模型;利用来自图像源的图像数据确定识别出的疾病症状的位置;以及执行可视化应用以在用户界面中显示被叠加到背景图像上的叠加图像。叠加图像包括针对每个识别出的疾病症状的位置的指示器,所述指示器显示在该位置处发生识别出的疾病症状的信息。
4.在实施例中,用于检测占用者疾病症状的系统包括用户界面、被配置成维持可视化应用和来自音频源的音频数据的存储器以及与存储器和用户界面通信的处理器。处理器被编程为:从占用者正占用的区域的照相机接收背景图像;从音频源接收音频数据;执行被配置成将音频数据的部分分类为指示疾病症状的分类模型;基于音频数据的被分类部分确定疾病症状的位置;以及执行可视化应用以在用户界面中显示被叠加到背景图像上的叠加图像,叠加图像包括针对每个确定的疾病症状的位置的指示器,所述指示器显示在该位置处发生疾病症状的信息。
5.在另一实施例中,用于检测占用者疾病症状的另一系统包括用户界面、被配置成维持可视化应用和来自雷达源的雷达数据的存储器以及与存储器和用户界面通信的处理器。处理器被编程为:从占用者正占用的区域的照相机接收背景图像;从雷达源接收雷达数据;执行被配置成基于雷达数据检测占用者的人类检测模型;执行被配置成基于雷达数据识别检测到的占用者的基于雷达的疾病症状的活动识别模型或生命体征识别模型;利用来自雷达源的雷达数据确定基于雷达的识别出的疾病症状的位置;以及执行可视化应用以便在用户界面中显示被叠加到背景图像上的叠加图像,叠加图像包括,针对每个确定的症状
的位置的在该位置处发生基于雷达的识别出的疾病症状的指示器。
附图说明
6.图1示出了根据实施例的用于检测占用者疾病症状的系统的示例。
7.图2示出了根据实施例的示出传感器的位置的车辆的内部。
8.图3示出了根据实施例的示出传感器的一个或多个位置的公交车的内部。
9.图4示出了根据实施例的用于基于音频数据检测并显示占用者疾病症状的流程图。
10.图5示出了根据实施例的可视化应用的输出,其用于突出显示具有更大量的检测到的占用者疾病症状的区域。
11.图6示出了根据实施例的用于基于图像数据检测并显示占用者疾病症状的流程图。
12.图7示出了根据实施例的用于基于来自传感器的数据检测人类的人类检测应用的实施方式。
13.图8是示出疾病检测操作或分类的使用的帧序列。
14.图9示出了根据实施例的用于基于图像数据和音频数据的融合来检测并显示占用者疾病症状的流程图。
15.图10示出了根据另一实施例的用于基于图像数据和音频数据的融合来检测并显示占用者疾病症状的流程图。
16.图11示出了根据实施例的用于基于雷达数据检测并显示占用者疾病症状的流程图。
17.图12示出了根据另一实施例的用于基于雷达数据检测并显示占用者疾病症状的流程图。
18.图13示出了根据另一实施例的用于基于雷达数据检测并显示占用者疾病症状的流程图。
19.图14示出了根据另一实施例的用于基于雷达数据检测并显示占用者疾病症状的流程图。
20.图15示出了根据实施例的用于基于雷达数据、图像数据和音频数据的融合来检测并显示占用者疾病症状的流程图。
21.图16示出了根据实施例的用于基于雷达数据、图像数据和音频数据的融合来检测并显示占用者疾病症状的流程图。
具体实施方式
22.在此描述了本公开的实施例。不过应该理解的是,公开的实施例仅仅是示例并且其它的实施例能够采取各种替代性形式。附图不必是成比例的;并且一些特征可以被放大或缩小以便示出具体部件的细节。因此,这里描述的特定结构和功能细节不试图被解释为限制性的,而是仅作为教导本领域技术人员的代表性基础以便广泛地应用实施例。如本领域技术人员将理解的,参考任何一幅图图释和描述的各种特征能够与一幅或多幅其它附图中的特征相结合来产生没有被明确示出或描述的实施例。所示特征的组合提供了典型应用
的代表性实施例。不过对于特定的应用或实施方式,可以期望与本公开的教导一致的特征的各种组合和修改。
23.人们日益依赖共享移动服务,诸如公交车、火车、出租车以及叫车服务,诸如uber和lyft。在这些共享移动服务中,许多不同的人在不同时间占用公共空间。随着新的传染病传播,当共享这样的公共空间时传染风险增加。目前的技术无法为占用者提供足够的信息来评估共享空间的清洁度。本公开提出了多个新颖技术来辅助共享移动服务的占用者基于由一种或多种不同类型的传感器(诸如音频传感器、视频传感器和/或雷达传感器)所指示的先前占用者的指示疾病的活动(诸如咳嗽或打喷嚏事件)做出有根据的决定。如果使用一种以上不同类型的传感器来检测占用者的潜在疾病症状,则传感器数据可以被融合。
24.在其它实施例中,传感器被用在其它的大型拥挤环境中,诸如餐厅、公共建筑、音乐会场地、体育赛事等。传感器可以被用于检测这些场所的占用者的疾病症状。
25.本公开也提出了为车队(诸如车辆租赁服务)的提供者(例如所有人或经理)提供这样的信息。例如,这里描述的传感器中的一个或多个能够被放置在车队的每辆车中,并且能够被用于检测该车辆内的占用者疾病症状并且将该信息传达给车队提供者。当车队提供者由于检测到咳嗽、打喷嚏等的迹象而获知之前占用者可能生病时,车队提供者能够给这样的车辆消毒并且通知共同占用者或随后占用者传染的可能性。这个信息也能够帮助城市规划者大体了解病菌在哪些路线上传播更快以及相关症状。
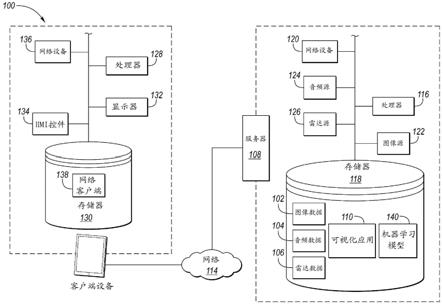
26.图1示出了示例系统100,其用于检测占用者疾病症状并以可视化显示检测到的症状。系统100也能够被称为检测和可视化系统,因为该系统至少部分被配置成处理图像并确定代表占用者疾病的图像的特定特征或质量,并且提供检测到的占用者疾病的可视化,以致占用者或其它用户能够做出明智的决定和行动。在其它实施例中,系统利用音频或射频(rf)来确定占用者疾病。所示系统100不仅被配置成检测占用者疾病症状,还被配置成显示关于症状的信息(例如,图像注解或者图像重叠)以用于作用于说明检测到的或确定的症状的数据。
27.在一个或多个实施例中,系统100被配置成用于图像数据102的捕捉。与图像数据102相结合或者与图像数据102分离,系统100可以被配置成捕捉和处理音频数据104和/或雷达数据106。系统100包括托管可视化应用110的服务器108,该可视化应用110可由一个或多个客户端设备112经由网络114访问。服务器108包括处理器116,其可操作地连接到存储器118和网络设备120。服务器108进一步包括用于接收图像数据102的图像数据输入源122,其可操作地连接到处理器116和存储器118。服务器108也可以包括用于接收音频数据104的音频数据输入源124,其可操作地连接到处理器116和存储器118。服务器108也可以包括用于接收雷达数据106的雷达数据输入源126,其可操作地连接到处理器116和存储器118。客户端设备112包括可操作地连接到存储器130的处理器128、显示设备132、人机界面(hmi)控件134和网络设备136。客户端设备112可以允许操作者访问网络客户端138。
28.应该注意,示例系统100是一种示例,并且可以使用由多个单元100构成的其它系统。例如,虽然仅示出一个客户端设备112,但是可以想到包括多个客户端设备112的系统100。作为另一可能性,虽然示例实施方式被示为基于网络的应用,但是替代性系统可以被实现为独立系统、本地系统或者作为具有胖客户端软件的客户端-服务器系统。诸如图像源122、音频源124和雷达源126的各种部件和相关联的数据102、104、106可以在系统100的客
户端设备处而不是在服务器108处被本地接收并处理。
29.服务器108的处理器116和客户端设备112的处理器128中的每个可以包括实现中央处理单元(cpu)和/或图形处理单元(gpu)的功能的一个或多个集成电路。在一些示例中,处理器116、128是片上系统(soc),其集成了cpu和gpu的功能。soc可以可选地将诸如例如存储器118和网络设备120或136的其它部件包括到单个集成设备中。在其它示例中,cpu和gpu经由诸如pci express的外围连接设备或另一适当的外围数据连接被连接到彼此。在一种示例中,cpu是商业上可用的中央处理设备,其实现诸如x86、arm、power或mips指令集系列之一的指令集。
30.不管具体情况如何,在操作期间,处理器116、128执行分别从存储器118、130检索到的存储的程序指令。存储的程序指令因此包括控制处理器116、128的操作来执行这里描述的操作的软件。存储器118、130可以包括非易失性存储器和易失性存储器设备二者。非易失性存储器包括固态存储器(诸如nand快闪存储器、磁性和光学存储介质)或者在系统100停用或断电时保留数据的任何其它适当的数据存储设备。易失性存储器包括静态和动态随机存取存储器(ram),其在系统100的操作期间存储程序指令和数据。
31.客户端设备112的gpu可以包括硬件和软件以用于向客户端设备112的显示设备132显示至少二维(2d)和可选的三维(3d)图形。显示设备132可以包括电子显示屏、投影仪、打印机或者重现图形显示的任何其它适当的设备。在一些示例中,客户端设备112的处理器128通过使用gpu中的硬件功能来执行软件程序以加速机器学习或者这里描述的其它计算操作的性能。
32.客户端设备112的hmi控件134可以包括使得系统100的客户端设备112能够从工人、车队车辆经理或其它用户接收控制输入的各种设备中的任何设备。接收人机界面输入的合适的输入设备的示例可以包括键盘、鼠标、轨迹球、触摸屏、语音输入设备、图形平板电脑等。如这里描述的,用户界面可以包括显示设备132和hmi控件134中的任何一者或两者。
33.网络设备120、136可以均包括使得服务器108和客户端设备112能够分别经由网络114发送和/或接收来自外部设备的数据的各种设备中的任何设备。适当网络设备120、136的示例包括网络适配器或者从另一计算机或外部数据存储设备接收数据的外围互连设备,其能够用于以高效方式接收大数据集。
34.可视化应用110是由服务器108执行的网络应用的示例。当被执行时,可视化应用110可以使用各种算法来执行这里描述的操作的各方面。在示例中,可视化应用110可以包括如上文讨论的可由服务器108的处理器116执行的指令。可视化应用110可以包括被存储到存储器118且如这里描述的可由处理器116执行的指令。计算机可执行指令可以由使用各种编程语言和/或技术创建的计算机程序编译或解释,包括但不限于,单独或组合的,java、c、c++、c#、visual basic、javascript、python、perl、pl/sql等。大体而言,处理器116例如从存储器或内存118、计算机可读介质等接收指令,并执行这些指令,从而执行一个或多个过程,包括本文描述的过程中的一个或多个。这样的指令和其它的数据可以通过使用各种计算机可读介质被存储和传输。
35.网络客户端138可以是由客户端设备112执行的网页浏览器或其它基于网页的客户端。当被执行时,网页客户端138可以允许客户端设备112访问可视化应用110以显示可视化应用110的用户界面。网络客户端138可以经由网络114向服务器108的可视化应用110进
一步提供经由hmi控件134接收的输入。
36.在人工智能(ai)或机器学习系统中,基于模型的推理指的是基于待分析的世界观的机器学习模型140来操作的推断方法。大体而言,机器学习模型140被训练成学习在输入值和输出值之间提供精确关联的函数。在运行时,机器学习引擎对照观察到的数据使用机器学习模型140中编码的知识来导出诸如诊断或预测的结论。一种示例机器学习系统可以包括可从加利福尼亚州山景城的alphabet inc.获得的tensorflow ai引擎,不过可以附加地或替代性地使用其它机器学习系统。如这里具体讨论的,可视化应用110与机器学习模型140通信并且可以被配置成识别图像数据102的特征以便在高效且可缩放的地面实况生成系统和方法中使用来产生被用于开发目标检测/定位和目标跟踪的高精度(像素级精度)注释。在一些实施例中,可视化应用110与机器学习模型140通信并且可以被配置成识别音频数据104的音频特征或模式以便在类似系统中使用来在这种音频源的位置处的显示器132或网页客户端138上生成可视输出。在一些实施例中,可视化应用110与机器学习模型140通信并且可以被配置成识别雷达数据106的雷达特征或模式以便在类似系统中使用来在可由雷达检测到的目标的人的位置处的显示器132或网页客户端138上生成可视输出。简而言之,可视化应用可以包括机器学习模型140或与其通信,以用于执行图像识别(例如,图6的步骤606-612)、音频识别(例如,图4的步骤406-412)和/或雷达识别(图11的步骤1106-1112)的各个步骤和/或包括这些技术中的两者或更多者的任何融合步骤。
37.图像数据输入源122可以是照相机,其例如被安装在诸如以下各者的位置中:车辆、车队车辆、公共交通工具、餐厅、飞机、电影院或发生大量人员交通或聚集的其它位置或其中确定有疾病症状的人的存在和位置可能值得的其它位置。图像数据输入源122被配置成捕捉图像数据102。在另一示例中,图像数据输入源122可以是界面,诸如网络设备120或至存储器118的界面,以用于检索之前捕捉的图像数据102。图像数据102可以是单个图像或者录像,例如图像序列。在图像数据102中的每个图像可以在此被称为帧。出于隐私考虑,对于某些注释或可视化任务,可以从图像数据102模糊面部和车牌。
38.音频源124可以是被安装在上文描述的示例性位置中的声学传感器或麦克风,并且被配置成检测并定位感兴趣事件(例如,发生疾病症状的区域)。音频源124被配置成捕捉音频数据104。在另一示例中,音频输入源124可以是界面,诸如网络设备120或至存储器118的界面,以用于检索之前记录的音频数据104。音频数据104可以是来自音频源124(例如,麦克风)的被接收音频,当音频源124启用时始终可以检测和/或记录该音频。如这里也将描述的,音频源124可以是在阵列中或各个位置中的多个音频源124,从而允许确定有疾病症状的受试占用者的三角测量或其位置。
39.雷达源126可以是无接触传感器,其被配置成通过分析在射频信号和生理运动之间的相互作用来检测人类生命体征,诸如呼吸、呼吸率、心率、心率变异性和人类情绪,而无需与人体进行任何接触。这种雷达源126的非限制示例是多普勒sd雷达,其中连续波(cw)窄带信号被发射,从人类目标反射,并且随后在雷达源126的接收机中被解调。其它雷达源126包括超宽带(uwb)雷达或其它cw雷达设备,或毫米波传感器,诸如60-ghz或77-ghz毫米波传感器。
40.图2示出了在车辆202内的传感器200的放置的实施例。车辆202可以是乘用车辆,诸如轿车、货车、卡车、运动型多功能车辆(suv)等。如这里所述,在其它实施例中,车辆是公
交车、火车、飞机或者其它公共运输车辆。传感器能够是图像源122、音频源124、雷达源126或其任何组合中的一个或多个。传感器的部署和放置可以取决于环境。例如,在所示实施例中,传感器200被安装在车辆202的仪表盘204上或被安装到仪表盘204。在其它实施例中,传感器200被安装在挡风玻璃206、后视镜208或车辆202中的其它位置上或被安装到这些位置。在实施例中,传感器200被安装在使得其能够从车辆202内的占用者适当地接收图像数据、音频数据和/或雷达数据的位置处。
41.代替使用单个传感器200,遍布车辆可以放置阵列或多个传感器200。在车辆是公交车或者其它大型多乘客车辆的实施例中,遍布车辆可以利用多个传感器200。更多传感器可以被用于覆盖大的共享移动空间,诸如在公交车或火车中。作为示例,在图3中示出了多个传感器200在公交车302中的部署。传感器可以被部署在公交车302的其它区域中,包括天花板、座椅之下或之上和其它位置。
42.如这里所述,传感器200可以被用在任何车辆中,尤其是用于同时(例如,公交车)或在单独的不同时间(例如,叫车或车队车辆、车辆租赁等)运输多个占用者的车辆中。同样地,传感器200可以位于非车辆位置中,诸如餐厅、公共建筑、机场、竞技场、体育场馆、场馆以及可能发生大量人流量或密度的其它此类位置。简而言之,这里提供的描述和图释不试图被限于传感器200仅在车辆内的使用。
43.图4示出了用于检测指示占用者疾病症状的事件、定位事件并以可视化显示相关信息的系统400的实施例的流程图。这些步骤能够由图1中所示的结构中的至少一些来执行,诸如处理器116、128、音频源124、存储器118、音频数据104等等。在这种实施例中,传感器200中的一个或多个被置于具有占用者的期望位置周围,诸如上述车辆、建筑等。在这种实施例中,传感器中的一个或多个包括音频源124,诸如麦克风。音频源124被配置成当使用时以特定采样率连续倾听音频声音。换言之,在402,系统从音频源124接收音频数据104诸如声学信号。
44.系统400能够包括在404的预处理步骤。捕捉的音频数据104通过使用过滤器来去噪。然后音频数据104通过使用滑动窗口算法被分段。同样地,隐私保护音频处理能够被用于满足用户隐私要求。例如,系统能够被配置成通过语音活动检测(vad)算法来选择性地取消或拒绝来自连续音频流的人类语音。通过在预处理阶段执行vad,能够避免不必要的编码或传输静音包或者能够移除噪声或不相干的言语,从而节省计算和网络带宽。设想了vad的各种实施例并且其应该被包括在本公开的范围内。例如,许多vad系统遵循如下各者的大体架构:(i)首先执行降噪,然后(ii)从诸如音频数据104的输入信号的一个区段计算特征或质量,且然后(iii)应用分类规则以便将这个区段分类为言语或非言语,可选地应用阈值并比较被分类噪声与该阈值。
45.系统400也能够包括在406处的特征提取模型或应用。在这个步骤处,已经如上所述被去噪和过滤的相关音频数据之后被提取以进行分析。在这个步骤处能够使用mel频率倒谱系数(mfcc)、声网卷积神经网络(cnn)或其它类型的机器学习、时域特征、频域特征和/或其组合来提取音频数据的相关特征。根据特征提取算法的类型,提取的数据(音频特征表示)能够被存储为多维向量或矩阵。
46.系统400也能够包括在408处的分类模型或应用。在这个步骤处,分类器被用于给音频事件分类。预处理和提取的音频数据的部分能够被分类为打喷嚏、咳嗽、呼吸短促或者
能够指示出占用者疾病可能性的其它这样音频。为此目的,能够使用支持向量机(svm)、随机森林或多层感知器分类器。这里描述的机器学习模型140可以为此目的被实施。同样地,音频特征学习和分类能够通过使用深度音频分析算法以端到端的方式被执行,其中时域波形被用作输入。例如,具有34个权重层的cnn能够高效地优化非常长的序列,例如32000的向量大小以处理声学波形。这能够通过使用批量归一化和残差学习来实现。这种模型的示例被讨论于wei dai、chia dai、shuhui qu、juncheng li、samarjit das在2017年的ieee声学、语音和信号处理国际会议(icassp)发表的“very deep convolutional neural networks for raw waveforms”中。
47.系统400也能够包括在410处的到达角(aoa)估计或确定。aoa能够被实施以估计声音源的位置,以致系统能够估计咳嗽、打喷嚏等源自哪里。为了执行此,系统可以包括多个传感器200或音频源124。波束形成算法可用于估计传入的声学信号的aoa。如果音频源例如是麦克风,则例如这能够通过使用具有多个麦克风的单个麦克风阵列,使用延迟和波束形成和多信号分类(music)算法来实现。
48.在完成aoa估计之后,在412处能够发生定位过程。可以实施音频测向技术,诸如三角测量法。这提供了感兴趣事件(例如,咳嗽、打喷嚏等)的源位置。在简化示例中,被分析声音源的位置可以由处理器通过测量在接收音频的每个音频源之间的时间差来确定。例如,如果使用麦克风的阵列,则在接收音频信号的麦克风中的第一和接收音频信号的麦克风中的第二个之间的时间被(多个)处理器注意到并且与在接收音频信号的第二麦克风和接收音频信号的麦克风中的第三个之间的时间进行比较。这个过程能够针对在系统的位置中提供的许多传感器继续。
49.在另一实施例中,如图4中所示,在408处的分类之后,aoa估计能够被跳过并且在412处的定位能够基于声学信号本身的强度被执行,而不是从aoa估计步骤410拉取数据。
50.在414处,系统之后执行时间序列聚合。在这个步骤处,贯穿一天检测到的感兴趣的音频事件被聚合。系统能够计算在位置的每个区域中每个音频事件发生多少次。例如,在系统被实施在公交车上的情况下,聚合能够编译在公交车上特定座位处发生打喷嚏或咳嗽事件的次数。在餐厅的情况下,聚合能够编译在餐厅的特定桌子处发生打喷嚏或咳嗽事件的次数。这个聚合414能够聚合每个音频源(例如,麦克风)或者每个确定的(例如,三角测量的)位置处的指示出疾病的音频事件的数量。聚合的结果能够被本地存储在存储器118上或者经由网络114存储在云中。
51.聚合414的结果能够触发在系统中的标志,从而指示出特定的感兴趣区域受到大量占用者疾病症状影响,并且需要消毒。例如,聚合可以经由音频信号处理指示出公交车内的特定座位受到大量占用者疾病症状影响,并且可以将公交车的这个区域标志为被感染,直到座位被清洁。检测到的占用者疾病症状的数量可以与将区域标志为被感染的阈值进行比较。例如,阈值可以是三,以致自最近的清洁以来,当系统检测到三个检测到的占用者疾病症状(例如,由音频信号检测到的咳嗽或打喷嚏),则系统将这个区域标志为被感染,直到该区域被再次清洁。在目标区域被消毒之后,聚合能够被重置为零。
52.系统之后能够执行在416处的可视化。在这个步骤处,来自414的聚合信息以允许人员以视觉友好格式看到数据的方式被显示给人员。通过通过网络114传输时,可视化在客户端设备112(例如,显示设备或者用户界面)处可查看,或者能够被本地查看。在一种示例
中,“热图”能够被显示给人员以进行可视化。热图可以进行颜色编码,在各位置处示出与在这些位置处检测到的疾病症状数量相对应的不同颜色。可视化可以包括背景图像。背景图像可以是占用者位置的静止单个图像(例如,空的公交车)。替代性地,背景图像可以是占用者的位置的实时视图(例如,视频)。具有对应于检测到的疾病的位置的颜色的热图可以被叠加到背景图像上。
53.图5示出了被示于显示器上以便人员观察的可视化500的示例。图5所示图像来自于图像或视频源,诸如照相机或者图像源122。在这种示例中,图像源122被安装在公交车内以显示公交车502内部的实时图像。系统能够预编程以致图像中所示位置与从音频源124检测到的对应位置相匹配。换言之,如这里解释的由音频源124检测到的疾病症状的位置能够被叠加在来自图像源122的图像上;能够在初步步骤处在图像上所示的位置与由音频源确定的位置之间进行匹配,以致处理器能够在与来自音频源124的检测到的疾病症状的确定的位置相匹配的区域中对图像进行简单颜色编码。
54.在图5所示的实施例中,所示的背景图像502的绝大部分与叠加图像504进行叠加。在这种实施例中,叠加图像504包括蓝色或暗色调,在此没有检测到经检测疾病症状。在其它实施例中,叠加图像504是清晰的,以致背景图像502在未检测到经检测疾病症状的区域中不失真或不进行颜色编码。通过使用这里解释的系统,从音频源124接收的信号被处理,并且确定来自占用者的检测到的疾病症状的位置。这些位置对应于不同颜色色调或阴影,如区域506和508所示。区域506可以对应于具有五个检测到的最近占用者疾病症状的位置,而区域508可以对应于具有四个检测到的最近占用者疾病症状的位置。该区域506、508也是被叠加到背景图像502上的叠加图像504的一部分。因此,热图示出被叠加到图像502上的更红一些或具有更亮颜色的区域506。图5所示的热图仅是显示在位置506和508处发生的检测到的占用者疾病症状的指示器的一个示例。在其它实施例中,不同于颜色编码的热图,叠加图像504能够显示对应于检测到疾病症状的区域的框、星、圆形或其它这样的指示器。
55.这种示例性可视化500可以以各种设定被示出。当然,可视化可以被提供给位置的所有人或经理,诸如车辆车队、公交车、餐厅等的所有人或者经理。另外,可视化可以被显示在该位置处的乘坐者或占用者的智能手机或移动设备(例如,客户端设备112)上,以向该乘坐者或占用者提供关于应避免去往的位置的明智决定,以减少感染传播的机会。网络114可以通过这里解释的示例性结构传达这样的信息至移动设备。可视化也可以被集成到乘坐者或占用者的移动设备的增强现实(ar)应用中。可视化也可以被提供在被安装在区域内(例如,公交车内)的显示器上以通知位置的当前占用者潜在的污染。
56.在另一实施例中,代替显示增强信息,聚合信息能够被本地存储,并且当用户在已经检测到大量(例如高于阈值)的检测到的占用者疾病的位置附近时通知他/她。每个传感器200可以装备有扬声器,并且可以在用户接近这样的还未被清洁的潜在污染区域时输出音频通知。
57.图6示出了用于检测指示占用者疾病症状的事件、定位事件并以可视化显示相关信息的系统600的实施例的流程图。再次地,这些步骤能够由图1中所示的结构中的至少一些来执行,诸如处理器116、128、图像源122、存储器118、图像数据102等等。在这种实施例中,传感器200中的一个或多个被置于具有占用者的期望位置周围,诸如上述车辆、建筑等。在这种实施例中,传感器中的一个或多个包括图像源122,诸如照相机。图像源122被配置成
当使用时以特定采样率连续捕捉图像或一系列图像(视频)。换言之,在602处,系统从图像源122接收图像数据102诸如捕捉的图像。
58.系统600能够包括在604处的预处理步骤。为了一致性原因,针对被馈送到系统的所有图像,捕捉的图像能够在604处被调整大小成基础大小。捕捉的图像也能够被去噪以平滑图像并去除不必要的噪声。去噪的一种示例是使用高斯模糊。仍然在604处的预处理步骤期间,图像能够被分段,从而将背景与前景目标分离。其它预处理功能能够被执行以准备图像以进行人类检测、特征提取等的处理。
59.一旦图像被预处理604,则系统在606处执行人类检测步骤。能够使用一个或多个目标检测技术,诸如你只看一次(yolo)、单镜头多盒检测器(ssd)、faster r-cnn等等。这些目标检测技术中的许多会利用预训练的模型进行“人类”或“人员”检测。这可以例如作为机器学习模型140的一部分被执行。
60.图7示出了在受试区域(诸如公交车)内的占用者的图像700。步骤606的人类检测技术提供了围绕每个检测到的人类的边界框,如图7中以黄色边界框702、704、706所示。目标检测器中的一些(诸如yolo)也提供包括检测到的目标实际上是人类的置信度百分比的输出。默认地,如果仅满足特定置信度(例如,50%或更高),则围绕人类放置边界框。然而,该置信度阈值能够被调整。
61.返回参考图6,在606处检测到人类的情况下,系统能够在608处执行特征提取应用或模型。在这个步骤处,针对其动作识别从每个人员提取相关视觉特征,以便识别打喷嚏、咳嗽或将指示出潜在疾病的其它的此类运动。为了捕捉时空特征,能够将二维(2d)卷积网络(convnet)膨胀为三维(3d)卷积网络,并且能够使用膨胀的3d convnet(i3d)特征。超深图像分类convnet的过滤器和池核能够被扩展到3d,从而使得可以从图像或视频学习无缝的时空特征提取器。替代性地,深度卷积网络,如vgg16(simonyan、karen和andrew zisserman,《用于大规模图像识别的超深卷积网络(very deep convolutional networks for large-scale image recognition)》,arxiv preprint arxiv:1409.1556 (2014))或resnet(he、kaiming等,《用于图像识别的深度残差学习(deep residual learning for image recognition)》,proceedings of the ieee conference on computer vision and pattern recognition (2016)),能够被用于提取空间特征并且之后被集成到基于lstm的网络以进行动作识别。滑动窗口可以被用于捕捉在该时间窗口内的每个人的特征。同样地,如openface(amos、brandon、bartosz ludwiczuk和mahadev satyanarayanan,《openface:一个带有移动应用程序的通用人脸识别库(openface: a general-purpose face recognition library with mobile applications)》,cmu school of computer science 6 (2016))或者deepface(taigman、yaniv等人《deepface:缩小人脸验证中与人类水平的差距(deepface: closing the gap to human-level performance in face verification)》,proceedings of the ieee conference on computer vision and pattern recognition, 2014)的神经网络能够被用于捕捉面部特征。通过使用这些特征提取系统,面部特征能够被用于活动识别和检测附加健康参数。例如,面部特征提取系统能够提取人类面部特征或身体特征,其之后被用于检测潜在疾病,诸如打喷嚏、咳嗽、流鼻涕、眼睛发红、疲劳、皮疹或身体疼痛。因此,人的鼻子、眼睛、嘴和手可以在608处经由特征提取模型被检测并提取。
62.能够使用隐私保护技术来保护占用者的隐私。在一种实施例中,捕捉的图像的像素以面部识别算法无法识别人的方式进行变换,但用于活动识别的特征受这种变换的影响最小。
63.在提取面部和身体特征的情况下,能够在610处执行活动识别步骤。在这个步骤处,通过使用提取的视觉特征,分类器被用于分类人的活动。为此目的,能够在提取步骤608中提取的特征图旁边添加完全连接的层。替代性地,能够使用支持向量机(svm)、随机森林或多层感知器分类器。分类器可以将视觉事件分类成下列感兴趣事件:打喷嚏、咳嗽、呼吸急促、流鼻涕、流泪、眼睛发红、疲劳、身体疼痛和/或呕吐。这可以被称为执行疾病检测操作,或者更广义地,活动识别模型。模型能够使用机器学习系统,诸如这里描述的那些系统。
64.作为示例,图8示出了显示一个人员正在打喷嚏的帧的序列。当人打喷嚏或咳嗽时,能够通过检测事件发生期间该人员的手是否遮住了该人员的脸并结合头部的运动来细分该活动。这是通过使用图像数据的疾病检测操作的输出的一种示例。
65.分类器也可以通过指示人员在擦拭或喷洒该区域的事件,将视觉事件分类为某人在为该区域消毒。这能够别记录为积极清洁事件,这能够重置时间序列聚合,或者这能够被用于更新存储在系统中的区域清洁度。
66.返回参考图6,系统可以在612处采用定位。在这个步骤处,通过使用感兴趣人员的边界框的坐标,估计事件位置。这能够通过在视野内对人员相对于他或她周围环境的深度分析来实现。这能够通过单个图像捕捉设备或者多个图像捕捉设备(为了附加的置信度)来执行。可以提供在先步骤来校准图像捕捉设备,以便映射每个像素如何与其物理真实世界位置相关。图像源122中的一个或多个可以配备机载深度检测,以致能够确定在图像内的任何给定目标的深度(例如,与图像源的距离)。替代性地,这样的信息能够通过分析图像的非机载系统确定,其具有已知变量,诸如图像源的位置、图像中某些特征之间的距离等。
67.在614处,系统之后执行类似于图4中的步骤414的时间序列聚合。在这个步骤处,贯穿一天检测感兴趣的事件,并且其被聚合以判断特定区域的清洁度。例如,处理器能够计算并存储在视野的每个区域中每个捕捉的潜在疾病事件(例如,咳嗽、打喷嚏等)发生多少次。这可以在每个传感器处被本地计算或者在云中被计算。在检测到某人已经清洁了该区域之后,值能够被自动重置。替代性地,或者附加地,在没有人类活动的情况下已经经过了特定时间量(例如,12小时或者整夜)之后值能够被重置或者其能够被手动重置。
68.在已经执行时间序列聚合之后,信息能够在616处经由可视化被呈现给用户。可视化能够类似于上文描述的416的可视化。具体地,图像捕捉设备的视野的图像能够覆盖有“热图”,该热图基于在这些区域中检测到的潜在疾病事件的数量在强度或颜色上发生变化。
69.在另一实施例中,除了rgb照相机之外,还能够使用热照相机作为附加的图像捕捉设备。热照相机能够被用于估计检测到的人类的身体温度以检测潜在发热,并相应地增强上述分析。
70.图9和图10示出了用于在使用音频和视觉数据的融合的同时检测指示占用者疾病症状的事件、定位事件并以可视化显示相关信息的系统的实施例的流程图。在图9和图10的实施例中,图像数据102和音频数据104被融合在一起以改善系统的识别能力。上文描述的传感器可以包括音频源和图像源二者。替代性地,受试区域可以装备有单独地遍布该区域
的音频源和图像源的阵列。
71.参考图9,示出使用音频和图像数据的融合来检测并显示占用者疾病症状的系统900的实施例。关于音频数据104,声学信号在402处被获得并且在404处被预处理,并且在406处执行特征提取。这些步骤类似于参考图4描述的那些步骤。关于图像数据102,在602处从图像源(例如,照相机)捕捉图像。图像在604处被预处理,并且在606处进行人类检测并且在608处进行特征提取。这些步骤类似于参考图6描述的那些步骤。
72.在902处添加融合层以将来自步骤402、404和406的音频数据与来自步骤602、604、606和608的图像数据融合。能够实施融合来确认或提高获得的数据的置信度水平。例如,从单个个体检测到的占用者疾病症状数据的子集可能指示出该个体患有疾病,但并非所有个体都将指示出疾病的所有可能症状。此外,某些症状指示可能没有其它症状指示严重。疾病症状确定的准确性可以使用概率标度来指示。确定概率标度所需的信息可以从各种资源中的任何资源获得。
73.在融合音频和图像数据时,可以提高准确性。例如,如果来自音频源的确定的咳嗽到达角与来自与该咳嗽相关联的颤动头部的图像源的位置一致,则可确定咳嗽数据是准确和可靠的。在特征融合的情况下,通过使用融合的特征图来检测感兴趣事件。在融合下游,能够在904处执行活动识别的步骤,其类似于上文描述的步骤610,除了现在音频的置信度被添加到视频。例如,如果这里描述且图8所示的图像信号处理产生某种疾病症状,则融合的音频数据能够通过将由图像处理识别的活动与例如由喷嚏的声音的音频源实现的音频对应来确认疾病症状的存在。
74.然后系统执行如上所述的aoa估计906、定位908、时间序列聚合910和可视化912。
75.图10示出了用于捕捉音频和图像数据、处理所述数据、融合数据并且由融合的数构建可视化的系统1000的实施例。在此,针对一致性比较并检查来自每种模态(例如,麦克风和照相机)的检测。例如,在402处捕捉声学信号,在404处进行预处理,在406处进行特征提取,在408处进行分类,在410处进行aoa估计的可选步骤,并且在412处进行定位。同时,在602处获得照相机图像,在604处执行对这些图像的预处理,在606处实施人类检测,在608处实施特征提取,在610处执行活动识别,并且在612处执行定位。在1002处的融合步骤中,考虑每种模态的置信度得分以滤出不正确的检测。例如,为了将事件标志为已经发生疾病症状的事件,音频和照相机数据二者必须均具有高于特定阈值的置信度。在另一实施例中,可以实现滑动标度,其中基于一种模态(例如麦克风)的置信度的增加,可接受另一模态(例如照相机)的较低阈值。随着一种数据源更可信,另一数据源的积极的疾病症状检测的阈值可以降低。
76.在融合信息或数据之后,在1004处执行融合数据的计时器序列聚合。基于融合数据的时间序列聚合,在1006处输出可视化。可视化能够是热图,如这里描述的热图。
77.这里公开的系统也能够使用雷达来操作,而不是使用音频和图像数据(或者与其结合)。图11示出了用于经由雷达检测指示占用者疾病症状的事件、定位事件并以可视化显示相关信息的系统1100的实施例的流程图。诸如这里描述的雷达源126的雷达设备使得能够感知生命体征参数,诸如呼吸率、发热率、心率变异性和人类情绪,否则使用本文描述的音频和图像技术可能无法获得这些参数。
78.另外,雷达源126也能够检测咳嗽、打喷嚏、突然跌倒或指示出潜在疾病症状的其
它此类运动。咳嗽和打喷嚏引入了胸部运动、上身运动或全身运动的独特模式,其能够由雷达源126检测并按本文所述进行处理。生命体征也能够被用于区分诸如季节性过敏、哮喘等的良性病例与实际疾病。换言之,如果雷达源126也未检测到偏离既定规范的偏离的心率、呼吸率、胸部运动等,则单独检测到的喷嚏可能不保证潜在疾病的标志。
79.系统首先检测目标人员的位置。位置信息能够使用雷达源通过距离和角度估计来获得。从目标人员反射的雷达信号能够以无接触方式捕捉这样的身体运动。借助于信号处理技术和/或机器学习模型,能够检测到咳嗽、打喷嚏或其它疾病症状事件。系统也在目标人员的疾病症状之间进行映射。
80.系统1100首先获得雷达基带信号。一个或多个雷达源126被部署并安装在用于进行占用者检测的期望位置处,诸如车队的车辆。雷达源126能够包括红外线(ir)雷达和调频连续波(fmcw)雷达。在部署期间也记录雷达源126的位置。通过将雷达传感器连接到数据记录设备来执行对原始雷达信号的获取,以获得并记录雷达数据106。原始雷达信号可以包括i和q样本、振幅和/或相位信息。
81.在获得基带雷达信号且获得并记录雷达数据106的情况下,在1104处能够发生对数据的预处理。在这个步骤处,系统执行一个或多个方法,包括去噪、对准、滤波、处理缺失数据和上采样。这能够更好地调节数据以用于人类检测、特征提取、生命体征识别的主要处理步骤。
82.在1106处,系统基于预处理的雷达数据进行人类检测。鉴于已知雷达传感器位置,提取2d或3d空间中的一个或多个占用者目标的位置。通过在传感器处接收反射回的无线电波来获得雷达数据。如此,人类检测的步骤能够例如通过基于反射的无线电波估计距目标占用者的距离和/或角度来完成。人类检测可以通过各种方法来完成,所述方法中的一种被公开于2014年international journal of microwave science and technology第2014卷文章id为958905的ram m. narayanan、sonny smith、kyle a. gallagher的《用于探测人类和表征人类活动的多频雷达系统,用于短程穿墙和远程树叶穿透应用(a multifrequency radar system for detecting humans and characterizing human activities for short-range through-wall and long-range foliage penetration applications)》中。
83.在1108处,能够基于雷达数据从检测到的人类提取特征。特征包括时域特征、频域特征和空间域特征。还可以使用基于雷达截面(rcs)测量的时间序列的梅林变换的雷达人类识别的特征提取程序;推导并分析在目标散射在交叉范围内的分布与rcs幅值之间的数学关系,并且使用序列法提取rcs特征。通过使用时域特征,提取能够识别需要随时间推移观察信号模式的呼吸率、心率等。同样地,能够提取人类的可识别区域,例如眼睛、鼻子、嘴、手、胸部等,将分析其中的疾病症状。例如,用于疾病检测的手捂住脸和突然的头部运动首先需要识别手和脸。
84.在提取特征的情况下,能够在1110处识别生命体征(例如,心率、呼吸率等)和突然的运动(例如,咳嗽、打喷嚏、摔倒等)。这能够使用分类模型(诸如参考音频和图像分类描述的那些模型)来执行,该分类模型能够以显著的置信度来预测和估计目标占用者正在进行什么活动、生命体征或突然的运动。这能够包括信号处理和/或机器学习模型,其可以包括但不限于快速傅里叶变换(fft)、独立分量分析(ica)、主分量分析(pca)、非负矩阵分解(nmf)和小波变换分类模型。
85.虽然已经存在雷达来提供定位,不过在1112处的定位的步骤能够包括基于任何潜在异常来定位目标占用者。例如,如果雷达源126中的一个存在不希望的噪声或其它错误,则能够使用一个或多个其它雷达源来确定具有疾病症状的目标占用者的位置。
86.在1114和1116处,能够分别执行计时器序列聚合和可视化。这些步骤能够类似于本文描述的步骤,诸如步骤414、416、614、616、910、912、1004和1006。例如,如上所述的热图等能够被显示给用户或占用者,其将阴影颜色叠加到占用者所处的位置的图像。
87.图12示出了用于经由雷达检测指示占用者疾病症状的事件、定位事件并以可视化显示相关信息的另一系统1200的实施例的流程图。系统1200是上述系统1100的简化版本,其包括许多相同的步骤。在这种实施例中,去除了特征提取,并且单独地利用活动识别1210。在1210处,该步骤涉及突然运动检测,诸如咳嗽/打喷嚏或跌倒检测。分类模型将预测当前事件是咳嗽或打喷嚏或跌倒或其它类似的疾病症状事件。
88.图13和图14分别示出了用于经由雷达检测指示占用者疾病症状的事件、定位事件并以可视化显示相关信息的其它系统1300、1400的实施例的附加流程图。在图13中,活动识别1210与1310处的生命体征识别分开,并且之后二者在1112处的定位步骤中合并。这能够提供单独的雷达传感器,其中一个专用于活动识别并且另一个专用于生命体征识别。在是更简化的实施例的图14中,系统1400具有移除特征提取步骤1108并将活动和生命体征识别组合到1110的单个步骤中的选项。
89.图15示出了用于经由音频、图像和雷达检测指示占用者疾病症状的事件、融合来自所有三种类型的传感器的信息并且基于融合数据输出可视化的系统的实施例的流程图。一个或多个图像源122被用于在602处捕捉图像,并且然后图1的相关联的处理器和结构中的一个或多个被用于预处理604、人类检测606和特征提取608。一个或多个音频源124被用于在402处获取声学信号,并且然后图1的相关联的处理器和结构中的一个或多个被用于预处理404和特征提取406。一个或多个雷达源126被用于建立射频基带信号1112,并且然后图1的相关联的处理器和结构中的一个或多个被用于预处理1104、人类检测1106以及可选地特征提取1108。
90.系统1500包括融合的步骤1502,其中音频、图像和雷达数据全部被融合在一起以生成对占用者潜在疾病的全面检查和分析。能够通过处理音频数据和图像数据来针对准确性来检查雷达数据;能够通过与雷达数据和音频数据进行比较来针对准确性来检查图像数据;能够通过将其与雷达数据和图像数据进行比较来针对准确性来检查音频数据。这个步骤可以类似于上文描述的融合步骤902,除了添加了雷达数据。
91.在1502处的特征的融合结果之后被传递到1110,在此如上所述从雷达数据识别活动和/或生命体征。之后,执行在1504处的定位的步骤以及在1506处的时间序列聚合和融合数据的可视化1508。通过将雷达数据与音频和图像数据融合,能够向用户提供更全面且准确的可视化。
92.图16示出了根据类似实施例的系统1600,除了在412、612和1112处执行定位之后发生信息的融合1602。这种实施例示出了,本公开设想到的信号处理和融合的各个步骤的多种架构和布局;数据的融合能够在沿着处理进程的时间的许多变型中发生。
93.这里描述的技术能够通过周围区域中的附加系统来证实。例如,如果这里描述的技术被用于客用车辆中,则处理器能够访问来自其它车辆系统的数据。在一种实施例中,车
辆的座位可以具有重量传感器;如果在检测到打喷嚏或咳嗽的同时在座位上的重量突然波动,则这可以进一步有助于这里描述的系统的准确性(例如,提供精神健全检查)。
94.本文所公开的过程、方法或算法可交付到能够包括任何现有的可编程电子控制单元或专用电子控制单元的处理设备、控制器或计算机或者由其实现。类似地,过程、方法或算法能够以多种形式被存储为可由控制器或计算机执行的数据和指令,所述形式包括但不限于永久存储在不可写存储介质(如rom设备)上的信息以及可变存储在可写存储介质(诸如软盘、磁带、cd、ram设备和其它磁性和光学介质)上的信息。过程、方法或算法也能够在软件可执行对象中实现。替代性地,过程、方法或算法能够通过使用合适的硬件部件被整体或部分地实现,所述硬件部件例如是专用集成电路(asic)、现场可编程门阵列(fpga)、状态机、控制器或其它硬件部件或设备或者硬件、软件和固件部件的组合。
95.虽然在上文描述了示例性实施例,不过这些实施例不试图描述由权利要求所涵盖的所有可能的形式。说明书中使用的词语是描述性词语而不是限制性的,并且应该理解的是能够在不背离本公开的精神和范围的情况下做出各种修改。如之前所述,各种实施例的特征能够组合以形成本发明的没有被明确描述或图释的进一步实施例。尽管可能已经将各种实施例描述为关于一个或多个期望特性优于其它实施例或现有技术实施例或关于一个或多个期望特性提供优点,但本领域普通技术人员认识到,一个或多个特征或特性可以被折衷以实现期望的总体系统属性,这取决于具体的应用和实施方式。这些属性可以包括但不限于成本、强度、耐用性、寿命周期成本、适销性、外观、包装、尺寸、适用性、重量、可制造性、易于组装等。因此,就一个或多个特性而言,即使任何实施例被描述为不如其它实施例或现有技术实施方式那么期望,这些实施例也不在本发明的范围之外,并且对于具体应用来说能够是期望的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1