一种基于强化学习的关系抽取方法
1.本发明涉及自然语言处理技术领域,具体涉及一种基于强化学习的关系抽取方法。
背景技术:
2.信息抽取是自然语言处理中的一项基本任务,通过对非结构化文本进行处理抽取结构化信息,作为后续自然语言处理任务的输入。关系抽取是信息抽取技术中的重要内容,对句子中两个实体之间的语义关系进行分类,自动识别出一对概念和联系这对概念的语义关系,构成三元组,可以用来进行知识图谱的构建。传统的关系抽取研究方法主要分为有监督、半监督、弱监督、无监督四类,有监督的关系抽取算法是目前研究的主流方向。
3.关系抽取的研究对象主要包括以下几类,1)从互联网上获取的结构化数据;2)从互联网各种网页上爬取的半结构化数据;3)广泛存在的非结构化文本数据。有监督关系抽取算法已经取得了较好的性能,但是此方法严重依赖于词性标注等nlp标注工具,这些工具的误差会传递到关系抽取任务中,并且标注大量的语料须要耗费大量的人力,而在实际应用中的数据规模往往较大。
4.基于远程监督的关系抽取算法解决了需要大量标注数据的问题,可以利用现有知识库标注文本数据,并且可以迁移现有的有监督的方法,但是远程监督的启发式匹配会产生大量噪声数据和误差传播等问题。
技术实现要素:
5.本发明的目的在于针对上述现有技术中远程监督关系抽取模型的噪声数据和粗粒度监督信号问题,提出一种基于强化学习的关系抽取方法,提高关系抽取的性能。
6.实现本发明目的的技术解决方案如下:一种基于强化学习的关系抽取方法,包括以下步骤:
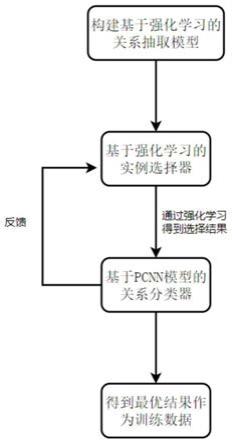
7.步骤s1:构建基于强化学习的关系抽取模型框架,所述关系抽取模型框架包括基于强化学习的实例选择器和基于pcnn模型的关系分类器;
8.步骤s2:所述基于强化学习的实例选择器通过强化学习过程得到选择结果,所述选择结果为相同实体对句子组成的包中最能表达包标签的句子;
9.步骤s3:将所述选择结果输入到所述基于pcnn模型的关系分类器,根据输入的句子识别出表达相同关系的语句,对所述基于强化学习的实例选择器进行反馈;
10.步骤s4:所述基于强化学习的实例选择器根据反馈更新策略函数选择句子,用选择的句子训练基于pcnn模型的关系分类器,优化实例的选择和关系分类过程;
11.步骤s5:最终选择出最能代表关系标签的句子作为所述基于强化学习的关系抽取模型的训练数据,减少远程监督语料库的噪声和粗粒度问题对关系抽取的影响。
12.本发明与现有技术相比,其显著优点为:(1)由基于强化学习的实例选择器和基于pcnn模型的关系分类器构成关系抽取模型,通过对关系分类器和实例选择器联合训练,优
化实例的选择和关系分类过程;(2)通过强化学习的方法促进实例选择器选择出最能表达关系的句子,即在包含相同实体对的句子构成的包中选取最能表达包关系标签的语句,减少了远程监督关系抽取模型中噪声数据和粗粒度监督信号问题对关系抽取模型性能的影响,提高了关系抽取的性能。
附图说明
13.图1为本发明的基于强化学习的关系抽取方法的主要流程示意图。
14.图2为本发明的基于强化学习的关系抽取方法的模型结构。
15.图3为本发明的基于强化学习的实例选择器的框架图。
具体实施方式
16.本发明基于强化学习的关系抽取方法,包括以下步骤:
17.步骤s1:构建基于强化学习的关系抽取模型框架,所述关系抽取模型框架包括基于强化学习的实例选择器和基于pcnn模型的关系分类器;
18.步骤s2:所述基于强化学习的实例选择器通过强化学习过程得到选择结果,所述选择结果为相同实体对句子组成的包中最能表达包标签的句子;
19.步骤s3:将所述选择结果输入到所述基于pcnn模型的关系分类器,根据输入的句子识别出表达相同关系的语句,对所述基于强化学习的实例选择器进行反馈;
20.步骤s4:所述基于强化学习的实例选择器根据反馈更新策略函数选择句子,用选择的句子训练基于pcnn模型的关系分类器,优化实例的选择和关系分类过程;
21.步骤s5:最终选择出最能代表关系标签的句子作为所述基于强化学习的关系抽取模型的训练数据,减少远程监督语料库的噪声和粗粒度问题对关系抽取的影响。
22.进一步地,所述步骤s1中,基于强化学习的实例选择器还包括状态、行为、回报;
23.所述状态是用于表达出句子语义,为智能体agent提供出选择句子的证据;
24.所述行为是指agent在不同环境时采取的动作;
25.所述回报是用于帮助agent选出正确的行为。
26.进一步地,所述步骤s1中,基于pcnn模型的关系分类器使用s={w1,w2,w3,...,wn}来表示句子,其中的n代表单词的数量,即句子的长度;wi代表句子中的第i个单词,单词编码包括词向量和位置向量;首先对句子编码进行卷积操作,再对每个滤波器进行分段池化操作,使用vs来表示句子的编码,给定一个句子编码s,定义使用softmax的分类器:其中|r|是关系总数,k是关系计数编号,分别表示关系ri、rk的置信度,且o=wr(sod)+br,wr是转化向量,代表对应特征预测特定关系的权重,so为给定句子编码,d是代表正则化的dropout层,br是偏执向量,p(ri|s,θ)表示语句s在θ作为参数时对于关系ri的置信度,k为句子计数编号。
27.进一步地,所述状态、行为的表示方法如下:
28.所述状态的表示公式为s=[e1;e2;s
pre
;p(r|s
pre
;θ);s
cur
p(r|s
cur
;θ)],其中符号[;]代表串联操作,e1,e2表示目标实体对,s
pre
表示先前语句向量,s
cur
表示当前语句向量,p(r|s
pre
;θ)表示语句s在θ作为参数时对所有关系的置信度,r为语句关系,θ为权值参数;
[0029]
所述行为a={u,p},u表示agent控制的行为,u∈{0,1},0代表保持之前的关系标签,1代表使用当前句子的标签;p∈{0,1}是指是否提前停止搜索行为,0代表继续搜索,1代表提前停止搜索,由于构造了强化模型的第二个行为p,会在相应的情况下提前停止搜索,在语句包规模较大时可以提高所述基于强化学习的实例选择器的性能,出现停止操作的行为有两种情况:
[0030]
第一种是所有的句子都已经处理;
[0031]
第二种是agent有足够的信息证明已经得到了最能表达选定关系的语句;
[0032]
agent通过计算来决定最优的行为,计算值用q(st,a)表示,代表在st状态下动作a的价值,由st状态下行为u和行为p的价值组成,即q(st,u)和q(st,p)两个部分,最终的行为a
*
等于argmaxaq(st,a);q函数作为一个引导者,指引agent获得更高的累积回报。
[0033]
进一步地,所述步骤s2中,强化学习的步骤具体包括:
[0034]
步骤s21:对于训练包b={(e1,e2),(r1,...,rl),{s1,...,sn}},e1,e2表示目标实体对,(r1,...,r
l
)代表该实体对在知识库中表达的关系标签,{s1,...,sn}代表句子集合,定义agent根据某个策略执行一系列行为到结束就为一个episode,启动n个episode,每个episode代表一个关系标签,表示为ep1,ep2,...,epn,初始状态为其中两个0分别代表无选择语义特征和无置信度,p(r|s1,θ)代表对于句子s1中每个关系的置信度;
[0035]
步骤s22:强化学习的agent会根据q(st,a)采取最优的行为,最终的目的是选择最能表达目的关系标签的句子;
[0036]
步骤s23:当多个episode都选择当前语句作为选择语句时,agent选择q(st,u=1)值最高的句子,更新此句子为选择的句子,剩余的更新过程将被禁止;
[0037]
步骤s24:当每个包的初始状态都一样时,采用启发式的初始化的方式,首先从包中找到t个句子,对于首个句子,计算p(r|s1,θ)对包中每个关系的置信度,将置信度最高的关系标签设为此句子的关系标签,然后将该句子赋予候选关系中置信度最高的关系r
*
←
argmaxrp(r|s1,θ),并且把这个关系标签所对应的episode的初始状态修改为[e1;e2;s1;p(r|s1,θ);s
l+1
;p(r|s
l+1
,θ)];
[0038]
步骤s25:根据剩余关系处理第二个句子,重复操作直到包中的句子都被这样处理。
[0039]
进一步地,所述步骤s4中,所述训练为基于强化学习的实例选择器和基于pcnn模型的关系分类器的联合训练,关系分类器的输入为步骤s2中选择出的最能表达包关系标签的句子,从而对实例选择过程和关系分类过程进行优化。
[0040]
下面参照附图来描述本发明的优选实施方式。
[0041]
结合图1~图3,一种基于增强学习的关系抽取模型,包括以下步骤:
[0042]
步骤s1:构建基于强化学习的关系抽取模型框架;所述关系抽取模型框架包括基于强化学习的实例选择器和基于pcnn模型的关系分类器;
[0043]
步骤s2:所述基于强化学习的实例选择器通过强化学习过程得到选择结果,所述选择结果为相同实体对句子组成的包中最能表达包标签的句子;
[0044]
步骤s3:将所述选择结果输入到所述关系分类器,根据输入的句子识别出表达相
同关系的语句,对所述实例选择器进行反馈;
[0045]
步骤s4:所述实例选择器根据反馈更新策略函数选择句子,用选择的句子训练出更好的关系分类器,优化实例的选择和关系分类过程;
[0046]
步骤s5:最终选择出最能代表关系标签的句子作为所述基于强化学习的关系抽取模型的训练数据,减少远程监督语料库的噪声和粗粒度问题对关系抽取的影响。
[0047]
作为优选例,所述步骤s1中,基于强化学习的实例选择器还包括状态、行为、回报;
[0048]
所述状态是用于表达出句子语义,为智能体agent提供出选择句子的证据;
[0049]
所述行为是指agent在不同环境时采取的动作;
[0050]
所述回报是用于帮助agent选出正确的行为。
[0051]
作为优选例,所述步骤s1中,基于pcnn模型的关系分类器使用s={w1,w2,w3,...,wn}来表示句子,其中的n代表单词的数量,即句子的长度,wi代表句子中的第i个单词,单词编码包括词向量和位置向量;
[0052]
首先对句子编码进行卷积操作,再对每个滤波器进行分段池化操作;
[0053]
使用vs来表示句子的编码,给定一个句子编码s,定义使用sofimax的分类器:其中|r|是关系总数,o=wr(sod)+br,wr是转化向量,代表对应特征预测特定关系的权重。d是代表正则化的dropout层,br是偏执向量。
[0054]
作为优选例,所述状态、行为、回报的表示方法如下:
[0055]
所述状态的表示公式为s=[e1;e2;s
pre
;p(r|s
pre
;θ);s
cur
p(r|s
cur
;θ)],其中符号代表串联操作,e1,e2表示目标实体对,s
pre
表示先前语句向量,s
cur
表示当前语句向量,p(r|s
pre
;θ)表示语句s在θ作为参数时对所有关系的置信度;
[0056]
所述行为a={u,p},u表示agent控制的行为,在0和1之间选取一个值,0代表保持之前的关系标签,1代表使用当前句子的标签;p是指是否提前停止搜索行为,在语句包规模较大时可以提高所述基于强化学习的实例选择器的性能,出现停止操作的行为有两种情况:
[0057]
第一种是所有的句子都已经处理;
[0058]
第二种是agent有足够的信息证明已经得到了最能表达选定关系的语句;
[0059]
agent通过计算来决定最优的行为,计算值用q(st,a)表示,包括q(st,u)和q(st,p)两个部分,最终的行为a
*
等于argmaxaq(st,a);q函数作为一个引导者,指引agent获得更高的累积回报。
[0060]
使用多层感知器来定义q函数,
[0061][0062]
其中,f()是指非线性函数,w是中间媒介矩阵进一步编码状态特征,wu和w
p
是从状态到行为的映射矩阵,bu和b
p
是偏置向量。
[0063]
所述回报是为了帮助agent选择正确的行为,为了解决粗粒度的问题,应该重点关注语句级别,语句的语义表达对关系的影响应该被放在首位;
[0064]
当包中的语句连续输入的时候,agent根据当前句子和先前被选中的句子对目标关系的偏差程度,每个episode中的agent的目标是使得整体获得最大化的回报,最后所有
的episode获取的回报构成了总的整体回报;
[0065]
所述回报应该能够帮助agent获得最能代表目标关系的句子,输入语句不同时计算回报的方式也不同;
[0066]
例如当agent保留当前句子时候,回报值等于当前语句与之前选择句子的关系置信度之差,但是当episode停止,agent选择当前处理的语句,当前语句的置信度最高的关系标签并不是目标关系的时候,回报等于对目标关系的置信度减去其本身最高标签的置信度,这时会给agent一个负反馈,会让agent倾向于选择正确的语句;
[0067]
根据上述分析,定义reward函数
[0068][0069]
其中t表示episode的终止状态,episode选定的关系标签是rt。
[0070]
作为优选例,所述步骤s2中,所述强化学习的步骤具体包括:
[0071]
步骤s21:对于训练包b={(e1,e2),(r1,...,rl),{s1,...,sn}},启动n个episode,每个episode代表一个关系标签,表示为ep1,ep2,
…
,epn,初始状态为其中两个0分别代表无选择语义特征和无置信度;
[0072]
步骤s22:强化学习的agent会根据q(st,a)采取最优的行为,最终的目的是选择最能表达目的关系标签的句子;
[0073]
步骤s23:当多个episode都选择当前语句作为选择语句时,agent选择q(st,u=1)值最高的句子,更新此句子为选择的句子,剩余的更新过程将被禁止;
[0074]
步骤s24:当每个包的初始状态都一样时,采用启发式的初始化的方式,首先从包中找到t个句子,对于首个句子,计算p(r|s1,θ)对包中每个关系的置信度,将置信度最高的关系标签设为此句子的关系标签,然后将该句子赋予候选关系中置信度最高的关系r
*
←
argmaxrp(r|s1,θ),并且把这个关系标签所对应的episode的初始状态修改为[e1;e2;s1;p(r|s1,θ);s
l+1
;p(r|s
l+1
,θ)];
[0075]
步骤s25:根据剩余关系处理第二个句子,重复操作直到包中的句子都被这样处理。
[0076]
作为优选例,所述步骤s4中,所述训练为所述基于强化学习的实例选择器和基于pcnn模型的关系分类器的联合训练,对实例选择过程和关系分类过程进行优化。
[0077]
实验验证对比如下:
[0078]
为了验证本发明的有效性,使用远程监督关系抽取常见的方法进行实验对比,有基于特征的mintz方法,是首个实现大规模远程监督关系抽取模型,hoffmann提出的概率图模型,以及miml模型。此外,还选用神经网络模型pcnn、cnn+att作为对比,并与feng提出的基于策略的强化学习模型对比,本发明的基于强化学习的关系抽取方法在实验中称为pcnn+rl,主要解决数据噪声和粗粒度信号问题。
[0079]
表1本发明模型pcnn+rl与神经网络关系抽取模型比较
[0080][0081]
表1是pcnn+rl模型与先验的神经网络进行对比,这些模型的不同主要在于对远程监督关系抽取的噪声数据处理方式。从结果中可以看出:
[0082]
(1)pcnn+rl的表现优于常见的基准方法,说明本发明提出的基于强化学习的关系抽取方法改善了关系抽取的性能
[0083]
(2)在同样的召回率情况下,pcnn模型的性能最低,因为pcnn没有很好的处理数据集中的噪声问题。
[0084]
(3)与feng的强化学习方法相比,pcnn+rl表现了更高的性能。因为feng的方法的回报函数是基于包级别的,pcnn+rl回报函数是基于句级别的,可以产生细粒度的监督信号,帮助agent在环境选择正确的action,最终模型会选取最能表达包标签的句子,减少噪声数据和粗粒度信号对关系抽取模型的影响。
[0085]
表2本发明模型pcnn+rl与基于特征的方法比较
[0086][0087]
表2显示的是pcnn+rl和基于特征方法比较的结果。认为基于特征的方法(mintz,hoffmann,surdeanu)使用从nlp工具中提取出来的特征,这样会不可避免地遭受错误的传递和累积。不同于传统方法,pcnn+rl直接使用分段卷积神经网络抽取语义特征,能够取得更好的性能。
[0088]
此外,使用p@n来评价模型,具体做法是将预测的结果按照置信度进行降序排序,取出前n个,并检查它们的正确性。表3显示了各种方法的p@n得分。从表中可以得到:
[0089]
(1)对于p@100,p@200,p@300和p@500,pcnn+rl在它们中间获得了最高的平均准确率,说明pcnn+rl可以在混合的数据中选取有效的句子来作为训练实例,提升了抽取器生成准确的预测结果。
[0090]
(2)feng比pcnn模型的方法表现好,但是弱于pcnn+rl。这个结果说明粗粒度的回报函数并不能够引导agent做出理想的行为决定,并且忽略多标签问题,会影响关系抽取模型的效果。
[0091]
表3关系抽取p@n得分
[0092][0093]
为了进一步验证模型的有效性,对训练实例进行研究,表4显示了两个多标签实例;
[0094]
表4训练语句的样例
[0095][0096]
在第一个样例中,feng的模型同时选择s1和s2作为关系标签“/locati-on/contains”和“/country/capital”的训练语句。但是只有s1表达了“/country/capital”,而s2则表达了“/location/contain”。这是因为feng的强化学习设计的状态(state)中没有关系信息,并且没有考虑多标签问题,导致了错误的标记数据。与feng的模型对比,借助启发式初始化,本发明的模型可以选择较为理想的语句。
[0097]
在样例二中,feng并没有发现s4明确表达的事实关系是:jane jacobs在toronto
去世了。产生这种现象的原因是,该模型没有使用置信度信息作为语句选择的依据,而语句信息在句子较长时,很难提供显著的有效信息,因为这部分句子包含过多的信息,稀释了原本有用的信息。
[0098]
此外,粗糙的回报函数不能够引导agent做出准确的语句级别的行为。与之相比,本发明的方法嵌入了置信度信息,并且开发了细粒度的回报函数,弥补了这些缺陷。因此,pcnn+rl能够选出s3作为关系
″
/person/place_lived”的训练语句,而s4作为关系“/decease_person/place_of_birth”的训练语句。
[0099]
本发明由基于强化学习的实例选择器和基于pcnn模型的关系分类器构成关系抽取模型,通过对关系分类器和实例选择器联合训练,优化实例的选择和关系分类过程;通过强化学习的方法促进实例选择器选择出最能表达关系的句子,即在包含相同实体对的句子构成的包中选取最能表达包关系标签的语句,减少了远程监督关系抽取模型中噪声数据和粗粒度监督信号问题对关系抽取模型性能的影响,提高了关系抽取的性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1