一种基于球形模糊集综合相似度的多属性决策方法
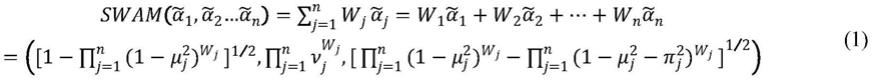
1.本发明提供一种基于球形模糊集综合相似度的多属性决策方法,涉及社会经济和工程技术领域中广泛存在的多属性决策问题,属于方案决策技术领域。
背景技术:
2.模糊集理论的提出使研究范围从精确领域拓展到了模糊领域,在诸多行业中都得到广泛应用。球形模糊集的引入允许决策者拥有更大的区域来表示隶属度,非隶属度和犹豫度,并且三元关系是非线性的,这比现有的线性关系更符合实际情况。现有的球形模糊多属性决策中,属性权重均是由决策者单独给出的球形模糊数形式,即属性主观权重,带有严重的主观性,不能完整且正确的反映各指标的重要性。在实际决策过程中,会出现排序结果违背事实情况。本发明提出一种基于球形模糊集综合相似度多属性决策方法用来计算属性客观权重,但是考虑到主观权重的表示方式为球形模糊数,客观权重的表示方式为数值,所以可以将主观加权决策矩阵和客观加权决策矩阵作线性加权处理得到加权决策矩阵,避免单一注重主观权重和客观权重,有利于提高评价结果的可信度,最后通过topsis方法进行择优和排序。
技术实现要素:
3.发明目的:针对属性客观权重信息未知的球形模糊多属性决策问题,为了综合考虑主观属性权重和客观属性权重对决策结果的影响,提出一种基于球形模糊集的决策对象综合相似度规划模型求解属性客观权重,采用两种指标:属性内平均相似度和属性间平均相似度。属性内平均相似度为同一属性下各备选之间的区别程度,属性间平均相似度为不同属性之间的区别程度,二者结合可以得到属性的综合相似度,进而得到属性客观权重。通过对主观加权决策矩阵和客观加权决策矩阵作线性加权处理得到加权决策矩阵,提高备选方案择优和排序的准确性。
4.为实现上述目的,如图1所述为本发明的基本流程图,该方法包括以下步骤:
5.s1:使用语言术语将决策者给出的判断进行表示,根据决策者的权重信息通过球形聚集算子构成球形模糊初始决策矩阵;
6.s2:由初始决策矩阵和决策者给出的球形模糊数形式的属性主观权重得到主观加权决策矩阵;
7.s3:分别计算属性间平均相似度和属性内相似度,通过综合相似度规划模型确定属性客观权重;
8.s4:由初始决策矩阵和属性客观权重得到客观加权决策矩阵;
9.s5:对主观加权决策矩阵和客观加权决策矩阵进行线性调整得到加权决策矩阵;
10.s6:通过得分函数得到球形模糊正理想解和负理想解;
11.s7:计算每个备选方案的分离度,相对接近系数并排序;
12.所述步骤s1中的球形模糊初始决策矩阵为y=(y
ij
)m×n,x为备选方案集合,有m个
备选方案:x1,x2,
…
,xm;c为属性集合,有n个属性:c1,c2,
…
,cn,其中y
ij
=(μ
ij
,v
ij
,π
ij
),μ
ij
表示方案xi满足属性cj的程度,v
ij
表示方案xi不满足属性cj的程度,π
ij
表示方案xi对属性cj的犹豫程度。球形聚集算子公式如下
13.(1)球形加权算术平均(swam)
[0014][0015]
(2)球形加权几何平均(swgm)
[0016][0017]
其中决策者权重信息w=(w1,w2,
…
,wn,)
t
,且对于球形模糊集对于球形模糊集
[0018]
所述步骤s2中主观加权决策矩阵s(w1)=(y
ij
)m×nwj,j=(1,2,
…
,n).其中w1为决策者所提供的球形模糊数形式的属性主观权重.
[0019]
所述步骤s3中的属性间平均相似度为bsj,表示第j个属性和其他属性之间的平均相似度,公式为
[0020][0021]
属性内平均相似度为wsj,表示第j个属性内的各方案之间的平均相似度,公式为
[0022][0023]
通过综合相似度规划模型得出求解权重系数
[0024][0025][0026]
其中csj是第j个属性中所包含的综合相似度,wsj是第j个属性内平均相似度,bsj为第j个属性与其他属性之间的平均相似度。
[0027]
权重向量最优解应使所有属性在权重向量作用下对综合相似度之和的加权最小。即应确定加权向量的最优解,以便在加权向量的作用下,所有属性与所有备选决策对象的综合相似度的倒数的加权和必须最大。
[0028]
通过求解优化模型,得到最优解
[0029][0030]
为了与传统的权重系数用法保持一致,对上述的最优解通过进行归一化处理,可以得到
[0031]
[0032]
所述步骤s4中客观加权决策矩阵o(w2)=(y
ij
)m×nwj,j=(1,2,
…
,n).其中w2为数值形式的属性客观权重.
[0033]
所述步骤s5中线性调整公式为
[0034]
so(w)=λs(w1)+(1-λ)o(w2),λ=0,0.1,
…1ꢀꢀꢀ
(8)
[0035]
考虑到主观权重的表示方式为球形模糊数,客观权重的表示方式为数值,所以可以将主观加权决策矩阵和客观加权决策矩阵作线性加权处理,避免了决策者对主观和客观的不同偏好从而影响最终的决策结果,有利于提高评价结果的可信度。其中λ为决策者的主观偏好,若λ》0.5说明决策者更重视决策者所给出的球形模糊数形式的主观权重信息;若λ《0.5说明决策者更重视客观数据所计算的权重信息。
[0036]
所述步骤s6中的得分函数为
[0037]
score(so
ij
)=(μ
ij
w-π
ij
w)
2-(v
ij
w-π
ij
w)2ꢀꢀꢀ
(9)
[0038]
正理想解为
[0039][0040][0041]
负理想解为
[0042][0043][0044]
所述步骤s7中的各备选方案的分离度为
[0045][0046][0046]
相对接近系数为
[0047][0048]
通过相对贴近度对备选方案进行排序和择优。
附图说明
[0049]
图1为本发明方法具体流程图;
具体实施方式
[0050]
实施例为便于比较,现用本发明方法应用于医院选址问题。评估5个地点(x1,x2,x3,x4,x5),选择标准有5个,分别为:安装成本(c1),靠近目标区域(c2),环境因素(c3),人口基础设施(c4),交通(c5)。在评估过程中,三个决策者(dm1,dm2,dm3,),并且根据决策者不同的经验水平,决策者的权重分别为(0.5,0.3,0.2),语言术语见表1。
[0051]
表1 语言术语及其对应的球形模糊数
[0052][0053]
使用上述方法进行处理和决策:
[0054]
步骤一:首先根据语言术语通过三个决策者得到dms的判断见表2。根据dms的权重,对这些判断进行聚集,构成的球形模糊初始决策矩阵y=(y
ij
)m×n如表3所示:
[0055]
表2 dms的判断
[0056][0057]
表3 swam初始决策矩阵
[0058][0059]
步骤二:根据sms给出的主观权重见表4,计算得到主观加权决策矩阵见表5
[0060]
表4 主观属性权重
[0061]
[0062]
表5 主观加权决策矩阵
[0063][0063]
步骤三:分别计算属性间平均相似度和属性内相似度,进而确定属性客观权重;
[0064]
计算属性之间的相似度见表6,得到计算属性间平均相似度
[0065][0066]
bs2=0.9352;bs3=0.9727;bs4=0.9081;bs5=0.9470
[0067]
表6 属性之间的相似度
[0068][0069]
计算得到属性内平均相似度
[0070][0071]
wd2=0.9721;wd3=0.8953;wd4=0.9147;wd5=0.9703
[0072]
计算权重系数
[0073]
cs1=0.7043;cs2=0.9091;cs3=0.8301;cs4=0.8306;cs5=0.9189
[0074]
ws1=0.2360;ws2=0.1828;ws3=0.2002;ws4=0.2001;ws5=0.1809
[0075]
步骤四:由初始决策矩阵和客观权重得到客观加权决策矩阵见表7;
[0076]
表7 客观加权决策矩阵
[0077][0078]
步骤五:对主观加权决策矩阵和客观加权决策矩阵进行线性调整,为了计算方便,将λ值设为0.5,即主观和客观偏好相等,得到加权决策矩阵见表8;
[0079]
表8 加权决策矩阵
[0080][0081]
步骤六:通过得分值确定球形模糊正理想解和负理想解;
[0082]
x
*
:{(0.5785 0.4242 0.2693),(0.5105 0.4971 0.2729),(0.5216 0.4817 0.2534),(0.2629 0.7604 0.3942),(0.4220 0.5867 0.3098)}
[0083]
x-:{(0.2706 0.7407 0.3444),(0.3834 0.6173 0.3592),(0.3281 0.6914 0.3183),(0.1860 0.8260 0.3616),(0.3572 0.6483 0.3554)}
[0084]
步骤七:计算每个备选方案与正理想解和负理想解之间的距离,计算close值并排序,结果如表9:
[0085]
表9 分离度,相对接近度和排序
[0086][0087]
根据close值结果表明,排序结果为y1》y3》y5》y4》y2.
[0088]
本发明不局限于以上所述的具体实施方式,以上所述仅为本发明的较佳实施案例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1