一种考虑制程差异的持久内存的分配方法
1.本发明涉及内存分配技术领域,尤其涉及一种考虑制程差异的持久内存的分配方法。
背景技术:
2.持久内存(persistent memory,pm)具有低延迟、高密度、大容量等优点,是动态随机存取存储器(dynamic random access memory,dram)的潜在替代对象。然而,与dram相比,pm的寿命远远不及dram。同时,pm内存单元具有巨大的制程差异,即电路的变化,例如底部电极接触直径、加热器厚度和存取晶体管长度。因此,持久内存单元的编程电流会发生变化,导致了持久内存单元的耐久性在生产过程中会发生变化,从而产生相对较弱和较强的内存单元,制程差异会带来pm页面间的耐久不均衡,使pm某些内存单元过早老化,导致其寿命更短。
3.内存分配器主要用于分配物理内存或虚拟内存,其目的在于对内存空间的管理和回收。基于pm耐久低的特性,现有的持久内存分配器会设计磨损均衡机制来延缓pm的老化。但大多数现有的pm内存分配忽略了页内磨损均衡,导致有些内存单元被磨损严重,仍然会减少pm设备的使用寿命。还有的磨损均衡的pm内存分配器不能感知存储单元的耐久差异,其磨损均衡算法并不一定能使其磨损得更均衡。因为不能感知耐久差异的磨损均衡算法可能导致耐久低的内存单元被过度磨损,也会导致pm的使用寿命被明显缩短。
技术实现要素:
4.本发明提供一种考虑制程差异的持久内存的分配方法,解决的技术问题在于:如何在对持久内存进行内存分配时,克服持久内存的制程差异所带来的耐久不均衡的问题,使得各个内存单元被均匀磨损,以充分延长pm的使用寿命。
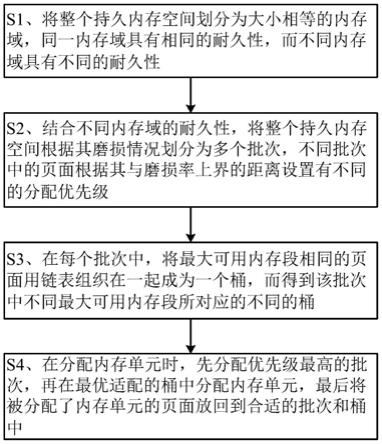
5.为解决以上技术问题,本发明提供一种考虑制程差异的持久内存的分配方法,包括步骤:
6.s1、将整个持久内存空间划分为大小相等的内存域,同一内存域具有相同的耐久性,而不同内存域具有不同的耐久性;
7.s2、结合不同内存域的耐久性,将整个持久内存空间根据其磨损情况划分为多个批次,不同批次中的页面根据其与磨损率上界的距离设置有不同的分配优先级;
8.s3、在每个批次中,将最大可用内存段相同的页面用链表组织在一起成为一个桶,而得到该批次中不同最大可用内存段所对应的不同的桶;
9.s4、在分配内存单元时,先分配优先级最高的批次,再在最优适配的桶中分配内存单元,最后将被分配了内存单元的页面放回到合适的批次和桶中。
10.进一步地,在步骤s2中,页面与磨损率上界的距离定义为页面到磨损率上界的可磨损次数wt,计算方式为:
[0011][0012]
其中,t表示所有页面统一的磨损率上界,e
max
和e
min
分别表示持久内存空间中耐久最大和最小的内存域的磨损次数的理论上限,d
num
表示内存域的数量,d
x
表示该页面所在内存域的序号,c表示该页面的平均磨损次数。
[0013]
进一步地,在所述步骤s2中,还包括步骤:
[0014]
为了记录每个批次的情况,用一个指针指向该批次所在的逻辑空间,用第一个变量记录该批次中页面的数量,用第二个变量记录该批次到磨损率上界的可磨损次数下界;可磨损次数下界是批次之间的分界线,意味着该批次中的页面到磨损率上界的可磨损次数要大于其可磨损次数下界,否则将会被放到下一个批次中。
[0015]
进一步地,在所述步骤s3中,还包括步骤:
[0016]
s31、将每个批次中的每一个页面划分成64个基本的内存单元,其中最后一个内存单元用于存储该页面的元数据,则每个批次用64个链表组织得到64个桶;
[0017]
s32、在一个页面的最后一个内存单元中,用第一段内存作为第一个位图use bitmap记录每个内存单元是否空闲,用第二段内存作为第二个位图size bitmap记录每次分配出去的内存单元的大小;用第三段内存c
fu
记录该页面内部空闲的内存单元的总数量,用第四段内存s
ms
记录最大可用内存段,用第五段内存s
ff
记录下一个将要分配的内存单元的序号,用第六段内存pre作为第一个指针用以指向前一个具有相同的最大可用内存段的页面,用第七段内存next作为第二个指针用以指向后一个具有相同的最大可用内存段的页面。
[0018]
进一步地,在所述步骤s4中,所述在最优适配的桶中分配空闲页中可以被分配的内存段,具体包括步骤:
[0019]
s41、在选定的批次中选择最优适配的桶,并判断该桶中是否有空闲页,若是则选择该空闲页,若否则选择该批次中下一个最大可用内存段更大的桶,再重新判断;若该批次中所有的桶都为空,那么配置内存页,再重新判断;如果配置内存页失败,则需要重新进行批次选择,再重新判断;
[0020]
s42、分配内存单元,得到被分配空间的首地址。
[0021]
进一步地,在所述步骤s4后还包括步骤:
[0022]
s5、更新被分配页面的元数据,包括use bitmap、size bitmap、c
fu
、s
ms
、s
ff
、pre和next;
[0023]
s6、利用公式(1)重新计算被分配页面的批次并根据更新后的s
ms
将该被分配页面放到对应的批次和桶中。
[0024]
进一步地,在步骤s1~s6的分配过程中,整个持久内存空间会老化,随着持久内存空间的老化,磨损率上界则被动态地调整,则所有页面到磨损率上界的可磨损次数被改变,需要重新划分批次;
[0025]
依据磨损率上界的更新次数n来计算现有的磨损率上界;
[0026]
依据页面所在内存域的磨损率上界对应的可磨损次数上界和该页面已经被磨损的次数来计算得到该页面的可磨损次数。
[0027]
进一步地,用大小为8bytes即64bits的位图size bitmap来记录整个页面的分配情况,在该位图中,每个bit表示一个内存单元的分配情况,用连续的0或1表示每次被分配出去的内存单元,用连续的0或1的数量n计算此次被分配出去的内存空间大小为n*64bytes;
[0028]
记录分配空间的步骤包括:
[0029]
a1、计算此次分配出去的内存空间对应在size bitmap中的起始位置和偏移量,这段bits被称为待着色空间;
[0030]
a2、计算待着色空间的bits对应的着色值,为0或者1,其值和待着色空间的前一个bit值相反;
[0031]
a3、对待着色空间的bits赋值;如果待着色空间后一位bit值和所赋值的bits值不相同,将后续的bits全部翻转;
[0032]
在步骤a2中,利用两个辅助数组来得到size bitmap的着色值,每一个辅助数组中的元素都是大小为64bits的0和1向量,第一个辅助数组aleft存储了值为1的下三角矩阵,第二个辅助数组aright存储了值为1的上三角矩阵;
[0033]
在步骤a3中,
[0034]
如果需要执行将第i到第j个bits置1的操作,首先计算该操作的掩码:aleft[j+1]&aright[i],接着与size bitmap做或运算;
[0035]
如果需要执行将第i到第j个bits置0的操作,首先计算该操作的掩码:aleft[i]|aright[j+1],接着与size bitmap做与运算;
[0036]
如果需要执行将第j个bit后的bits翻转的操作,则首先计算翻转部分的掩码:~size_bitmap&aright[j+1],接着保留原来部分的掩码:size_bitmap&aleft[j+1],最后将这两个掩码做或运算。
[0037]
进一步地,当且仅当桶k中页面的平均空闲单元数tfk.avg超过桶的序号k,即tfk.avg》k时,采用一个守护线程对桶进行改造,具体包括步骤:
[0038]
b1、守护线程计算桶k的tfk.avg:
[0039][0040]
其中,npk为桶k中的总页数,c
fu
(pq)表示第q页pq的空闲单元数;
[0041]
b2、如果tfk.avg》k,计算桶k中的每个页面的最大空闲段,页面中的元数据s
ms
和c
fu
将根据最大空闲段进行重置;
[0042]
b3、根据其元数据s
ms
将改造后的页面添加到桶中;
[0043]
b4、该线程将每个桶的数据持久化;
[0044]
将位图use bitmap分成包含以下三个部分的n个位图片段:
[0045]
左边部分:从位图片段的第一个位开始的最大空闲段,第i个位图片段的左边部分的大小用si.left来表示;
[0046]
右边部分:在位图片段的最后一位结束的最大空闲段,第i个位图片段的右边部分的大小用si.right表示,如果左边部分在片段的最后一位结束,si.right=0;
[0047]
中间部分:左边部分和右边部分之间的最大空闲段,第i个位图片段的中间部分的
大小用si.mid来表示,如果在左边部分和右边部分之间没有超过一个空闲内存单元,si.mid=0;
[0048]
则在步骤b2中,计算最大空闲段的步骤包括:
[0049]
b21、寻找完全空闲的位图片段;
[0050]
b22、确定从位图片段i开始的最大空闲段的大小为max{si.left,si.mid,si.right+(j-i-1)*s
slice
+sj.left},s
slice
表示位图片段的大小,sj.left表示结束位图片段j的左边部分。
[0051]
进一步地,当达到以下条件之一时,触发对批次的改造:
[0052]
条件1:p1=0;
[0053]
条件2:p1《=x且p1的值在r个连续分配请求后依然保持不变;
[0054]
条件3:p1》x且p2=0,或者p2《=x并且p2在r个连续分配请求后保持不变;
[0055]
p1和p2分别是优先级最高的批次和优先级第二高的批次的页面数量,x为该批次中初始页面数量的1%,r为256;
[0056]
对批次的改造操作包括:
[0057]
设置一个滑动的窗口,当窗口滑动的时候,当前优先级最高的批次会被抛弃,该批次中的页面会被放入下一批次,当前优先级次高的批次成为新的优先级最高的批次,最后,在这些批次底部增加一个新批次,并计算出相应的新边界;
[0058]
随着批次的不断改造,批次的可磨损次数将接近磨损率上界t,这将导致t被更新以适应pm的老化,计算t的方程式如下:
[0059][0060]
其中,α为比例因子,n为t的更新次数;在初始时刻将t设为0.01%;
[0061]
随着t的更新,批次到t的可磨损次数上界也将被改变,使用到t的可磨损次数的最大增量e
max
来计算新边界,其计算式如下:
[0062]emax
=(t-t
′
)
×emax
ꢀꢀꢀꢀꢀ
(4)
[0063]
其中t'是更新前的磨损率上界,当第一次计算t时,t'为0。
[0064]
本发明提供的一种考虑制程差异的持久内存的分配方法,其效果在于:
[0065]
1、针对页面之间存在的制程差异,采用了基于优先级的动态磨损均衡策略(步骤s1、s2、s4),首先针对所有页面,设置一个统一的磨损率上界;然后,根据pm中的页面与磨损率上界的距离,将整个内存空间分成不同的批次,不同批次设置有不同的分配优先级;然后,优先级最高的页面总是被先分配;最后,随着pm的老化,批次和磨损率上界会被不断更新,确保页面之间的磨损率均衡(磨损率是现有磨损次数和理论磨损次数上限的比值);
[0066]
2、针对页面内部的磨损不均衡,本发明对页内空间做了细粒度的空间管理和分配策略,以一种循环的最优适应策略来分配内存单元(步骤s3、s4)。首先,用最大可用内存段来组织内存页,用链表将最大可用内存段相同的页链接起来,然后从最优适应链表里选择页面分配。随着不断的分配释放,更新页内的最大连续内存单元,将其放到合适的链表中。以这样的方式,同一个页面内部的内存单元能够被均匀地磨损;
[0067]
3、充分考虑了页面之间和页面内部的磨损均衡,能够感知耐久差异,减少耐久低
的内存单元的磨损,增大耐久度高的内存单元的磨损,做到每一个页面的内存单元都能够被均匀地磨损,可最大程度地提高pm的使用寿命。
附图说明
[0068]
图1是本发明实施例提供的一种考虑制程差异的持久内存的分配方法的步骤流程图;
[0069]
图2是本发明实施例提供的内存空间的总体结构图;
[0070]
图3是本发明实施例提供的页面的组织结构图;
[0071]
图4是本发明实施例提供的内存分配的流程图;
[0072]
图5是本发明实施例提供的size bitmap的示例图;
[0073]
图6是本发明实施例提供的辅助数组的展示图;
[0074]
图7是本发明实施例提供的滑动窗口策略的处理过程图。
具体实施方式
[0075]
下面结合附图具体阐明本发明的实施方式,实施例的给出仅仅是为了说明目的,并不能理解为对本发明的限定,包括附图仅供参考和说明使用,不构成对本发明专利保护范围的限制,因为在不脱离本发明精神和范围基础上,可以对本发明进行许多改变。
[0076]
为了克服制程差异所带来的磨损不均衡的问题,本发明实施例提供一种考虑制程差异的持久内存的分配方法,如图1所示,包括步骤s1~s4:
[0077]
s1、将整个持久内存空间划分为大小相等的内存域,同一内存域具有相同的耐久性,而不同内存域具有不同的耐久性。
[0078]
内存域的耐久性分布可以用线性函数近似拟合得到。e
max
和e
min
分别表示持久内存空间中耐久最大和最小的内存域的磨损次数的理论上限,d
num
表示内存域的数量,d
x
(x=1,2,
…
,d
num
)表示该页面所在内存域的序号。
[0079]
s2、结合不同内存域的耐久性,将整个持久内存空间根据其磨损情况划分为多个批次,不同批次中的页面根据其与磨损率上界的距离设置有不同的分配优先级。
[0080]
这里,页面与磨损率上界的距离定义为页面到磨损率上界的可磨损次数wt,计算方式为:
[0081][0082]
其中,t表示所有页面统一的磨损率上界,c表示该页面的平均磨损次数。
[0083]
如图2所示,整个内存空间根据其磨损情况被划分为n个批次(batch cache0~batch cache n-1,保存批次的缓存元数据在dram中),在每个批次的元数据中,用一个指针(b-pointer)指向该批次所在的逻辑空间,用第一个变量(b-counts)记录该批次中页面的数量,用第二个变量(boundary)记录该批次到磨损率上界t的可磨损次数下界;可磨损次数下界是批次之间的分界线,意味着该批次中的页面到磨损率上界的可磨损次数要大于其可磨损次数下界,否则将会被放到下一个批次中。批次的分配优先级在图2中从上到下依次下降。批次的这些元数据都会被持久化到pm的batch metadata区域中。
[0084]
随着pm的老化,t会被动态调整。本发明通过记录t的更新次数n来计算现有t值,其被存放在pm的元数据区域。动态调整t会导致所有页面的到t的可磨损次数被改变,所以本例用页面所在内存域的t值对应的磨损次数(近似该页面t值对应的磨损次数)和该页面已经被磨损的次数来计算得到。在图2中,内存域的t值对应的磨损次数用maximum wear times表示,每个页面的磨损次数被持久化到元数据wear counts区域,都被持久化到pm中。
[0085]
s3、在每个批次中,将最大可用内存段相同的页面用链表组织在一起成为一个桶,而得到该批次中不同最大可用内存段所对应的不同的桶。
[0086]
对于页面内部的管理,如图3所示,本例具体设有步骤:
[0087]
s31、将一个页划分成64个基本的内存单元,页面中的最后的一个单元用于存储页面的元数据,则每个批次用64个链表组织得到64个桶;
[0088]
s32、在页面元数据的管理下,在一个页面的最后一个内存单元中,用第一段内存作为第一个位图use bitmap(8bytes)记录每个内存单元是否空闲,用第二段内存作为第二个位图size bitmap(8bytes)记录每次分配出去的内存单元的大小;用第三段内存c
fu
(1byte)记录该页面内部空闲的内存单元的总数量,用第四段内存s
ms
记录最大可用内存段(即:最大的连续空闲内存单元),用第五段内存s
ff
记录下一个将要分配的内存单元的序号,用第六段内存pre作为第一个指针用以指向前一个具有相同的最大可用内存段的页面,用第七段内存next作为第二个指针用以指向后一个具有相同的最大可用内存段的页面,reserved space表示剩余空间。
[0089]
页内的内存单元的分配是循环分配的,每次从最大空闲内存段里分配。所以内存段的大小从0到63,分别表示页满和页空的两种状态。为了迅速进行内存分配,这些页根据最大连续空闲内存单元被划分成不同的链表。其链表结构如图2右上角的链表所示,每个批次用64个链表组织。
[0090]
s4、在分配内存单元时,先分配优先级最高的批次,再在最优适配的桶中分配空闲页中可以被分配的内存段,最后将被分配了内存单元的页面放回到合适的批次和桶中。
[0091]
针对页面内部磨损均衡,本例设计了顺时针最优适应的分配策略(按顺时针的方式循环搜索最大内存段,在最优适配的桶中分配空闲页中可以被分配的内存段),具体包括步骤:
[0092]
s41、在选定的批次中选择最优适配的桶,并判断该桶中是否有空闲页,若是则选择该空闲页,若否则选择该批次中下一个最大可用内存段更大的桶,再重新判断;若该批次中所有的桶都为空,那么配置内存页,再重新判断;如果配置内存页失败,则需要重新进行批次选择,再重新判断;
[0093]
s42、分配内存单元,得到被分配空间的首地址。
[0094]
页面内部的可用内存单元是按顺时针的方式循环搜索的,最大可用内存段相同的页面被链表组织在一起,被称作不同的“桶”。所以,本例首先计算分配请求需要的内存段的大小。然后,尝试从最优适应的“桶”(也就是图2中右边的链表)中找到可以被分配的内存段。当该最优适应的桶为空时,则从更大的桶中搜寻。当找到满足条件的内存段之后,分配空间并更新相应的元数据。整体的内存分配流程如图4所示。
[0095]
s5、更新被分配页面的元数据,包括use bitmap、size bitmap、c
fu
、s
ms
、s
ff
、pre和next。
[0096]
s6、利用公式(1)重新计算被分配页面的批次并根据更新后的s
ms
将该被分配页面放到对应的批次和桶中。
[0097]
s7、对内存进行回收。该步骤主要包括步骤:
[0098]
s71、通过回收内存的地址,找到相应的页面元数据;
[0099]
s72、计算应该回收的内存单元大小;
[0100]
s73、更新dram中相应的页面元数据,包括记录内存单元是否空闲的位图use bitmap和页面空闲单元的数量c
fu
。
[0101]
为了记录分配空间的大小,本例提出了位图着色算法。这个算法用大小为8bytes(64bits)的位图(size bitmap)来记录整个页面的分配情况。在该位图中,每个bit表示一个内存单元的分配情况,用连续的0或1表示每次被分配出去的内存单元,用连续的0或1的数量n来计算此次被分配出去的内存空间大小为n*64bytes。如图5所示的示例,最开始的连续4个1表示被分配出去的空间大小为4*64bytes,之后的3个连续的0表示另外一次被分配出去的空间大小为3*64bytes。该位图着色算法记录分配空间的步骤包括:
[0102]
a1、计算此次分配出去的内存空间对应在size bitmap中的起始位置和偏移量,这段bits被称为待着色空间;
[0103]
a2、计算待着色空间的bits对应的着色值,为0或者1,其值和待着色空间的前一个bit值相反;
[0104]
a3、对待着色空间的bits赋值;如果待着色空间后一位bit值和赋值的bits值不相同,将后续的bits全部翻转。
[0105]
为了加快计算速度,本例利用两个辅助数组来得到size bitmap的着色值。每一个数组中的元素都是大小为64bits的0和1向量。具体的,如图6所示,第一个辅助数组aleft存储了值为1的下三角矩阵,第二个辅助数组aright存储了值为1的上三角矩阵。
[0106]
在步骤a3中,如果需要执行将第i到第j个bits置1的操作,首先计算该操作的掩码:aleft[j+1]&aright[i],接着与size bitmap做或运算;
[0107]
如果需要执行将第i到第j个bits置0的操作,首先计算该操作的掩码:aleft[i]|aright[j+1],接着与size bitmap做与运算;
[0108]
如果需要执行将第j个bit后的bits翻转的操作,则首先计算翻转部分的掩码:~size_bitmap&aright[j+1],接着保留原来部分的掩码:size_bitmap&aleft[j+1],最后将这两个掩码做或运算。
[0109]
例如,内存单元9-13需要被赋值为1,那么首先利用逻辑运算aleft[13]&aright[9]得到9-13位bits值为1的掩码。然后对size bitmap和掩码进行按位或操作,就得到了记录了此次分配空间大小的size bitmap。同样的,最后一步后续bits翻转操作也被优化。这样,该算法的时间复杂度为o(1)。
[0110]
在执行了大量的空间分配和回收操作后,本例提出内存改造操作来整理桶和批次。改造桶的目的是为页面找到最大的空闲段,并将页面放到恰当的桶中。改造批次的目的是为了更新t以适应pm的老化,并调整批次以保持磨损均衡策略的有效性。
[0111]
当且仅当桶k中页面的平均空闲单元数tfk.avg超过桶的序号k,即tfk.avg》k时,采用一个守护线程对桶进行改造,具体包括步骤:
[0112]
b1、守护线程计算桶k的tfk.avg:
[0113][0114]
其中,npk为桶k中的总页数,c
fu
(pq)表示第q页pq的空闲单元数;
[0115]
b2、如果tfk.avg》k,计算桶k中的每个页面的最大空闲段,页面中的元数据s
ms
和c
fu
将根据最大空闲段进行重置;
[0116]
b3、根据其元数据sms将改造后的页面添加到桶中;
[0117]
b4、该线程将每个桶的数据持久化。
[0118]
桶改造操作后,元数据缓存被备份到pm中对应的页面的元数据中。在步骤b2中,有必要迅速找出最大空闲段。因此,本例提出了一个dma(divide-and-matching algorithm)算法来有效地获得最大空闲段。该算法的主要思想是基于分治思想和缓存状态。该算法中,空间使用位图(use bitmap)被分成包含了以下三个部分的n个位图片段:
[0119]
左边部分:从位图片段的第一个位开始的最大空闲段,第i个位图片段的左边部分的大小用si.left来表示;
[0120]
右边部分:在位图片段的最后一位结束的最大空闲段,第i个位图片段的右边部分的大小用si.right表示,如果左边部分在片段的最后一位结束,si.right=0;
[0121]
中间部分:左边部分和右边部分之间的最大空闲段,第i个位图片段的中间部分的大小用si.mid来表示,如果在左边部分和右边部分之间没有超过一个空闲内存单元,si.mid=0。
[0122]
则在步骤b2中,计算最大空闲段的步骤包括:
[0123]
b21、寻找完全空闲的位图片段;
[0124]
b22、确定从位图片段i开始的最大空闲段的大小为max{si.left,si.mid,si.right+(j-i-1)*s
slice
+sj.left}(即确定为si.left、si.mid、si.right+(j-i-1)*s
slice
+sj.left三个值中最大的那个),s
slice
表示位图片段的大小。
[0125]
在步骤b22中,如果当前位图片段是完全空闲的,最大空闲段必须包括后续所有完全空闲的片段[si.right+(j-i-1)*s
slice
]和结束位图片段的左边部分(sj.left)。假设当前图片片段不是完全空闲的,位图片段的所有部分都可能是最大部分。然而,右边部分可能与后续片段的左边部分接壤。因此,从片断i开始的最大段的大小为max{si.left,si.mid,si.right+(j-i-1)*s
slice
+sj.left}。
[0126]
最后,必要时更新s
ms
和s
ff
。
[0127]
为了提高dma算法的效率,本例用空间换时间的思想计算每个位图片段的空闲比特。首先,本例构建了一个辅助数组来存储位图片段的所有可能状态,包括每个位图片段的左边部分,右边部分和中间部分的大小。所以,只需查询存储在辅助数组中的相应状态,就可以在o(1)时间内得到si.left、si.mid和si.right。在实现上,本例将8字节的位图被分为4*2字节的位图片段。每个2字节的位图片段可以被看作是一个从0到65535的整数范围。本例构建了一个辅助数组来存储所有65536个比特片段的状态,包括每个比特片段的三个部分的大小。每个部分的大小最多可以用4比特表示,因为一个片段的长度是16比特。
[0128]
随着内存分配请求不断发生,优先级最高的批次中的页面会由于被磨损而被放入后续批次中,所以优先级高的批次中页面会越来越少。为了调整批次以保持磨损均衡策略
的有效性,需要对批次进行改造。然而,一些应用场景会导致优先级高的批次中页面数量不均匀下降。因此,这里总结了批处理操作的触发条件:
[0129]
条件1:p1=0;
[0130]
条件2:p1《=x且p1的值在r个连续分配请求后依然保持不变;
[0131]
条件3:p1》x且p2=0,或者p2《=x并且p2在r个连续分配请求后保持不变。
[0132]
当达到以上条件之一时,触发对批次的改造。其中,p1和p2分别是优先级最高的批次和优先级第二高的批次的页面数量,x为该批次中初始页面数量的1%,r为256,是一个页面的基本内存单元数量的4倍。也就是说,批次改造触发的条件为:优先级最高的批次中的页面很少或者其页面长时间保持不变。
[0133]
本例使用滑动窗口策略来进行批次改造。具体的改造操作包括:设置一个滑动的窗口,当窗口滑动的时候,当前优先级最高的批次会被抛弃,该批次中的页面会被放入下一批次,当前优先级次高的批次成为新的优先级最高的批次,最后,在这些批次底部增加一个新批次,并计算出相应的新边界。举例如图7所示,该窗口包含每一个批次的到t的可磨损次数边界,分别由b0到b
n-1
表示。当滑动窗口后,第0批(也就是优先级最高的批次)的页面被搬移到了下一批次。然后,下一个批次成为新的优先级最高的批次。最后,在这些批次底部增加一个新批次,并计算出相应的新边界。新的第0批到第n-1批的边界变成了b'0到b'
n-1
,如图7右侧所示。通过批次改造操作,这些页面可以继续按照磨损情况进行划分,距离磨损率上界t较远的页面将被首先分配。
[0134]
随着批次的不断改造,批次的可磨损次数将接近磨损率的上限t,这将导致t被更新以适应pm的老化。初始阶段,本例采用宽松的磨损均衡策略,t的增量最为明显。随着pm的老化,逐渐收紧磨损均衡策略,t的增长也逐渐放缓。考虑到t的上升趋势,本例调整sigmoid函数,将x轴的正半轴对应的y值缩放到0到1之间,计算t的方程式如(3):
[0135][0136]
其中,α为比例因子,n是更新t的次数。为了防止磨损耐久差的内存域过早老化,本例通过在初始时刻将t设为0.01%对页面的磨损次数进行精细控制,并把α设置为5000。随着t的更新,批次的到t的可磨损次数上界也将被改变。本例使用到t的可磨损次数的最大增量(用e
max
表示)来计算新边界,其计算式如下:
[0137]emax
=(t-t
′
)
×emax
ꢀꢀꢀꢀꢀꢀ
(4)
[0138]
其中t'是更新前的磨损率上界,当第一次计算t时,t'为0。
[0139]
总之,边界更新包括两种情况:第一种是通常情况下的批次改造,不会更新t,另一种情况是批次和t一起更新。第一种情况只需要在添加新批次时计算其到t的可磨损次数边界b(i),其计算式如下:
[0140]
b(i)=b(i-1)
×
(1-t)
ꢀꢀꢀꢀꢀꢀ
(5)
[0141]
其中,t是预设的边界下降率,b(i-1)是上一批次的边界。在初始化批次时,边界的计算方法如公式(6):
[0142]
[0143]
其中e
max
是由公式(4)计算的到t的可磨损次数的最大增量。同样地,e
min
是到t的可磨损次数的最小增量,n是批次的数量。本例将b(-1)的大小定义为e
max
来计算第一批的边界。
[0144]
然而,如果由公式(5)计算的新边界b(i)接近t,批次边界将随着t的更新而更新,以避免页面的磨损率超过t。在这种情况下,本例首先通过公式(3)调整阈值t。然后,按以下方式更新所有批次的边界。
[0145]
b(i)=e
max
+b(i)
′ꢀꢀꢀꢀꢀ
(7)
[0146]
其中,b(i)
′
是更新前的到t的可磨损次数的边界。
[0147]
本发明实施例提供的一种考虑制程差异的持久内存的分配方法,其效果在于:
[0148]
1、针对页面之间存在的制程差异,采用了基于优先级的动态磨损均衡策略(步骤s1、s2、s4),首先针对所有页面,设置一个统一的磨损率上界;然后,根据pm中的页面与磨损率上界的距离,将整个内存空间分成不同的批次,不同批次设置有不同的分配优先级;然后,优先级最高的页面总是被先分配;最后,随着pm的老化,批次和磨损率上界会被不断更新,确保页面之间的磨损率均衡(磨损率是现有磨损次数和理论磨损次数上限的比值);
[0149]
2、针对页面内部的磨损不均衡,本发明对页内空间做了细粒度的空间管理和分配策略,以一种循环的最优适应策略来分配内存单元(步骤s3、s4)。首先,用最大可用内存段来组织内存页,用链表将最大可用内存段相同的页链接起来,然后从最优适应链表里选择页面分配。随着不断的分配释放,更新页内的最大连续内存单元,将其放到合适的链表中。以这样的方式,同一个页面内部的内存单元能够被均匀地磨损;
[0150]
3、在执行了大量的空间分配和回收操作后,提出内存改造操作来整理桶和批次。改造桶的目的是为页面找到最大的空闲段,并将页面放到恰当的桶中。改造批次的目的是为了更新t以适应pm的老化,并调整批次以保持磨损军均衡策略的有效性;
[0151]
4、充分考虑了页面之间和页面内部的磨损均衡,能够感知耐久差异,减少耐久低的内存单元的磨损,增大耐久度高的内存单元的磨损,做到每一个页面的内存单元都能够被均匀地磨损,可最大程度地提高pm的使用寿命。
[0152]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1