用于合同文档弯曲文本行校正的方法与流程
用于合同文档弯曲文本行校正的方法
【技术领域】
1.本发明涉及合同文档技术领域,尤其涉及一种用于合同文档弯曲文本行校正的方法。
背景技术:
2.现有的弯曲文本处理,一般都是针对特定场景的弯曲文本进行处理,无法处理结构体文档文本。针对特定场景下的弯曲文本矫正,需要检测每个字符位置,及一些聚类算法拟合曲线,操作复杂且依赖于单个字符的检测算法误差累积影响,单字符检测因为特征小容易检测出错,同时如果是文档结构性文本行,聚类拟合文本曲线容易串行等极大的影响最终校正结果。目前已经存在非常成熟的文本行检测算法,检测精度非常高,因此可以极大的避免这种单字符检测的误差累积。而基于模型的方法,需要构造数据集并设计网络模型进行训练,需要的成本比较高,网络相对复杂度比较高,无法描述到学习到的映射内容意义。
3.因此,现有技术存在不足,需要改进。
技术实现要素:
4.为克服上述的技术问题,本发明提供了一种用于合同文档弯曲文本行校正的方法。
5.本发明解决技术问题的方案是提供一种用于合同文档弯曲文本行校正的方法,包括如下步骤:
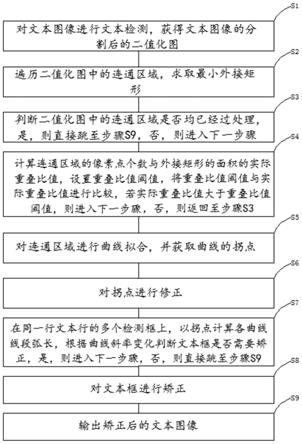
6.步骤s1:对文本图像进行文本检测,获得文本图像的分割后的二值化图;
7.步骤s2:遍历二值化图中的连通区域,求取最小外接矩形;
8.步骤s3:判断二值化图中的连通区域是否均已经过处理,是,则直接跳至步骤s9,否,则进入下一步骤;
9.步骤s4:计算连通区域的像素点个数与外接矩形的面积的实际重叠比值,设置重叠比值阈值,将重叠比值阈值与实际重叠比值进行比较,若实际重叠比值大于重叠比值阈值,则进入下一步骤,否,则返回至步骤s3;
10.步骤s5:对连通区域进行曲线拟合,并获取曲线的拐点;
11.步骤s6:对拐点进行修正;
12.步骤s7:在同一行文本行的多个检测框上,以拐点计算各曲线线段弧长,根据曲线斜率变化判断文本框是否需要矫正,是,则进入下一步骤,否,则直接跳至步骤s9;
13.步骤s8:对文本框进行矫正;
14.步骤s9:输出矫正后的文本图像。
15.优选地,在步骤s1中,采用基于分割的psenet文本检测算法进行文本检测。
16.优选地,在步骤s5中,通过获取连通区域从左至右排列的像素点中心数组,并对该数组进行最小二乘法进行拟合。
17.优选地,在步骤s5中,所述曲线的拐点为文本行的分割点。
18.优选地,在步骤s6中,将二值化图映射会文本图像,对分割点进行修正,文字行垂直投影,寻找出字符间隔符作为最终分割点。
19.优选地,在步骤s8中,对目标文本图像进行重新定义,使其高度为分割曲线的最小外接矩形的高度,宽度为曲线的弧长。
20.相对于现有技术,本发明的用于合同文档弯曲文本行校正的方法具有如下优点:
21.通过本发明的方法,可在分割图上对弯曲样本进行矫正,仅对弯曲文本进行处理,有效降低了正常文本因被矫正而产生变形的可能性,进而有助于恢复矫正后的文本行,操作过程较为简单,无需构建模型学习、训练,矫正效果较佳,且无需进行单字符切分,避免了对文本内容的依赖,有助于文档文本的恢复,同时较佳的文本矫正结果也有利于提高ocr识别的准确程度,适用于多个文本图像场景,具有较强的通用性。
【附图说明】
22.图1是本发明用于合同文档弯曲文本行校正的方法的具体流程示意图。
【具体实施方式】
23.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施实例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
24.请参阅图1,本发明提供一种用于合同文档弯曲文本行校正的方法,包括如下步骤:
25.步骤s1:对文本图像进行文本检测,获得文本图像的分割后的二值化图。
26.具体地,在步骤s1中,采用基于分割的psenet文本检测算法进行文本检测,以获得整个文本图像的分割后的二值化图。其中,基于分割的文本检测算法,为文本图像二值分割图的基础模型,该检测方法直接影响文本框的定位,影响到后期文本框的定位,因此需要训练文本检测模型。文本检测模型使用psenet网络结构,样本标注使用ctw1500的标注格式,输入文本框的14个曲面标注点。psenet采用基于分割的方式,但是对文本行不同核大小做预测,然后采用渐进式扩展算法扩展小尺度kernel到最终的文本行大小。因为在小尺度kernel之间存在比较大的margin,因此能够很好的区分相邻的文本行,最终输出分割后的二值化图。
27.进一步地,步骤s2:遍历二值化图中的连通区域,求取最小外接矩形。
28.在进行文本检测后获得的二值化图中,每一连通图代表文本行所在的位置,所以对文本图像的二值化图的连通区域分别求取最小外接矩形。
29.进一步地,步骤s3:判断二值化图中的连通区域是否均已经过处理,是,则直接跳至步骤s9,否,则进入下一步骤;
30.步骤s4:计算连通区域的像素点个数与外接矩形的面积的实际重叠比值,设置重叠比值阈值,将重叠比值阈值与实际重叠比值进行比较,若实际重叠比值大于重叠比值阈值,则进入下一步骤,否,则返回至步骤s3。
31.通过判断实际重叠比值与重叠比值阈值的比较,确认图像是否为弯曲样本。当实
际重叠比值小于重叠比值阈值时,则认定当前连通区域的图像为弯曲样本,需要进行文本框分割,以增大实际重叠比值的数值。
32.进一步地,步骤s5:对连通区域进行曲线拟合,并获取曲线的拐点。
33.具体地,在步骤s5中,通过获取连通区域从左至右排列的像素点中心数组,并对该数组进行最小二乘法进行拟合,并求取曲线的拐点。具体拟合过程为:按偏差平方和最小的原则选取拟合区域选,并通过下述方程实现,使偏差平方和最小。
[0034][0035]
可以理解,本发明中曲线的拐点为文本行的分割点。
[0036]
进一步地,步骤s6:对拐点进行修正。
[0037]
具体地,在步骤s6中,将二值化图映射会文本图像,对分割点进行修正,文字行垂直投影,寻找出字符间隔符作为最终分割点,以使矩形框的分割出不包含有文字,通过落在空白间隔符上,以确保字符不会被至少部分分割。
[0038]
进一步地,步骤s7:在同一行文本行的多个检测框上,以拐点计算各曲线线段弧长,根据曲线斜率变化判断文本框是否需要矫正,是,则进入下一步骤,否,则直接跳至步骤s9。
[0039]
步骤s8:对文本框进行矫正。
[0040]
对需要进行矫正的文本框进行矫正,具体为通过重新定义目标文本图像,使其高度为分割曲线的最小外接矩形的高度,宽度为曲线的弧长,原始文本图像为最小外接矩形,修正至目标图像,通过双线性插值法将原始文本图像的像素点映射至目标图像中。
[0041]
步骤s9:输出矫正后的文本图像。
[0042]
通过本发明的方法,对弯曲的文本进行矫正,将变形的弯曲文本进行恢复,同时对最终结果进行矫正,恢复合同文档的文本数据,有利于提高ocr的识别率。
[0043]
相对于现有技术,本发明的用于合同文档弯曲文本行校正的方法具有如下优点:
[0044]
通过本发明的方法,可在分割图上对弯曲样本进行矫正,仅对弯曲文本进行处理,有效降低了正常文本因被矫正而产生变形的可能性,进而有助于恢复矫正后的文本行,操作过程较为简单,无需构建模型学习、训练,矫正效果较佳,且无需进行单字符切分,避免了对文本内容的依赖,有助于文档文本的恢复,同时较佳的文本矫正结果也有利于提高ocr识别的准确程度,适用于多个文本图像场景,具有较强的通用性。
[0045]
以上所述仅为本发明的较佳实施例,并非因此限制本发明的专利范围,凡是在本发明的构思之内所作的任何修改,等同替换和改进等均应包含在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1