玉米淀粉工艺参数与淀粉乳DE值的关联度分析方法
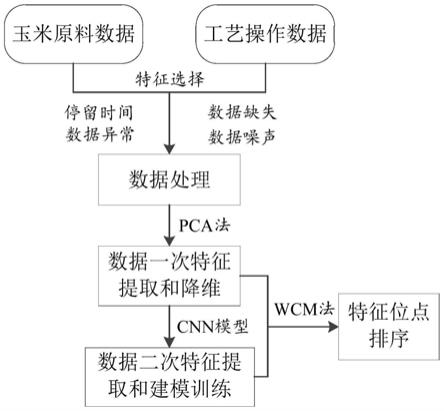
玉米淀粉工艺参数与淀粉乳de值的关联度分析方法
技术领域
1.本发明涉及大数据的工艺建模领域,具体地涉及一种玉米淀粉工艺参数与淀粉乳de值的关联度分析方法。
背景技术:
2.玉米淀粉工业是碳水化合物衍生物的基础产业,其产品中的玉米淀粉是食品加工的重要原料。在国民生活、经济和农业产业化发展方面,食品加工中的淀粉行业是我国食品行业的重要组成部分,也是玉米深加工中最重要的环节之一。
3.不同来源的玉米原料,在加工过程中所对应的适宜的加工工艺参数也会有所不同。随着管理的精细化,玉米深加工企业在生产过程中采集的数据日益庞杂,数据量呈爆炸式增长,且数据均为时序数据。面对着海量的数据记录,生产管理人员仅依靠生产经验,很难准确地分析数据间的关联关系。在玉米淀粉工艺中反映了淀粉乳产品的品质的重要指标为de值,de值表示还原糖占糖浆干物质的百分比;如何利用历史工艺数据挖掘出对de值影响最大的工艺参数,是我们亟需解决的技术问题。
技术实现要素:
4.本发明实施例的目的是提供一种玉米淀粉工艺参数与淀粉乳de值的关联度分析方法,主要解决玉米淀粉工艺参数与淀粉乳de值之间的关联度,以实现提高淀粉乳de值的工艺调整方案。
5.为了实现上述目的,一种玉米淀粉工艺参数与淀粉乳de值的关联度分析方法,包括:
6.获取与玉米淀粉工艺中的位点相关联的玉米原料数据和玉米淀粉工艺中的生产监测原始数据共同形成初始输入数据;
7.运用主成分分析法对初始输入数据进行特征提取处理,得到初始输入数据的特征向量;以及运用主成分分析法对初始输入数据进行降维处理,得到初始输入数据的主成分输入数据;
8.将所述主成分输入数据运用卷积神经网络模型进行训练,并计算训练后的卷积神经网络模型的总权值矩阵;以及将所述初始输入数据的特征向量依次组合成的矩阵作为初始输入数据的权值矩阵;
9.将所述卷积神经网络模型的总权值矩阵与所述初始输入数据的权值矩阵相乘,将得到的矩阵作为玉米淀粉工艺位点与玉米淀粉工艺中的淀粉乳产品de值对应的关联度矩阵。
10.优选的,所述获取与玉米淀粉工艺中的位点相关联的玉米原料数据和玉米淀粉工艺中的生产监测原始数据,形成初始输入数据,包括:
11.将与玉米淀粉工艺中的位点相关联的玉米原料数据和玉米淀粉工艺中的生产监测原始数据进行去噪处理,得到去噪数据;
12.运用lasso回归分析法对所述去噪数据进行特征选择,将特征选择后的数据作为所述初始输入数据。
13.优选的,所述运用主成分分析法对初始输入数据进行特征提取处理,得到初始输入数据的特征向量,包括:
14.将初始输入数据进行标准化转换得到标准化矩阵z,运用所述标准化矩阵z得到所述标准化矩阵z和标准化矩阵z的转置矩阵之间的相关系数矩阵r;
15.运用相关系数矩阵r的特征方程,得到单位特征向量作为初始输入数据的特征向量。
16.优选的,所述运用主成分分析法对初始输入数据进行降维处理,得到初始输入数据的主成分输入数据,包括:
17.将所述标准化阵z和所述单位特征向量运用关联公式得到的矩阵作为初始输入数据的主成分输入数据;所述关联公式为:
18.j=1,2,...,m;m是主成分个数。
19.优选的,所述将初始输入数据的特征向量依次组合成的矩阵作为初始输入数据的权值矩阵,包括:
20.将单位特征向量依次作为列向量,得到的矩阵作为初始输入数据的权值矩阵w
p
:
21.m是主成分个数;p是特征位点的个数。
22.优选的,所述卷积神经网络模型包括多个一维卷积核和全连接神经网络;所述主成分输入数据包括训练集和验证集;
23.所述将主成分输入数据运用卷积神经网络模型进行训练,包括:
24.利用训练集中的多个一维卷积核对主成分输入数据进行两次卷积操作的数据输入全连接神经网络进行迭代训练,直到训练集和验证集的均方误差均收敛时,训练完成。
25.优选的,所述计算训练后的卷积神经网络模型的总权值矩阵,包括:
26.1)将卷积层中同一特征不同时间的权值相加,得到卷积层的权值w
jc
:
[0027][0028]
其中,s为卷积核的个数;p为卷积核的大小;n为卷积核c在卷积操作后的大小;wh为卷积核中的权值系数;wq为全连接层中的权值系数:wq=wq1wq2,...,wqa;其中,a为全连接层的层数;
[0029]
2)将卷积层的权值w
jc
组合成的矩阵作为卷积神经网络模型的总权值矩阵wc:wc=(w
1c
,...,w
jc
)。
[0030]
优选的,所述玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵w为:
[0031]
w=w
p
wc。
[0032]
优选的,所述关联度分析方法,还包括:
[0033]
将所述玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵中的元素的绝对值进行排序,得到排序序列;根据排序序列的先后顺序确定玉米淀粉工艺位点对de值之间的影响程度。
[0034]
优选的,所述影响程度包括正相关和负相关;
[0035]
当玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵中的元素为负值时,确定该元素对应的玉米淀粉工艺位点对淀粉乳de值的影响程度为负相关;
[0036]
当玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵中的元素为正值时,确定该元素对应的玉米淀粉工艺位点对淀粉乳de值的影响程度为正相关。
[0037]
通过上述技术方案,主成分分析法pca对玉米淀粉工艺数据进行特征位点的降维,一定程度上解决了数据的维度灾难问题;卷积神经网络cnn模型同时对时间特征进行了捕捉,解决数据的时序不一致问题,使大数据的建模更加准确可靠,最后通过权值连接法wcm可以直观易于理解展示了对淀粉乳产品de值影响的特征位点的关联情况,最终根据关联情况,针对不同原料可以快速的形成工艺调整方案,提高淀粉乳产品的de值。
[0038]
本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
[0039]
附图是用来提供对本发明实施例的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明实施例,但并不构成对本发明实施例的限制。在附图中:
[0040]
图1是实施例中提供的一种玉米淀粉工艺参数与淀粉乳de值的关联度分析方法示意图;
[0041]
图2是实施例中提供的主成分的贡献率及累计贡献率示意图;
[0042]
图3是实施例中提供的一种卷积神经网络模型模型原理图;
[0043]
图4是实施例中提供的卷积神经网路模型的训练结果示意图;
[0044]
图5是实施例中提供的调整本发明确定的位点对应的参数前后的淀粉乳产品de值检测图。
具体实施方式
[0045]
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
[0046]
实施例1
[0047]
如图1所示,本实施例提供的一种玉米淀粉工艺参数与淀粉乳de值的关联度分析方法,包括:
[0048]
获取与玉米淀粉工艺中的位点相关联的玉米原料数据和玉米淀粉工艺中的生产监测原始数据共同形成初始输入数据;
[0049]
运用主成分分析法对初始输入数据进行特征提取处理,得到初始输入数据的特征向量;以及运用主成分分析法对初始输入数据进行降维处理,得到初始输入数据的主成分输入数据;这里主要对进行初始输入数据一次特征提取和降维;
[0050]
将所述主成分输入数据运用卷积神经网络模型进行训练,并计算训练后的卷积神经网络模型的总权值矩阵;以及将所述初始输入数据的特征向量依次组合成的矩阵作为初始输入数据的权值矩阵;通过卷积神经网络模型的机器学习,主要是通过卷积核进行二次特征提取后进行机器学习;
[0051]
将所述卷积神经网络的总权值矩阵与所述初始输入数据的权值矩阵相乘,将得到的矩阵作为玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵。根据关联度矩阵,可以确定影响度大小,从而运用影响度大的特征位点参数进行生产工艺参数的优化,提高淀粉乳产品de值。其中,de值反映了玉米淀粉工艺中淀粉乳产品的品质。
[0052]
优选的,所述获取与玉米淀粉工艺中的位点相关联的玉米原料数据和玉米淀粉工艺中的生产监测原始数据形成初始数据;初始数据为矩阵数据,矩阵数据的列为玉米原料数据中的理化数据及玉米淀粉工艺中的生产监测原始数据中的加工工艺数据,不要求排列顺序;行为时间(按照时间顺序,间隔为10min),然后进行初始数据的特征选择。具体的,将与玉米淀粉工艺中的位点相关联的玉米原料数据和玉米淀粉工艺中的生产监测原始数据进行去噪处理,得到去噪数据;
[0053]
运用lasso回归分析法对所述去噪数据进行特征选择,将特征选择后的数据作为所述初始输入数据。
[0054]
具体的,去噪处理的具体方法可以采用调整停留时间,异常值去除,缺失值补充,噪声去除和特征降维中的一种或多种数据处理方式。其中各种数据处理方式具体方式如下1.1)-1.4)步骤中所示:
[0055]
1.1)考虑到同一批次物料在不同工序之中会有较长的停留时间,简单的截取同一时刻的工艺时间记录位点,会造成物料批次错位,用“现在”的输入参数去关联受到“过去”输入影响的目标参数。因此,以玉米原始数据为基准按照停留时间关联后段工艺数据:淀粉工艺数据和淀粉检测数据时间为48h(玉米浸泡)、糖化工段时间为50h(液化柱内停留)、果糖的occ数据时间为98h(糖化时间)。以此确保输入数据矩阵时间行中每一列数据对应的是同一批玉米原料,保证数据信息的相对一致性。
[0056]
1.2)由于工艺设备传感器的稳定性问题,其记录的工艺数据可能出现异常值的情况。对工艺中出现的异常值进行识别,并删除数据所对应时间的所有位点数据。如,数据矩阵j列(w位点)在第i个(t时刻)数据异常,则删除数据矩阵中的i行。异常值的判定优选采用肖维勒法对数据的异常值进行识别;肖维勒法的判别公式为:
[0057][0058]
ωn=1+0.4ln(n)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0059]
其中,为数据的均值,s
x
为数据的标准差,ωn为肖维勒系数,n为数据点个数;运用(1)式,可以确定数据中的异常值。
[0060]
1.3)由于玉米原料记录数据的时间间隔大于设定值,不同于后续玉米淀粉工艺操作的数据,需要对玉米原料数据进行填补,保证数据的稳定性。采用插值法对空缺的数据进行填补,如式(3-4)所示:
[0061][0062]
x
t_i
=x
t_n
+k*(i-n)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0063]
其中,x
t_n
和x
t_m
为缺失值前后的已知数据;k为新增的空缺数据。
[0064]
1.4)由于工艺运行稳定性和检测技术的限制,采集的数据会出现存在大量噪声的情况,这些噪声极大影响模型训练结果。因此需要对原始的工艺数据进行降噪处理。在进行数据矩阵的异常值处理后,该过程无需对位点数据进行判断,对数据矩阵中所有数据按列
进行降噪。采用“(2n+1点)单纯移动平均”法来平滑滤波进行数据的降噪,如式(5)所示:
[0065][0066]
其中,x
′i为降噪后的数据,x
i+1
为以xi为中心前后各n个的数据。
[0067]
上述运用lasso回归分析法对所述去噪数据进行特征选择,是为了选择有意义的特征进行下一步的模型训练。lasso回归分析法的定义函数,如式(6)所示:
[0068][0069]
其中λ为非负正则参数,控制着模型的复杂程度;β为回归系数向量;n为特征个数。λ越大,对特征较多的线性模型惩罚力度就越大,从而获取一个特征较少的模型,本模型选取λ=0.01。
[0070]
将特征选择后的数据进行标准化转换得到标准化矩阵z,运用所述标准化矩阵z得到所述标准化矩阵z和标准化矩阵z的转置矩阵之间的相关系数矩阵r;具体的标准化转换的公式(7):
[0071][0072]
其中,n为时间维度数据的个数,p为特征位点的个数,为特征位点数据的平均值,s为特征位点数据的方差。z
ij
表示标准化矩阵z中的元素,i和j为对应的行和列索引。
[0073]
运用相关系数矩阵r的特征方程,得到单位特征向量作为初始输入数据的特征向量。具体的,相关系数矩阵的特征方程为:
[0074]
|r-λi
p
|=0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0075]
求解得到p个特征根λ;
[0076]
运用公式(9-10)求解得到单位特征向量
[0077][0078]
rb=λjb,j=1,2,...,m
ꢀꢀꢀꢀꢀ
(10)
[0079]
其中,m为确定的主成分个数,主成分的贡献率kj和累计贡献率sm如图2所示。
[0080]
优选的,所述运用主成分分析法对初始输入数据进行降维处理,得到初始输入数据的主成分输入数据,包括:
[0081]
将所述标准化阵z和所述单位特征向量运用关联公式得到的矩阵作为初始输入数据的主成分输入数据;所述关联公式为:
[0082]
j=1,2,...,m;m是主成分个数;zi是标准化矩阵z的行向量。
[0083]
优选的,所述将初始输入数据的特征向量依次组合成的矩阵作为初始输入数据的权值矩阵,包括:
[0084]
将单位特征向量依次作为列向量,得到的矩阵作为初始输入数据的权值矩阵w
p
:
[0085]
m是主成分个数;p是特征位点的个数。
[0086]
优选的,如图3所示,所述卷积神经网络模型包括多个一维卷积核和全连接神经网络;所述主成分输入数据包括训练集和验证集;
[0087]
所述将主成分输入数据运用卷积神经网络模型进行训练,包括:
[0088]
首先利用多个一维卷积核对主成分输入数据进行卷积操作,然后输入全连接层神经网络。对此过程进行卷积和神经网络的迭代训练,直到训练集和验证集的均方误差均收敛时,训练完成。均方误差的计算如式(12)所示。如图4所示,训练集和验证集的均方误差均一致接近于零,因此模型训练较好,且未发生过拟合现象。
[0089][0090]
其中,yi为真实值,y
′i为预测值。
[0091]
采用一维卷积核的原因在于,捕捉时序对玉米淀粉工艺的影响,而位点数据之间的相对位置特征对此工艺数据的知识学习没有帮助,否则机器学习模型会过于挖掘数据的特征。进行全连接神经网络模型训练,将学到的“分布式特征表示”映射到样本标记空间的作用,相当于将卷积操作提取的特征与目标联系在一起,通过不断地迭代训练和学习得出数据中隐含的规律。
[0092]
优选的,所述计算训练后的卷积神经网络模型的总权值矩阵,包括:
[0093]
1)将卷积层中同一特征不同时间的权值相加,得到卷积层的权值w
jc
:
[0094][0095]
其中,s为卷积核的个数;p为卷积核的大小;n为卷积核c在卷积操作后的大小;wh为卷积核中的权值系数;wq为全连接层中的权值系数:wq=wq1wq2,...,wqa;其中,a为全连接层的层数;
[0096]
2)将卷积层的权值w
jc
组合成的矩阵作为卷积神经网络模型的总权值矩阵wc:wc=(w
1c
,...,w
jc
)。
[0097]
优选的,所述玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵w为:w=w
p
wc。
[0098]
优选的,所述关联度分析方法,还包括:
[0099]
将所述玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵中的元素的绝对值进行排序,得到排序序列;根据排序序列的先后顺序确定玉米淀粉工艺位点对de值之间的影响程度。
[0100]
优选的,所述影响程度包括正相关和负相关;
[0101]
当玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵中的元素为负值时,确定该元素对应的玉米淀粉工艺位点对淀粉乳de值的影响程度为负相关;
[0102]
当玉米淀粉工艺位点与淀粉乳产品de值对应的关联度矩阵中的元素为正值时,确
定该元素对应的玉米淀粉工艺位点对淀粉乳de值的影响程度为正相关。
[0103]
对总权值矩阵wc中元素的绝对值进行排序,可得到对淀粉乳产品de值目标影响较大的特征位点,为下一步的工艺参数调优,提供一定的指导,结果如下表1所示。
[0104]
表1:特征位点位号与de值相关性对应表
[0105]
特征位点与de值相关性lia2103_7负相关lia2103_3正相关lia2103_5负相关lia2103_8正相关lia2103_1正相关pid1\lic1401_2_5-pv正相关level1\lia_1473_1正相关level2\lia_1590负相关pid1\lic_302a-pv负相关pid1\lic_502a-pv正相关pid1\lic1401_2_12-pv负相关pid1\lic_501a-pv负相关pid1\lic_301b-pv正相关pid1\lic_502b-pv负相关level1\lia_1401_1_5正相关level1\lia_1684正相关level2\lia_1401_3_2负相关level1\lia_1401_1_4负相关lia2103_2正相关level1\lia_1631正相关
[0106]
调整影响较大的特征位点,进行生产工艺参数的优化。比如,对淀粉乳产品de值正负影响较大的特征位点参数,分别相应调整10%,某段时间的结果如图5所示,de值累计提高21%。
[0107]
从以上技术方案可以看出,本发明具有以下优点:对玉米淀粉原料及工艺数据进行分析,得到针对不同玉米原料,影响淀粉乳产品de值均较大的特征参数,结果具有很好的普适性。通过对挖掘的特征参数进行调整,提高了产品的de值,为玉米淀粉加工生产提供了更好的辅助作用。
[0108]
通过以上数据处理、主成分分析、卷积神经网络建模、模型权值提取和确定确定优化特征位点参数五个步骤,进行了玉米淀粉工艺参数与淀粉乳产品de值的关联度分析。对玉米淀粉生产数据进行了特征选择和降维,不仅避免了大数据建模的维度灾难问题,而且保证了输入机器学习模型数据的独立性,同时进行了两次的特征提取和模型训练,在对工艺数据的时序特征进行挖掘和提取的同时,使此技术方案得到的结果更加可靠。此技术方案同样可用于其它工艺的大数据挖掘,调整生产工艺参数。从而优化产品生产、提高产品质量、维护企业生产安全。
[0109]
以上结合附图详细描述了本发明实施例的可选实施方式,但是,本发明实施例并不限于上述实施方式中的具体细节,在本发明实施例的技术构思范围内,可以对本发明实施例的技术方案进行多种简单变型,这些简单变型均属于本发明实施例的保护范围。
[0110]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明实施例对各种可能的组合方式不再另行说明。
[0111]
此外,本发明实施例的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明实施例的思想,其同样应当视为本发明实施例所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1