基于主成分分析法和神经网络的工艺优化方法
1.本发明涉及大数据的工艺建模领域,具体地涉及一种基于主成分分析法和神经网络的工艺优化方法。
背景技术:
2.随着工业飞速发展,工厂规模和产量不断扩大,产品种类不断增多,旧工厂的升级改造或为了市场需求等进行参数调节优化的过程中都存在众多困难。在众多工业工艺发展日新月异,其产品广泛应用于食品、化工、医药和其他工业过程中,在我国国民经济的发展中起着越来越重要的作用。如,以淀粉为原材料生产糖品的过程统称为淀粉糖工艺。淀粉糖工艺包含四段液化工段、糖化工段、葡糖糖过滤工段、脱色工段、四段离交工段、蒸发工段和异构化工段等,整个加工过程涉及较长的工艺路线和复杂的流程控制,由于原料体系复杂,生产工况变动频繁等因素的影响,不能针对产品质量波动做出迅速的调参指令和优化方案,往往会导致产品质量不稳定、原料利用率偏低等一系列问题。淀粉糖工艺中双酶法工艺是淀粉糖的主要生产工艺。双酶法工艺中,淀粉首先经过液化酶水解成糊精和低聚糖范围较小分子产物,随后再采用糖化酶进一步将这些产物水解成葡萄糖,最终产品包括结晶葡萄糖、全糖、葡麦糖浆和麦芽糖浆等。这是由于淀粉糖生产过程受到ph值、液糖化时间、加酶量等大量操作因素(工艺位点)的影响,仅仅依靠工程师经验进行调参过程会导致产品品质参差不齐。
3.在工厂普遍实现数字化监控和记录的基础上,充分挖掘数据本身包含的大量有用信息,开发利用隐藏在数据背后的潜在价值,通过基于大数据分析,帮助生产管理部门迅速发现影响产品质量的关键参数是我们要解决的技术难题。
技术实现要素:
4.本发明实施例的目的是提供一种基于主成分分析法和神经网络的工艺优化方法,主要解决如何确定工艺中用于优化工艺参数的位点,以提高工艺调整的效率。
5.为了实现上述目的,本发明实施例提供一种基于主成分分析法和神经网络的工艺优化方法,包括:
6.获取工艺中位点上的样本点数据;
7.将工艺中位点和所述工艺中位点上的样本点数据运用主成分分析法进行降维处理,得到工艺中位点对应的特征数据;
8.运用主成分分析法确定所述工艺中位点对应的特征数据的权重;
9.根据所述工艺中位点对应的特征数据的权重确定工艺中主要位点;
10.将所述工艺中主要位点上的样本点数据输入循环神经网络进行训练,以还原糖占糖浆干物质的百分比作为目标,训练所述循环神经网络,并根据所述循环神经网络的权值矩阵确定所述工艺中主要位点的重要度值;
11.根据所述工艺中主要位点的重要度值确定工艺中用于优化工艺参数的位点。
12.可选的,所述根据所述工艺中主要位点的重要度值确定工艺中用于优化工艺参数的位点,包括:
13.根据工艺中主要位点的重要度值按照从大到小进行排序,得到重要度值序列;
14.将重要度值序列的前n位运用双酶法淀粉糖加工工艺分析,得到工艺中用于优化工艺参数的位点。
15.可选的,在将工艺中位点上的样本点数据和工艺中位点运用主成分分析法进行降维处理之前,还包括:
16.将工艺中位点上的样本点数据进行噪声预处理。
17.可选的,所述将工艺中位点上的样本点数据和工艺中位点运用主成分分析法进行降维处理,得到工艺中位点对应的特征数据,包括:
18.将所述工艺中位点上的样本点数据和工艺中位点组合成的相关性的变量进行正交变换,将正交变换得到的变量作为工艺中位点对应的特征数据。
19.可选的,所述运用主成分分析法确定所述工艺中位点对应的特征数据的权重,包括:
20.运用主成分分析法确定所述工艺中位点对应的特征数据的变量成分矩阵、主元特征值和主元方差贡献率;
21.计算变量成分矩阵与主元特征值的算术平方根的比值,作为成分得分系数矩阵;
22.以主元方差贡献率为权重,对成分得分系数矩阵进行加权平均,得到综合得分模型系数;
23.根据所述综合得分模型系数确定所述工艺中位点对应的特征数据的权重。
24.可选的,所述根据所述综合得分模型系数确定所述工艺中位点对应的特征数据的权重,包括:
25.将所述综合得分模型系数进行归一化处理,将处理后的结果作为所述工艺中位点对应的特征数据的权重。
26.可选的,所述根据所述工艺中位点对应的特征数据的权重确定工艺中主要位点,包括:
27.将所述工艺中位点对应的特征数据的权重从大到小进行排序,得到排位序列,将排位序列的前m位对应的位点作为工艺中主要位点。
28.可选的,所述循环神经网络包括lstm和人工神经网络层;
29.将所述工艺中主要位点上的样本点数据输入循环神经网络进行训练,以还原糖占糖浆干物质的百分比作为目标,训练所述循环神经网络,包括:
30.将所述工艺中主要位点上的样本点数据分别输入lstm和人工神经网络层,以还原糖占糖浆干物质的百分比作为目标,训练所述lstm和人工神经网络层。
31.可选的,所述循环神经网络的权值矩阵的计算步骤包括:
32.将人工神经网络层中每次训练后的每个神经元的权值组成的矩阵进行矩阵相乘,得到人工神经网络层的权值矩阵;
33.将lstm的综合权值矩阵与所述人工神经网络层的权值矩阵进行矩阵相乘,得到循环神经网络的权值矩阵。
34.可选的,所述循环神经网络的权值矩阵的计算步骤包括:
35.将所述工艺中主要位点上的样本点数据分批输入人工神经网络层进行训练,每批工艺中主要位点上的样本点数据训练完成后神经元的权值的平均值作为该批训练中神经元的批权值;将所有的批权值组成的矩阵进行矩阵相乘,得到人工神经网络层的权值矩阵;
36.将lstm的综合权值矩阵与所述人工神经网络层的权值矩阵进行矩阵相乘,得到循环神经网络的权值矩阵。
37.可选的,所述根据循环神经网络的权值矩阵确定所述工艺中主要位点的重要度值,包括:
38.将循环神经网络的权值矩阵中的元素归一化,得到所述工艺中主要位点的重要度值。
39.可选的,所述根据工艺中主要位点的重要度值确定工艺中用于优化工艺参数的位点,包括:
40.将所述工艺中主要位点的重要度值进行排序的到重要度值序列,将重要度值序列的前k位对应的位点作为工艺中用于优化工艺参数的位点。
41.通过上述技术方案,通过主成分分析法筛选出影响工艺过程的主要位点,另一方面可以依据这些主要位点采用循环神经网络对过程进行基于大数据的建模,循环神经网络能有效处理时序数据,实现目标参数的精准预测,并进一步获得关键控制位点(工艺中主要位点);将关键控制位点(工艺中主要位点)运用到对于指导现场工艺参数调节具备重要意义,能够在保证产品质量的同时,最优化生产成本和加工效率。
42.本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
43.附图是用来提供对本发明实施例的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明实施例,但并不构成对本发明实施例的限制。在附图中:
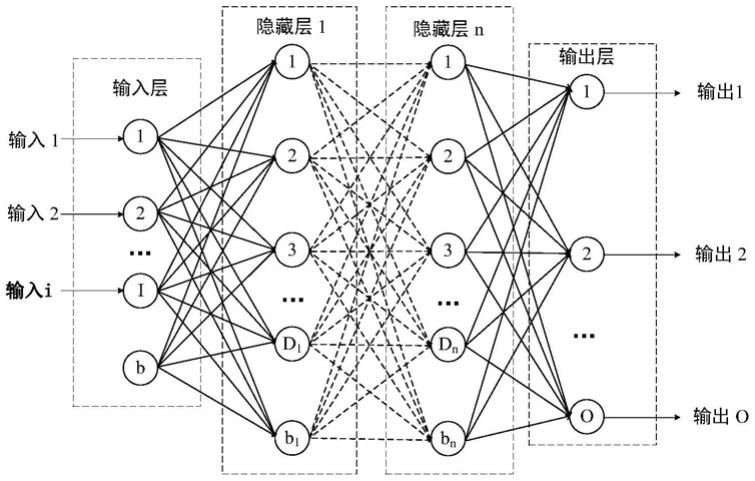
44.图1是实施例中提供一种人工神经网络层的结构示意图;
45.图2是实施例中提供的一种lstm训练效果图;
46.图3是实施例中提供的10次训练中重要度值排在前10的各个位点对应的重要度值箱线图;
47.图4是实施例中提供的一种lstm网络的结构示意图。
具体实施方式
48.以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
49.实施例1
50.本实施例选择双酶法淀粉糖加工工艺作为具体的优化实施,提供一种基于主成分分析法和神经网络的双酶法淀粉糖加工工艺优化方法。
51.一种基于主成分分析法和神经网络的双酶法淀粉糖加工工艺优化方法包括:
52.获取双酶法淀粉糖加工工艺中位点上的样本点数据;将双酶法淀粉糖加工工艺中位点和所述双酶法淀粉糖加工工艺中位点上的样本点数据运用主成分分析法进行降维处
理,得到双酶法淀粉糖加工工艺中位点对应的特征数据;运用主成分分析法确定所述双酶法淀粉糖加工工艺中位点对应的特征数据的权重;根据所述双酶法淀粉糖加工工艺中位点对应的特征数据的权重确定双酶法淀粉糖加工工艺中主要位点;将所述双酶法淀粉糖加工工艺中主要位点上的样本点数据输入循环神经网络进行训练,以还原糖占糖浆干物质的百分比作为目标,训练所述循环神经网络,并根据所述循环神经网络的权值矩阵确定所述双酶法淀粉糖加工工艺中主要位点的重要度值;根据所述双酶法淀粉糖加工工艺中主要位点的重要度值确定双酶法淀粉糖加工工艺中用于优化双酶法淀粉糖加工工艺参数的位点。通过采用主成分分析法对海量的操作位点进行降维处理,选出对过程有较大影响的主要位点。进一步地,针对工业数据大滞后、非线性、强耦合等特点引入擅长处理时序数据的循环神经网络进行建模,以筛选出的主要位点作为其输入对目标参数进行预测。本专利选择de值为目标,de值表示还原糖占糖浆干物质的百分比,是评价液糖化效果的重要指标。最后,通过一种拓展的权值连接法计算这些主要位点的重要度,对重要度进行排序,筛选出重要度排名靠前的关键位点。通过对这些关键位点的控制和调节实现工艺流程优化。
53.具体的,双酶法淀粉糖加工工艺中位点选择从dcs系统和现场测试记录数据库中收集165个位点的信息,每个位点包含13600个样本点数据。这165个位点位于de值检测点的上游工段,上游工段主要包括四段液化工段、和糖化工段;165个位点的信息为上述上游工段中的公用工程系统中的检测和操作位点。
54.可选的,在将双酶法淀粉糖加工工艺中位点上的样本点数据和双酶法淀粉糖加工工艺中位点运用主成分分析法进行降维处理之前,还包括:将双酶法淀粉糖加工工艺中位点上的样本点数据进行噪声预处理。可选的,噪声预处理包括对数据进行过异常值的筛选和剔除、数据降噪、数据补充以及修正错误处理。对于手动记录数据实现时间自动划分,采用线性插值法进行数据补充;对于时间间隔小于基准间隔的数据,采用提取平均值的方法进行数据提取;对于缺失值采用线性插值法,按照如下公式计算缺失值:
[0055][0056]
其中(x0,y0),(x1,y1)代表数据中的已知点,x表示缺失值对应的时间点,y表示该时间点的补充值。
[0057]
对于异常值的筛选和剔除采用箱型图法,将所有时间的数据放入同一个箱中,即此箱子包含全部的采样点。对所述的箱子ai=[xi,1,xi,2,
…
xi,n],将箱子中的所有数值由小到大进行排列,得到有序箱a’i=[x’i,1,x’i,2,
…
x’i,n],其中xi代表位点i,n代表采样点的个数;
[0058]
所述的箱型图法通过四分位数来检测异常值,四分位数的位置的计算公式如下:
[0059][0060]
其中l表示四分位数的序号,pl表示四分位数的位置,n表示采样点个数,根据四分位数的位置计算相应的四分位数;下四分位数q1又称“较小四分位数”,等于该样本中所有数值由小到大排列后位置位于第25%的数字,所述的下四分位数q1为:
[0061][0062]
其中表示对p1向下取整,表示对p1向上取整,n*表示正整数;
[0063]
上四分位数q3又称“较大四分位数”,等于该样本中所有数值由小到大排列后位置位于第25%的数字,所述的下四分位数q3为:
[0064][0065]
其中表示对p3向下取整,表示对p3向上取整,n*表示正整数;
[0066]
非异常值的下限qmin和上限qmax通过四分位距iqr来计算,所述的iqr计算公式为:iqr=q
3-q1;
[0067]
则qmin和qmax的计算公式分别为:
[0068]qmin
=q
1-m
·
iqr
[0069]qmax
=q3+m
·
iqr;
[0070]
其中m可以根据数据的情况和想要保留的数据个数进行更改,一般将m的值取1.5;
[0071]
数据降噪采用“(2n+1点)单纯移动平均”法来平滑滤波进行数据的降噪,其中心思想是:求出以yi为中心的前后各n个数据(yi
–
n,
…
,yi
–
1,yi,
…
yi+n)求得平均值yi’代替yi,公式如下:
[0072][0073]
进一步的,将上面经过噪声预处理后的双酶法淀粉糖加工工艺中位点上的样本点数据和双酶法淀粉糖加工工艺中位点运用主成分分析法进行降维处理,得到双酶法淀粉糖加工工艺中位点对应的特征数据。具体的,将所述双酶法淀粉糖加工工艺中位点上的样本点数据和双酶法淀粉糖加工工艺中位点组合成的相关性的变量进行正交变换,将正交变换得到的变量作为双酶法淀粉糖加工工艺中位点对应的特征数据。主成分分析法是一种使用最广泛的数据降维方式,通过正交变换将一组可能存在相关性的变量转化为一组线性不相关的变量,转换后的这组变量叫做主成分,即在原有的n维特征基础上通过主成分分析法重新构造出k维特征,从而达到降维的目的。本实施例中将165个位点的信息和对应的位点包含13600个样本点数据,通过主成分分析法构建的一组新的特征矩阵,作为双酶法淀粉糖加工工艺中位点对应的特征数据。
[0074]
进一步的,双酶法淀粉糖加工工艺中位点对应的特征数据无法直接反映输入位点的重要程度,所以需要求双酶法淀粉糖加工工艺中各个位点的权重,双酶法淀粉糖加工工艺中各个位点的权重也即是位点对应特征数据的权重。具体的,运用主成分分析法确定所述双酶法淀粉糖加工工艺中位点对应的特征数据的变量成分矩阵、主元特征值和主元方差贡献率;计算变量成分矩阵与主元特征值的算术平方根的比值,作为成分得分系数矩阵;以主元方差贡献率为权重,对成分得分系数矩阵进行加权平均,得到综合得分模型系数。根据
所述综合得分模型系数确定所述双酶法淀粉糖加工工艺中位点对应的特征数据的权重。可选的,将所述综合得分模型系数进行归一化处理,将处理后的结果作为所述双酶法淀粉糖加工工艺中位点对应的特征数据的权重。
[0075]
具体的,所述根据所述双酶法淀粉糖加工工艺中位点对应的特征数据的权重确定双酶法淀粉糖加工工艺中主要位点,包括:
[0076]
将所述双酶法淀粉糖加工工艺中位点对应的特征数据的权重从大到小进行排序,得到排位序列,将排位序列的前m位对应的位点作为双酶法淀粉糖加工工艺中主要位点。双酶法淀粉糖加工工艺中位点对应的特征数据的权重越大则对应的位点越重要,本实施例选择权重最大的前50个位点作为双酶法淀粉糖加工工艺中主要位点。
[0077]
进一步的,将50个双酶法淀粉糖加工工艺中主要位点上的样本点数据输入循环神经网络(lstm和人工神经网络层)进行训练,以还原糖占糖浆干物质的百分比作为目标,训练所述循环神经网络,具体的,将50个双酶法淀粉糖加工工艺中主要位点上的样本点数据分别输入lstm和人工神经网络层,以还原糖占糖浆干物质的百分比作为目标,训练所述lstm和人工神经网络层。训练循环神经网络采用长短时记忆模型(lstm)架构,lstm模型在传统的循环神经网络模型基础上通过引入“门”的概念,从而解决了循环神经网络模型存在的梯度消失和梯度爆炸问题;该网络由lstm层加人工神经网络层构成,其中人工神经网络层的结构如图1所示,lstm层的结构原理如图4所示。建模基于keras开展,相关参数设置如下:时间步长为5,迭代次数设置为300次,以均方根误差(mse)为损失函数,优化器选择adam。训练完成后,模型mse为0.16%,训练迭代过程如图2所示,可见该模型既不存在过拟合问题,也能保持较高精度。
[0078]
可选的,在一种可能的实施例中,上述循环神经网络的权值矩阵的计算步骤包括:
[0079]
将人工神经网络层中每次训练后的每个神经元的权值组成的矩阵进行矩阵相乘,得到人工神经网络层的权值矩阵;将lstm的综合权值矩阵与所述人工神经网络层的权值矩阵进行矩阵相乘,得到循环神经网络的权值矩阵。
[0080]
可选的,在又一种可能的实施例中,由于循环神经网络训练过程中的权值存在随机性,因此对循环神经网络训练15次,取权值平均值(批权值)进行分析计算。具体的,所述循环神经网络的权值矩阵的计算步骤包括:
[0081]
将所述双酶法淀粉糖加工工艺中主要位点上的样本点数据分批输入人工神经网络层进行训练,每批双酶法淀粉糖加工工艺中主要位点上的样本点数据训练完成后神经元的权值的平均值作为该批训练中神经元的批权值;将所有的批权值组成的矩阵进行矩阵相乘,得到人工神经网络层的权值矩阵,然后将lstm的综合权值矩阵与所述人工神经网络层的权值矩阵进行矩阵相乘,得到循环神经网络的权值矩阵。
[0082]
具体的,人工神经网络层的权值矩阵的公式为:
[0083][0084]
其中,oi表示神经元输出值,w
ij
和v
jk
表示隐含层权值,i和j表示相应的变量个数。
该公式是通过将每个神经元的权值归一化后,再对其进行权值的矩阵相乘,得到人工神经网络层的权值矩阵。
[0085]
lstm的综合权值矩阵的求解具体如下:
[0086]
lstm层包括遗忘门、输入门、候选门、记忆门和输出门,下文介绍了各个门的运算机理:
[0087]
lstm层来说,该层包括遗忘门、输入门、候选门、记忆门和输出门,下文介绍了各个门的运算机理:
[0088]
遗忘门f
t
=σ(wf·
[h
t-1
,x
t
]+bf),其中wf表示遗忘门权值,bf表示遗忘门阈值,σ表示sigmoid函数;
[0089]
输入门i
t
=σ(wi·
[h
t-1
,x
t
]+bi),其中wi表示遗忘门权值,bi表示遗忘门阈值;
[0090]
候选门其中wc表示候选门权值,bc表示遗忘门阈值;
[0091]
记忆门记忆门表示矩阵按照元素相乘;
[0092]
输出门o
t
=σ(wo·
[h
t-1
,x
t
]+bo),其中wo表示输出门权值,bo表示输出门阈值;
[0093]
最终输出值为:h表示输出值,x表示输入值,其中h和x的下标表示不同时刻。
[0094]
依据lstm层的原理,采用olden权值连接法的思想,可以推导出lstm层综合权值矩阵的计算公式为:其中w
lstm
表示lstm层的综合权值,w
inor
,w
cnor
,w
onor
分别表示wf,wi,wc,wo标准化后的数值。
[0095]
最后将上述的lstm的综合权值矩阵w
lstm
与所述人工神经网络层的权值矩阵进行矩阵乘法,得到循环神经网络的权值矩阵。然后将循环神经网络的权值矩阵中的元素归一化,归一化后的循环神经网络的权值矩阵中的元素对应所述双酶法淀粉糖加工工艺中主要位点的重要度值。
[0096]
将所述双酶法淀粉糖加工工艺中主要位点的重要度值进行排序的到重要度值序列,将重要度值序列的前10位对应的位点作为双酶法淀粉糖加工工艺中用于优化双酶法淀粉糖加工工艺参数的位点。前10的位点如表1中所示。
[0097]
序号位点位点含义重要度值x1糖化酶糖化酶流量0.169629x2ti1113_5液化柱温度测量0.059181x3tc1107_2.mv一次闪蒸不凝气调节阀0.051036x4tc1111_2.mv二次闪蒸不凝气调节阀0.040574x5sic6120.mv异构用酸频控0.039223x6fiq1125液化酶流量累积0.035748x7dsq1104淀粉乳来绝干流累积0.035432x8fiq1105一喷蒸汽进流量累积0.035225x9dsq1103淀粉乳出绝干流量累积0.034611x10si1109b二次喷射信号反馈二0.033754
[0098]
表一:前十的位点的信息详细表
[0099]
将重要度排名前10位点在10次训练中的重要度值绘制到箱线图中,如图3所示。由
图3可知,每次训练连过程中权值虽然会有波动,但整体保持稳定性,证明该拓展的权值连接法的有效性。经过对找出的10位点进行工艺分析可知,糖化酶流量、液化柱温度测量、液化酶流量累积、淀粉乳来绝干流量累积、淀粉乳出绝干流量累积等位点与de值,即淀粉糖产品质量之间存在明显的机理可解释性关系;而部分位点如一次闪蒸不凝气调节阀、二次闪蒸不凝气调节阀、异构用酸频控、一喷蒸汽进流量累积、二次喷射信号反馈二等与de值之间不存在明显的机理可解释性关系,这些位点需要厂方加强关注,通过现场试验验证。所筛选出的关键位点可以辅助工厂方进行生产过程的参数调节,从而优化淀粉糖生产过程、提高淀粉糖质量、维护企业生产安全。本发明原理简单、可拓展性良好,还能适用于其他的流程工业建模和关键位点筛选过程中,具备十分广阔的应用前景。
[0100]
以上结合附图详细描述了本发明实施例的可选实施方式,但是,本发明实施例并不限于上述实施方式中的具体细节,在本发明实施例的技术构思范围内,可以对本发明实施例的技术方案进行多种简单变型,这些简单变型均属于本发明实施例的保护范围。
[0101]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明实施例对各种可能的组合方式不再另行说明。
[0102]
此外,本发明实施例的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明实施例的思想,其同样应当视为本发明实施例所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1