一种基于链接技术的云存储文件去重方法与流程
1.本发明隶属于云存储和文件系统技术领域,具体涉及一种基于链接技术的云存储文件去重方法。
背景技术:
2.当前背景下,云存储技术往往应用在多个场景之中。例如运营商用申请云存储服务,开辟用户图片和视频存储空间;用户使用云存储空间分享自己的存储文件,进行文件归档和数据容灾;数据服务商利用云存储进行分布式静态文件缓存等等。这些应用场景有一些共同的特征,即存储空间占用大,访问频率和带宽占用增长快,同一文件含多个副本等等。
3.若想以最小的代价存储最多的文件,将带来存储成本和传输成本的全面下降。因此,如何降低文件存储成本成为云存储方案重要考量之一。
4.目前市面上有一些利用云存储或本地存储执行数据去重的技术,但这些技术大多完全依赖于本地离线计算结果,即计算出每一文件的哈希值,然后比对哈希值,并将这些重复文件的关联信息记录在本地;在请求访问文件时,利用这些本地已经计算好的关联信息进行访问跳转。对于分布式要求高的系统,这意味着需要多点部署数据库,并保持关联数据的同步,实施难度及成本均高。
5.因此,需要一种性能更优越的云存储文件去重方法。
技术实现要素:
6.本发明所要解决的技术问题是克服现有技术的不足,提供一种性能更优越的云存储文件去重方法。
7.为解决上述技术问题,本发明提供一种基于链接技术的云存储文件去重方法,在云存储内创建并保存重复文件的链接文件,并利用链接文件保存链接信息,每个链接文件的链接信息顺序地记录重复文件在云存储内的位置,实现对真实文件与各个重复文件的串联,用户对任一重复文件的访问,都将通过链接文件的遍历寻找到真实文件。由于链接文件小,且链接信息保存在云存储内,并不依赖于本地存储,有利于实现在分布式环境中文件去重的单点计算和多点独立访问的特性,有效解决重复文件过多导致的云存储空间占用过大、带宽成本增高的问题,同时又能简单便利地应用在分布式系统中;其特征在于,包含如下步骤:
8.步骤1:配置本地的文件信息表,所述文件信息表用于记录云存储系统内现有文件的文件信息,所述文件信息包含文件内容、存储路径;所述文件信息表的配置项包含文件内容的哈希值和文件的储存路径;
9.步骤2:获取待上传文件的文件内容,解析文件内容,计算文件内容的哈希值;获取本地的文件信息表,在文件信息表中检索是否存在与所述文件内容的哈希值一致的文件信息;若不存在,判定所述待上传文件为真实文件,执行步骤3;若存在,判定所述待上传文件
为重复文件,执行步骤4;
10.步骤3:调用云存储系统的文件上传接口,将真实文件的文件信息上传至云存储系统内,并在文件信息表中记录文件内容的哈希值和文件储存路径;
11.步骤4:将本次待上传的重复文件新建为链接文件,将链接文件的文件信息存入云存储系统内,并在文件信息表中记录链接文件的文件内容的哈希值和文件储存路径,所述链接文件的文件内容的哈希值为经步骤2计算获得的文件内容的哈希值;
12.步骤5:遍历云存储系统内的现有文件的文件信息,执行文件去重访问,获取云存储系统内的真实文件的文件信息。
13.所述步骤2中计算哈希值的算法为md5;所述步骤2中的云存储系统为亚马逊s3。
14.所述步骤4中包括:以预设的文本键值对标记新建的链接文件;在新建的链接文件的文件内容中,写入链接文件的魔数值、版本号及链接位置;所述链接文件的魔数值、版本号均是预设的具有固定字节数的标识符;从文件信息表中获取与步骤2中文件内容的哈希值相同的现有文件的文件信息,按照现有文件上传的时间顺序,取最后上传的现有文件的储存路径为链接位置;待链接文件的文件信息存入云存储系统中,以文件元数据的形式保存文本键值对。
15.所述步骤4中,所述在新建的链接文件的文件内容中,写入链接文件的魔数值、版本号及链接位置,是从文件内容的头部开始依次写入链接文件魔数值、版本号及链接位置;
16.所述步骤5包括:提取文件信息访问请求中的存储路径,按照存储路径从云存储系统中获取文件内容及文本键值对;比对文本键值对是否与步骤4中链接文件的文本键值对一致;若不一致,判定当前获取的文件为真实文件;将真实文件的文件信息返回给浏览器端;若一致,判定当前获取的文件为链接文件,提取文件内容中的链接位置,按照链接位置指向的储存路径,继续从云存储系统中获取文件内容及文本键值对,比对文本键值对,直至根据比对结果判定文件为真实文件为止。
17.所述步骤4中,所述文本键值对的键为content-type,值为自定义mime类型;链接文件的文本键值对表示为《content-type,自定义mime类型》;所述文本键值对的存储通过亚马孙s3的文件元数据功能实现存储;待从亚马逊s3中获取文件信息的同时获取文件元数据中的文本键值对。
18.所述步骤5中,比对文本键值具体包含:
19.步骤501:比对文本键值对是否为键为content-type的键值对,且所述键为content-type的键值对中的值是否与步骤4中自定义mime类型一致;若上述两者均满足,则文件判定为链接文件;若上述两者不满足,则文件判定为真实文件;
20.步骤502:若文件判定为链接文件,从链接文件内容的头部开始计算链接文件魔数值及链接文件版本号占据的固定字节数,以固定字节数加1的位置为起始位置,从起始位置开始提取所有文件内容作为链接位置。
21.在所述步骤1-步骤5中,若云存储系统不支持mime类型的存储,则根据链接文件魔数值判定文件是否为链接文件,具体是根据预设链接文件魔数值占据的字节数,从文件内容头部提取相同字节数的内容,若提取的内容与步骤4预配的链接文件魔数值一致,则判定为链接文件;若不是,则判定为真实文件。
22.本发明所达到的有益效果为:
23.本发明通过离线计算云存储文件的哈希值,为重复文件创建内容极小的链接文件,减少云存储的容量,降低上传文件时的带宽占用。与现有技术相比,减少了分布式系统访问时所需要的链接关系存储,降低了本地存储的成本。此外,虽然多次访问看似会降低文件访问的性能,但由于链接文件极小,因而访问速度极快,性能损耗几乎可以忽略不计。
附图说明
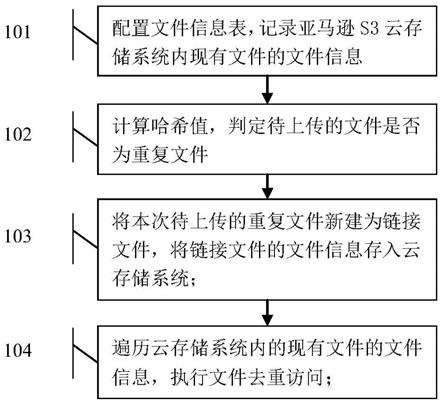
24.图1为本发明实施例中基于链接技术的文件去重方法实现流程示意图
25.图2为本发明实施例中链接文件内容的结构示意图;
26.图3为本发明实施例中文件去重访问的流程示意图;
27.图4为本发明实施例中基于链接技术的云存储内文件去重的系统结构示意图;
28.图5为本发明实施例中基于链接技术的云存储文件去重的系统部署图;
具体实施方式
29.下面结合附图和示例性实施例对本发明作进一步的说明。
30.本发明实施例中以亚马逊s3为云存储系统;所述亚马逊s3,全称为亚马逊简易存储服务(amazon simple storage service),是一个由亚马逊网络服务(amazon web services,简称aws)提供的服务,它通过通过多种通信方式提供对象存储服务。亚马逊s3可以被用来存储任何类型的对象,这些对象可以被用于类似互联网应用的存储、备份和恢复、灾备、数据归档、用于分析的数据湖,以及混合云存储。比如,用户上传图片到亚马逊s3云储存系统中,亚马逊s3云存储系统为帮助用户在全球各个地方快速展示图片给目标客户,将上传至云存储系统的图片同步到亚马逊s3的各个边缘节点,以加速当地客户访问。
31.如图1所示的本发明实施例中一种基于链接技术的文件去重方法实现流程示意图,具体包含:
32.步骤101:储存路径配置本地的文件信息表,所述文件信息表用于记录亚马逊s3云存储系统内现有文件的文件信息,所述文件信息包含文件内容、储存路径;所述文件信息表的配置项包含文件内容的哈希值和文件的储存路径;任一文件上传至亚马逊s3云存储系统后,获取储存路径存入文件信息表中;所述文件包含文档、图片、视频及音频;
33.步骤102:计算哈希值,判别待上传的文件是否为重复文件,具体为:获取待上传至亚马逊s3云存储系统中的文件信息,解析文件内容,利用md5算法对文件内容计算哈希值;在文件信息表中检索是否存在与所述哈希值一致的文件信息,若存在,则云存储系统内存在与所述文件内容相同的文件信息,判定所述待上传文件为重复文件,执行步骤103;若不存在,则云存储系统内不存在与所述文件内容相同的文件信息,判定待上传文件为真实文件,调用上传服务接口,将文件上传至云存储系统中,同时在文件信息表中保存所述文件的文件内容哈希值及储存路径;
34.步骤103:将本次待上传的重复文件新建为链接文件,将链接文件的文件信息存入云存储系统内,并在文件信息表中记录链接文件的文件内容的哈希值和文件储存路径,所述链接文件的文件内容的哈希值为经步骤102计算获得的文件内容的哈希值;
35.具体流程包含:首先,以预设的文本键值对标记新建的链接文件;其次,在新建的链接文件的文件内容中,写入链接文件的魔数值、版本号及链接位置;所述链接文件的魔数
值、版本号均是预设的具有固定字节数的标识符;从文件信息表中获取与步骤102中文件内容的哈希值相同的现有文件的文件信息,按照现有文件上传的时间顺序,取最后上传的现有文件的储存路径为链接位置;最后,待链接文件的文件信息存入云存储系统中,以文件元数据的形式保存文本键值对;
36.所述新建为链接文件具体流程包含:
37.步骤103-1:写入链接文件的内容,包含依次写入文件类型魔数值、链接文件版本号、链接位置;
38.所述写入链接文件魔数值:将预设的链接文件魔数值写入文件头部,比如写入“link”;
39.所述写入链接文件版本号:在链接文件魔数值之后,将预设的链接文件版本号写入文件内容,比如在“link”之后写入“v1.0”;
40.所述写入链接位置:从文件信息表中获取与所述重复文件的哈希值相同的文件信息记录,按照文件上传的时间,从前至后排序,取最后一个文件信息记录中的云存储位置作为链接位置的值,写在链接文件版本号之后;
41.所述写入代码配置在文件上传程序中,具体如下:
42.private byte[]createlinkfile(string filelocation,byte version){
[0043]
//魔数值定义
[0044]
final string magic_number="link";
[0045]
//按顺序拼接三组字节,分别是魔数的字节、版本的字节、文件位置
[0046]
return combinebytes(magic_number.getbytes(standardcharsets.utf_8),new byte[]{version},filelocation.getbytes(standardcharsets.utf_8));
[0047]
如图2的所示的本发明示例性实施例中的链接文件内容的结构示意图,链接文件内容以链接文件魔数值“link”开头,紧跟着版本号“v0.1”,版本号后所有字节均为重复文件的前一个链接文件在云存储内的位置,如图中“position”。由于链接文件魔数值和链接文件版本号为预设值,具有固定字节数;因此从文件头开始计算,固定字节数之后的所有字节均是链接位置;
[0048]
步骤103-2:以预设的文本键值对标记新建的链接文件,具体为:在文件上传至亚马逊s3云存储系统的过程中,文件上传程序为文件增加预设的文本键值对;在所述文本键值对中,所述键为content-type,所述值为mime类型;所述mime类型包含mime类型常规值及自定义mime类型值;利用亚马逊s3云存储系统的文件元数据功能,对上传至亚马逊s3的文件,在文件元数据中保存文本键值对;
[0049]
针对非链接文件,mime类型根据文件类型标记公开的mime类型常规值;比如image/jpg,text/html等。针对链接文件,mime类型为自定义mime类型,比如“application/vnd.mic-link”;
[0050]
所述标记链接文件的代码配置在文件上传程序中,如下:
[0051]
[0052][0053]
在上述代码中,所述文本键值对写入文件上传程序中,在上传文件时为文件增加一个键值对,以链接文件为例,写入《content-type,application/vnd.mic-link》;所述键值对将在获取文件时用于判断文件是否为链接文件;
[0054]
mime类型(multipurpose internet mail extensions,一种公开的互联网文件传输类型定义)的组成结构为type/subtype;由类型与子类型两个字符串中间用'/'分隔而组成。不允许空格存在。type表示可被分为多个子类的独立类别;subtype表示细分后的每个类型。所有人都可以自定义mime类型,为了避免重复和误解,私人或公司制定协议时需要在子类型上加上vnd的前缀,并辅以实体的标识,然后才是文件类型。例如,application/vnd.ms-excel,其中vnd是标识这个mime类型是自定义的,ms是微软,excel是文件的实际格式。
[0055]
步骤104:遍历云存储系统内的现有文件的文件信息,执行文件去重访。
[0056]
如图3所示的本发明示例性实施例中文件去重访问的流程示意图,具体流程包含:
[0057]
步骤104-1:用户通过浏览器请求访问亚马逊s3云存储系统内现有文件的文件信息,云存储系统的服务器响应请求,获取文件信息请求中的储存储存路径,并依据储存路径从亚马逊s3云存储系统内提取文件信息及文件元数据;
[0058]
步骤104-2:从文件元数据中提取键为content-type的文本键值对,比对所述文本键值对中的值是mime类型常规值还是自定义mime类型值,所述自定义mime类型值如步骤103的application/vnd.mic-link;
[0059]
若所述文本键值对中的值是mime类型常规值,判定当前获取的文件为真实文件;将真实文件的文件信息返回给浏览器端;
[0060]
否所述文本键值对中的值是application/vnd.mic-link,则判定获取的文件为链接文件,提取链接文件的文件信息,解析获取文件内容中的链接位置,得到上一个重复文件的文件信息在亚马逊s3云存储系统中的储存路径;
[0061]
104-3:按照步骤104-2的储存路径,从亚马逊s3云存储系统中提取文件信息,按照步骤104-2判定文件,直至判定文件为真实文件并将文件内容返回浏览器端;
[0062]
在本发明实施例中,由于预设的链接文件魔数值和链接文件版本号占据固定字节数,比如约定的链接文件魔数值是“mic-link”,占用8个字节,然后链接文件版本号1.0,占用一个字节,共及9个字节,那么从第10个字节开始往后都是链接位置。
[0063]
在本发明实施例中,部署在各地的访问工作站同时在访问亚马逊s3云存储系统站
点时,各工作站对提取的文件进行mime类型判断,以此确认文件是否为链接文件。由于亚马逊s3服务本身可以为其进行文件类型的标记,单独为链接文件设定一个自定义mime类型:application/vnd.xx-link。这样,在访问图片时,可以快速获知图片的类型。对于普通图片,我们使用它原有的mime格式,例如image/png,image/jpg等。
[0064]
如图4所示的本发明示例性实施例中基于链接技术的云存储内文件去重的系统结构示意图,具体包含配置在本地机房的本地文件服务器、应用服务器、云存储系统和文件信息数据表;将本发明的文件去重系统部署在所述应用服务器中;
[0065]
所述本地文件服务器用于发起文件信息的上传请求;
[0066]
所述应用服务器内配有重复计算模块、文件去重模块、文件上传模块、文件访问模块;
[0067]
所述重复计算模块用于对上传文件的文件内容执行哈希值计算及调用文件信息数据表执行哈希值比对,进而判断待上传文件是否与云存储内文件重复;
[0068]
所述文件去重是根据文件是否重复执行不同操作,针对不重复文件交由文件上传模块;针对重复文件生成为一个链接文件交由文件上传模块;
[0069]
所述文件上传模块用于调用云存储系统的文件上传接口,执行真实文件及链接文件上传至云存储系统内;
[0070]
所述文件访问模块用于根据文件存储位置获取云存储系统内的文件;
[0071]
所述云存储系统为亚马逊s3云存储系统,用于存储真实文件及重复文件对应的链接文件;
[0072]
在本地机房内部署不少于1个的上传服务器;允许多个上传服务器并发执行文件上传;
[0073]
在链接文件内容中保存上一个重复文件的链接文件在云存储系统中的存储位置,通过将真实文件及多个重复文件的存储位置的链接信息保存在云服务端,让文件访问去重不再依赖本地的文件信息数据表,去除了分布式环境中的关联数据同步步骤,以更简洁及低成本的方式实现云储存系统内的访问去重。
[0074]
如图5所示的本发明示例性实施例中一种基于链接技术的云存储文件去重的系统部署图,包含文件上传服务器、文件记录表、云存储系统、访问代理;在系统部署层次上。多个上传服务器可以并发执行图片文件的上传任务。它们共同依赖一个本地的文件记录表。依靠这个本地的文件记录表,上传服务器可以比较md5信息,从而判定一张特定的图片是否曾经上传过。访问代理即云存储的访问服务,此服务不依赖于本地文件记录表——因为链接信息已经以链接文件的形式上传到云端了。多个访问代理可以同时并发运作。
[0075]
本发明提供一种基于链接技术的云存储文件去重方法,其有益效果在于:
[0076]
通过离线计算云存储文件的哈希值,为重复文件创建内容极小的链接文件,减少云存储的容量,降低上传文件时的带宽占用。与现有技术相比,减少了分布式系统访问时所需要的链接关系存储,降低了本地存储的成本。此外,虽然多次访问看似会降低文件访问的性能,但由于链接文件极小,因而访问速度极快,性能损耗几乎可以忽略不计。
[0077]
以上实施例不以任何方式限定本发明,凡是对以上实施例以等效变换方式做出的其它改进与应用,都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1