一种基于人工智能OCR的电子秤图像文字识别方法与流程
一种基于人工智能ocr的电子秤图像文字识别方法
技术领域
1.本发明涉及人工智能领域,具体涉及一种基于人工智能ocr的电子秤图像文字识别方法。
背景技术:
2.ocr文字识别技术,ocr是指光学设备(扫描仪、数码相机等)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,其本质就是利用光学设备去捕获图像并识别文字,将人眼的能力延伸到机器上。ocr技术应用领域比较广泛,证件识别、车牌识别,智慧医疗,pdf文档转换为word,拍照识别、截图识别、网络图片识别,无人驾驶,无纸化办公、稿件编辑校对,物流分拣,舆情监控,文档检索,字幕识别,文献资料检索等。
3.电子秤是用来对货物进行称重的自动化称重设备,通过传感器的力电转换,经称重仪表处理来完成对货物的计量。
4.随着智能化时代的发展,远程电子秤图像识别也有了需求。通过一张图像识别出图像中计量值,在远程数据校对、无人值守等场景也得到应用。
技术实现要素:
5.本发明要解决的技术问题是,现有技术不能准确实现电子秤图像识别。
6.本发明提供一种基于人工智能ocr的电子秤图像文字识别方法,其特征在于,包括以下步骤:
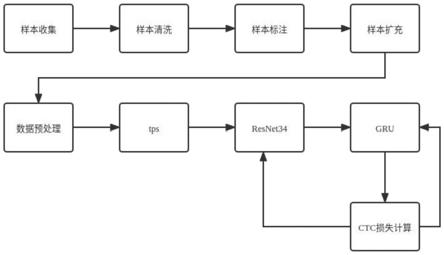
7.s1:样本收集步骤,收集电子秤文字图像数据,视频图像抽帧得到相应图像;
8.s2:样本清洗步骤,剔除重复电子秤图像数据,剔除没有所需电子秤文字的图像数据;
9.s3:样本标注步骤,使用4点标注法方便文字裁剪后快速倾斜矫正,使用ppocr标签标注工具,同时标注文字位置与文字内容,完成标注后裁剪导出图像数据,查看图像是否有倒立图像,有倒立图像则手动旋转180度使之图像正放;
10.s4:样本扩充步骤,对样本进行扩充。
11.s5:数据预处理步骤,数据在送入模型训练之前需要对数据进行处理加工,对输入图像数据归一化,调整到合适大小维度,对数据标签转成数字序列。
12.s6:采用第一算法处理图像数据,第一算法输入为两张图像中多组相同部位的匹配点对,输出为两张图像的相同部位的坐标映射;
13.s7:数据通过resnet34提取特征,第一神经网络处理后,经ctc损失计算优化resnet34、第一神经网络模型中的权重。
14.本发明的有益效果是,采用本发明提供的方法可以准确实现电子秤图像文字识别。
附图说明
15.图1为本发明的一种基于人工智能ocr的电子秤图像文字识别方法整体步骤图。
16.图2为本发明的一种基于人工智能ocr的电子秤图像文字识别方法resnet34网络结构图实现。
具体实施方式
17.本发明提供基于人工智能ocr的电子秤图像文字识别方法,该方法包括以下步骤:
18.s1:样本收集,在互联网上收集电子秤文字图像数据,视频图像可以抽帧得到相应图像。
19.s2:样本清洗,电子秤文字图像数据本身类型也比较多,需要规范哪些需要的种类。收集的数据比较混乱,往往有很高的重复性以及图像没有文字或者文字不全等等,所以需要先剔除重复电子秤图像数据,再剔除没有所需电子秤文字的图像数据,文字不全的图像可以根据情况保留与剔除。
20.s3:样本标注,ocr文字图像需要标注图像中的文字与图像中文字的位置,这里使用4点标注法方便文字裁剪后可以快速倾斜矫正。本发明使用的是ppocr标签标注工具,它可以同时标注文字位置与文字内容。完成标注后裁剪导出图像数据,查看图像是否有倒立图像,有倒立图像则手动旋转180度使之图像正放。电子秤文字图像中是没有竖着或倒立显示,所有本发明这里图像只需关注正放情况。
21.s4:样本扩充,ocr文字识别本身需要大量的数据,每个字符标签都需要包含在内,同时电子秤文字类型多情况复杂,背景干扰等情况。现有收集的数据满足不了上面的条件,所以对样本进行扩充。
22.s5:数据预处理,数据在送入模型训练之前需要对数据进行处理加工,对输入图像数据归一化,调整到合适大小维度,对数据标签转成数字序列。将输入图像大小变换成100*32的图像大小,映射图像区域值[0,255]空间到[-1,1]空间区域。
[0023]
s6:第一算法输入为两张图像中多组相同部位的匹配点对,输出为两张图像的相同部位的坐标映射。第一算法采用以下公式实现,
[0024]
φ(x)=c+a
t
x+w
t
s(x)
[0025]
s(x)=(σ(x-x1),σ(x-x2),...,σ(x-xn))
t
[0026][0027]
公式中x表示输入数据,c表示标量,向量a∈r2×1,r表示实数集,权重w∈rn×1,n表示x的长度,t表示转置,表示输入数据x的n-范式后平方。
[0028]
s7数据通过第一算法处理,resnet34提取特征,第一神经网络处理后,经ctc损失计算优化resnet34、第一神经网络模型中的权重。
[0029]
resnet34,resnet(residual neural network)resnet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时resnet的推广性非常好,甚至可以直接用到inceptionnet网络中。传统的卷积网络或者全连接网络在信息传递的时候或多或少会存在信息丢失,损耗等问题,同时还有导致梯度消失或者梯度爆炸,导致很深的网络无法训练。resnet在一定程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息
的完整性,整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度。
[0030]
resnet34过程如图2所示:
[0031]
7*7卷积核,步长为2,通道为64的卷积层;
[0032]
2*2最大池化层;
[0033]
2次3*3卷积核,通道为64的卷积层,并将计算后与计算前的结果做一次融合;
[0034]
重复上一个步骤3次;
[0035]
3*3卷积核,步长为2,通道为128的卷积层,3*3卷积核,通道为128的卷积层,并将计算后与开始时的结果做一次融合;
[0036]
2次3*3卷积核,通道为128的卷积层,并将计算后与计算前的结果做一次融合;
[0037]
重复上一个步骤3次;
[0038]
3*3卷积核,步长为2,通道为256的卷积层,3*3卷积核,通道为256的卷积层,并将计算后与开始时的结果做一次融合;
[0039]
2次3*3卷积核,通道为256的卷积层,并将计算后与计算前的结果做一次融合;
[0040]
重复上一个步骤5次;
[0041]
3*3卷积核,步长为2,通道为512的卷积层,3*3卷积核,通道为512的卷积层,并将计算后与开始时的结果做一次融合;
[0042]
2次3*3卷积核,通道为512的卷积层,并将计算后与计算前的结果做一次融合;
[0043]
重复上一个步骤2次;
[0044]
2*2平均池化层;
[0045]
第一神经网络采用以下公式构建。
[0046]zt
=σ(wz·
[h
t-1
,x
t
])
[0047]rt
=σ(wr·
[h
t-1
,x
t
])
[0048][0049][0050][0051]
公式中wz表示更新门z
t
中的权重,σ表示激活函数,h
t-1
表示上一个时刻的输出,h
t
表示当前时刻的输出,x
t
表示当前出入,wr表示重置门r
t
中的权重,w表示候选隐藏状态中的权重,tanh为双曲正切函数。
[0052]
ctc损失,ctc的全称是connectionist temporal classification.这个方法主要是解决神经网络标签和output不对齐的问题。常用于文字识别,语音,自然语言等任务中。
[0053]
本发明的有益效果是,采用本发明提供的方法可以准确实现电子秤图像文字识别。
[0054]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修
改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1