基于人工智能的林地生活垃圾样本数据扩增方法和系统与流程
1.本发明属于城市管理技术领域,特别涉及一种基于人工智能的林地生活垃圾样本数据扩增方法和系统。
背景技术:
2.在大数据图像处理中,以卷积神经网络为代表的深层结构具有更高的性能,但同时需要相对更多的标签训练样本。目前,在对林地中生活垃圾的管理中,已经运用到了高空图像识别深度学习模型,但是遇到的难题是,虽然林地内生活垃圾图像获取渠道较多,但数据标注的过程往往耗资巨大,林地生活垃圾识别面临标签样本缺乏的困难。
技术实现要素:
3.本发明实施例之一,一种基于gcgan算法的林地内生活垃圾样本数据扩增方法,利用搭载相机的无人机采集的林地生活垃圾图像样本,对所述林地生活垃圾图像样本进行标注后,利用dcgan网络模型生成林地生活垃圾图像,并将该扩增的林地生活垃圾图像加入林地生活垃圾样本集。所述的dcgan网络模型包括,
4.判别器,对于输入的虚假图像和真实图像,判别其真伪;
5.生成器,生成接近真实图像的虚假图像。
6.本发明实施例的数据扩增可以增加训练集的样本,有效缓解模型过拟合的情况,使得训练数据尽可能的接近测试数据,从而提高预测精度。另外样本扩增可以迫使网络学习到更鲁棒性的特征,从而使模型拥有更强的泛化能力,比如对图像进行一定程度的遮挡。
附图说明
7.通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
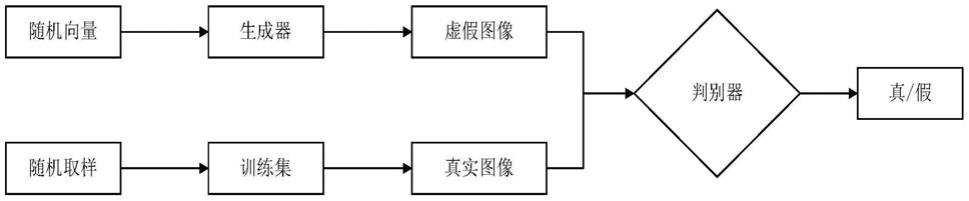
8.图1生成对抗网络模型结构示意图。
9.图2根据本发明实施例之一的基于gcgan算法的林地内生活垃圾样本数据扩增方法流程图。
具体实施方式
10.林地样本数据规模是林业智能识别算法性能的关键,利用少量已有数据扩增得到大量林业样本数据成为林业场景识别需要解决的问题。而林地垃圾的种类非常多样,例如,林地内生活垃圾主要有:
11.1)废纸张:报纸、纸箱、书本、纸塑铝复合包装和纸袋等。
12.2)废塑料:塑料瓶、玩具、油桶、乳液罐、食品保鲜盒、泡沫塑料和衣架等。
13.3)废玻璃制品:酒瓶、玻璃放大镜和玻璃杯等。
14.4)废金属:易拉罐、锅和电线等。
15.5)废织物:皮鞋、衣服、床单、枕头、包和毛绒玩具等。
16.6)废杀虫剂和消毒剂的包装物等。
17.7)废胶片及废相纸:x光片等感光胶片、相片底片等。
18.8)食材废料:谷物及其加工食品、肉蛋及其加工食品、水产及其加工食品、蔬菜、调料和酱料等。
19.9)干垃圾:餐巾纸、卫生间用纸、尿不湿、狗尿垫、猫砂、烟蒂、污损纸张、干燥剂、污损塑料、尼龙制品、编制袋、防碎气泡膜、大骨头、硬贝壳、毛发、灰土、炉渣、橡皮泥、太空沙、陶瓷花盆、带胶制品、旧毛巾、一次性餐具、镜子、陶瓷制品、竹制品、成分复杂的制品等。
20.10)大件垃圾:沙发、床垫、床和桌子等。
21.11)电子废弃物:电冰箱、洗衣机、空调、电视机、手机、微电脑、电饭煲等。样本数据量不足可能会导致训练-验证过程遇到的问题:
22.1)模型可能对某些种类垃圾识别效果好,对某些种类垃圾识别效果差;
23.2)模型对预测图片明暗色彩过度依赖,导致不同场景的图片有些识别效果,有些识别效果差;
24.3)模型出现对某些复杂背景的垃圾图片识别效果差,增加模型训练次数不能很好地提升识别率;
25.4)模型出现对某些复杂背景垃圾图片的背景误识别为垃圾实例,增加模型训练次数不能很好地减低背景误识别率;
26.5)模型出现对垃圾图片中的局部堆叠垃圾不能有效地识别,往往出现局部堆叠垃圾的漏识别现象,且增加模型训练次数不能很好地提升局部堆叠垃圾的识别率;
27.6)模型训练时出现训练次数与训练效果不成正比例的现象,训练次数少的可能比训练次数多的效果更好,只采用训练次数评判模型的好坏不合适;
28.7)模型训练速度比较缓慢,训练-验证过程耗时较长。
29.深度学习作为一种数据驱动技术,在样本充足的情况下能够取得很好的训练效果。而实际研究中,更多的是小样本数据,若直接将小样本数据代入深度学习训练,将会出现过拟合问题。为了改善小样本数据在深度学习中的训练效果,需要对小样本数据进行处理,使其能够在深度学习中取得好的训练结果。
30.数据扩增的目的是使得训练数据尽可能的接近测试数据,从而提高预测精度。另外数据扩增可以迫使网络学习到更鲁棒性的特征,从而使模型拥有更强的泛化能力,比如对图像进行一定程度的遮挡。通常进行数据扩增操作的时候应该保持图像原本的标签不变,数据扩增应该在不改变标签的前提下进行。从大量无标签数据集中学习可重复使用的特征表示已经是一个热门研究区域。在林地内生活垃圾目标识别中,由于样本数量较小,导致识别的效果比较差,这时就需要进行数据扩增。
31.数据扩增是对数据进行扩充的方法的总称。数据扩增可以增加训练集的样本,可以有效缓解模型过拟合的情况,也可以给模型带来更强的泛化能力。数据扩增是针对有限训练数据问题的一个重要的空间解决办法,旨在扩增训练数据的规模,缓解深度神经网络模型的过拟合问题,提高模型的性能和泛化能力。
32.数据扩增的思想,是通过对样本图像进行不同的变换,从而得到更多的样本,以此
来提高样本的多样性。数据扩增方法很多,如主成分分析(pca)抖动、随机裁剪、翻转等。利用旋转、颜色抖动、模糊处理和缩放等基本图像处理方式进行数据扩增,实现过程没有新的特征信息生成,扩增后的数据信息多样性差,对林业场景智能算法识别率提升较低。数据扩增发展至今衍生出许多方法,但由于始终都是在原始图像上进行变换,对于分类性能的提升依然十分有限,即使后来出现了自动化搜索数据扩增策略,也只是简化了策略选择流程,本质上并未对数据集的分类性能带来很大的提升。这些方法虽然能实现数据增强,但是其效果有限,因为这些方法局限于在原图的基础上进行变换,具有重复性,且数据分布单一。
33.目前,数据扩增主要分为数据扩增数据集和基于对抗生成网络(gan)的图像生成算法扩增数据集。生成对抗网络(gan)是一种全新的深度学习框架,它可以从图像中学习鉴别特征并生成真实样本,gan生成的图像主要取决于模型结构和样本集质量。dcgan是继gan之后比较好的改进,提升了gan训练的稳定性以及生成结果质量。dcgan为gan的训练提供了一个很好的网络拓扑结构,表明生成的特征具有向量的计算特性。深度卷积对抗网络(dcgan)是生成对抗网络的一种模型改进,将卷积运算的思想引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。
34.生成对抗网络需要理解的重要概念是“生成模型”,如图1所示,生成对抗网络模型。生成对抗网络的生成器能够根据输入的数据产生可能的样本输出,样本输出的内容依据训练过程产生。生成对抗网络是一种新的非监督学习结构,其中包含两部分是以一种对抗的方式来优化自身的。一部分网络模型是分类器,他是用来分辨其输入的数据为真实数据还是生成的虚假数据;第二部分网络模型是生成器,它的目的是生成类似于真实数据的随机样本,将其作为虚假数据。
35.生成对抗网络说明:判别器discriminator,简称d,作为数据的判别器,对于输入的数据判别其真伪。生成器generator,简称g,目的是生成十分接近真实数据样本的虚假数据。训练过程中,判别器d的输入为真实数据和生成器g生成的虚假数据,d的任务就是判断出输入的数据是属于真实的还是假假的。根据判别器d的判断结果,同时对生成器和判别器的参数进行调优。如果判别器的判断正确,就需要优化生成器的参数,使其生成的更加逼真得虚假数据;相反如果判别器的判断错误,就需要优化判别器d的参数,使其做出更加精准的判断。训练过程,两者需要均衡的持续对抗优化,直至生成器生成的数据十分接近真实数据。有效训练后的生成器可以生成高质量的数据,用于机器创作,而判别器则可用于准确的机器分类。
36.根据一个或者多个实施例,如图2所示。一种基于gcgan算法的林地内生活垃圾样本数据扩增方法,利用无人机采集的林地场景下的少量生活垃圾样本,利用dcgan网络模型生成判别识别不出真假的图像数据将其作为生活垃圾样本集的一部分。dcgan模型的结构包括:
37.1.判别器模型使用卷积步长取代了空间池化,生成器模型中使用反卷积操作扩大数据维度。
38.2.除了生成器模型的输出层和判别器模型的输入层,在整个对抗网络的其它层上都使用了batch normalization,原因是batch normalization可以稳定学习,有助于优化初始化参数值不良而导致的训练问题。
39.3.整个网络去除了全连接层,直接使用卷积层连接生成器和判别器的输入层以及
输出层。
40.4.在生成器的输出层使用tach激活函数以控制输出范围,而在其它层中均使用relu激活函数;在判别器上使用leaky relu激活函数。
41.本发明技术方案带来的有益效果包括:
42.gcgan算法是一种无监督学习模型,相较于gan模型,它结合深度神经网络概念,对对网络结构进行优化,达到提高样本生成质量和收敛速度的目的。gcgan算法的主要优点是通过一些经验性的网络设计使得对抗训练更加稳定。
43.通过优化方法对深度学习进行数据集、模型和训练过程的优化,最终垃圾识别的准确度在复杂场景下有较大提升。虽然还存在少数误识别和漏检的现象,但是由于深度学习使用的硬件成本较低,识别准确率较高,符合现有实际场景垃圾识别的需求。
44.可以降低无人机采集林地场景下中生活垃圾的成本,同时通过深度卷积生成对抗网络生成的大量生活垃圾样本,可以使得场景识别模型有了大量训练样本,从而提高林地场景智能识别率得到相应地提高。
45.相比其他生成对抗网络算法,dcgan在稳定性和生成样本质量方面有一定的优势,但是梯度消失、多样性不高等问题依然存在。针对这些问题可以加入一些改进方法:损失函数替换、加入谱归一化和最佳噪声输入估算。未来将会继续优化网络结构使其能够更加高效的运行,进一步适配不平衡数据集,并优化数据选择算法使其能进行自适应参数选择。
46.根据一个或者多个实施例,一种基于gcgan算法的林地内生活垃圾样本数据扩增方法,包括:
47.(1)通过标注软件对垃圾图片进行标注,并保证较高的标注准确度。
48.(2)模型训练:垃圾图片采用深度学习模型进行训练,我们先对垃圾数据集进行划分,将90%的图片作为训练集进行模型训练,另外10%的图片作为验证集进行模型验证。在配置模型网络、选型激活函数、损失函数和优化函数后进行模型训练,从而实现垃圾目标物的识别。
49.值得说明的是,虽然前述内容已经参考若干具体实施方式描述了本发明创造的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1