面向开源社区的跨项目issue参与者推荐框架
1.本发明属于计算机软件工程应用领域,具体涉及一种面向开源社区的跨项目issue参与者推荐框架。
背景技术:
2.开源软件的蓬勃发展使开源社区(例如github)中维护了越来越多的软件仓库,每个人都可以在公共软件仓库中提交issue,issue可以帮助开发人员发现软件漏洞,但由于数目太多致使维护人员往往无法及时检查这些issue。此外,人工查看issue并选择合适的参与者困难且乏味,而且在更大的软件仓库中这种情况会更加糟糕。
3.类似的问题也在bug跟踪系统(另一种开源社区,通常维护单一仓库,例如mozilla)中出现,在bug跟踪系统中,bug分流技术将此问题视为从bug报告文本到开发者或修复者的分类问题。关于bug分类的现有工作只关注于从维护仓库的开发人员中推荐,但是在github中,这个问题变得复杂,因为每个人都可以参与问题的讨论,或者提交关于这个问题的额外信息,有些人可能是专家,但并不维护此仓库。
4.最经典的bug分流技术已经研究了将其作为简单的文本分类问题的可能,并取得了一定的成果。但是在不限制开发者的范围下,若仍采用文本分类方法将会面临维数灾难而难以取得良好的效果。在bug分流技术方面,有研究在考虑issue到开发者的投递序列,在建立语言主题模型等方案上分别取得了各自的成功。
5.在开源社区中的推荐问题上,已有pull-request审阅者推荐问题从开源社区的结构上进行研究,审阅者推荐问题的研究结果表明从开源社区中各个实体的历史交互结构上预测未来关系的可能。另外,在图的边预测问题中也揭示了历史关系组成的结构的有效性。
6.在开源社区中,大量开源仓库中存在着交互关系,主要表现在issue之间的相互引用关系上,有研究表明跨项目的issue相比于一般issue更加难以修复,需要消耗更多的人力和时间,也有研究表明不同仓库会出现相似bug,因此某个仓库现有的issue或bug可以为其它仓库提供解决思路。这些研究都为开源社区中跨项目issue的参与者推荐问题提供了新的解决思路。
技术实现要素:
7.为了克服传统bug分流技术在开源社区中的不足,提高对跨项目issue的推荐能力,本发明结合开源社区场景特性,提出一种面向开源社区的跨项目issue参与者推荐框架,利用issue的引用关系拓展项目外的开发者参与进来,利用开源社区的结构关系增强推荐的准确性和可解释性。为实现上述目的,本发明采用以下技术方案:
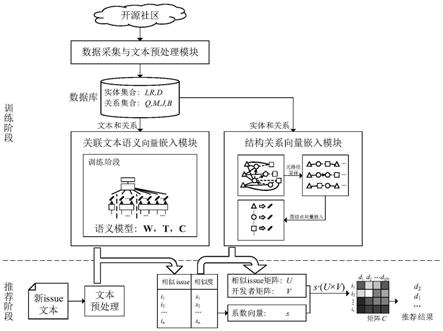
8.面向开源社区的跨项目issue参与者推荐框架,包括数据采集与文本预处理模块、关联文本语义嵌入模块、开源社区实体结构嵌入模块和推荐结果排序模块,
9.所述数据采集与文本预处理模块:用于从开源社区中获取信息并以一定格式加以处理,包括,去除质量差的issue和issue中的干扰部分,对issue文本进行词干提取、词形还
原并去除停止词以得到issue文本集,提取每个issue对其他issue的引用关系以构建issue关系集;
10.所述关联文本语义嵌入模块:定义训练目标函数并利用issue文本集和issue关系集训练语义嵌入模型,通过语义嵌入模型获取待推荐issue的文本语义嵌入向量,并通过其与issue文本集中issue文本语义嵌入向量的距离找出与待推荐issue语义相似的issue集合;
11.所述开源社区实体结构嵌入模块:构建整个开源社区中开发者、仓库、issue三种结点间交互关系的异质图,为跨项目的推荐任务设计issue引用关系增强的元路径,以元路径对异质图进行采样并采用图嵌入方法训练得到每个结点的结构嵌入向量以构建结构关系向量集合;
12.所述推荐结果排序模块:从结构关系向量集合中找出issue集合和待推荐issue所属仓库的结构关系向量,并计算其与开发者结点的向量距离以得到有序的开发者推荐结果。
13.进一步地,所述数据采集与文本预处理模块的具体处理过程包括:
14.s1.1、从开源社区中获取需要的开源仓库集合r,对r中的每个仓库r,获取其issue集合ir,每个issue包含标题、描述和评论的所有文本,所有仓库的issue构成集合i=∪
r∈r
ir;
15.s1.2、从集合i中去除标题单词数目少于m或描述字符数目少于n的issue,并去除issue中引用他人部分的文本和代码,利用传统文本预处理方法进行词干提取、词形还原、去除停止词得到issue预处理后的文本集;
16.s1.3、抽取出所有issue的参与者构成参与者集合d,再根据所有开发者参与issue的关系构成参与关系集合j;
17.s1.4、根据开源社区仓库信息抽取维护关系《d,r》构成维护关系集合m,《d,r》表示开发者d维护仓库r,d∈d,r∈r;
18.s1.5、提取issu之间的所有引用关系构成引用关系集合q,其中《im,in》∈q(im∈i,in∈i,im≠in)表示issue im中包含对issue in的引用链接;
19.s1.6、构建issue属于仓库的隶属关系集合b,其中《im,rn》∈b(im∈i,rn∈r)表示issue im属于仓库rn。
20.进一步地,所述关联文本语义嵌入模块的具体处理过程为:
21.s2.1、定义训练目标函数为
[0022][0023]
其中,表示窗口j内扫描到的单词wj的嵌入向量,下标x表示窗口中心;表示函数在分布pn(w
x
)下的数学期望,pn(w
x
)表示单词w
x
的噪声分布;σ(
·
)为sigmoid函数;vh表示训练过程融合的issue语义嵌入向量,且
[0024]
vh=h(ti;c
i~j
,
…
,c
m~i
;w
x-k
,
…
,w
x-1
,w
x+1
,
…
,w
x+k
)
[0025]ci~j
表示issue i和j的关系嵌入向量,k表示扫描单词的窗口大小,ti为issue i的文本语义向量,融合函数h(
·
)选定为向量平均函数;
[0026]
s2.2、将单词嵌入向量按列组成模型参数矩阵w,将文本语义向量按列组成模型参数矩阵t,关系嵌入向量按列组成模型参数矩阵c;
[0027]
s2.3、利用引用关系集合q和预处理后的文本集i训练语义嵌入模型,得到模型参数w、t、c以及文本集i中所有issue的文本语义嵌入向量;
[0028]
s2.4、利用训练完成的语义嵌入模型获取待推荐issue的文本语义嵌入向量,并通过其与issue文本集中issue文本语义嵌入向量的相似度找出与待推荐issue最相似的n个issue及其相似度,表示为[《i1,s1》,《i2,s2》,
…
,《in,sn》],且满足s1≥s2≥
…
≥sn,in与sn表示第n个相似issue及其相似度;相似度采用文本语义嵌入向量的距离的倒数来度量。
[0029]
进一步地,所述开源社区实体结构嵌入模块的具体处理过程包括:
[0030]
s3.1、将开源仓库集合r、预处理后的文本集i和参与者集合d、作为三种结点,将参与关系集合j,维护关系集合m,隶属关系集合b和引用关系集合q作为四种边构建开源社区的异质图;
[0031]
s3.2、构建issue引用关系增强的元路径,在随机游走的过程中加强对issue引用边的游走概率,并结合整个开源社区的结构特征,合理增加issue结点与开发者和仓库两种结点在元路径的关联关系;
[0032]
s3.3、使用元路径对异质图进行采样,采用metapath2vec方法对采样的结点序列进行训练,对于结点n得到其开源社区结构关系嵌入向量gn。
[0033]
进一步地,所述推荐结果排序模块的具体处理流程为:
[0034]
s4.1、从s3.3中取出s2.4中所有相似issue的结构关系嵌入向量并按行构成矩阵矩阵u的首行为待推荐issue所属仓库的结构关系嵌入向量,其余n行为相似issue的结构关系嵌入向量,d为结构关系嵌入向量的维度;
[0035]
s4.2、从s3.3中取出所有开发者结点的结构关系嵌入向量按列构建矩阵|d|为开发者数目;
[0036]
s4.3、定义向量s=[αs1,s1,s2,
…
,sn]
t
为系数向量,α为仓库的重要性权重,用于控制矩阵u中仓库行的表现效果;
[0037]
s4.4、计算c=s
·
(u
×
v),则矩阵c中m行n列的元素(c)
mn
(m≠0)为issue m与开发者n的距离,元素(c)
mn
(m=0)为待推荐issue所属仓库与开发者n的距离;将开发者按照(c)
mn
从大到小排序并去除重复排序的开发者,取得前若干个开发者作为推荐结果。
[0038]
本发明结合开源社区场景特性,提出一种面向开源社区的跨项目issue参与者推荐框架,利用issue的引用关系拓展项目外的开发者参与进来,利用开源社区的结构关系增强推荐的准确性和可解释性,克服了传统bug分流技术在开源社区中的不足,提高了对跨项目issue的推荐能力。
附图说明
[0039]
图1为本发明的推荐框架结构;
[0040]
图2为本发明中的语义嵌入模型;
[0041]
图3为本发明中的开源社区结构异质图;
[0042]
图4本发明中构建的元路径示意图。
具体实施方式
[0043]
现在结合附图对本发明作进一步详细的说明。
[0044]
如图1所示,本发明提出的一种面向开源社区的跨项目issue参与者推荐框架,主要包括数据采集与文本预处理模块、关联文本语义嵌入模块、开源社区实体结构嵌入模块和推荐结果排序模块,图1展示了整个推荐框架的结构图,其中各模块的具体处理流程分别如下:
[0045]
(1)数据采集与文本预处理模块
[0046]
1.1)通过github api获取需要的开源仓库集合r,对r中的每个仓库r,同样通过api获取其所有issue构成集合ir,每个issue包含标题,描述和评论的所有文本,所有仓库的issue构成集合i=∪
r∈r
ir;
[0047]
1.2)去除集合i中所有标题和描述单词数目少于10和字符数目少于50的issue;去除文本中引用他人部分的文本和大段代码,即在github开源社区中去除html中《blockquote》块和《pre》块的内容;再利用传统文本预处理方法进行词干提取(例如:playing转换为play),词形还原(例如:is转换为be),去除停止词(例如:the,of)得到预处理后的文本;
[0048]
1.3)抽取出所有issue的参与者构成集合d,再根据所有开发者参与issue的关系《d,i》(例如有d1,d2两名开发者参与issue i的讨论,则有关系《d1,i》和《d2,i》)构成参与关系集合j;
[0049]
1.4)在本示例中,根据github开源社区中分配者(assignee)确定开发者对仓库的维护关系《d,r》,所有的维护关系构成维护关系集合m;
[0050]
1.5)提取issue与issue之间的所有引用关系构成引用关系集合q,《im,in》∈q(im∈i,im∈i,im≠in)表示issue im的讨论中包含对issue in的引用链接;
[0051]
1.6)构建issue属于仓库的关系集合b,其中《im,rn》∈q(im∈i,rn∈r)表示issue im属于仓库rn,每个issue有且仅有一个自己归属的仓库,一个仓库可以包含多个issue。
[0052]
需要说明的是,本发明到此提供了一种组织仓库,issue,开发者的方法,并且对issue之间的关系做了统一的收集,整个数据集组成了解决跨项目参与者推荐问题的数据基础。
[0053]
(2)关联文本语义嵌入模块
[0054]
在本发明的关联文本语义嵌入模块中,需要对issue中的文本进行合理的建模,为github中issue之间的链接提供了新的思考方向。由于链接是由开发者发起的,可以直观地得到,开发者通过链接建立了两个issue之间的关系。所以本发明的该模块将通过issue之间的链接优化issue的文本语义向量嵌入。
[0055]
2.1)结合issue之间的引用关系特点并基于doc2vec中的pv-dm方法明确优化目标为最小化以下函数,此函数综合了issue i的文本嵌入表示ti,其具有的引用关系c
i~j
,
…
,c
m~i
和窗口内扫描到的单词内容w
x-k
,
…
,w
x-1
,w
x+1
,
…
,w
x+k
,下标x表示窗口中心,k表示扫描单词的窗口大小。
[0056]
[0057]
此函数目的在于利用issue i的单词序列建立issue的整体文本语义表示ti,引用关系嵌入表示c
i~j
,
…
,c
m~i
,和单词嵌入表示uw,且规定三种嵌入向量的维度相同。
[0058]
2.2)确定上式的条件概率函数p(
·
|
·
;
…
;
…
)在实际任务中的定义,一般定义为一个softmax函数,如下面的公式所示:
[0059][0060]
与此同时,由于上式条件概率函数中的分母计算需要遍历所有训练集的内容并且在每次更新时候需要重新计算,故此处采用sigmoid函数σ(
·
)进行近似计算优化速度。另外,加上负采样以加快训练速度,所以最终的优化目标为最小化如下函数:
[0061][0062]
在以上的公式中,表示窗口j内扫描到的单词wj的嵌入向量,c
i~j
表示issue i和j的关系嵌入向量。表示函数f(
·
)在分布pn(w
x
)下的数学期望,在该式中该部分作为优化目标的负采样以加快训练速度,上式中f(
·
)显然等于pn(w
x
)表示整个关联文本数据集中单词w
x
的噪声分布。vh表示训练过程融合的issue语义嵌入向量,计算vh的融合函数选定为向量平均函数。
[0063]
vh=avg(ti,c
i~j
,
…
,c
m~i
,w
t-k
,
…
,w
t-1
,w
t+1
,
…
,w
t+k
)
[0064]
此融合函数用于获得issue i在窗口中心下标为x下的语境嵌入向量,结合了issue的文本向量嵌入,issue与其引用关系的向量嵌入和窗口中的单词的向量嵌入。
[0065]
2.3)综合上述公式,将单词嵌入向量按列组成模型参数矩阵w,将文本语义向量按列组成模型参数矩阵t,关系嵌入向量按列组成模型参数矩阵c。
[0066]
2.4)训练阶段使用(1)中得到的issue引用关系集q和预处理后的文本集i按照类似于pv-dm的方法(如附图2所示)训练得到语义嵌入模型和训练集中所有issue的语义嵌入向量,训练完成之后得到模型参数w,t,c。
[0067]
2.5)利用训练完成的语义嵌入模型获取待推荐issue的文本语义嵌入向量,并通过其与issue文本集中issue文本语义嵌入向量的相似度找出与待推荐issue最相似的n个issue及其相似度,表示为[《i1,s1》,《i2,s2》,
…
,《in,sn》],且满足s1≥s2≥
…
≥sn,in与sn表示第n个相似issue及其相似度;相似度采用文本语义嵌入向量的距离的倒数来度量。
[0068]
通过关联文本语义嵌入模块,我们能获得所有issue的文本语义嵌入向量,并且,训练得到的模型将会在推荐阶段用于建模待推荐的issue文本。需要注意的是,待推荐的issue一般不包含引用关系。
[0069]
(3)开源社区实体结构嵌入模块
[0070]
3.1)将(1)中的仓库集合r、预处理后的文本集i和参与者集合d作为三种结点,将参与关系集合j、维护关系集合m、隶属关系集合b和引用关系集合q作为四种边构建开源社区的异质图,附图3展示了异质图的示例。
[0071]
3.2)构建issue引用issue关系增强的元路径如附图4所示,包含对三种不同issue
的不同策略。
[0072]
3.2.1)对包含外部引用的issue(附图4中称为外部引用issue),使其以概率p(本示例令p等于0.6)游走到相关的issue结点;
[0073]
3.2.2)对不包含外部引用但包含内部引用的issue(附图4中称为内部引用issue),使其以概率q(本示例令q等于0.6)游走到相关的issue结点;
[0074]
3.2.3)对不包含引用的issue,使其直接游走到仓库结点。
[0075]
3.3)使用元路径对异质图进行采样,采用metapath2vec方法对采样的结点序列进行训练,对于结点n得到其开源社区结构关系嵌入向量gn。
[0076]
(4)推荐结果排序模块
[0077]
4.1)从3.3)中取出2.5)中所有相似issue的结构关系嵌入向量并按行构成矩阵矩阵u的首行为待推荐issue所属仓库的结构关系嵌入向量,其余n行为相似issue的结构关系嵌入向量,d为结构关系嵌入向量的维度;
[0078]
4.2)从3.3)中取出所有开发者结点的结构关系嵌入向量按列构建矩阵|d|为开发者数目;
[0079]
4.3)定义向量s=[αs1,s1,s2,
…
,sn]
t
为系数向量,α为仓库的重要性权重,用于控制矩阵u中仓库行的表现效果;
[0080]
4.4)计算c=s
·
(u
×
v),则矩阵c中m行n列的元素(c)
mn
(m≠0)为issue m与开发者n的距离,元素(c)
mn
(m=0)为待推荐issue所属仓库与开发者n的距离;将开发者按照(c)
mn
从大到小排序并去除重复排序的开发者,取得前若干个开发者作为推荐结果。
[0081]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1