基于肤色联合Adaboost算法的人脸检测方法
基于肤色联合adaboost算法的人脸检测方法
技术领域
1.本发明属于图像处理领域,具体为一种基于肤色联合adaboost算法的人脸检测方法。
背景技术:
2.人脸检测计算机视觉技术下的一种应用。它旨在查找和识别数字图像中的人脸。而且,这是在图像中定位面部以执行面部识别的预备步骤的过程。人脸检测基本分为两个步骤:第一步就是找出一幅图像中是否含有人脸,第二步就是确定人脸在这幅图像中所在的位置。人脸检测可用于执法,生物识别和娱乐等各个领域。由于人脸检测技术的非接触式认证,直接,友好,方便的特点使得人脸检测技术的研究得到了广泛的研究和发展,已成为研究的热点。
3.目前,有四种方法用于人脸检测:基于统计的方法,特征不变方法,模板匹配方法和基于外观的方法。其中基于统计的检测方法用得比较多。基于统计的人脸检测方法主要有:adaboost、神经网络方法、支持向量机方法、隐马尔可夫模型等。其中最成熟的方法是adaboost方法。它是第一个实时的人脸检测算法。在这种情况下,2001年,paul viola和michaeljones提出基于haar
‑ꢀ
like特征的adaboost人脸检测算法。现在viola
–
jones算法已被广泛用于面部检测。viola
–
jones算法使用adaboost训练作为机器学习来解决分类问题。它使用haar级联分类器检测关键的面部特征,使用积分图像有效地计算矩形内像素的总和,并采用级联方法来检测人脸。
4.虽然adaboost算法在人脸检测上有许多优点,但是在检测过程中还是存在着准确率和检测效率不高的情况。
技术实现要素:
5.本发明的目的在于提出了一种基于肤色联合adaboost算法的人脸检测方法。
6.实现本发明目的的技术方案为:一种基于肤色联合adaboost算法的人脸检测方法,包括以下步骤:
7.步骤1:对人脸图像进行预处理;
8.步骤2:建立新的颜色空间ycbc
gcr
;
9.步骤3:确定阈值模型以分割肤色和非肤色区域,得到初步的人脸检测候选图像;
10.步骤4:利用adaboost算法训练弱分类器,将不同训练集中的弱分类器组合成强分类器,强分类器串联成级联分类器;利用训练好的级联分类器对步骤 3选出的候选图像进行第二次检测,得到最终的检测结果。
11.优选地,对人脸图像进行预处理的具体过程为:
12.将图像中所有像素的亮度从高到低进行排序,取前10%的像素l作为参考白,则参考白像素的亮度平均值avegray为:
13.avegray=gray
ref
/gray
refnum
14.式中gray
ref
为参考白灰度值;gray
refnum
用为参考白像素数;
15.计算光照补偿系数coe:
16.coe=255/avegray
17.将原像素值分别乘以光照补偿系数coe,得到光照补偿后的图像;
18.对光照补偿后的图像进行伽马矫正补偿,具体如下:
19.对光照补偿后的图像进行归一化操作,具体采用rgb范数的方法对伽马矫正进行归一化,具体为:
20.建立图像i(i,j),r、g、b分量与i(i,j)的关系:
21.i(i,j)=r(i,j)+g(i,j)+b(i,j)
22.其中,r(i,j),g(i,j),b(i,j)为红、绿、蓝分量在第(i,j)像素的值;
23.采用范数概念:
[0024][0025][0026][0027]
根据公式ie=(in)
γ
,γ为常数,分别带入得到:
[0028][0029][0030][0031]
通过反归一化,得到改进后的图像,四舍五入取整得到最终伽马增强图像 i
′
。
[0032]
优选地,步骤2中新的肤色空间具体为:
[0033][0034]
r、g、b分别为红绿蓝分量。
[0035]
优选地,步骤3中所述肤色模型具体为:
[0036]
80<cb<135;
[0037]
133<cr<173;
[0038]
133<cg<173。
[0039]
优选地,步骤4利用adaboost算法训练弱分类器,将不同训练集中的弱分类器组合成强分类器,强分类器再串联成级联分类器的具体方法为:
[0040]
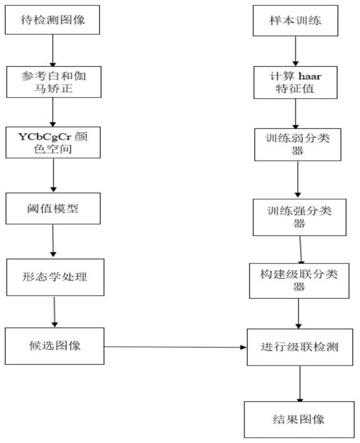
步骤4.1:准备人脸及非人脸图片,分别标记为正、负样本,并且根据人脸不同部位特征提取出不同的haar特征;
[0041]
步骤4.2:采用积分图的方法计算haar特征值;
[0042]
步骤4.3:使用adaboost迭代算法训练弱分类器,弱分类器具体为:
[0043][0044]
x是要检测的窗口,f是haar特征值,θ是haar特征的阈值,p用于控制不等式方向;
[0045]
将haar特征值排序,对排好序的每个特征计算全部正样本权重和t
+
、全部负样本的权重和t-、该特征前正样本的权重和s
+
和该特征前负样本的权重和 s-,选取当前特征的特征值fk和它前面的一个特征值f
k-1
之间的数作为阈值,该阈值的分类误差为:
[0046]
e=min(s
+
+(t-‑
s-),s-+(t
+-s
+
))
[0047]
将分类误差最小的haar特征及其阈值记录下来,作为一个最优弱分类器;
[0048]
步骤4.4:按照规则将弱分类器组成强分类器;
[0049]
步骤4.5:将强分类器组成级联分类器。
[0050]
优选地,构成的强分类器具体为:
[0051][0052][0053]
式中,ε
t
=∑iqi|h(xi,f,p,θ)-yi|,
[0054]
其中,ε
t
代表代表第t个弱分类器的误差,qi代表第i个训练样本在第i次迭代的权值,h(xi,f,p,θ)代表第i个弱分类器对第i个样本的判别值。yi=1,表示人脸, yi=0表示非人脸。
[0055]
优选地,将强分类器组成级联分类器的具体方法为:
[0056]
将级联的分类器的最大误检率设为f
max
,每个强分类器的最小的检测率设置为d
min
,最大的误检率设置为f
max
,计算级联的分类器的最大的层数为:
[0057]
m=log(f
max
)/log(f
max
)
[0058]
在样本库中,挑选正样本numpos个和负样本numneg个;
[0059]
计算出所有正负样本的全部矩阵特征值,并且用矩阵的形式来存储;
[0060]
对{t/t=1,2,...,m},训练第t个强分类器,设定误检率f
t
≤f
max
,设定检测率d
t
≤d
min
,将前t个强分类器构造成级联的分类器。
[0061]
本发明与现有技术相比,其显著优点为:
[0062]
(1)本发明使用扩展的参考白算法与rgb范数对伽马矫正进行改进,消除了光照对肤色的影响。
[0063]
(2)本发明创建一个新的颜色空间ycbc
gcr
,使其更加符合人脸检测的标准。
[0064]
(3)本发明对haar特征进行扩展,寻找更加符合人脸标准的特征,从而提高了adaboost检测准确率。
[0065]
下面结合附图对本发明做进一步详细的描述。
附图说明
[0066]
图1为本发明的流程图。
[0067]
图2为积分图。
[0068]
图3为原始的haar特征。
[0069]
图4是扩展的haar特征。
[0070]
图5是检测效果图片。
具体实施方式
[0071]
一种基于肤色联合adaboost算法的人脸检测方法,包括以下步骤:
[0072]
步骤1:对人脸图像进行预处理,主要利用参考白算法和伽马矫正,在进行肤色提取之前,进行光照的补偿。具体为:
[0073]
将图像中所有像素的亮度从高到低进行排序,取前10%的像素l作为参考白,则参考白像素的亮度平均值avegray为:
[0074]
avegray=gray
ref
/gray
refnum
[0075]
式中gray
ref
为参考白灰度值;gray
refnum
用为参考白像素数;
[0076]
计算光照补偿系数coe:
[0077]
coe=255/avegray
[0078]
原像素值分别乘以光照补偿系数coe,得到光照补偿后的图像;
[0079]
对光照补偿后的图像进行归一化操作,具体采用rgb范数的方法对伽马矫正进行归一化,具体为:
[0080]
建立图像i(i,j),r、g、b分量与i(i,j)的关系:
[0081]
i(i,j)=r(i,j)+g(i,j)+b(i,j)
[0082]
其中r(i,j),g(i,j),b(i,j)为红,绿,蓝分量在第(i,j)像素的值。
[0083]
为提高补偿效果采用范数概念:
[0084][0085][0086][0087]
然后根据公式ie=(in)
γ
(γ值一般选取为2.2.效果最好),分别带入得到:
[0088][0089][0090][0091]
这一步是对归一化的预补偿。
[0092]
通过反归一化,得到改进后的图像,四舍五入取整得到最终伽马增强图像 i
′
。
[0093]
步骤2:建立合适的肤色空间,人脸肤色和环境存在较大的颜色差异,通过肤色很容易将人脸和背景区分开。基于肤色来进行人脸检测是最常用的方法,该方法需要选取合适的颜色空间和建立肤色模型。因此创造一个新的颜色空间ycbcgcr,下面的等式中定义了rgb到y和ycbc
gcr
的转换。如下:
[0094]
[0095][0096]
所以新的颜色空间的转换如下:
[0097][0098]
步骤3:确定阈值模型以分割肤色和非肤色区域,得到初步的人脸检测候选图像;
[0099]
所谓肤色模型就是一种数值的方法,可以根据其建立一种规则,通过这种规则可以用来区分肤色和非肤色。
[0100]
本发明仅使用可以完全代表颜色的色度通道。在cb和cg,cr通道中成功定义了肤色。cb和cg,cr范围如下公式所示:
[0101]
80<cb<135;
[0102]
133<cr<173;
[0103]
133《cg<173。
[0104]
根据上述颜色范围,本发明拟采用阈值法建立肤色模型,阈值肤色模型实现简单且运算较快,根据上述cb和cg,cr的范围,当像素值落在范围之内,就可以断定是肤色区域,当在范围之外就是非肤色区域。对图像完成分割。
[0105]
通过阈值模型得到初步的人脸检测图像,但是由于背景复杂等原因,会出现误检,没有检测到等情况的发生,所以需要进行第二次人脸检测。
[0106]
步骤4:利用adaboost算法训练弱分类器,将不同训练集中的弱分类器组合成强分类器,强分类器再串联成级联分类器。通过计算人脸haar积分图特征,再通过多层的级联分类器来进行人脸检测的,主要包括以下几个过程:
[0107]
步骤4.1:准备人脸及非人脸图片,分别标记为正、负样本,并且通过人脸特征提出不同的haar特征。
[0108]
例如,脸上含有眉毛和睫毛的区域比脸颊暗。鼻子桥区域比眼睛明亮。没有使用单个的rgb像素来找到这些相似的特征,而是使用了根据眼睛,嘴巴和鼻子的位置和大小的属性组成来基于haar小波获得数字图像特征。
[0109]
步骤4.2:采用积分图的方法计算haar特征值。
[0110]
步骤4.3:使用adaboost迭代算法训练弱分类器的具体方法为:
[0111][0112]
x是要检测的窗口,f是haar特征值,θ是haar特征的阈值,p用于控制不等式方向。
[0113]
将haar特征值排序,对排好序的每个特征计算全部正样本权重和t
+
、全部负样本的权重和t-、该特征前正样本的权重和s
+
和该特征前负样本的权重和 s-,选取当前特征的特征值fk和它前面的一个特征值f
k-1
之间的数作为阈值,该阈值的分类误差为:
[0114]
e=min(s
+
+(t-‑
s-),s-+(t
+-s
+
))
[0115]
将分类误差最小的haar特征及其阈值记录下来,作为一个最优弱分类器。
[0116]
步骤4.4:按照规则将弱分类器组成强分类器,具体方法为:
[0117]
建立训练样本(xi,y1),(x2,y2)
…
(xn,yn).y∈{0,1},y=0不是人脸样本,y=1 是人脸样本。
[0118]
对负样本来说:m是负样本数目。
[0119]
对正样本来说:i是正样本数目。
[0120]
初始化权重:
[0121]
对于每个函数f,训练一个弱分类器h,计算所有样本对应权重的错误率,
[0122]
ε
t
=∑iqi|h(xi,f,prθ)-yi|
[0123]
使用最小错误率分类器h来更新所有样本的权重:
[0124][0125]
β
t
=ε
t
/1-ε
t
[0126]
在t轮迭代之后,把t个弱分类器联合构成一个强分类器:
[0127][0128][0129]
步骤5.5:将强分类器组成级联分类器,具体方法为:
[0130]
将级联的分类器的最大误检率设为f
max
,每个强分类器的最小的检测率设置为d
min
,最大的误检率设置为f
max
,计算级联的分类器的最大的层数为:
[0131]
m=log(f
max
)/log(f
max
)
[0132]
在样本库中,挑选正样本numpos个和负样本numneg个;
[0133]
计算出所有正负样本的全部矩阵特征值,并且用矩阵的形式来存储;
[0134]
对{t/t=1,2,...,m},训练第t个强分类器,设定误检率f
t
≤f
max
,设定检测率d
t
≤d
min
,将前t个强分类器构造成级联的分类器。
[0135]
级联分类器采用简并的决策树结构,该结构将adaboost算法中的多个强分类器串联在一起。强分类器本身具有较高的检测率和适宜的错误率,以确保它可以通过大多数人脸样本,同时排除非非人脸样本。当级联分类器应用于人脸检测,在被判定为人脸时,将在下一个强分类器中检测到它;如果它是非人脸的,则不需要标识。分类器越强,训练的轮数越多检测率就越高。
[0136]
本发明经过肤色第一次检测与adaboost算法第二次检测得到最终的检测结果,该结果有效提高了检测效率,从而提高了检测的准确率。该算法具有很好的鲁棒性,可以准确快速地检测出人脸。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1