一种快速启动的交互式关系标注与抽取框架
1.本发明涉及一种以人机交互为基础,快速启动的交互式关系标注与抽取框架,属于计算机人工智能以及自然语言处理技术领域。
背景技术:
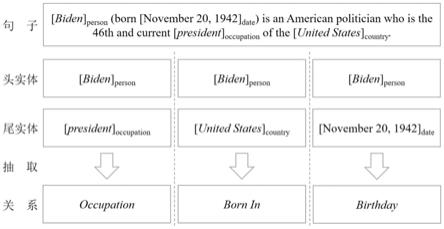
2.关系抽取是信息抽取领域的重要子任务,在知识图谱、对话系统和知识问答系统的构建等多个应用场景中起到关键作用,在医疗、军事、金融等领域也具有广泛的应用价值。关系抽取的主要目标是从文本中抽取出《主、谓、宾》的三元组结构,或《头、关系、尾》。关系抽取的常见形式是输入一段文本和其涉及的两个实体,判断文本内容是否描述了两个实体之间存在的关系,并推断出存在何种关系。
3.在过去的研究中,监督学习关系抽取方法取得了不错的效果。但监督学习方法本身依赖于大量的标注数据,这些标注数据的获得往往需要耗费极大的人力物力,这使得监督学习方法在实际业务落地中的冷启动成本非常高昂,难以普及。此外,监督学习方法的可迁移性也较差,例如用通用领域语料训练出来的监督学习关系抽取模型,很难应用于特定领域。因此,监督学习关系抽取方法在实际应用落地中存在诸多问题。
4.少样本学习技术是一种解决冷启动数据需求问题的有效方法。元学习技术是少样本学习技术中的一类重要技术,利用元学习可对关系抽取任务进行预训练,从而获得关系抽取模型的一套初始化参数。这一套初始化参数能够利用少数训练数据进行快速收敛,从而解决关系抽取任务中的冷启动数据需求问题。
5.主动学习技术被广泛用于降低标注成本,且在计算机视觉领域取得了较好的效果。主动学习技术通过计算机器学习过程中的指标,获取较难分类的数据样本。然后人工对这些样本进行校对和审核,并将校对后数据重新用于机器学习模型的训练,从而提升机器学习模型的性能,并降低标注的数据量。
技术实现要素:
6.本发明正是针对现有技术中存在的问题,提供一种快速启动的交互式关系标注与抽取框架,该技术方案提出了利用人工校对信息降低标注数据并提升模型性能的主动学习技术,结合了少样本关系抽取技术以提升模型的冷启动性能,基于本发明公布的框架,可有效克服现有关系抽取系统冷启动成本高昂和重人力成本投入的缺点,实现具有快速启动和低人工成本特性的关系标注和抽取系统。
7.为了实现上述目的,本发明的技术方案如下,一种快速启动的交互式关系标注与抽取框架,包括以下步骤:
8.s1:使用通用命名实体识别数据集对命名实体识别模型进行预训练;
9.s2:使用通用关系抽取数据集对少样本关系抽取模型进行预训练;
10.s3:设定待抽取关系和少量标注数据;
11.s4:对待抽取文本进行数据预处理;
12.s5:使用命名实体识别模型对待抽取文本进行命名实体识别;
13.s6:对实体进行人工配对;
14.s7:对配对结果进行初步关系抽取;
15.s8:对关系抽取结果进行人工校对;
16.s9:对少样本关系抽取模型进行微调;
17.s10:重复s4到s9直到所有的待抽取文本均处理完成。本框架提出了利用人工校对信息降低标注数据并提升模型性能的主动学习技术,结合了少样本关系抽取技术以提升模型的冷启动性能。利用校对后数据进行模型微调,提升模型抽取的效果。基于本发明公布的框架,可有效克服现有关系抽取系统冷启动成本高昂和重人力成本投入的缺点,实现具有快速启动和低人工成本特性的关系标注和抽取系统。
18.作为本发明的一种改进,步骤s1:使用通用命名实体识别数据集对命名实体识别模型进行预训练,构建快速启动交互式关系标注与抽取框架,其中框架包含:命名实体识别模型、少样本关系抽取模型、待处理文本仓库、通用命名实体识别数据集、通用关系抽取数据集和专用关系抽取数据仓库,此外,所述框架还包含人工校对交互方法、元学习训练方法、参数更新方法和主动学习。
19.作为本发明的一种改进,步骤s2使用通用关系抽取数据集对少样本关系抽取模型进行预训练,具体如下,构建框架中的命名实体识别模型net
ner
,采用通用领域命名实体类识别数据集进行预训练;构建所述框架中的少样本关系抽取模型net
re
,先使用通用领域关系抽取数据集以元学习方式训练,得到初始化参数θ0,再使用专用关系抽取数仓库对net
re
的参数θ0进行微调,得到参数θ1。
20.作为本发明的一种改进,步骤s3:设定待抽取关系和少量标注数据;从待处理文本仓库中,选取一条待抽取文本s。
21.作为本发明的一种改进,步骤s4:对待抽取文本进行数据预处理;使用预训练的命名实体类识别模型对待抽取文本进行命名实体识别,为方便标注者处理,在待处理文本中将命名实体识别的结果{e1,e2,...en}进行标记。
22.作为本发明的一种改进,步骤s5:使用命名实体识别模型对待抽取文本进行命名实体识别,具体如下,标注者手动将s4中识别出的命名实体进行配对,即选出需要进行关系抽取的头尾实体对{eh,e
t
}。将被标注者选中的实体对{eh,e
t
},以及包含实体对的句子s、实体类型{ch,c
t
}和实体在句子中的相对位置{posh,pos
t
}作为下一步进行关系抽取的输入。
23.作为本发明的一种改进,步骤s6:对实体进行人工配对,标注者手动将命名实体进行配对:在文本中依次点击两个实体,先点击的实体为头实体eh,对应类型为ch,后点击的实体为e
t
,对应类型为c
t
;实体根据点击的实体和其所在的句子之间的关系,计算实体在句子中的相对位置,具体做法如下:
24.1)若eh和e
t
均包含于句子s,则将句子s的第一个字的序号标记为0,第二个字的序号标记为1,依次标记整个句子s,则posh={h
start
,h
end
},pos
t
={t
start
,t
end
}。其中h
start
为eh的开始的字的序号,h
end
为eh的结束的字的序号,t
start
为e
t
的开始的字的序号,t
end
为e
t
的结束的字的序号;
25.2)若eh和e
t
包含于两个相连的句子s1和s2,则将s1和s2进行连接,记为s,若s长度小于等于预设阈值l,并按1)所述方法进行处理;若s长度大于预设阈值l,则不构成配对,并提
示标注者;
26.3)若eh和e
t
包含于两个不相连的句子s1和s2,则将s1、中间句子、s2进行连接,记为s,若s长度小于等于预设阈值l,则按1)的所述方法进行处理;若s长度大于预设阈值l,则不构成配对,并提示标注者。
27.作为本发明的一种改进,步骤s7:对配对结果进行初步关系抽取,具体如下,
28.s7:标注者人工校对s6中的抽取结果,确认预测关系是否正确。如果预测正确,则将结果关系记为并同步骤s6的输入一并记录为一组正确关系抽取结果如果预测错误,则需要标注者人工从候选关系集合r中选择正确的结果关系并记并同步骤s6的输入一并记录为一组校对关系抽取结果
29.作为本发明的一种改进,步骤s8:对关系抽取结果进行人工校对;具体如下:
30.标注者人工校对s7中的抽取结果,确认预测关系是否正确,其具体做法如下:
31.1)如果预测正确,则将结果关系记为并同s5的输入一并记录为一组正确关系抽取结果
32.2)如果预测错误,则需要标注者人工从候选关系集合r中选择正确的结果关系并记并同s5的输入一并记录为一组校对关系抽取结果
33.作为本发明的一种改进,步骤s9:对少样本关系抽取模型进行微调;具体如下:
34.1)当存入的正确关系抽取结果数量小于k
+
且校对关系抽取结果数量小于k-时,使用所有专用关系抽取数据仓库中的数据对net
re
进行微调,其参数更新公式如下:
[0035][0036]
其中,θ
i-1
为更新前的参数,θi为更新后参数,d为所有专用关系抽取数据仓库中的数据;
[0037]
当参数更新后,将d中的所有校对关系抽取结果d-取出,用θi初始化关系抽取模型,并对d-进行预测,将仍然预测错误的结果的错误次数加1;并使用仍然预测错误的校对结果对参数进行一次微调;
[0038]
2)当存入的正确关系抽取结果数量大于等于k
+
或校对关系抽取结果数量大于等于k-时,从正确关系抽取结果d
+
中随机选取k
+
个正确关系抽取结果,从校对关系抽取结果中,按以下公式计算各结果的选中概率:
[0039][0040]
其中,pi表示第i个校对关系抽取结果被选中的概率,eci表示该结果在1)所述的微调后预测中,错误的累计次数;计算所有校对关系抽取结果的概率,被并按概率不重复地选择k-个校对关系抽取结果,组成微调数据集,并对参数进行一次微调。
[0041]
当参数更新后,如1)所述再对所有校对关系抽取结果进行一次预测,将仍然预测
错误的结果的错误次数加1;并使用仍然预测错误的校对结果对参数进行一次微调。
[0042]
作为本发明的一种改进,步骤s10:微调后的少样本关系抽取模型net
re
用于后续的待抽取文本的抽取任务。
[0043]
相对于现有技术,本发明具有如下优点,该技术方案本发明中所述的少样本关系抽取面向的是冷启动知识图谱构建等使用领域的关系抽取方法。在少样本关系抽取中,在系统启动时,需要对所需抽取的关系进行预设,这要求系统使用者完善待抽取关系的关系名称和关系描述的录入,并对每个待抽取关系添加少量标注好的抽取数据。不同于监督学习关系抽取方法,少样本关系抽取的预训练在不同关系的数据集上进行,这一数据集需按任务进行组织,数据组织的基本单位是任务,而每个任务的构成则遵守被称为n-way-k-shot的实验设定。n-way指的是每个任务中被分类的类别数量为n,k-shot指的是在这些任务中的支持集中,每个类别包含了k个训练样本。支持集指的是一个任务中用于训练关系抽取模型的数据,查询集则指的则是用于测试关系抽取模型的数据。在元训练阶段使用的任务被称为元训练任务,在元测试阶段使用的任务被称为元测试任务,而且它们包含不同的分类类别,一般若干元训练任务构成一个轮次,元训练阶段包含一或多个轮次。在元测试阶段,元学习器将在元训练阶段获得的元知识快速应用于支持集的训练过程,通过使用极少量支持集快速对关系抽取模型进行微调,并使用微调结果对专用关系抽取数据集进行关系分类预测。所述框架具有快速启动和低人工成本的特性,这两个特性的实现依赖于:1)利用少样本关系抽取算法实现快速启动的特性,通过元学习方法预训练关系抽取模型的初始化参数,利用该初始化参数可使用极少量数据完成快速启动;2)利用人机交互提供监督信息,利用主动学习技术筛选数据对模型进行微调,提升模型性能并降低微调的时间需求。本框架与现有技术相比,考虑了人机交互所带来的监督信息,利用少样本关系抽取技术解决在关系抽取系统启动阶段的冷启动问题,利用主动学习技术降低模型在微调时所需要使用的数据量,提高了模型的性能并降低了微调所需的时间。有效解决了关系抽取系统的冷启动问题,提出了具有快速启动和低人工成本特性的关系标注和抽取系统框架。基于该框架,可以开发出具有如上特点的关系标注与抽取系统,此类系统在知识图谱构建、对话系统构建、问答系统构建上具有广泛的应用价值和意义。
附图说明
[0044]
图1是关系抽取的常见形式示意图;
[0045]
图2是本发明中所提出的框架总体示意图;
[0046]
图3是本发明实施例中的关系抽取神经网络分类模型的结构。
具体实施方式:
[0047]
为了加深对本发明的理解,下面结合附图对本实施例做详细的说明。
[0048]
实施例1:参见图1-图3,一种快速启动的交互式关系标注与抽取框架,包括以下步骤:
[0049]
s1:使用通用命名实体识别数据集对命名实体识别模型进行预训练;
[0050]
s2:使用通用关系抽取数据集对少样本关系抽取模型进行预训练;
[0051]
s3:设定待抽取关系和少量标注数据;
[0052]
s4:对待抽取文本进行数据预处理;
[0053]
s5:使用命名实体识别模型对待抽取文本进行命名实体识别;
[0054]
s6:对实体进行人工配对;
[0055]
s7:对配对结果进行初步关系抽取;
[0056]
s8:对关系抽取结果进行人工校对;
[0057]
s9:对少样本关系抽取模型进行微调;
[0058]
s10:重复s4到s9直到所有的待抽取文本均处理完成。
[0059]
其中,步骤s1中的快速启动的交互式关系标注与抽取框架如图2所示;
[0060]
构建快速启动的交互式关系标注与抽取框架,其中框架包含:命名实体识别模型、少样本关系抽取模型、待处理文本仓库、通用命名实体识别数据集、通用关系抽取数据集和专用关系抽取数据仓库,此外,所述框架还包含人工校对交互方法、元学习训练方法、参数更新方法和主动学习。
[0061]
步骤s2使用通用关系抽取数据集对少样本关系抽取模型进行预训练,具体如下,构建框架中的命名实体识别模型net
ner
,采用通用领域命名实体类识别数据集进行预训练;构建所述框架中的少样本关系抽取模型net
re
,先使用通用领域关系抽取数据集以元学习方式训练,得到初始化参数θ0,再使用专用关系抽取数仓库对net
re
的参数θ0进行微调,得到参数θ1。
[0062]
所述步骤s2中所述的专用关系抽取数据仓库仅包含标注者自行制定的关系类型和少量的相应标注数据。
[0063]
所述步骤s2中所述的构建少样本关系抽取模型net
re
的步骤中,元学习训练方法,详述如下:
[0064][0065]
进一步地,所述步骤s2中所述的构建少样本关系抽取模型net
re
的步骤中,元学习微调方法,详述如下:
[0066][0067]
步骤s3:设定待抽取关系和少量标注数据;从待处理文本仓库中,选取一条待抽取文本s;
[0068]
步骤s4:对待抽取文本进行数据预处理;使用预训练的命名实体类识别模型对待抽取文本进行命名实体识别,为方便标注者处理,在待处理文本中将命名实体识别的结果{e1,e2,...en}进行标记,具体做法为:将文本中所识别出的实体按不同的类型进行颜色标记,其中,实体类型为预先定义的;
[0069]
步骤s5:使用命名实体识别模型对待抽取文本进行命名实体识别,具体如下,标注者手动将s4中识别出的命名实体进行配对,即选出需要进行关系抽取的头尾实体对{eh,e
t
}。将被标注者选中的实体对{eh,e
t
},以及包含实体对的句子s、实体类型{ch,c
t
}和实体在句子中的相对位置{posh,pos
t
}作为下一步进行关系抽取的输入。
[0070]
步骤s6:对实体进行人工配对,标注者手动将命名实体进行配对:在文本中依次点击两个实体,先点击的实体为头实体eh,对应类型为ch,后点击的实体为e
t
,对应类型为c
t
;实体根据点击的实体和其所在的句子之间的关系,计算实体在句子中的相对位置,具体做法如下:
[0071]
1)若eh和e
t
均包含于句子s,则将句子s的第一个字的序号标记为0,第二个字的序号标记为1,依次标记整个句子s,则posh={h
start
,h
end
},pos
t
={t
start
,t
end
}。其中h
start
为eh的开始的字的序号,h
end
为eh的结束的字的序号,t
start
为e
t
的开始的字的序号,t
end
为e
t
的结束的字的序号;
[0072]
2)若eh和e
t
包含于两个相连的句子s1和s2,则将s1和s2进行连接,记为s,若s长度小于等于预设阈值l,并按1)所述方法进行处理;若s长度大于预设阈值l,则不构成配对,并提示标注者;
[0073]
3)若eh和e
t
包含于两个不相连的句子s1和s2,则将s1、中间句子、s2进行连接,记为
s,若s长度小于等于预设阈值l,则按1)的所述方法进行处理;若s长度大于预设阈值l,则不构成配对,并提示标注者。
[0074]
步骤s7:对配对结果进行初步关系抽取,具体如下,
[0075]
s7:标注者人工校对s6中的抽取结果,确认预测关系是否正确。如果预测正确,则将结果关系记为并同步骤s6的输入一并记录为一组正确关系抽取结果如果预测错误,则需要标注者人工从候选关系集合r中选择正确的结果关系并记并同步骤s6的输入一并记录为一组校对关系抽取结果
[0076]
步骤s8:对关系抽取结果进行人工校对;具体如下:
[0077]
标注者人工校对s7中的抽取结果,确认预测关系是否正确,其具体做法如下:
[0078]
1)如果预测正确,则将结果关系记为并同s5的输入一并记录为一组正确关系抽取结果
[0079]
2)如果预测错误,则需要标注者人工从候选关系集合r中选择正确的结果关系并记并同s5的输入一并记录为一组校对关系抽取结果
[0080]
步骤s9:对少样本关系抽取模型进行微调;具体如下:
[0081]
1)当存入的正确关系抽取结果数量小于k
+
且校对关系抽取结果数量小于k-时,使用所有专用关系抽取数据仓库中的数据对net
re
进行微调,其参数更新公式如下:
[0082][0083]
其中,θ
i-1
为更新前的参数,θi为更新后参数,d为所有专用关系抽取数据仓库中的数据;
[0084]
当参数更新后,将d中的所有校对关系抽取结果d-取出,用θi初始化关系抽取模型,并对d-进行预测,将仍然预测错误的结果的错误次数加1;并使用仍然预测错误的校对结果对参数进行一次微调;
[0085]
2)当存入的正确关系抽取结果数量大于等于k
+
或校对关系抽取结果数量大于等于k-时,从正确关系抽取结果d
+
中随机选取k
+
个正确关系抽取结果,从校对关系抽取结果中,按以下公式计算各结果的选中概率:
[0086][0087]
其中,pi表示第i个校对关系抽取结果被选中的概率,eci表示该结果在1)所述的微调后预测中,错误的累计次数;计算所有校对关系抽取结果的概率,被并按概率不重复地选择k-个校对关系抽取结果,组成微调数据集,并对参数进行一次微调;
[0088]
当参数更新后,如1)所述再对所有校对关系抽取结果进行一次预测,将仍然预测错误的结果的错误次数加1;并使用仍然预测错误的校对结果对参数进行一次微调。
[0089]
步骤s10:微调后的少样本关系抽取模型net
re
用于后续的待抽取文本的抽取任务。
[0090]
具体实施例:参照图1一图3,本实施例中,通用命名实体识别数据集为muc-6和muc-7数据集,通用关系抽取数据集为fewrel,待处理文本仓库中的文本段来源于wikipedia。命名实体识别模型是基于条件随机场的序列标注模型,关系抽取模型采用prototypicalnetwork结构,其中,采用pcnn模型为文本句子和实体进行编码,其结构如图3所示,采用glove词嵌入向量作为预训练词向量对句子中的词进行编码。
[0091]
本实施例中应用本发明提供的一种快速启动的交互式关系标注与抽取框架,其总体框架如图2所示,其具体包括如下步骤:
[0092]
步骤1)使用通用命名实体识别数据集对命名实体识别模型进行预训练;
[0093]
设定命名实体的7个类型:地点(location),人物(person),机构组织(organization),货币(money),百分比(percent),日期(date),时间(time);使用muc 6和muc 7数据集的训练集作为训练数据;训练数据文件中,每行得第一个是字,第二个是它的标签,使用空格分隔,标签类型为“bio-类型”联合标签;使用bert预训练模型对训练数据进行嵌入编码,使用条件随机场作为解码器;使用命名实体类识别任务常用的路径得分和的负对数作为损失函数;
[0094]
步骤2)使用通用关系抽取数据集对少样本关系抽取模型进行预训练;
[0095]
使用fewrel数据集对少样本关系抽取模型进行预训练,在训练文件中,每个训练实例由三个部分组成,自然语言句子s,头实体eh和尾实体e
t
。其中,每个实体中包含三个部分,实体指称,实体首字在s中的相对位置和实体尾字在s中的相对位置;使用glove对自然语言句子s中的单词进行嵌入式向量编码,使用pcnn将句子的嵌入式编码和实体相对位置信息进行编码得到实体向量;使用bilstm对关系标签进行编码得到关系向量;采用余弦相似度计算实体向量和关系向量计算相似度得分;使用间隔损失函数作为训练的损失函数;
[0096]
步骤3)设定待抽取关系和少量标注数据;
[0097]
标注者手动添加若干个待抽取关系,每个关系需要添加关系名称和关系描述;此外,针对每个待抽取关系,添加10个标注数据,标注数据结构同fewrel数据集中的数据结构;
[0098]
步骤4)对待抽取文本进行数据预处理;
[0099]
待抽取文本需先进行清洗和预处理,以方便后续抽取流程,具体操作为:
[0100]
1)滤除特殊符号和标点,采用正则表达式匹配来滤除文本中除逗号、句号、问号、引号和书名号之外的其他所有特殊符号符号;
[0101]
2)为保证抽取速度,将按段落为单位存放。针对长文本,本实施例中以300词为上限,将长文本以句子划分成段落,以限制内最后一个自然句的结束作为分割条件;
[0102]
步骤5)使用命名实体识别模型对待抽取文本进行命名实体识别;
[0103]
针对命名实体识别的结果,根据“bio-类型”标签,将不同实体进行划分,并标记各实体的类型;本实施例中以特殊颜色对实体进行了标注,在预选定义的七类实体中,每类实体均定义不同颜色,并和文本一同进行显示;
[0104]
步骤6)对实体进行人工配对;
[0105]
在本实施例中,标注者在文本中依次点击两个实体进行配对。先点击的实体为头实体eh,对应类型为ch,后点击的实体为e
t
,对应类型为c
t
;实体根据点击的实体和其所在的句子之间的关系,计算实体在句子中的相对位置,具体做法如下:
[0106]
1)若eh和e
t
均包含于句子s,则将句子s的第一个字的序号标记为0,第二个字的序号标记为1,依次标记整个句子s,则posh={n
start
,h
end
},pos
t
={t
start
,t
end
}。其中h
start
为eh的开始的字的序号,h
end
为eh的结束的字的序号,t
start
为e
t
的开始的字的序号,t
end
为e
t
的结束的字的序号;
[0107]
2)若eh和e
t
包含于两个相连的句子s1和s2,则将s1和s2进行连接,记为s,若s长度小于等于预设阈值l,并按1)所述方法进行处理;若s长度大于预设阈值l,则不构成配对,并提示标注者;
[0108]
3)若eh和e
t
包含于两个不相连的句子s1和s2,则将s1、中间句子、s2进行连接,记为s,若s长度小于等于预设阈值l,则按1)的所述方法进行处理;若s长度大于预设阈值l,则不构成配对,并提示标注者;
[0109]
步骤7)对配对结果进行初步关系抽取;
[0110]
将配对结果输入给关系抽取模型,关系抽取模型取出句子s、实体eh和e
t
、实体相对位置posh和pos
t
,将其编码为实例向量;将专用关系抽取数据仓库中的候选关系取出,并将其编码为关系向量;计算实例向量与关系向量之间的余弦相似度,并选择相似度最高的关系向量所代表的关系作为预测关系
[0111]
步骤8)对关系抽取结果进行人工校对;
[0112]
在本实施例中,标注者需要人工校对步骤7)中的抽取结果,确认预测关系是否正确。其具体做法如下:
[0113]
1)如果预测正确,则将结果关系记为并步骤7)的输入一并记录为一组正确关系抽取结果
[0114]
2)如果预测错误,则需要标注者人工从候选关系集合r中选择正确的结果关系并记并步骤7)的输入一并记录为一组校对关系抽取结果
[0115]
步骤9)对少样本关系抽取模型进行微调;
[0116]
在本实施例中,当专用关系抽取数据仓库存入的关系抽取结果数量达到一定数量后,使用其中的数据对少样本关系抽取模型net
re
进行微调,其具体做法如下:
[0117]
1)当存入的正确关系抽取结果数量小于k
+
且校对关系抽取结果数量小于k-时,使用所有专用关系抽取数据仓库中的数据对net
re
进行微调,其参数更新公式如下:
[0118][0119]
其中,θ
i-1
为更新前的参数,θi为更新后参数,d为所有专用关系抽取数据仓库中的数据;
[0120]
当参数更新后,将d中的所有校对关系抽取结果d-取出,用θi初始化关系抽取模型,并对d-进行预测,将仍然预测错误的结果的错误次数加1;并使用仍然预测错误的校对结果对参数进行一次微调;
[0121]
2)当存入的正确关系抽取结果数量大于等于k
+
或校对关系抽取结果数量大于等于k-时,从正确关系抽取结果d
+
中随机选取k
+
个正确关系抽取结果,从校对关系抽取结果
中,按以下公式计算各结果的选中概率:
[0122][0123]
其中,pi表示第i个校对关系抽取结果被选中的概率,eci表示该结果在1)所述的微调后预测中,错误的累计次数;计算所有校对关系抽取结果的概率,被并按概率不重复地选择k-个校对关系抽取结果,组成微调数据集,并对参数进行一次微调;
[0124]
当参数更新后,如1)所述再对所有校对关系抽取结果进行一次预测,将仍然预测错误的结果的错误次数加1;并使用仍然预测错误的校对结果对参数进行一次微调;
[0125]
步骤10)重复步骤4)到步骤9)直到所有的待抽取文本均处理完成。
[0126]
综上所述,本发明方法基于人机交互所带来的监督信息,提出了一种结合少样本关系抽取技术和主动学习技术的互式关系标注与抽取框架。该方法利用了少样本关系抽取技术解决在关系抽取系统启动阶段的冷启动问题,利用主动学习技术降低模型在微调时所需要使用的数据量,提高了模型的性能并降低了微调所需的时间。基于该方法,可有效克服现有关系抽取系统冷启动成本高昂和重人力成本投入的缺点,实现具有快速启动和低人工成本特性的关系标注和抽取系统。此类系统在知识图谱构建、对话系统构建、问答系统构建等自然语言处理领域及信息抽取领域具有广泛的应用价值和应用前景。
[0127]
需要说明的是上述实施例,并非用来限定本发明的保护范围,在上述技术方案的基础上所作出的等同变换或替代均落入本发明权利要求所保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1