音乐播放控制方法及系统与流程
1.本发明属于智能控制技术领域,具体涉及一种音乐播放控制方法及系统。
背景技术:
2.目前,许多音乐播放器都支持设置不同的音效,例如摇滚、电子、人声等,但用户如果需要更换不同音效要进行手动设置,这种切换方式在开车、写作等场景下操作不便,导致用户体验差,影响使用率。
技术实现要素:
3.本发明提供一种音乐播放控制方法及系统,能够根据音乐播放场景及用户表情,控制更匹配的音乐播放方式。本发明由以下技术方案实现:
4.一种音乐播放控制方法,包括:
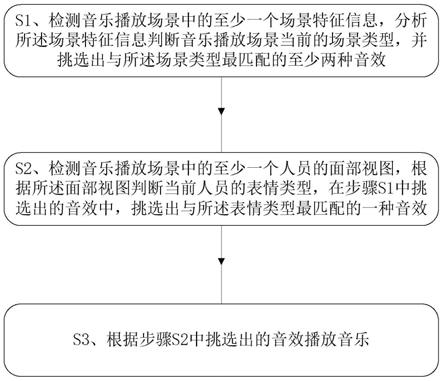
5.s1、检测音乐播放场景中的至少一个场景特征信息,分析所述场景特征信息判断音乐播放场景当前的场景类型,并挑选出与所述场景类型最匹配的至少两种音效;
6.s2、检测音乐播放场景中的至少一个人员的面部视图,根据所述面部视图判断当前人员的表情类型,在步骤s1中挑选出的音效中,挑选出与所述表情类型最匹配的一种音效;
7.s3、根据步骤s2中挑选出的音效播放音乐。
8.优选地,所述场景类型包括嘈杂类型和安静类型,所述场景特征信息包括音乐播放场景中的嘈杂音强度、人员密度中的至少一个;所述嘈杂音强度、人员密度超过设定阈值则将所述场景类型判断为嘈杂类型,否则判断为安静类型。
9.优选地,所述表情类型包括喜、怒、悲、乐、忧、恐、惊中的至少两种,步骤s2中,将所述面部视图与预存的表情视图进行特征比对,找出最接近的表情视图判断出相应的表情类型。
10.优选地,步骤s1之前,还包括模式选择步骤,所述播放模式包括智能推荐模式,选择所述智能推荐模式则进入步骤s1。
11.优选地,步骤s1之前,将各种音效与各种场景类型的音效匹配度进行存储,将各种音效与各种表情类型的音效匹配度进行存储;步骤s2和s3中基于所述音效匹配度的高低对音效进行挑选。
12.优选地,步骤s1还包括:挑选出与所述场景类型最匹配的至少两首歌曲;步骤s2还包括:在步骤s1中挑选出的至少两首歌曲中,挑选出与所述表情类型最匹配的一首歌曲;步骤s3还包括:根据所述最匹配的一首歌曲播放音乐。
13.优选地,步骤s1之前,将各首歌曲与各种场景类型的歌曲匹配度进行存储,将各首歌曲与各种表情类型的歌曲匹配度进行存储;步骤s2和s3中基于所述歌曲匹配度的高低对歌曲进行挑选。
14.一种音乐播放控制系统,包括音乐播放器、场景特征采集器、面部视图采集器;所
述音乐播放器包括音效管理模块及音乐播放模块,所述音效管理模块根据所述场景特征采集器检测的音乐播放场景中的至少一个场景特征信息,分析所述场景特征信息判断音乐播放场景当前的场景类型,并挑选出与所述场景类型最匹配的至少两种音效;所述音效管理模块还根据所述面部视图采集器检测的音乐播放场景中的至少一个人员的面部视图,根据所述面部视图判断当前人员的表情类型,在所述挑选出的至少两种音效中,挑选出与所述表情类型最匹配的一种音效;所述音乐播放模块根据所述最匹配的一种音效播放音乐。
15.优选地,所述音乐播放器还包括曲目管理模块,所述曲目管理模块用于挑选出与所述场景类型最匹配的至少两首歌曲,以及在挑选出的至少两首歌曲中,挑选出与所述表情类型最匹配的一首歌曲;所述音乐播放模块根据所述最匹配的一首歌曲播放音乐。
16.优选地,所述场景特征采集器包括用于对音乐播放场景中嘈杂音强度进行检测的拾音器及或用于对音乐播放场景中人员密度进行检测的红外传感器;所述面部视图采集器为用于对音乐播放场景中人员面部进行拍摄的摄像头。
17.本发明的有益效果在于:通过对音乐播放场景中的嘈杂音强度及或人员密度等场景特征进行检测,确定当前场景类型,基于此对音效进行一次挑选;然后,通过对音乐播放场景中人员面部进行拍摄,获取用户表情类型所反映的情绪状态,基于此对所选音效再进行一次挑选并确认最终的音效。此外,本发明还可以基于场景类型及用户的表情类型挑选匹配度高的歌曲。
附图说明
18.图1为本发明实施例提供的风扇送风控制系统的构成示意图。
具体实施方式
19.结合图1所示,本实施例提供的音乐播放控制方法,主要用于根据音乐播放场景及用户表情,对预设的音效进行挑选,预设音效一般包括:人声、摇滚乐、重金属、电子、重低音、柔和、助眠等。
20.上述音乐播放控制方法包括以下主要步骤:
21.s1、检测音乐播放场景中的至少一个场景特征信息,分析所述场景特征信息判断音乐播放场景当前的场景类型,并挑选出与所述场景类型最匹配的至少两种音效。
22.其中,场景类型包括嘈杂类型和安静类型,场景特征信息包括音乐播放场景中的嘈杂音强度、人员密度中的至少一个;嘈杂音强度、人员密度超过设定阈值则将所述场景类型判断为嘈杂类型,否则判断为安静类型。而且,当用户所处的环境是比较嘈杂时,筛选出人声、摇滚乐、重金属、电子等类型的预设音效,当用户所处环境比较安静时,筛选出重低音、柔和、助眠等类型的预设音效。
23.s2、检测音乐播放场景中的至少一个人员的面部视图,根据所述面部视图判断当前人员的表情类型,在步骤s1中挑选出的音效中,挑选出与所述表情类型最匹配的一种音效。
24.其中,所述表情类型包括喜、怒、悲、乐、忧、恐、惊中的至少两种,步骤s2中,将检测到的所述面部视图与预存的表情视图进行特征比对,找出最接近的表情视图判断出相应的表情类型。
25.s3、根据步骤s2中挑选出的音效播放音乐。
26.本实施例中,步骤s1之前,还包括模式选择步骤,所述播放模式包括智能推荐模式,选择所述智能推荐模式则进入步骤s1。而且,步骤s1之前,将各种音效与各种场景类型的音效匹配度进行存储,将各种音效与各种表情类型的音效匹配度进行存储;步骤s2和s3中是基于所述音效匹配度的高低对音效进行挑选。
27.另外,本实施例提供的音乐播放控制方法,还可以基于场景类型及用户的表情类型挑选匹配度高的歌曲。实现该功能时,步骤s1还包括:挑选出与所述场景类型最匹配的至少两首歌曲;步骤s2还包括:在步骤s1中挑选出的至少两首歌曲中,挑选出与所述表情类型最匹配的一首歌曲;步骤s3还包括:根据所述最匹配的一首歌曲播放音乐。同样地,步骤s1之前,需要将各首歌曲与各种场景类型的歌曲匹配度进行存储,将各首歌曲与各种表情类型的歌曲匹配度进行存储;步骤s2和s3中也相应基于所述歌曲匹配度的高低对歌曲进行挑选。
28.本实施例还提供一种音乐播放控制系统,包括音乐播放器、场景特征采集器、面部视图采集器;所述音乐播放器包括音效管理模块及音乐播放模块,所述音效管理模块根据所述场景特征采集器检测的音乐播放场景中的至少一个场景特征信息,分析所述场景特征信息判断音乐播放场景当前的场景类型,并挑选出与所述场景类型最匹配的至少两种音效;所述音效管理模块还根据所述面部视图采集器检测的音乐播放场景中的至少一个人员的面部视图,根据所述面部视图判断当前人员的表情类型,在所述挑选出的至少两种音效中,挑选出与所述表情类型最匹配的一种音效;所述音乐播放模块根据所述最匹配的一种音效播放音乐。
29.相应地,为了实现基于场景类型及表情类型挑选匹配度高的歌曲。上述音乐播放器还包括曲目管理模块,用于挑选出与所述场景类型最匹配的至少两首歌曲,以及在挑选出的至少两首歌曲中,进而挑选出与所述表情类型最匹配的一首歌曲;音乐播放模块根据所述最匹配的一首歌曲播放音乐。
30.具体地,场景特征采集器包括用于对音乐播放场景中嘈杂音强度进行检测的拾音器及或用于对音乐播放场景中人员密度进行检测的红外传感器;面部视图采集器为用于对音乐播放场景中人员面部进行拍摄的摄像头。
31.以上具体实施方式仅为充分公开而非限制本发明,凡基于本发明的创作主旨、无需经过创造性劳动即可得到的等效技术特征的替换,应当视为本技术揭露的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1