基于人工智能的识别系统的制作方法
1.本发明涉及人工智能领域,尤其涉及基于人工智能的识别系统。
背景技术:
2.人工智能(简称ai),是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。随着人工智能技术的不断发展,人工智能技术愈加成熟,人工智能应用到实际生产环境中,为人们的生活提供了极大的便利。
3.随着社会的不断发展,社会对于残障人士也越来越关心,对于聋哑人来说,他们既不能发出声音也不能听到外界的声音,只能使用手语与外界交流,但是社会上使用手语的人较少,导致聋哑人与正常人之间沟通较为不便,尤其在办理一些业务时,聋哑人与工作人员之间的沟通障碍,往往会使得他们在办理业务时,困难重重,为此,本方案提出了基于人工智能的识别系统。
技术实现要素:
4.本发明提出的基于人工智能的识别系统,解决了现有技术中与聋哑人沟通不方便的问题。
5.为了实现上述目的,本发明采用了如下技术方案:
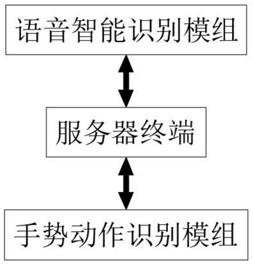
6.基于人工智能的识别系统,包括服务器终端、语音智能识别模组和手势动作识别模组,所述服务器终端中构建有手语编码表与文本编码表,所述语音智能识别模组包括:语音录入模块、语音预处理模块、语音翻译模块、文本编码模块和识别显示模块,所述语音通过语音录入模块录入,经语音预处理模块提高语音信号,语音信号由语音翻译模块译成文本,文本经过文本编码模块编码编码成文字编码,文本编码经识别显示模块参照手语编码表译成手语动作,并通过显示器实时播放,所述手势动作识别模组包括:动作录入模块、动作截取模块、动作翻译模块、文本组合模块和播放模块,所述手语动作通过录入模块录入,经过动作截取模块对录入的手语动作进行截取,得到手势动作图片,手势动作图片经过动作翻译模块参照手语编码表得到手语编码,文本组合模块参照文本编码表将手语编码转换成文字,并对文字进行组合得到通顺的语句文本,通过播放模块对语句文本播放。
7.优选的,所述语音预处理模块具体操作为:对语音录入模块中得到的原始语音进行归一化处理,然后采用梅尔频率倒谱系数(mfcc)获取语音的声谱特征图。
8.优选的,所述语音翻译模块中构建有ctc损失函数。
9.优选的,所述动作录入模块包括到多个高清摄像头,动作截取模块对高清摄像头摄录的视频逐帧分析,并截取多个具有动作意义的动作图片。
10.优选的,所述手语编码表中的手语编码与文本编码表中文本编码一一对应。
11.基于人工智能的识别系统的识别方法,包括语音智能识别和手势动作识别;
12.所述语音智能识别包括以下步骤:
13.a1、语音录入:对语音进行端点检测,找到语音录入的起始点与结束点,得到原始
语音;
14.a2、语音预处理:对a1中得到的原始语音进行预处理,得到清晰的语音信号;
15.a3、语音翻译:对a2中得到的语音信号翻译成语句通顺的句段,并截取句段中的关键字段;
16.a4、文字编码:a3中截取到的关键字段与文本编码表对比,组成文字编码;
17.a5、识别显示:参照手语编码表,按照a4中得到的文字编码组成手语动作、并通过显示器实时3d演示播放;
18.手势动作识别,所述手势动作识别包括以下步骤:
19.b1、动作录入:对手势动作进行录入,找到手势录入的起始点与结束点,得到手势动作视频;
20.b2、动作截取:将b1中得到的手势动作进行截取,得到多个动作图片;
21.b3、动作翻译:b3中的动作图片与手语编码表对比,得到手语编码;
22.b4、文本组合:参照文本编码表将b3中的手语编码转换成文字,并对文字进行组合得到通顺的语句文本;
23.b5、语音播放:b4中得到的语句文本转换成电信号,经过扬声器播放。
24.优选的,所述a2中语音预处理具体操作为:对a1中得到的原始语音进行归一化处理,以降低噪音的影响,然后采用梅尔频率倒谱系数(mfcc)获取语音的声谱特征图。
25.优选的,所述a3中语音翻译过程中,采用ctc损失函数对声谱特征图进行翻译。
26.优选的,所述文本组合将b3中得到的手语编码参考文本手语编码表得到输出文本,然后把输出的文本输入到语言模型,通过语言模型来计算一个句子出现的概率,最终选出概率最大的句子,然后输出比较通顺的文字,再采用拼写纠错模型来对错别字和同音字进行纠错改正,最终得到通顺且语义逻辑连贯的文本。
27.本发明的有益效果:
28.1、通过语音智能识别模组、服务器终端、手势多组识别模组等相互配合,实现将语音转换成手势动作,并通过显示器演示播放,或者对聋哑人的手势动作进行识别转换成语音,通过扬声器播报,有效的方便了聋哑人与社会上他人之间的沟通。
29.2、通过对语音进行预处理之后,提高语音的清晰度,并经过ctc函数对语音进行翻译,有效的保证了语音能够被准确识别。
30.3、通过高清摄像头、动作截取模块、文本组合模块等相互配合,实现对手势动作进行捕捉,并截取有意义的动作图片,得到手语动作的含义文本,并对文本内容进行组合,得到顺畅的语句文本
31.本发明布局合理,不仅能够将语音转换成手势动作,方便正常人向聋哑人表达话语的含义,还能够将手势多组转换成语音,方便聋哑人向正常人表达手势动作含义,有效的方便了聋哑人与正常人之间沟通,易于推广使用。
附图说明
32.图1为本发明的系统架构示意图。
33.图2为本发明的语音智能识别模组架构示意图。
34.图3为本发明的手势多组识别模组架构示意图。
具体实施方式
35.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
36.参照图1-3,基于人工智能的识别系统,包括服务器终端、语音智能识别模组和手势动作识别模组,服务器终端中构建有手语编码表与文本编码表,手语编码表中的手语编码与文本编码表中文本编码一一对应。
37.语音智能识别模组包括:语音录入模块、语音预处理模块、语音翻译模块、文本编码模块和识别显示模块,语音通过语音录入模块录入,得到原始的语音文件,语音预处理模块对录入的原始语音进行归一化处理,然后采用梅尔频率倒谱系数(mfcc)获取语音的声谱特征图,语音翻译模块中构建有ctc损失函数,将声谱特征图翻译成文本文件,并截取文本关键词,文本关键词经过文本编码模块编码编码成文字编码,文本编码经识别显示模块参照手语编码表译成手语动作,并通过显示器实时3d演示播放。
38.手势动作识别模组包括:动作录入模块、动作截取模块、动作翻译模块、文本组合模块和播放模块,动作录入模块包括到多个高清摄像头,手语动作经过多个高清摄像头全面的对手势动作录入,动作截取模块对高清摄像头摄录的视频逐帧分析,并截取多个具有动作意义的手势动作图片,手势动作图片经过动作翻译模块参照手语编码表得到手语编码,文本组合模块参照文本编码表将手语编码转换成文字,并对文字进行组合得到通顺的语句文本,通过播放模块对语句文本播放。
39.语音智能识别包括以下步骤:
40.a1、语音录入:录音机对语音录制,并对语音进行端点检测,找到语音录入的起始点与结束点,得到原始语音;
41.a2、语音预处理:对a1中得到的原始语音进行降噪处理,然后对降噪之后的语音进行归一化处理,进一步的降低噪音的影响,然后采用梅尔频率倒谱系数(mfcc)获取语音的声谱特征图;
42.a3、语音翻译:在语音翻译模块中构建有ctc损失函数,在语音翻译过程中,采用ctc损失函数对声谱特征图进行翻译,得到语句通顺的句段,并截取句段中的关键字段;
43.a4、文字编码:a3中截取到的关键字段与文本编码表对比,组成文字编码;
44.a5、识别显示:参照手语编码表,按照a4中得到的文字编码组成手语动作,通过手语模型将多个手语动作组成流畅的手语动作,并通过显示器实时3d演示播放,便于聋哑人了解话语的含义。
45.手势动作识别,手势动作识别包括以下步骤:
46.b1、动作录入:使用多个高清摄像机从多个角度对手势动作进行录入,并找到手势动作的起始点与结束点,得到手势动作视频;
47.b2、动作截取:对高清摄像头摄录的视频逐帧分析,并截取多个具有动作意义的手势动作图片,筛除无意义的手势动作图片;
48.b3、动作翻译:b3中的动作图片与手语编码表对比,得到手语编码;
49.b4、文本组合模块:参照文本编码表将b3中的手语编码转换成文字,然后把输出的文本输入到语言模型,通过语言模型来计算一个句子出现的概率,最终选出概率最大的句子,然后输出比较通顺的文字,再采用拼写纠错模型来对错别字和同音字进行纠错改正,最
终得到通顺且语义逻辑连贯的文本;
50.b5、播放模块:b4中得到的语句文本转换成电信号,经过扬声器播放,进而便于将手势动作转换成语音,便于他人了解手势语的含义。
51.工作原理:在使用时,语音经过语音录入模块录入之后,经过语音预处理模块进行处理之后,有语音翻译模块翻译成文本句段,然后经过文本编码模块参照文本编码表对文本句段进行编码,得到文本编码,识别显示模块参照手语编码表对文本编码翻译成手语动作,通过手语模型将多个手语动作组成流畅的手语动作,并通过显示器实时3d演示播放,便于聋哑人了解话语的含义,聋哑人的手语动作被动作录入模块中的多个高清摄像机捕捉,得到手势动作视频,经过动作截取模块对手势动作视频一帧一帧的分析,筛除无意义的动作图片,并截取有意义的动作图片,截取的动作图片参照手语编码表得到手语编码,文本组合模块先参照文本编码表将手语编码翻译成字段,然后把输出的文本字段输入到语言模型,通过语言模型来计算一个句子出现的概率,最终选出概率最大的句子,然后输出比较通顺的文字,再采用拼写纠错模型来对错别字和同音字进行纠错改正,最终得到通顺且语义逻辑连贯的文本,播放模块加将最终得到的文本转换成电信号,并经过扬声器播放。
52.在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的设备或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
53.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
54.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1