一种基于视角生成器的点云补全方法
1.本发明属于计算机视觉技术领域;尤其涉及一种基于视角生成器的点云补全技术。
背景技术:
2.近年来,点云补全任务在计算机视觉和机器人领域引起了广泛的关注。因为分辨率或遮挡等限制,由深度相机或激光雷达等设备获取的原始点云数据通常是稀疏和残缺的。不完整的三维物体极大地限制了其在实际生活中的应用,如目标检测、场景分割等其他下游任务。因此,从部分观察的残缺点云中预测或推断出缺失的结构是非常必要的,这在三维视觉领域具有非常重要的潜力和价值,尤其是自动驾驶、机器人等应用场景。
3.许多工作都试图解决点云补全问题。这些方法根据三维数据的表示方法可以分为三类:基于体素的方法、基于网格的方法和基于点云的方法。基于体素的方法在体积数据上进行形状补全,例如采用占用网格或tsdf体素表示等。使用体素表示方法的优点是可以直接使用卷积操作,但缺点是会消耗大量的内存。基于网格的方法将三维物体表示为一组顶点和边的集和。虽然网格可以描述复杂的结构,但由于其固定的顶点连接模式,在模型训练中很难改变拓扑形状。相比之下,点云是一种直观的、简洁的三维数据表示,越来越多的研究关注基于点云的形状补全方法。然而,点云的无序性和不规则性给点云完成任务带来了巨大挑战。目前主流的点云补全方法的解码器结构大多采用基于分辨率的从粗到细的策略,通过对稀疏的粗点云进行上采样来获得精细输出。由粗到细的策略适用于由分辨率引起的残缺点云补全任务,对于由视角遮挡引起的缺失表现不够出色。如何更好的处理由视角引起的点云补全任务是本专利的主要内容。
技术实现要素:
4.为解决上述问题,本发明公开了一种基于视角生成器的点云补全方法,该方法包括以下步骤:
5.s1、数据集生成:使用不可见点移除算法对数据集进行处理,生成残缺点云pv;
6.s2、网络模型构建:基于编码器-解码器结构,提出基于视角的点云生成器,构建pv-net网络模型;
7.s3、模型训练:使用生成的训练集,采用优化算法降低损失函数,使得网络收敛,完成点云补全。
8.本发明进一步优选:所述步骤s1中所述的不可见点移除算法具体包括视角选取、球面映射和可见点选取。
9.其中视角选取的具体方法为:以单位正二十面体的十二个顶点作为视角c,视角方向朝向坐标原点(0,0,0);球面映射操作的具体步骤为:任意选择视角ck∈c,将点云p中任意一点pi映射到半径为r的球面上球面映射公式为:
[0010][0011]
可见点选取操作的具体步骤为:选择由视角ck和映射集并集中的凸包点,得到最终只含可见点的残缺点云pv。
[0012]
本发明进一步优选:步骤s2中所述的pv-net网络模型由编码器e和解码器d组成,
[0013]
编码器e负责提取输入残缺点云的全局特征f,解码器d负责对全局特征f解码得到完整点云;
[0014]
编码器e的具体结构为:输入残缺点云pv首先通过由三个多层感知机(mlp)组成的卷积层conv1,得到256维的特征,接着经过最大池化层得到全局特征f2,公式为:
[0015]
f2=maxpool(conv1(pv)),
[0016]
将全局特征f2在维度2上重复256次与f1拼接得到混合特征f3,公式为:
[0017]
f3=[repeat(f2)||f1],
[0018]
接着再通过由三个mlp组成的卷积层conv2和最大池化层得到最终的全局特征f,公式为:
[0019]
f=maxpool(conv2(f3));
[0020]
解码器d的具体结构为:输入解码器e得到的全局特征f,经过由k个视角生成器组成的编码器d1,得到中间点云yk,公式为:
[0021][0022]
其中,γ为最远点采样操作,∪为逐点的拼接操作,为每个视角生成器的输出,公式为:
[0023][0024]
其中,vi为相邻视角的视角参数,f为编码器得到的全局特征,g为二维网格生成器生成的二维网格参数。
[0025]
再经过由j个视角生成器组成的编码器d2,得到最终完整点云y,公式为:
[0026][0027]yji
=mlps[vi,yk,g]
[0028]
所述的一种基于视角生成器的点云补全方法,步骤s3中所述的生成训练集包括残缺点云和完整点云对,优化算法为梯度下降法,损失函数采用倒角距离(chamfer distance,cd)和地球移动距离(earth mover’s distance,emd),定义为:
[0029][0030][0031]
其中,s1、s2为任意两个点云集。需要注意的是,emd距离需要两个点云集点数相同,cd两个子集点数可以任意。pv-net的损失函数公式为:
[0032][0033]
其中,yk为解码器第一阶段各视角生成器的输出,yj为解码器第二阶段各视角生成器的输出,y为网络的最终输出完整点云,为真值。
[0034]
本发明的有益效果:
[0035]
1、本发明针对点云补全方法在处理由视角遮挡产生的点云缺失时容易产生整体形状粗估计误差和局部细节恢复不好的问题,提出了一种基于视角生成器的点云补全方法,有效提高了点云整体和局部细节的补全质量。
[0036]
2、本发明通过采用基于编码器-解码器的结构,设计了基于视角的点云补全网络pv-net,其中解码器利用了编码器和视角信息,有效的针对不同视角下的残缺点云,进行针对处理,通过逐步扩大残缺点云的视角,恢复缺失点云,充分挖掘不同视角下残缺点云的关系,从而得到整体性更强的完整点云,同时保留点云的局部细节,达到更优的补全效果。
附图说明
[0037]
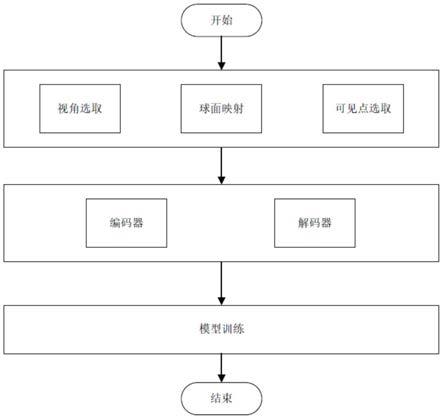
图1是本发明的整个流程图;
[0038]
图2是本发明实施例中的视角选取图;
[0039]
图3是本发明pv-net网络结构图;
[0040]
图4是本发明编码器结构图;
[0041]
图5是本发明解码器结构图;
[0042]
图6是本发明实施例提供的8类点云仿真结果图;
[0043]
图7是本发明实施例提供的飞机点云不同视角下仿真结果图。
具体实施方式
[0044]
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。需要说明的是,下面描述中使用的词语“前”、“后”、“左”、“右”、“上”和“下”指的是附图中的方向,词语“内”和“外”分别指的是朝向或远离特定部件几何中心的方向。
[0045]
本实施例的一种种基于视角生成器的点云补全方法,算法流程图如图1所示。具体包括以下步骤:
[0046]
步骤1:数据集生成:使用不可见点移除算法对数据集进行处理,生成残缺点云pv,包括视角选取、球面映射和可见点选取三个模块。
[0047]
视角选取的具体方法为:以单位正二十面体的十二个顶点作为视角c,视角方向朝向坐标原点(0,0,0),如图2所示;球面映射操作的具体步骤为:任意选择视角ck∈c,将点云p中任意一点pi映射到半径为r的球面上球面映射公式为:
[0048][0049]
可见点选取操作的具体步骤为:选择由视角ck和映射集并集中的凸包点,得到最终只含可见点的残缺点云pv。
[0050]
步骤2:网络模型构建:如图3所示,基于编码器-解码器结构,提出基于视角的点云生成器,构建pv-net网络模型。由编码器e和解码器d1、d2组成,编码器e负责提取输入残缺点云的全局特征f,解码器d1、d2负责对全局特征f解码得到完整点云。
[0051]
编码器e的具体结构如图4所示,输入残缺点云pv首先通过由三个多层感知机(mlp)组成的卷积层conv1,得到256维的特征,接着经过最大池化层得到全局特征f2,公式为:
[0052]
f2=maxpool(conv1(pv)),
[0053]
将全局特征f2在维度2上重复256次与f1拼接得到混合特征f3,公式为:
[0054]
f3=[repeat(f2)||f1],
[0055]
接着再通过由三个mlp组成的卷积层conv2和最大池化层得到最终的全局特征f,公式为:
[0056]
f=maxpool(conv2(f3));
[0057]
解码器的具体结构如图5所示,输入解码器e得到的全局特征f,经过由k个视角生成器组成的编码器d1,得到中间点云yk,公式为:
[0058][0059]
其中,γ为最远点采样操作,∪为逐点的拼接操作,为每个视角生成器的输出,公式为:
[0060][0061]
其中,vi为相邻视角的视角参数,f为编码器得到的全局特征,g为二维网格生成器生成的二维网格参数。
[0062]
再经过由j个视角生成器组成的编码器d2,得到最终完整点云y,公式为:
[0063][0064]yji
=mlps[vi,yk,g]。
[0065]
步骤3:模型训练:使用生成的训练集,采用优化算法降低损失函数,使得网络收敛,完成点云补全。训练集包括残缺点云和完整点云对,优化算法为梯度下降法,损失函数采用倒角距离(chamfer distance,cd)和地球移动距离(earth mover’s distance,emd),定义为:
[0066][0067][0068]
其中,s1、s2为任意两个点云集。需要注意的是,emd距离需要两个点云集点数相同,cd两个子集点数可以任意。pv-net的损失函数公式为:
[0069]
[0070]
其中,yk为解码器第一阶段各视角生成器的输出,yj为解码器第二阶段各视角生成器的输出,y为网络的最终输出完整点云,为真值。
[0071]
训练集包括残缺点云和完整点云对,优化算法为梯度下降法,损失函数采用倒角距离(chamfer distance,cd)和地球移动距离(earth mover’s distance,emd),定义为:
[0072][0073][0074]
其中,s1、s2为任意两个点云集。需要注意的是,emd距离需要两个点云集点数相同,cd两个子集点数可以任意。pv-net的损失函数公式为:
[0075][0076]
其中,yk为解码器第一阶段各视角生成器的输出,yj为解码器第二阶段各视角生成器的输出,y为网络的最终输出完整点云,为真值。
[0077]
下面结合仿真实验对本发明的技术效果作进一步描述。
[0078]
本发明仿真实验是采用本发明和现有点云补全网络,分别对pcn数据集中测试集进行补全,获得点云补全定性结果图,如图6所示。
[0079]
在仿真实验中,采用的现有技术包括:
①
wentao yuan等人在其发表的论文“pcn:point completion network.in 2018international conference on 3d vision(pp.728-737).ieee.”中提出的点云补全网络;
②
yaoqing yang等人在其发表的论文“foldingnet:point cloud auto-encoder via deep grid deformation.in 2018ieee/cvf conference on computer vision and pattern recognition(pp.206-215).ieee”中提出的点云补全网络;
③
lyne p.tchapmi等人在其发表的论文“topnet:structural point cloud decoder.2019ieee/cvf conference on computer vision and pattern recognition(pp.383-392).ieee”中提出的点云补全网络。
[0080]
下面结合图6的仿真图对本发明的效果做进一步的描述。图6中第一列、第七列分别为按步骤1被处理到固定点数为512和2048个点的残缺输入点云和完整真值点云,第二列到第五列为现有技术在输出点数分辨率分别为2048点下的补全结果,第六列为本发明方法在输出点数分辨率为2048个点下的补全结果。从图6定性的测试结果中可以清晰看出现有技术与本发明补全结果相比,不能很好保存输入残缺点云中的细节突出部位,对残缺部位的推理效果不够准确,且补全点云的点数分布不够均匀。
[0081]
利用步骤3提及的倒角距离作为点云补全结果的评价标准,将所有补全结果与真值点云之间的倒角距离绘制成表1。
[0082]
表1仿真实验中本发明和现有技术补全的定量测试结果
[0083][0084]
结合表1可以看出,本发明在输出分辨率为2048个点补全结果的倒角距离均小于现有技术,证明本发明可以得到与真值点云更相似的补全点云。
[0085]
应当指出,上述实施实例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定,这里无需也无法对所有的实施方式予以穷举。本实施例中未明确的各组成部分均可用现有技术加以实现。对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1