低剂量CT图像降噪方法及装置
低剂量ct图像降噪方法及装置
技术领域
1.本发明涉及一种低剂量ct图像降噪方法及装置。
背景技术:
2.现在公开且较流行的低剂量ct图像降噪方法包括投影域过滤、迭代重建和图像域后处理。基于投影域过滤的方法,大多采用惩罚加权最小二乘算法、双边滤波和结构自适应滤波等图像处理方法进行去噪,这可能导致图像域的边缘模糊和空间分辨率损失。基于迭代重建的算法计算量大且和投影域滤波一样需要访问对大多数用户不透明的原始投影数据。后处理方法不需要访问低剂量ct的投影数据,很容易集成到临床低剂量ct的工作流程中,移植性强,但是传统的后处理方法容易在抑制噪声/伪影的同时模糊细节信息。基于分块的k-svd算法属于传统字典学习范畴,它交替更新字典中的原子和字典的稀疏表示,以此来抑制图像中的噪声/伪影,但基于分块且独立重建图像块会缺乏平移不变性,容易忽略不同块之间的结构依赖性,相邻甚至重叠块的独立稀疏也使得整个图像的稀疏表示高度冗余。
3.随着深度学习技术的快速发展,基于卷积神经网络的方法在图像分类,目标检测,图像去噪和图像融合等领域取得了长足的进步。卷积神经网络能够在输入图像中提取多张特征图,具有强大的特征提取能力,其训练过程是输入数据和标签数据之间误差函数的最小化过程,但这种输入数据到标签数据的学习映射缺乏可解释性。深度学习技术下的去噪方法的差异性往往在于精心设计的复杂网络,但它们都需要较大的训练数据集,用于医学图像降噪时也会产生过度模糊的现象,造成细节信息的丢失。
4.目前比较流行的图像降噪算法中基于卷积字典学习的方法,用卷积运算代替信号表示中的矩阵乘法,使用多个滤波器和相应特征图的卷积总和对整张图像进行分解,克服了基于块的缺点。现有的卷积字典学习方法大多没有严格遵循字典学习的图像表示模型,使用手工先验,训练得到的通用字典细微结构表达能力有限,去噪效果逊于深度学习的方法且应用领域局限在自然图像上。
技术实现要素:
5.本发明的发明目的在于提供一种低剂量ct图像降噪方法及装置,能够有效提高低剂量ct图像降噪处理效果。
6.基于同一发明构思,本发明具有两个独立的技术方案:
7.1、一种低剂量ct图像降噪方法,包括如下步骤:
8.步骤1:对图像数据集进行预处理;
9.步骤2:初始化卷积稀疏图x和卷积字典d;
10.步骤3:通过超参数预测模块产生每次迭代参数;基于所述迭代参数,迭代更新卷积稀疏图x和卷积字典d,直至获得预训练模型;
11.步骤4:选取低剂量ct图像数据集,对图像数据集进行预处理,基于所述预训练模
型在低剂量ct图像数据集上训练,直至获得降噪模型;
12.步骤5:基于所述降噪模型,对低剂量ct图像进行降噪处理。
13.进一步地,步骤2中,通过初始化模块获得初始化卷积稀疏图x,所述初始化模块由不同卷积层的拼接和级联组成,输入带噪声图像和噪声标准差至所述初始化模块,获得初始化卷积稀疏图x。
14.进一步地,步骤3中,超参数预测模块由两个卷积层和两个激活函数组成,输入噪声标准差至所述超参数预测模块,并将其和超参数预测模块末端的输出相乘,以获得更新卷积稀疏图x和卷积字典d所需的迭代参数。
15.进一步地,步骤3中,卷积字典d的求解网络由4个卷积层、relu激活函数和多尺度inception模块组成。
16.进一步地,步骤3中,卷积稀疏图x的求解网络以密集旁路连接下的u-net结构为基础,相邻两层之间设有残差模块,每个残差模块包括多个残差单元。
17.进一步地,步骤3中,引入x'和d'作为辅助变量,迭代更新卷积稀疏图x和卷积字典d;在第t次迭代中,输入的含噪图像y同前一次迭代后的卷积稀疏图x(t-1)、卷积字典d(t-1)和本次迭代的超参数α
x(t)
,经辅助变量x'求解模块求解获得x'(t),x'(t)再与超参数β
x(t)
拼接,并用卷积稀疏图求解网络得出该次迭代后的卷积稀疏图x(t);
18.含噪图像y、超参数α
d(t)
、前一次迭代后的卷积字典d(t-1)和该次迭代后的卷积稀疏图x(t),经辅助变量d'求解模块求解获得d'(t),d'(t)与超参数β
d(t)
拼接并用卷积字典求解网络得出该次迭代后的d(t),d(t)与x(t)逐层卷积并求和以重构出该次迭代后的图像y(t);
19.所述超参数α
x(t)
、β
x(t)
、α
d(t)
、β
d(t)
均通过超参数预测模块获得。
20.进一步地,辅助变量x'求解模块与辅助变量d'求解模块分别基于快速傅里叶变换和最小二乘法,以求获得相应的闭合解。
21.进一步地,步骤3中,每次迭代的损失函数由l1损失和ms-ssim损失组成,两者比例的取值范围为[0,1];第一次迭代的损失函数权重记为1,其余t-1次迭代的损失函数权重记为反向传播时使用所有t次迭代的损失函数总和。
[0022]
进一步地,步骤4中,基于预训练模型在低剂量ct图像数据集上训练,根据网络收敛情况调节初始学习率、学习率衰减时的迭代次数阈值和学习率衰减比例。
[0023]
2、一种低剂量ct图像降噪装置,用于执行上述方法。
[0024]
本发明具有的有益效果:
[0025]
本发明低剂量ct图像降噪方法基于迁移学习思想,其包括如下步骤:对图像数据集进行裁剪、旋转和镜像等预处理操作;初始化卷积稀疏图x和卷积字典d;通过超参数预测模块产生每次迭代参数;基于所述迭代参数,迭代更新卷积稀疏图x和卷积字典d,直至获得预训练模型;选取低剂量ct图像数据集,基于所述预训练模型在低剂量ct图像数据集上训练,直至获得降噪模型;基于所述降噪模型,对低剂量ct图像进行降噪处理。本发明提出一种基于卷积字典学习和神经网络的低剂量ct图像降噪方法,将卷积字典学习可解释性强的优点和神经网络强大特征提取能力的优势有效结合,有助于在去除噪声的同时保护图像边缘细节信息,克服了基于分块的传统字典学习信息冗余的问题和现有基于卷积字典学习理
论的降噪方法由于使用手工先验和通用字典难以在降噪效果上媲美深度学习方法的缺点,同时也弥补了卷积神经网络进行低剂量ct图像降噪时需要大量ct数据集且容易造成图像过度平滑和细节信息丢失的不足,很好的完成了对噪声类型复杂并伴有伪影的低剂量ct图像降噪任务。本发明先在带噪声的自然图像上训练网络以获得最好的降噪模型,再使用有限的低剂量ct数据集在预训练获得的模型上继续训练,让模型能够完成低剂量ct图像的降噪任务,有效提高低剂量ct图像降噪模型建立效率。
[0026]
本发明超参数预测模块由两个卷积层和两个激活函数组成,输入噪声标准差至所述超参数预测模块,并将其和超参数预测模块末端的输出相乘,以获得更新卷积稀疏图x和卷积字典d所需的迭代参数;卷积字典d的求解网络由4个卷积层、relu激活函数和多尺度inception模块组成;卷积稀疏图x的求解网络以密集旁路连接下的u-net结构为基础,相邻两层之间设有残差模块,每个残差模块包括多个残差单元;引入x'和d'作为辅助变量,迭代更新卷积稀疏图x和卷积字典d;在第t次迭代中,输入的含噪图像y同前一次迭代后的卷积稀疏图x(t-1)、卷积字典d(t-1)和超参数α
x(t)
,经辅助变量x'求解模块求解获得x'(t),x'(t)再与超参数β
x(t)
拼接,并用卷积稀疏图求解网络得出该次迭代后的卷积稀疏图x(t);含噪图像y、超参数α
d(t)
、前一次迭代后的卷积字典d(t-1)和该次迭代后的卷积稀疏图x(t),经辅助变量d'求解模块求解获得d'(t),d'(t)与超参数β
d(t)
拼接并用卷积字典求解网络得出该次迭代后的d(t),d(t)与x(t)逐层卷积并求和,以重构出该次迭代后的图像y(t);所述超参数α
x(t)
、β
x(t)
、α
d(t)
、β
d(t)
均通过超参数预测模块获得;辅助变量x'求解模块与辅助变量d'求解模块分别基于快速傅里叶变换和最小二乘法,以求获得相应的闭合解。本发明通过超参数预测模块、卷积字典d的求解网络、卷积稀疏图x的求解网络以及引入x'和d'作为辅助变量的具体设置,进一步保证低剂量ct图像降噪模型的可靠性,保证在去除噪声的同时保护图像边缘细节信息。
附图说明
[0027]
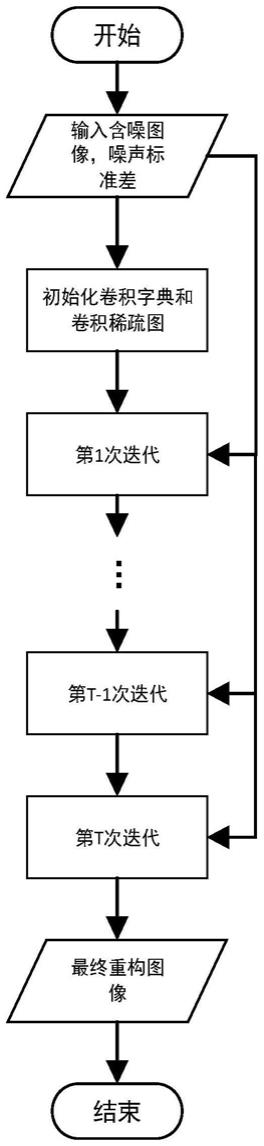
图1是本发明低剂量ct图像降噪方法的流程示意图;
[0028]
图2是本发明每次迭代时卷积字典和卷积稀疏图学习更新的示意图;
[0029]
图3是本发明超参数预测模块示意图;
[0030]
图4是本发明卷积稀疏图x初始化模块示意图;
[0031]
图5是本发明卷积稀疏图x求解网络示意图;
[0032]
图6是本发明卷积字典d求解网络示意图;
[0033]
图7是本发明卷积稀疏图x求解网络中的残差模块示意图;
[0034]
图8是本发明卷积字典d求解网络的多尺度inception模块示意图。
具体实施方式
[0035]
下面结合附图所示的各实施方式对本发明进行详细说明,但应当说明的是,这些实施方式并非对本发明的限制,本领域普通技术人员根据这些实施方式所作的功能、方法、或者结构上的等效变换或替代,均属于本发明的保护范围之内。
[0036]
实施例一:
[0037]
低剂量ct图像降噪方法
[0038]
本发明低剂量ct图像降噪方法欲在图像域内对低剂量ct图像进行降噪,结合卷积字典学习的可解释性和神经网络强大的特征提取能力,将低剂量ct图像的降噪过程拆分为预训练阶段和模型微调阶段。本发明先对易获取的自然图像数据集添加一定标准差范围的高斯噪声,在带噪声的自然图像上训练网络以获得最好的降噪模型,再使用有限的低剂量ct数据集在预训练获得的模型上继续训练,让模型能够完成低剂量ct图像的降噪任务。如图1所示,本发明低剂量ct图像降噪方法包括如下步骤:
[0039]
步骤1:对图像数据集进行预处理。
[0040]
假设原始数据集的图像大小为a
×
a,对其随机添加[0,α]的高斯噪声,并在带噪声图像上随机裁剪若干a
×
a大小的区域作为训练图像,结合旋转、镜像等数据增强操作以增大数据集。
[0041]
步骤2:初始化卷积稀疏图x和卷积字典d。
[0042]
如图4所示,通过初始化模块获得初始化卷积稀疏图x,所述初始化模块由不同卷积层的拼接和级联组成,输入带噪声图像和噪声标准差至所述初始化模块,获得初始化卷积稀疏图x。输入是噪声标准差σ经repeat操作并与噪声图像y拼接的结果。由于是对整张图进行表示,而在输入和输出层之间包含更短的连接,卷积网络能训练更深的结构,能提取更高维的特征来降噪。具体实施时,将含噪图像和相应的噪声标注差σ输入到卷积稀疏图初始化模块,初始化m通道大小为a
×
a的卷积稀疏图x。相应的卷积字典也定为m通道并用全0初始化,每通道的卷积字典原子大小远小于卷积稀疏图。其中m为卷积稀疏图的初始化通道数,同时也是卷积字典原子的数量,卷积字典原子尺寸取值范围为[3,7](比如,128
×
128大小的稀疏系数图可选择数量为64且大小为5
×
5的卷积字典原子)。
[0043]
步骤3:通过超参数预测模块产生每次迭代参数;基于所述迭代参数,迭代更新卷积稀疏图x和卷积字典d,直至获得预训练模型。
[0044]
如图3所示,超参数预测模块由两个卷积层和两个激活函数组成,超参数预测模块的输入和模块末端的输出相乘作为最终的预测结果。本实施例中,超参数预测网络使用sigmoid和softplus作为激活函数,以确保所有超参数都是正值。输入噪声标准差σ至所述超参数预测模块,获得更新卷积稀疏图x和卷积字典d所需的迭代参数α
x(t)
、α
d(t)
、β
x(t)
和β
d(t)
。
[0045]
如图6、图8所示,卷积字典d的求解网络由4个卷积层、relu激活函数和多尺度inception模块组成。卷积字典的字典原子可取5
×
5大小,浅层的网络就能提供足够的感受野,为通过多个尺度同时提取低维和高维特征,在卷积字典d求解网络的尾部添加多尺度模块。多尺度模块使用1
×
1卷积核降低特征通道数以减少参数量,用两个3
×
3卷积代替5
×
5卷积核在达到相同作用的同时继续减少参数量,经拼接操作融合多个尺度上提取的特征后,使用1
×
1卷积核进行降维。。卷积核初始化权重的实现方式为:随机初始化、高斯初始化等。批量归一化层的批量大小可根据模型收敛情况判定调节。激活函数可采用sigmoid函数,relu函数,leaky relu函数,softplus等函数中的一种。
[0046]
如图5、图7所示,卷积稀疏图x的求解网络以密集旁路下的u-net结构为基础,相邻两层之间设有残差模块,每个残差模块包括多个残差单元。比如,128
×
128的图像,结合实际感受野占理论感受野的比重,每个残差模块包含4个残差单元。为防止图像经过下采样丢失过大的信息,卷积稀疏图x求解网络采用卷积下采样操作而不是传统的池化下采样,同样
在上采样时使用卷积上采样。卷积稀疏图x求解网络的输入经包含n组k
×
k卷积核的残差模块,会产生n个大小为a
×
a的特征图,再经过卷积下采样操作,特征图大小减半,继续经包含2n组k
×
k卷积核的残差模块,会产生新的2n个大小为a/2
×
a/2的特征图,以此类推,到达网络的卷积上采样部分时特征图大小加倍,与卷积上采样相邻的残差模块中卷积核通道数逐层减半,网络最后一个卷积上采样操作衔接包含m组k
×
k卷积核的残差模块,输出学习更新后的m通道大小为a
×
a的卷积稀疏图。网络设计中的密集旁路连接部分是采用跨层连接方式连接两个有一定间隔的特征层,间隔的大小和旁路连接的个数可根据模型降噪情况判定调节。其中m为卷积稀疏图的输入和输出通道数;n为卷积层的卷积核数量,k
×
k为卷积核大小,m、n和k都可根据模型收敛情况灵活选取。
[0047]
如图2所示,引入x'和d'作为辅助变量,迭代更新卷积稀疏图x和卷积字典d;在第t次迭代中,输入的含噪图像y同前一次迭代后的卷积稀疏图x(t-1)、卷积字典d(t-1)和本次迭代的超参数α
x(t)
,经辅助变量x'求解模块求解获得x'(t),x'(t)再与超参数β
x(t)
拼接,并用卷积稀疏图求解网络得出该次迭代后的卷积稀疏图x(t);含噪图像y、超参数α
d(t)
、前一次迭代后的卷积字典d(t-1)和该次迭代后的卷积稀疏图x(t),经辅助变量d'求解模块求解获得d'(t),d'(t)与超参数β
d(t)
拼接并用卷积字典求解网络得出该次迭代后的d(t),d(t)与x(t)逐层卷积并求和以重构出该次迭代后的图像y(t);所述超参数α
x(t)
、β
x(t)
、α
d(t)
、β
d(t)
均通过超参数预测模块获得。辅助变量x'求解模块与辅助变量d'求解模块分别基于快速傅里叶变换和最小二乘法,以求获得相应的闭合解。
[0048]
每次迭代的损失函数由l1损失和ms-ssim损失组成,两者比例的取值范围为[0,1];第一次迭代的损失函数权重记为1,其余t-1次迭代的损失函数权重记为反向传播时使用所有t次迭代的损失函数总和,在模型稳定后保存预训练模型。本实施例中,使用的复合损失采用0.85倍的l1损失和0.15倍的ms-ssim损失。
[0049]
l1误差函数和ms-ssim损失函数:
[0050][0051][0052][0053][0054]
其中p为所处理图像p上的像素索引,为图像p的中心像素,n为p上的像素点数量,x(p)和y(p)是预测图像和标签图像的像素值,μ
x
和μy表示图像的平均值,σ
x
和σy表示图像的标注差,σ
xy
表示图像间的协方差,m为金字塔阶数,α和βj通常设为1。
[0055]
步骤4:选取低剂量ct图像数据集,基于所述预训练模型在低剂量ct图像数据集上训练,直至获得降噪模型。
[0056]
模型微调阶段可使用mayo数据集中的正常剂量ct图作为标签,噪声图像为数据集中的模拟四分之一剂量ct图像。假设输入的低剂量ct图像大小为b
×
b,随机裁剪若干a
×a大小的区域作为训练图像,结合旋转、镜像等数据增强操作以增大数据集。
[0057]
调整学习率,用迁移学习的方式微调预训练模型。此时的噪声标准差σ通过相应的正常剂量ct图像和低剂量ct图像作差计算得到。选取合适的学习率,在预训练模型的基础上继续训练,基于预训练模型在低剂量ct图像数据集上训练,根据网络收敛情况调节初始学习率、学习率时衰减的迭代次数阈值和学习率衰减比例,以求稳定模型的同时缩短训练时间并克服低剂量ct图像有限的问题。观察验证集的降噪结果和损失函数变化,在模型达到最优时保存最终的降噪模型。
[0058]
预训练和模型微调阶段的初始学习率及训练次数可根据网络的收敛情况判定调节,按照线性缩放规则,当批量大小batch_size增加为原来的n倍时,学习率应该增加为原来的n倍(比如batch_size=4时,预训练的学习率可初始化取值范围为[4e-5
,8e-5
],模型微调阶段的学习率可初始化取值范围为[1e-6
,2e-6
],训练次数初始化取值范围分别为[20,30]epoch和[10,20]epoch,也可根据验证集指标手动停止训练)。
[0059]
网络参数更新的实现方式为:随机梯度下降算法(sgd算法)、adam算法等,训练过程中,可根据网络的收敛情况和测试结果不断调节学习率、卷积核数量、卷积核大小,权重、网络层数等其中的一种或多种。
[0060]
步骤5:基于所述降噪模型,对低剂量ct图像进行降噪处理。
[0061]
测试时,假设测试图像大小为b
×
b,由于测试图像不再裁剪,卷积字典d的正则化强度需相应调整,即α
d(t)
缩放b/a倍。将测试图像依次输入到网络中,获得各自卷积字典和卷积稀疏图,输出降噪后的ct图像。
[0062]
实施例二:
[0063]
低剂量ct图像降噪装置
[0064]
所述低剂量ct图像降噪装置用于执行上述的低剂量ct图像降噪方法。
[0065]
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
[0066]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1