一种根据图文信息自动生成小视频的方法与流程
1.本发明属于图文信息处理技术领域,具体涉及一种根据图文信息自动生成小视频的方法。
背景技术:
2.近年来,随着计算机视觉领域的飞速发展和生成对抗网络的提出,图像生成的研究受到了越来越广泛的关注,其在素材积累,数据集自动生成方面有非常积极的意义。视频相比于图像它更加生动,生成难度也更大,因此对于视频生成方面的探索更加有研究意义。
3.现阶段将图文信息生成小视频没有系统化的流程,操作过程十分繁琐,缺乏智能化的处理方法。如今随着小视频的流行,用户的阅读倾向逐渐从图文信息转化为观看小视频。因此迫切需要一种根据图文信息自动生成小视频的方法。
技术实现要素:
4.本发明的目的在于提供一种根据图文信息自动生成小视频的方法,解决现有图文信息生成小视频操作繁琐、智能化程度低的问题。
5.本发明采用的技术方案如下:
6.一种根据图文信息自动生成小视频的方法,包括以下步骤:
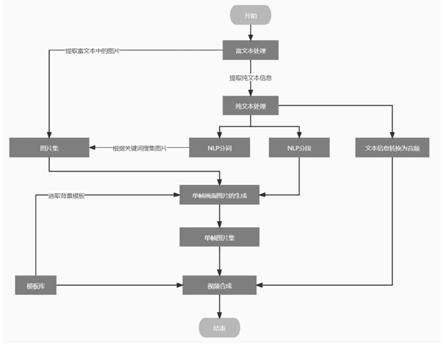
7.(1)进行富文本处理,提取富文本中的图片并添加到图片集,提取纯文本信息;
8.(2)对纯文本信息进行处理,处理过程具体包括对以下步骤:
9.(2.1)对纯文本信息进行nlp分词处理,提取纯文本信息中的人名、地名关键词,用于检索图片中的对应图片资源;
10.(2.2)对纯文本信息进行nlp分段处理,将纯文本信息中段落较长的部分再次分段并进行缩句处理;
11.(2.3)对纯文本信息进行音频转换处理,将纯文本信息的语句转换为音频信息并写入到音频文件;
12.(3)根据nlp分词处理提取的关键词,对图片集进行搜索提取与关键词匹配的图片;
13.(4)将步骤(3)中提取的图片与nlp分段处理后的一段或多段纯文本信息进行组合,搭配预设的背景模板生成一张指定分辨率的图片,合成单帧画面图片;
14.(5)根据纯文本信息的段落顺序依次合成若干单帧画面图片,并根据纯文本信息的段落顺序进行排序,形成有序的单帧图片集;
15.(6)指定单帧图片集中每张单帧画面图片的显示时长,然后将单帧图片集与步骤(2.3)中的音频文件结合动画模板及背景音乐,合成视频文件。
16.进一步地,所述步骤(2.3)中纯文本信息通过ai语音识别转成音频文件。
17.进一步地,所述步骤(6)中,背景音乐为纯音乐或歌曲。
18.进一步地,所述图片集的图片包括富文本中提取的图片和图片素材数据库中的图
片。
19.进一步地,所述富文本中提取的图片和图片素材数据库中的图片均通过图片内容进行关键词定义,关键词内容包括图片人物姓名、图片所处地点、图片物体名称。
20.综上所述,由于采用了上述技术方案,本发明的有益效果是:
21.1、本发明中,通过系统化的提取富文本中的图片和纯文本信息,并对纯文本信息进行nlp分词处理、nlp分段处理、音频转换处理,再基于文本关键词搜索图片集的图片,将图片集的图片与纯文本信息处理后的一段或多段文字进行组合再搭配背景模板后生成一张指定分辨率的图片,最终形成相同分辨率的有序的单帧图片集,再结合音频文件最终生成小视频,有效提升了图文信息生成小视频的处理效率,且智能化、自动化程度高,有效解决了现有图文信息生成小视频操作繁琐、智能化程度低的问题。
附图说明
22.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图,其中:
23.图1为本发明的流程示意图。
具体实施方式
24.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
25.因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.一种根据图文信息自动生成小视频的方法,包括以下步骤:
27.(1)进行富文本处理,提取富文本中的图片并添加到图片集,提取纯文本信息;
28.(2)对纯文本信息进行处理,处理过程具体包括对以下步骤:
29.(2.1)对纯文本信息进行nlp分词处理,提取纯文本信息中的人名、地名关键词,用于检索图片中的对应图片资源;
30.(2.2)对纯文本信息进行nlp分段处理,将纯文本信息中段落较长的部分再次分段并进行缩句处理;
31.(2.3)对纯文本信息进行音频转换处理,将纯文本信息的语句转换为音频信息并写入到音频文件;
32.(3)根据nlp分词处理提取的关键词,对图片集进行搜索提取与关键词匹配的图片;
33.(4)将步骤(3)中提取的图片与nlp分段处理后的一段或多段纯文本信息进行组
合,搭配预设的背景模板生成一张指定分辨率的图片,合成单帧画面图片;
34.(5)根据纯文本信息的段落顺序依次合成若干单帧画面图片,并根据纯文本信息的段落顺序进行排序,形成有序的单帧图片集;
35.(6)指定单帧图片集中每张单帧画面图片的显示时长,然后将单帧图片集与步骤(2.3)中的音频文件结合动画模板及背景音乐,合成视频文件。
36.进一步地,所述步骤(2.3)中纯文本信息通过ai语音识别转成音频文件。
37.进一步地,所述步骤(6)中,背景音乐为纯音乐或歌曲。
38.进一步地,所述图片集的图片包括富文本中提取的图片和图片素材数据库中的图片。
39.进一步地,所述富文本中提取的图片和图片素材数据库中的图片均通过图片内容进行关键词定义,关键词内容包括图片人物姓名、图片所处地点、图片物体名称。
40.本发明在实施过程中,通过系统化的提取富文本中的图片和纯文本信息,并对纯文本信息进行nlp分词处理、nlp分段处理、音频转换处理,再基于文本关键词搜索图片集的图片,将图片集的图片与纯文本信息处理后的一段或多段文字进行组合再搭配背景模板后生成一张指定分辨率的图片,最终形成相同分辨率的有序的单帧图片集,再结合音频文件最终生成小视频,有效提升了图文信息生成小视频的处理效率,且智能化、自动化程度高,有效解决了现有图文信息生成小视频操作繁琐、智能化程度低的问题。
41.实施例1
42.一种根据图文信息自动生成小视频的方法,包括以下步骤:
43.(1)进行富文本处理,提取富文本中的图片并添加到图片集,提取纯文本信息;
44.(2)对纯文本信息进行处理,处理过程具体包括对以下步骤:
45.(2.1)对纯文本信息进行nlp分词处理,提取纯文本信息中的人名、地名关键词,用于检索图片中的对应图片资源;
46.(2.2)对纯文本信息进行nlp分段处理,将纯文本信息中段落较长的部分再次分段并进行缩句处理;
47.(2.3)对纯文本信息进行音频转换处理,将纯文本信息的语句转换为音频信息并写入到音频文件;
48.(3)根据nlp分词处理提取的关键词,对图片集进行搜索提取与关键词匹配的图片;
49.(4)将步骤(3)中提取的图片与nlp分段处理后的一段或多段纯文本信息进行组合,搭配预设的背景模板生成一张指定分辨率的图片,合成单帧画面图片;
50.(5)根据纯文本信息的段落顺序依次合成若干单帧画面图片,并根据纯文本信息的段落顺序进行排序,形成有序的单帧图片集;
51.(6)指定单帧图片集中每张单帧画面图片的显示时长,然后将单帧图片集与步骤(2.3)中的音频文件结合动画模板及背景音乐,合成视频文件。
52.实施例2
53.在实施例1的基础上,所述步骤(2.3)中纯文本信息通过ai语音识别转成音频文件。
54.实施例3
55.在上述实施例的基础上,所述步骤(6)中,背景音乐为纯音乐或歌曲。
56.实施例4
57.在上述实施例的基础上,所述图片集的图片包括富文本中提取的图片和图片素材数据库中的图片。
58.实施例5
59.在上述实施例的基础上,所述富文本中提取的图片和图片素材数据库中的图片均通过图片内容进行关键词定义,关键词内容包括图片人物姓名、图片所处地点、图片物体名称。
60.如上所述即为本发明的实施例。前文所述为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明的验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1