一种无人机充电柜的用户识别方法、装置及充电柜与流程
1.本发明涉及无人机智能充电技术领域,尤其涉及一种无人机充电柜的用户识别方法、装置及充电柜。
背景技术:
2.目前,无人机已经广泛应用于多个领域,电力线路的巡检是无人机重要的应用领域之一,一片区域内需要多个无人机进行巡检,随着无人机的增多,使其管理难度越来越大,因此,无人机充电柜应运而生,例如,专利文献cn214303105u公开了一种智能管理的无人机库房,无人机库房主体内设置有机身储存柜和锂电池充电柜,机身储存柜设置有多个单独的机身隔间,机身隔间均设置有柜门,柜门上设置有电子标签阅读器和智能门锁;锂电池充电柜设置有多个锂电池插槽,锂电池插槽底部设置有充放电接口,充放电接口与充放电管理电路电连接,充放电管理电路对锂电池进行充放电。为了避免无关人员闯入,同时实时检测操作人员的工作,库房主体入口门处设置有智能门禁开关和视频探头,机身储存柜和锂电池充电柜顶部均设置有视频探头,智能门禁开关与视频探头分别与中央控制器信号连接。智能门禁开关可使用类似人脸识别或者指纹密码开启的门禁开关,对操作人员进行识别。而视频探头则对进入库房内的操作人员监控录像并反馈给中央控制器。然而仅通过人脸识别或者指纹密码开启的门禁开关,安全性差。
技术实现要素:
3.本发明提供了一种无人机充电柜的用户识别方法、装置及充电柜,能够有效提高无人机充电柜的安全性。
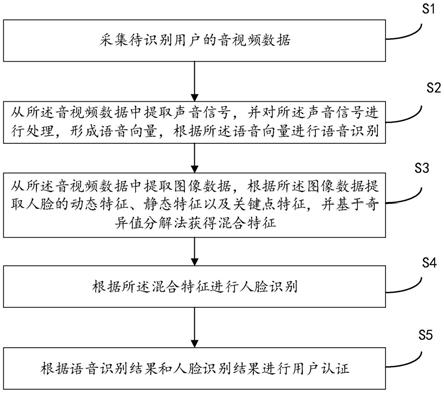
4.一种无人机充电柜的用户识别方法,包括:
5.采集待识别用户的音视频数据;
6.从所述音视频数据中提取声音信号,并对所述声音信号进行处理,形成语音向量,根据所述语音向量进行语音识别;
7.从所述音视频数据中提取图像数据,根据所述图像数据提取人脸的动态特征、静态特征以及关键点特征,并基于奇异值分解法获得混合特征;
8.根据所述混合特征进行人脸识别;
9.根据语音识别结果和人脸识别结果进行用户认证。
10.进一步地,对所述声音信号进行处理,形成语音向量,包括:
11.将所述声音信号分成多个帧并进行离散傅里叶变换,提取频谱信息;
12.根据所述频谱信息,计算mel倒谱系数;
13.根据所述mel倒谱系数进行离散余弦变换,获得所述语音向量。
14.进一步地,根据所述图像数据提取人脸的动态特征和静态特征,包括:
15.利用相邻矩形像素组之间的对比度值,从所述图像数据中提取haar-like特征;
16.将每个haar-like特征区域的像素强度进行相加,并计算各个haar-like特征区域
像素强度和之间的差值;
17.根据预先训练获得的分类器,利用像素强度和之间的差值进行特征分类,获得嘴唇的动态特征、眼睛的静态特征和鼻子的静态特征。
18.进一步地,根据所述图像数据提取人脸的关键点特征,包括:
19.利用高斯函数的差分识别所述图像数据中的尺度和方向不变的点,获得关键点;
20.以所述关键点为圆心,周围预设范围内的像素进行梯度计算,建立直方图,根据直方图为关键点分配方向;
21.为每个关键点建立关于位置、尺度和方向的描述符,获得所述关键点特征。
22.进一步地,基于奇异值分解法获得混合特征,包括:
23.将所述动态特征、静态特征以及关键点特征进行矩阵表达;
24.将动态特征矩阵和静态特征矩阵作为左奇异特征矩阵,将关键点特征矩阵作为右奇异特征矩阵,计算获得混合特征矩阵。
25.进一步地,根据所述语音向量进行语音识别,包括:
26.将所述语音向量与预先建立的注册用户语音模型进行比对,判断所述语音向量与所述注册用户语音模型的相似度是否超过语音识别阈值。
27.进一步地,根据所述混合特征进行人脸识别,包括:
28.将所述混合特征与预先建立的注册用户人脸模型进行比对,判断所述混合特征与所述注册用户人脸模型的相似度是否超过面部识别阈值。
29.进一步地,根据语音识别结果和人脸识别结果进行用户认证,包括:
30.当所述语音向量与所述注册用户语音模型的相似度超过语音识别阈值,且所述混合特征与所述注册用户人脸模型的相似度超过面部识别阈值时,确定所述待识别用户为注册用户。
31.一种无人机充电柜的用户识别装置,包括:
32.采集模块,用于采集待识别用户的音视频数据;
33.语音识别模块,用于从所述音视频数据中提取声音信号,并对所述声音信号进行处理,形成语音向量,根据所述语音向量进行语音识别;
34.图像特征提取模块,用于从所述音视频数据中提取图像数据,根据所述图像数据提取人脸的动态特征、静态特征以及关键点特征,并基于奇异值分解法获得混合特征;
35.识别模块,用于根据所述混合特征进行人脸识别;
36.认证模块,用于根据语音识别结果和人脸识别结果进行用户认证。
37.一种充电柜,包括处理器和存储装置,所述存储装置存储有多条指令,所述处理器用于读取所述指令并执行:
38.采集待识别用户的音视频数据;
39.从所述音视频数据中提取声音信号,并对所述声音信号进行处理,形成语音向量,根据所述语音向量进行语音识别;
40.从所述音视频数据中提取图像数据,根据所述图像数据提取人脸的动态特征、静态特征以及关键点特征,并基于奇异值分解法获得混合特征;
41.根据所述混合特征进行人脸识别;
42.根据语音识别结果和人脸识别结果进行用户认证。
43.本发明提供的无人机充电柜的用户识别方法、装置及充电柜,至少包括如下有益效果:
44.(1)基于语音和面部特征多模态生物特征识别技术进行用户身份认证,具有较高的识别率和鲁棒性,智能验证用户身份,大幅度缩短识别时间、提高识别的准确性、降低算法的复杂度;
45.(2)通过静态特征、动态特征以及关键点特征的提取和融合,基于奇异值分解法获得混合特征进行面部识别,能够有效降低混合特征的向量的维数,提高识别效率。
附图说明
46.图1为本发明提供的无人机充电柜的用户识别方法一种实施例的流程图。
47.图2为本发明提供的无人机充电柜的用户识别方法中特征识别一种实施例的流程图。
48.图3为本发明提供的无人机充电柜的用户识别装置一种实施例的结构示意图。
49.图4为本发明提供的充电柜一种实施例的结构示意图。
具体实施方式
50.为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案做详细的说明。
51.参考图1,在一些实施例中,提供一种无人机充电柜的用户识别方法,包括:
52.s1、采集待识别用户的音视频数据;
53.s2、从所述音视频数据中提取声音信号,并对所述声音信号进行处理,形成语音向量,根据所述语音向量进行语音识别;
54.s3、从所述音视频数据中提取图像数据,根据所述图像数据提取人脸的动态特征、静态特征以及关键点特征,并基于奇异值分解法获得混合特征;
55.s4、根据所述混合特征进行人脸识别;
56.s5、根据语音识别结果和人脸识别结果进行用户认证。
57.具体地,步骤s1中,可以通过在无人机充电柜设置视频装置,获取待识别用户的音视频数据。
58.进一步地,步骤s2中,对所述声音信号进行处理,形成语音向量,包括:
59.s21、将所述声音信号分成多个帧并进行离散傅里叶变换,提取频谱信息;
60.s22、根据所述频谱信息,计算mel倒谱系数;
61.s23、根据所述mel倒谱系数进行离散余弦变换,获得所述语音向量。
62.本实施例中,通过mfcc(mel-frequency cepstral coefficients)提取语音向量。
63.步骤s21中,将声音信号分为多个帧,从而将其分析为短时间段,利用傅里叶变换提取离散频带的频谱信息,傅里叶变换将信号从时域转换到频域,为mel频率弯折做准备。
64.进一步地,步骤s22中,对于给定频率,mel倒谱系数通过以下公式进行计算:
[0065][0066]
其中,f是实际频率,mf为mel倒谱系数。
[0067]
步骤s3中,根据所述mel倒谱系数进行离散余弦变换,经过离散余弦变换之后,所有系数的集合即为语音向量,用于语音识别。
[0068]
进一步地,参考图2,步骤s3中,根据所述图像数据提取人脸的动态特征和静态特征,包括:
[0069]
s31、利用相邻矩形像素组之间的对比度值,从所述图像数据中提取haar-like特征;
[0070]
s32、将每个haar-like特征区域的像素强度进行相加,并计算各个haar-like特征区域像素强度和之间的差值;
[0071]
s33、根据预先训练获得的分类器,利用像素强度和之间的差值进行特征分类,获得嘴唇的动态特征、眼睛的静态特征和鼻子的静态特征。
[0072]
本实施例中,采用viola
–
jones进行面部识别,首先利用相邻矩形像素组之间的对比度值,从所述图像数据中提取haar-like特征,像素组间的对比度差异用于确定人脸检测目标的明暗区域,将每个haar-like特征区域的像素强度进行相加,并计算各个haar-like特征区域像素强度和之间的差值,人脸图像中眼睛区域比脸颊区域更暗,根据预先训练获得的分类器,利用像素强度和之间的差值进行特征分类,获得嘴唇的动态特征、眼睛的静态特征和鼻子的静态特征。
[0073]
进一步地,参考图2,步骤s3中,根据所述图像数据提取人脸的关键点特征,包括:
[0074]
s34、利用高斯函数的差分识别所述图像数据中的尺度和方向不变的点,获得关键点;
[0075]
s35、以所述关键点为圆心,周围预设范围内的像素进行梯度计算,建立直方图,根据直方图为关键点分配方向;
[0076]
s36、为每个关键点建立关于位置、尺度和方向的描述符,获得所述关键点特征。
[0077]
本实施例中,采用尺度不变特征变换(sift)进行特征提取,利用高斯函数的差分识别所述图像数据中的尺度和方向不变的点,获得关键像素点,对关键像素点进行定位,只保留稳定、显著的特征,以所述关键点为圆心,周围预设范围内的像素进行梯度计算,建立直方图,根据直方图为关键点分配方向,具体地,构建具有36个跨过360个区间的直方图,直方图中的最高峰值和大于80%的峰值被视为方向分配,将具有16个邻域的关键点分成16个子块,大小为4
×
4。每个子块生成8个方向直方图,得到128个关键点特征向量。
[0078]
进一步地,步骤s3中,基于奇异值分解法获得混合特征,包括:
[0079]
s37、将所述动态特征、静态特征以及关键点特征进行矩阵表达;
[0080]
s38、将动态特征矩阵和静态特征矩阵作为左奇异特征矩阵,将关键点特征矩阵作为右奇异特征矩阵,计算获得混合特征矩阵。
[0081]
具体地,计算公式如下所示:
[0082][0083]
其中,an×
p
为n
×
p的混合特征矩阵,un×n为左奇异特征矩阵,sn×
p
为奇异值矩阵,为右奇异特征矩阵。
[0084]
混合特征结合了viola
–
jones提取的嘴唇的动态特征、眼睛的静态特征、鼻子的静态特征,以及sift算法提取的关键点特征。奇异值分解(svd)法作为融合方法用于所有特征
的综合,从而使识别系统更加准确,奇异值分解可降低混合特征的维数并生成一个紧凑的特征向量。
[0085]
进一步地,步骤s2中,根据所述语音向量进行语音识别,包括:
[0086]
将所述语音向量与预先建立的注册用户语音模型进行比对,判断所述语音向量与所述注册用户语音模型的相似度是否超过语音识别阈值。
[0087]
进一步地,步骤s4中,根据所述混合特征进行人脸识别,包括:
[0088]
将所述混合特征与预先建立的注册用户人脸模型进行比对,判断所述混合特征与所述注册用户人脸模型的相似度是否超过面部识别阈值。
[0089]
进一步地,步骤s5中,根据语音识别结果和人脸识别结果进行用户认证,包括:
[0090]
当所述语音向量与所述注册用户语音模型的相似度超过语音识别阈值,且所述混合特征与所述注册用户人脸模型的相似度超过面部识别阈值时,确定所述待识别用户为注册用户。
[0091]
即当人脸和语音都匹配时,确认用户为注册用户,进一步提高智能柜的安全性。
[0092]
进一步地,用户注册时,预先采集的注册用户音视频数据,建立基于语音和面部特征多模态生物特征识别模型,根据所述注册用户语音、人脸图像对所述多模态生物特征识别模型进行训练,获得注册用户人脸模型和注册用户语音模型。将多个注册用户人脸模型和注册用户语音模型进行存储,形成注册用户人脸模型和注册用户语音模型模型库。
[0093]
上述实施例提供的方法,至少包括如下有益效果:
[0094]
(1)基于语音和面部特征多模态生物特征识别技术进行用户身份认证,具有较高的识别率和鲁棒性,智能验证用户身份,大幅度缩短识别时间、提高识别的准确性、降低算法的复杂度;
[0095]
(2)通过静态特征、动态特征以及关键点特征的提取和融合,基于奇异值分解法获得混合特征进行面部识别,能够有效降低混合特征的向量的维数,提高识别效率。
[0096]
参考图3,在一些实施例中,提供一种无人机充电柜的用户识别装置,包括:
[0097]
采集模块201,用于采集待识别用户的音视频数据;
[0098]
语音识别模块202,用于从所述音视频数据中提取声音信号,并对所述声音信号进行处理,形成语音向量,根据所述语音向量进行语音识别;
[0099]
图像特征提取模块203,用于从所述音视频数据中提取图像数据,根据所述图像数据提取人脸的动态特征、静态特征以及关键点特征,并基于奇异值分解法获得混合特征;
[0100]
识别模块204,用于根据所述混合特征进行人脸识别;
[0101]
认证模块205,用于根据语音识别结果和人脸识别结果进行用户认证。
[0102]
进一步地,语音识别模块202还用于将所述声音信号分成多个帧并进行离散傅里叶变换,提取频谱信息;根据所述频谱信息,计算mel倒谱系数;根据所述mel倒谱系数进行离散余弦变换,获得所述语音向量。
[0103]
图像特征提取模块203还用于利用相邻矩形像素组之间的对比度值,从所述图像数据中提取haar-like特征;将每个haar-like特征区域的像素强度进行相加,并计算各个haar-like特征区域像素强度和之间的差值;根据预先训练获得的分类器,利用像素强度和之间的差值进行特征分类,获得嘴唇的动态特征、眼睛的静态特征和鼻子的静态特征。
[0104]
进一步地,图像特征提取模块203还用于利用高斯函数的差分识别所述图像数据
中的尺度和方向不变的点,获得关键点;以所述关键点为圆心,周围预设范围内的像素进行梯度计算,建立直方图,根据直方图为关键点分配方向;为每个关键点建立关于位置、尺度和方向的描述符,获得所述关键点特征。
[0105]
进一步地,图像特征提取模块203还用于将所述动态特征、静态特征以及关键点特征进行矩阵表达;将动态特征矩阵和静态特征矩阵作为左奇异特征矩阵,将关键点特征矩阵作为右奇异特征矩阵,计算获得混合特征矩阵。
[0106]
进一步地,语音识别模块202还用于将所述语音向量与预先建立的注册用户语音模型进行比对,判断所述语音向量与所述注册用户语音模型的相似度是否超过语音识别阈值。
[0107]
进一步地,识别模块204还用于将所述混合特征与预先建立的注册用户人脸模型进行比对,判断所述混合特征与所述注册用户人脸模型的相似度是否超过面部识别阈值。
[0108]
认证模块205还用于当所述语音向量与所述注册用户语音模型的相似度超过语音识别阈值,且所述混合特征与所述注册用户人脸模型的相似度超过面部识别阈值时,确定所述待识别用户为注册用户。
[0109]
上述实施例提供的装置,至少包括如下有益效果:
[0110]
(1)基于语音和面部特征多模态生物特征识别技术进行用户身份认证,具有较高的识别率和鲁棒性,智能验证用户身份,大幅度缩短识别时间、提高识别的准确性、降低算法的复杂度;
[0111]
(2)通过静态特征、动态特征以及关键点特征的提取和融合,基于奇异值分解法获得混合特征进行面部识别,能够有效降低混合特征的向量的维数,提高识别效率。
[0112]
参考图4,在一些实施例中,还提供一种充电柜,包括处理器301和存储装置302,存储装置302存储有多条指令,处理器301用于读取所述指令并执行:
[0113]
采集待识别用户的音视频数据;
[0114]
从所述音视频数据中提取声音信号,并对所述声音信号进行处理,形成语音向量,根据所述语音向量进行语音识别;
[0115]
从所述音视频数据中提取图像数据,根据所述图像数据提取人脸的动态特征、静态特征以及关键点特征,并基于奇异值分解法获得混合特征;
[0116]
根据所述混合特征进行人脸识别;
[0117]
根据语音识别结果和人脸识别结果进行用户认证。
[0118]
此外,所述充电柜还包括视频采集装置303,用于拍摄获取待识别用户的音视频数据。
[0119]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1