一种会话场景信息抽取方法与流程
1.本发明涉及信息人工智能技术领域,尤其涉及一种会话场景信息抽取方法。
背景技术:
2.在会话场景中,会话文本中包含着很多信息,其中用户的个人基础信息、个人特征信息对于构建用户画像,从而推动业务进行极为重要。
3.但大多数营销会话场景下,信息干扰比较多、口语话严重,例如,会话中会出现许多人名,其中只有一个或者都不是客户的信息,或是问方提出问题,但客户表示否认,怎么区分哪些信息是用户本人的,哪些不是,哪些问题是客户确认的,哪些不是,这些都是自动抽取用户信息的关键。
4.针对这一问题,我们急需解决的是如何通过上下文去对非用户信息进行筛选,以达到明确信息的问题。
技术实现要素:
5.基于背景技术中提出的会话文本中干扰信息较多的技术问题,本发明提出了一种会话场景信息抽取方法。
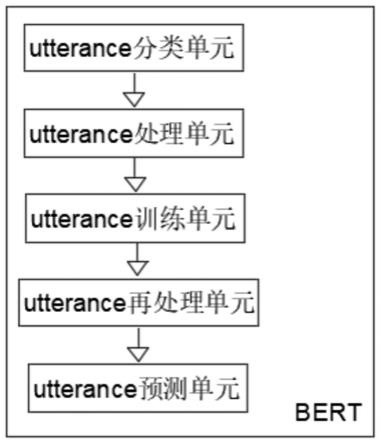
6.本发明提出的一种会话场景信息抽取方法,包括bert,所述bert包括utterance分类单元、utterance处理单元、utterance训练单元、utterance再处理单元和utterance预测单元,所述utterance分类单元是用于对问答双方的utterances进行分类以及信息类别匹配,所述utterance处理单元是加入适当标记并捕获语义编码,同时将窗口数据格式化,所述utterance训练单元是通过编码分类utterances,并加以数据计算获取信息并识别,所述utterance再处理单元是用于获取新编码,并对其进行二次分类,所述utterance预测单元是用于将对话中即将出现的信息进行预测处理。
7.优选地,所述utterance分类单元中,具体包括以下步骤:
8.s11:问答方标注分类:一般来说,用户信息出现一般来自于两种方式,一种来自于客服的询问,用户回答,另一种来自于用户主动表达,并规定对于问答式的信息采用qa方式标注,用户信息询问的utterance问题标为q_type,所询问的utterance问题的所有回答标注为pa_typei和na_typei;
9.s12:信息分类:将用户信息归为姓名、职位、公司名、联系地址、邮寄地址、电话、性别、年龄类多种信息种类;
10.s13:回答识别:识别s11中标注的回答方信息,并归类用于后续信息识别;
11.s14:utterance信息类别匹配:将回答的信息中的所有信息按照s12中的分类分别做识别归类;
12.所述问答方标注分类中的type表示用户信息的种类,当姓名为qname,地址为qaddress,i则表示该种类问答的次序,pa_type代表肯定回答,na_type代表否定回答,而对于用户主动表述的信息,则规定标为sa_type,含义同上。
13.优选地,所述utterance处理单元中,具体包括以下步骤:
14.s21:符号处理:对标注数据进行的utterance经过去掉emoji表情、特殊符号的预处理手段;
15.s22:加入标记:为了统一问答式的信息表述和主动表述的形式,则对输入加入特殊标记“[emptyq]”,并规定该标记的token type和客服的token type一致,当用户是主动的信息表述,则将该标记和sa_type构成完整的qa形式;
[0016]
s23:二次加入标记:加入[spkear0]、[spkear1]标记来表示对话角色信息;
[0017]
s24:语义编码捕获:利用标记来捕获对应utterance的语义编码;
[0018]
s25:窗口数据格式化:此时窗口数据将被格式化为:
[0019][0020]
表示第j个utterance的第k个token;
[0021]
所述二次加入标记中,[spkear0]、[spkear1]分别对应客服和用户。
[0022]
优选地,所述utterance训练单元中,具体包括以下步骤:
[0023]
s31:编码取出分类:训练时,取出所有[speak]的编码接ffn做多分类,用作判断对应的utterance;
[0024]
s32:类别缓解:考虑到出现类别不均衡,将采用logit指数压缩结合corssentropyloss的办法缓解;
[0025]
s33:数据计算:推断时则直接判断ffn的输出,考虑到首尾两句可能缺乏足够的信息判断,计算loss的时候忽略第二第三个[speak]和后两个[speak]的损失,只计算中间五个[speak]的损失,预测是同样只关心中间五个[speak]的输出,取值最大的索引作为该utterance作为相应信息类别的q;
[0026]
s34:信息识别获取:为了输出具体信息,基于本次输出的token编码结合crf做实体识别任务,这样可获得相应utterance的实体信息;
[0027]
所述utterance再处理单元中,具体包括以下步骤:
[0028]
s41:信息注入:采用condition normalization将该utterance的信息注入到utterance训练单元中输出的token编码以获得根据信息类别编码信息的新token编码;
[0029]
s42:二次分类:对各个[speak]接ffn进行二次分类,判断是否是utterance训练单元中输出问题的答案;
[0030]
s43:二次类别缓解:考虑到出现类别不均衡,将再次采用logit指数压缩结合corssentropyloss的办法缓解;
[0031]
所述utterance再处理单元中,具体包括以下步骤:
[0032]
s51:新会话切分:预测时,将新的会话按照utterance分类单元的方式进行切分;
[0033]
s52:实体信息获取:然后分别重复utterance处理单元和utterance训练单元的步骤拿到信息类别的q以及各个utterance的实体信息;
[0034]
s53:答案分析:再经过utterance再处理单元的步骤拿到每段的问题以及对应的答案,在没有答案或者答案是否定的情况下则该问答对的实体不作为返回,反之则返回。
[0035]
本发明中的有益效果为:
[0036]
1、该一种会话场景信息抽取方法,通过以抽取模型bert为基础,提出一种基于上
下文理解由粗到细的用户信息抽取方法,首先从utterance级别去理解上下文语义,确定哪些utterance是表述用户信息,再从这些可能的utterance中获取具体的用户信息,例如用户的姓名、地址、职位、公司名等等,使该网络架构能在理解上下文的基础上从utterance语义上缩小信息抽取的范围,从粗到细、粗细结合的方法保证了抽取信息的准确性,该方法在会话场景中具有很好的效果。
[0037]
2、该一种会话场景信息抽取方法,通过此方法的整个信息处理流程为end2end的结构方式,以一个流畅的流程瞬间处理好所有的数据,具有落地部署的复杂度小,维护迭代成本低的优势。
[0038]
3、该一种会话场景信息抽取方法,通过在自标数据上,utterance seq-f1的数值为0.912,在最后抽取信息的准确率上为0.893,达到了工业运用标准,保证了信息抽取方法的质量,也提高了该方法的基础水平。
[0039]
该方法中未涉及部分均与现有技术相同或可采用现有技术加以实现。
附图说明
[0040]
图1为本发明提出的一种会话场景信息抽取方法的信息抽取模型bert的结构图;
[0041]
图2为本发明提出的一种会话场景信息抽取方法的utterance分类单元的流程图;
[0042]
图3为本发明提出的一种会话场景信息抽取方法的utterance处理单元的流程图;
[0043]
图4为本发明提出的一种会话场景信息抽取方法的utterance训练单元的流程图;
[0044]
图5为本发明提出的一种会话场景信息抽取方法的utterance再处理单元的流程图;
[0045]
图6为本发明提出的一种会话场景信息抽取方法的utterance预测单元的流程图;
[0046]
图7为本发明提出的一种会话场景信息抽取方法的实例会话的分类标号图;
[0047]
图8为本发明提出的一种会话场景信息抽取方法的实例会话处理的流程图。
具体实施方式
[0048]
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
[0049]
下面详细描述本专利的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本专利,而不能理解为对本专利的限制。
[0050]
参照图1,一种会话场景信息抽取方法,包括bert,bert包括utterance分类单元、utterance处理单元、utterance训练单元、utterance再处理单元和utterance预测单元,utterance分类单元是用于对问答双方的utterances进行分类以及信息类别匹配,utterance处理单元是加入适当标记并捕获语义编码,同时将窗口数据格式化,utterance训练单元是通过编码分类utterances,并加以数据计算获取信息并识别,utterance再处理单元是用于获取新编码,并对其进行二次分类,utterance预测单元是用于将对话中即将出现的信息进行预测处理,通过以抽取模型bert为基础,结合utterance的判别和实体识别联合任务,使该网络架构能在理解上下文的基础上从utterance语义上缩小信息抽取的范围,从粗到细、粗细结合的方法保证了抽取信息的准确性。
[0051]
参照图2、图3、图4、图5、图6、图7、图8,本发明中,utterance分类单元中,具体包括
以下步骤:
[0052]
s11:问答方标注分类:一般来说,用户信息出现一般来自于两种方式,一种来自于客服的询问,用户回答,另一种来自于用户主动表达,并规定对于问答式的信息采用qa方式标注,用户信息询问的utterance问题标为q_type,所询问的utterance问题的所有回答标注为pa_typei和na_typei;
[0053]
s12:信息分类:将用户信息归为姓名、职位、公司名、联系地址、邮寄地址、电话、性别、年龄类多种信息种类;
[0054]
s13:回答识别:识别s11中标注的回答方信息,并归类用于后续信息识别;
[0055]
s14:utterance信息类别匹配:将回答的信息中的所有信息按照s12中的分类分别做识别归类;
[0056]
问答方标注分类中的type表示用户信息的种类,当姓名为qname,地址为qaddress,i则表示该种类问答的次序,pa_type代表肯定回答,na_type代表否定回答,而对于用户主动表述的信息,则规定标为sa_type,含义同上。
[0057]
参照图3、图4、图5、图6、图7、图8,本发明中,utterance处理单元中,具体包括以下步骤:
[0058]
s21:符号处理:对标注数据进行的utterance经过去掉emoji表情、特殊符号的预处理手段;
[0059]
s22:加入标记:为了统一问答式的信息表述和主动表述的形式,则对输入加入特殊标记“[emptyq]”,并规定该标记的token type和客服的token type一致,当用户是主动的信息表述,则将该标记和sa_type构成完整的qa形式;
[0060]
s23:二次加入标记:加入[spkear0]、[spkear1]标记来表示对话角色信息;
[0061]
s24:语义编码捕获:利用标记来捕获对应utterance的语义编码;
[0062]
s25:窗口数据格式化:此时窗口数据将被格式化为:
[0063][0064]
表示第j个utterance的第k个token;
[0065]
二次加入标记中,[spkear0]、[spkear1]分别对应客服和用户。
[0066]
参照图2、图3、图4、图5、图6、图7、图8,本发明中,utterance训练单元中,具体包括以下步骤:
[0067]
s31:编码取出分类:训练时,取出所有[speak]的编码接ffn做多分类,用作判断对应的utterance;
[0068]
s32:类别缓解:考虑到出现类别不均衡,将采用logit指数压缩结合corssentropyloss的办法缓解;
[0069]
s33:数据计算:推断时则直接判断ffn的输出,考虑到首尾两句可能缺乏足够的信息判断,计算loss的时候忽略第二第三个[speak]和后两个[speak]的损失,只计算中间五个[speak]的损失,预测是同样只关心中间五个[speak]的输出,取值最大的索引作为该utterance作为相应信息类别的q;
[0070]
s34:信息识别获取:为了输出具体信息,基于本次输出的token编码结合crf做实体识别任务,这样可获得相应utterance的实体信息;
[0071]
utterance再处理单元中,具体包括以下步骤:
[0072]
s41:信息注入:采用condition normalization将该utterance的信息注入到utterance训练单元中输出的token编码以获得根据信息类别编码信息的新token编码;
[0073]
s42:二次分类:对各个[speak]接ffn进行二次分类,判断是否是utterance训练单元中输出问题的答案;
[0074]
s43:二次类别缓解:考虑到出现类别不均衡,将再次采用logit指数压缩结合corssentropyloss的办法缓解;
[0075]
utterance再处理单元中,具体包括以下步骤:
[0076]
s51:新会话切分:预测时,将新的会话按照utterance分类单元的方式进行切分;
[0077]
s52:实体信息获取:然后分别重复utterance处理单元和utterance训练单元的步骤拿到信息类别的q以及各个utterance的实体信息;
[0078]
s53:答案分析:再经过utterance再处理单元的步骤拿到每段的问题以及对应的答案,在没有答案或者答案是否定的情况下则该问答对的实体不作为返回,反之则返回,此方法的整个信息处理流程为end2end的结构方式,以一个流畅的流程瞬间处理好所有的数据,具有落地部署的复杂度小,维护迭代成本低的优势,且在自标数据上,utterance seq-f1的数值为0.912,在最后抽取信息的准确率上为0.893,达到了工业运用标准,保证了信息抽取方法的质量,也提高了该方法的基础水平。
[0079]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1