一种基于自适应遗传算法改进后的水库优化调度方法与流程
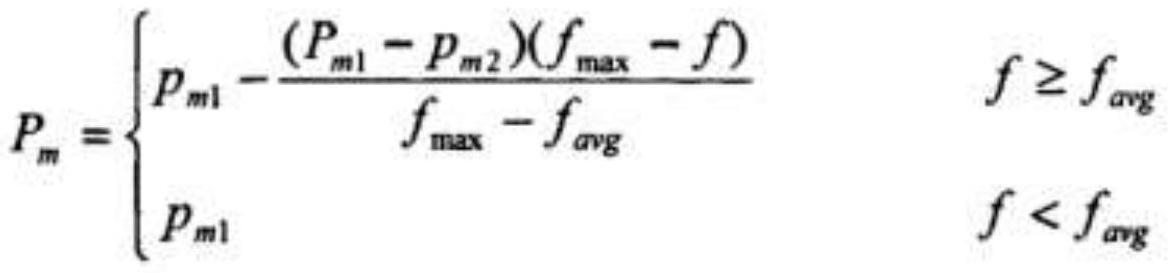
1.本发明属于水库调度技术,尤其涉及一种基于自适应遗传算法改进后的水库优化调度方法。
背景技术:
2.水库调度的优化算法目前主要又常规优化算法和智能优化算法。
3.常规的优化算法存在作“维数灾”、收敛性差、计算速度慢等局限性;因此,目前在国内外很少使用常规的优化算法。
4.随着现在人工智能不断兴起,利用神经网络和遗传算法进行优化调度的研究越来越多;神经网络的进行水库优化调度算法建立模型比较复杂,因此在利用遗传算法进行水库的优化调度成为当前比较主流的算法。
5.但简单遗传算法主要存在两个问题:一是算法的收敛数据太慢;二是容易产生早熟现象。简单遗传算的局部搜索能力不强,影响算法搜索性能的因素主要包括初始种群、编码方式、遗传算子和控制参数等方面。针对控制参数(种群大小、交叉概率、变异概率)在进化过程中不变的情况,现有学者提出自适应遗传算法解决,即:遗传算法运行初期,适应度相对较低的个体比较集中,若采用较小的交叉概率和变异概率,种群很难产出优秀新个体导致收敛速度慢。遗传算法后期,适应度相对较高的个体比较集中,倘若采用较大的交叉概率和变异概率,容易破坏优良个体,使算法陷入局部最优解。通过使交叉概率和变异概率随着遗传代数增加适应度值自动改变的自适应遗传算法。
6.针对编码方式改进主流思想是把二进制编码改为浮点数编码、格雷码等方式。针对水库优化调度中泄流方案与水库水位密切相关,有学者提出把水库允许最高水位和最大水位之间等分为n等份,得到n+1个离散的水位点(z1,z2,...,zn,z
n+1
),每个子区间表示一个下泄流量,用0或1构成长度为l的二进制串,形成了每个时段总长为n*l的染色体,m个时段的染色体总长为m*n*l。
7.通过实践发现,若需要调度的时段比较多,这样的编码方式会导致染色体很长,在计算过程中,导致以下四方面问题:
8.1)染色体长,资源消耗高:由于每个时段都对应一段染色体,导致染色体的长度很长;在计算过程中数据的读取会耗费较大的cpu、内存等计算资源。
9.2)染色体长,遗传收敛慢:由于染色体的长度过长,在进行遗传的过程中会导致交叉、变异后值变化较小,收敛数据慢。
10.3)编码固定,灵活性差:由于固定的编码方式,无法根据来水特征进行灵活的编码;导致常规来水也需进行大量的计算才能求解。
11.4)每时段随机,锯齿数多:由于每个时段都有划分水位区间,解码后相当于每个时段都是一个随机值;这样求解出来的解锯齿严重,没有较好去锯齿算法,导致不能满足调度中闸门开度不能太频繁更改原则。
技术实现要素:
12.本发明要解决的技术问题是:提供一种基于自适应遗传算法改进后的水库优化调度方法,以解决现有技术水库优化调度方法中存在的在计算过程中数据的读取会耗费较大的cpu、内存等计算资源;常规来水也需进行大量的计算才能求解;不能满足调度中闸门开度不能太频繁更改原则等技术问题。
13.本发明的技术方案是:
14.一种基于自适应遗传算法改进后的水库优化调度方法,它包括:
15.步骤1、计算无蓄水及调度情况下断面来水;
16.步骤2、划分下泄流量;
17.步骤3、识别来水涨、跌和平时段区间;
18.步骤4、以顺序对每个区间段进行编码;
19.步骤5、判断每个时段所在的时段区间,并获取到相应的染色体段进行解码,结合预报来水过程及起调水位开始优化,得到和泄流过程及水位变化过程;
20.步骤6、适应度函数计算;根据泄流过程计算每个个体的适应度;
21.步骤7、收敛性判断;
22.步骤8、遗传操作;
23.步骤9、控制参数;
24.步骤10、循环步骤5至步骤9,直到满足条件。
25.计算无蓄水及调度情况下断面来水的方法为:根据上一个断面来水,利用马斯京根计算需要控制断面的来水。
26.划分下泄流量的方法为:设置一个最小泄流的下限,当来水小于下限值,则全部作为平稳状态划分;设置下限的方法是:有断面一年以上的平均流量值则使用平均流量,没有则使用来水预报的平均值。
27.识别来水涨、跌和平时段区间的方法为:涨水段为设置泄流下限值或谷值到峰值的时段;跌水段为峰值到设置泄流下限值或谷值的时段;平稳段为小于等于设置的泄流下限值的时段。
28.以顺序对每个区间段进行编码的方法为:根据步骤3划分的时段区间依次顺序对每个区间段,将水库允许最低水位与允许最高水位之间等分成n份,得到n+1个离散的水位点,每个区间表示一个下泄流量,用0或1构成长度为l的字符串,n个子区间形成总长为n*l的一个染色体。
29.步骤5所述判断每个时段所在的时段区间,并获取到相应的染色体段进行解码,结合预报来水过程及起调水位开始优化,得到和泄流过程及水位变化过程的方法包括:
30.判断每个时段所在的时段区间,并获取到相应的染色体段;然后将染色体二进制转换成十进制,然后通过水库水位和下泄流量关系曲线查得每一个水位对应水位区间得最大下泄能力(q1max,q2max,q3max..qnmax),再根据解码公式,将十进制数转换成变量(q1,q2,q3,
…
qn);解码公式如下:
[0031][0032]
式中:x-十进制数:
[0033]
x
′‑
二进制数所对应的十进制数;
[0034]
a-x的下限值;
[0035]
b-x的上限值;
[0036]
m-二进制数的位数。
[0037]
结合预报来水过程及起调水位开始优化;第一时段,假设这一时段水库不下泄洪水,根据来水,计算出这一时段的末的水库蓄水量,根据水位库容关系曲线查出对应的水位;通过上述的解码过程,由此水位对应的水位区间;计算出下泄流量q(t)假,为平均流量,根据水量平衡公式重新计算水库的蓄水量v(t)假、查出对应水位z(t)假查q-v曲线得相应的q(t)查,假如q(t)假与q(t)查相等,假定正确,q(t)假与v(t)假作为下一时段的状态;假如不正确,则采用q(t)假、q(t)查平均值为新q(t)假重新计算;依次对后一时段进行相同的运算过程,得到和泄流过程及水位变化过程。
[0038]
步骤6所述适应度函数计算;根据泄流过程计算每个个体的适应度的方法为:利用“限幅滤波法”和“消抖滤波法”去掉泄流过程中的锯齿;重新利用水量平衡公式计算后求解;作为该染色体的对应的解,进而作为适应度计算的输入;根据设定的目标函数,包括最大削峰、最短成灾历时或超标水量最小,根据泄流过程计算每个个体的适应度。
[0039]
收敛性判断的方法为:
[0040]
步骤7.1、达到精度要求,即种群中有个体的解满足目标函数
[0041]
步骤7.2、连续几代最优个体适应度值差异很小且种群所有个体适应度值差异很小;
[0042]
步骤7.3、超过设置迭代次数;
[0043]
步骤7.5、超过设置计算时间。
[0044]
步骤8所述遗传操作包括:
[0045]
步骤8.1、选择:最优保存策略与比例选择结合;
[0046]
步骤8.2、单点交叉:在个体编码串中随机设置一个交叉点,然后在该点相互交换两个配对个体的部分染色体;
[0047]
步骤8.3、均匀变异:分别用符合某一范围内均匀分布的随机函数,以某一较小的概率来替换个体编码串中各个基因座上的原有基因值。
[0048]
控制参数的方法为:使选择、交叉、变异的概率设置和适应度值随遗传中变化的缩放,从而实现控制参数的自适应。
[0049]
本发明有益效果:
[0050]
本发明在水库优化调度过程中,同一个水位区间当处于平稳、涨水、跌水状态与希望泄流方案有所不同,因此本发明提出根据来水的涨、跌、平稳状态划分时段区间,一个时段区间用一个染色体编码表示其泄流方案,来实现缩短编码、减少泄流过程锯齿的目标。
[0051]
假设来水时段长为m,按现有普遍的编码方式,把水位设置n个区间,每个区间长度为l,染色体的总长度为:m*n*l;本文提出:只需要把来水划分为起涨前平稳时段、涨水时段、退水时段、退水后平稳时段m个区间,编码长度为:m*n*l;多峰来水过程同样按涨、跌、平来水特性划分时段区间再进行编码,由于来水过程的水文特性,m的值一定会小于m的值,这样的编码方式会大大缩短染色体长度。所以在计算过程中计算资源消耗变低、收敛速度变快、不同来水适应性变强;且由于在一段时间内水位在划分的同一区间,通过水量平衡的试算后的出流过程,锯齿数少、消除锯齿变得容易。
[0052]
解决了现有技术存在的水库优化调度方法中存在的在计算过程中数据的读取会耗费较大的cpu、内存等计算资源;常规来水也需进行大量的计算才能求解;不能满足调度中闸门开度不能太频繁更改原则等技术问题。
具体实施方式
[0053]
本发明针对现有技术的缺陷,提出针对编码方式进行改进。在调度过程中,同一个水位区间当处于平稳、涨水、跌水状态我们希望泄流方案有所不同,因此本发明提出根据来水的涨、跌、平稳状态划分时段区间,一个时段区间用一个染色体编码表示其泄流方案,来实现缩短编码、减少泄流过程锯齿的目标。
[0054]
本发明实现步骤总体与自适应遗传算法在水库优化调度中应用一致,具体步骤如下:
[0055]
步骤1:计算无蓄水、调度情况下断面来水
[0056]
根据上有个断面来水,利用马斯京根计算需要控制断面的来水。
[0057]
步骤2:设置划分下泄流量
[0058]
为了避免对一些常规来水进行涨、跌状态划分,本发明会设置一个最小泄流的下限,当来水小于本值,全部作为平稳状态划分。设置本值算法原则是:有断面的多年平均则使用多年平均流量,没有则使用来水预报的平均值。
[0059]
步骤3:识别来水涨、跌、平时段区间
[0060]
涨水段:设置泄流下限值或谷值到峰值的时段;
[0061]
跌水段:峰值到设置泄流下限值或谷值的时段;
[0062]
平稳段:小于等于设置的泄流下限值的时段;
[0063]
划分出每个时段区间结束的下标,比如把一个时段长为72的划分为4个时段区间,对应的时段下标为[10,16,34,72]。
[0064]
步骤4:编码
[0065]
根据步骤3划分的4个时段区间依次顺序对每个区间段,将水库允许最低水位(汛限水位)与允许最高水位(防洪高水位)之间等分成n份,得到n+1个离散的水位点,每个区间表示一个下泄流量,用0或1构成长度为l的字符串,n个子区间形成总长为n*l的一个染色体。例如某水库的汛限水位是106m,防洪高水位是110.5m,分为5份,z1=106、z2=106.9、z3=107.8、z4=108.7、z5=109.6、z6=110.5;长度为l=10,随机生成染色体编码:4*n*l,表示水库水位在上述5个水位区间分别对应的下泄流量(q1,q2,q3,q4,q5)。编码精度为:(umax-umin)/(pow(2,l)-1)。编码由长度有现有编码形式的72*m*l变为4*m*l,缩短了18倍。
[0066]
步骤5:解码
[0067]
判断每个时段所在的时段区间,并获取到相应的染色体段;然后将染色体二进制转换成十进制,然后通过水库水位和下泄流量关系曲线查得(z1,z2,z3,
…
zn)中每一个水位对应水位区间得最大下泄能力(q1max,q2max,q3max..qnmax),再根据解码公式,将十进制数转换成变量(q1,q2,q3,
…
qn)。解码公式如下:
[0068]
[0069]
式中:x-十进制数:
[0070]
x
′‑
二进制数所对应的十进制数:
[0071]
a-x的下限值;
[0072]
b-x的上限值:
[0073]
m-二进制数的位数。
[0074]
结合预报来水过程及起调水位(没提供则以水库的防汛限制水位起调)开始优化。第一时段,假设这一时段水库不下泄洪水,根据来水,计算出这一时段的末的水库蓄水量,根据水位库容关系曲线查出对应的水位。通过上述的解码过程,由此水位对应的水位区间;计算出下泄流量q(t)假,为平均流量,根据水量平衡公式重新计算水库的蓄水量v(t)假、查出对应水位z(t)假查q-v曲线得相应的q(t)查,假如q(t)假与q(t)查相等,假定正确,q(t)假与v(t)假作为下一时段的状态。假如不正确,采用q(t)假、q(t)查平均值为新q(t)假重新计算。依次对后一时段进行相同的运算过程,得到和泄流过程及水位变化过程。
[0075]
利用“限幅滤波法”和“消抖滤波法”去掉泄流过程中的锯齿;重新利用水量平衡公式计算后求解。作为该染色体的对应的解(下泄流量过程),进而作为适应度计算的输入。
[0076]
步骤6:适应度函数计算
[0077]
根据设定的目标函数(最大削峰、最短成灾历时、超标水量最小等),根据泄流过程计算每个个体的适应度。
[0078]
步骤7:收敛性判断
[0079]
1)达到精度要求,即种群中有个体的解满足目标函数
[0080]
2)连续几代最优个体适应度值差异很小且种群所有个体适应度值差异很小
[0081]
3)超过设置迭代次数
[0082]
4)超过设置计算时间
[0083]
步骤8:遗传操作
[0084]
1)选择:最优保存策略与比例选择结合。该过程首先找出适应度最大的个体不经过交叉和变异保存到下一代,然后将适应度进行归一化,求出相对是应对适应度值p`i,设置种群大小为n,个体的适应度值为fi,那么相对适应度值为p`i=fi/sum(fi)。且sum(p`i)=1。再将相对适度值相加,每个染色体的相对适度值按比例占据长短不一的一段距离,然后随机产生一个0.0-1.0之间的数据a,a落在哪个区间,所在区间的个体即被选中遗传到下一代;循环(n-1)次共被选出n个染色体遗传到下一代。
[0085]
2)单点交叉:在个体编码串中随机设置一个交叉点,然后在该点相互交换两个配对个体的部分染色体。操作过程是依次指定两个个体编码串中的每个基因座为变异点,对每一个变异点,随机生成一个0.0-1.0之间的数,跟变异概率pc比较,如果小于pc;进行交叉。自适应遗传算法交叉概率pc随着适应度大小变化。按以下公式进行自适应调整:
[0086][0087]
fmax:种群中最大的适应度值;
[0088]
favg:每代种群的平均适应度值;
[0089]
f`:要交叉的两个个体较大的适应度值;
[0090]
pc1=0.9pc2=0.6
[0091]
3)均匀变异:分别用符合某一范围内均匀分布的随机函数,以某一较小的概率来替换个体编码串中各个基因座上的原有基因值。操作过程是依次指定个体编码串中的每个基因座为变异点,对每一个变异点,随机生成一个0.0-1.0之间的数,跟变异概率pm比较,如果小于pm,则此基因座发生变异,即“0“、”1”互换。自适应遗传算法变异概率pm适应度大小变化。按以下公式进行自适应调整:
[0092][0093]
fmax:种群中最大的适应度值;
[0094]
favg:每代种群的平均适应度值;
[0095]
f:要变异个体的适应度值;
[0096]
pm1=0.1pm2=0.001
[0097]
步骤9:控制参数
[0098]
为了尽可能避免早熟现象和局部最优解和在收敛速度间做平衡。应对适应度进行”缩放法”。使选择、交叉、变异的概率设置和适应度值随遗传中变化的缩放,从而实现控制参数的自适应。即:个体间适应度差异较大时(初期),将缩放值设置比较小,这样与适应度平均值相接近的个体适应度呈”放”的趋势,与适应度平均值较远的适应度呈”缩”的趋势,保持了多样性,不至于过早出现早熟现象;个体差异不大时(后期),将缩放值设置比较大,样与适应度平均值相接近的个体适应度呈”放”到”缩”的趋势距离平均值近一些,适应度平均值较远的适应度呈”缩”到”放”的趋势距离平均值远一些。个体之间适应度差异加大,加快收敛速度。
[0099]
步骤10:循环步骤5到步骤9,知道满足条件结束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1