一种基于多特征融合生成对抗网络的股票收盘价预测方法
1.本发明属于股票预测技术领域,具体涉及一种基于多特征融合生成对抗网络的股票收盘价预测方法。
背景技术:
2.由于深度学习在数据方面具有强大的处理能力,所以在很多领域都取得了巨大的成功,而股市预测是金融领域最受欢迎和最有价值的领域之一。
3.中国专利cn 107239855a公开了一种基于lstm模型的股票预测方法和系统,采用了lstm模型构建股票预测模型适用于周期性强的数据和序列数据,解决长期依赖问题,比传统时间序列模型等更加灵活调参。基于机器学习方法方面,中国专利cn 109360097a公开了一种基于深度学习的股票预测方法,通过先利用复合神经网络中的卷积神经网络学习目标股票和关联股票的交易数据的特征,再将特征输入到复合神经网络中的长短期记忆网络进行处理,得到对股票涨跌的预测,提供了一种基于深度学习和群体智能的股票预测方法,可以准确地预测股票的涨跌。中国专利cn 112163951a公开了提供了一种结合投资者心理情绪与股市历史交易数据相结合的股票预测方法,从而有效缓解了lstm循环神经网络梯度爆炸梯度弥散的问题,进一步提高股市预测的准确性,中国专利cn 108074007a公开了涉及信息处理领域中的一种人工智能超深度学习的股票预测方法,可将所有与预测有关的因素,以及各种数学模型所产生的预测效果通过超深度学习构建成一个预测平台,并对预测结果进行多次的机器学习从而达到最佳化的预测,同时还可以进行自动的或人为的模糊参数的修正,在股票预测上具有突破性。中国专利cn 113129148a公开了一种融合生成对抗网络与二维注意力机制的股票预测方法,可以产生更为精准、更为理想的股票价格预测结果。
4.但由于股市的复杂性,上述专利仍然存在预测精度不高的问题,本专利提出了一种基于多特征融合生成对抗网络的股票收盘价预测模型。单一特征难以有效识别股市起伏的规律,采用多个特征将会造成特征冗余,信息源的增加会导致高维数据集信息爆炸问题,可以采用特征融合解决这一问题。特征融合的方法多,但是少有分析特征之间的关系,大都采用直接融合的方式,这将导致两个问题:
①
忽略了原始特征之间的联系。
②
容易造成维度爆炸。因此本专利使用了一种基于皮尔森相关性分析的pca特征融合方法,该方法将皮尔森相关性分析与pca相结合,其中,皮尔森相关性分析法注重特征之间的关联性,弥补了传统融合方法不考虑特征之间关联性的不足;pca实现了特征的降维,解决了维度爆炸的问题。即采用基于皮尔森相关性分析的pca特征融合方法,可以凝练特征,利用尽可能少的维度代表尽可能多的信息。
技术实现要素:
5.发明目的:本发明提出一种基于多特征融合生成对抗网络的股票收盘价预测方法,可以凝练特征,利用尽可能少的维度代表尽可能多的信息。
6.技术方案:本发明提出一种基于多特征融合生成对抗网络的股票收盘价预测方
法,具体包括以下步骤:
7.(1)预先获取股票数据,并对数据进行预处理;
8.(2)选取开盘价、成交量、最高价、最低价,以及由以上基础因素计算得来的相对强弱指数rsi、随机震荡指标kd、累积/派发线ad、真实波动幅度均值atr等多个特征作为数据源;
9.(3)选取n日为窗口滚动划分数据集,将得到的数据集为多特征数据源,收盘价的滚动数据集作为真实序列;
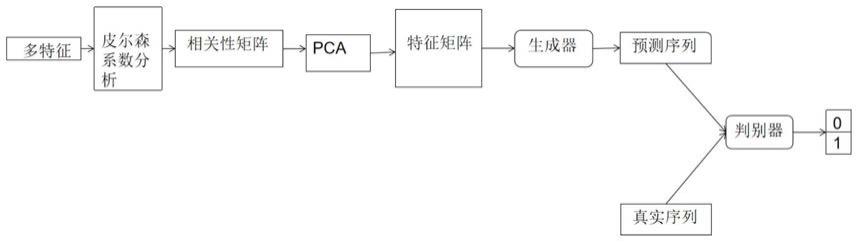
10.(4)构建包括生成器和判别器的生成对抗网络,其中生成器是由门控循环单元构成,用于生成股票数据;判别器由卷积神经网络构成,用于区分真假数据;
11.(5)从多特征数据源依次取出数据作为输入,先将其进行皮尔森相关性分析,得到相关性矩阵,然后将相关性矩阵利用pca进行数据降维,得到特征矩阵,最后将特征矩阵输入生成对抗网络进行训练;
12.(6)将真实的收盘价序列记为“真”,生成器生成的收盘价序列记为“假”,将“假”序列与“真”序列分别输入判别器,输出真伪的判断结果,根据判断结果进行反复训练,直至达到纳什均衡,训练结束。
13.进一步地,所述步骤(1)所述数据预处理为:对数据进行量纲处理,并按照8:2划分训练集测试集。
14.进一步地,步骤(4)所述卷积神经网络是由卷积层、池化层和全连接层构成,其中卷积层主要是通过共享权值来实现对特征的提取,其数学表达式为:
[0015][0016]
式中,σ为激活函数,c为偏置参数,l表示局部感受野的长,m表示局部感受野的宽,w
l,m
是权重参数,α
j+l,k+m
表示卷积层的输入数据。
[0017]
进一步地,步骤(4)所述生成器是由三层门控神经单元与三个全连接层组成,共计六层;第一层为1024个神经元,第二层为512个神经元,第三层为256个神经元,学习率为0.0006,并且每一层都设置dropout防止过拟合;接下来的三层全连接网络,输出维度分别设置为128、64、n,n*1的序列作为生成器的最终输出。
[0018]
进一步地,步骤(4)所述判别器是由两个卷积层与一个全连接层组成,卷积核与步长均为[2,2],激活函数为leakyrelu,学习率为0.0006,负数部分线性函数的梯度均为0.01,全连接层输出维度为1,激活函数为sigmoid。
[0019]
进一步地,步骤(5)所述皮尔森相关性分析实现过程如下:
[0020][0021]
其中,ρ(x,y)为皮尔森相关系数,cov为两个变量的协方差,分母为两个变量标准差的乘积;μx表示x的平均值,μy表示y的平均值,e为期望。
[0022]
进一步地,步骤(5)将相关性矩阵利用pca进行数据降维的实现过程如下:
[0023]
s1:计算矩阵x的样本的协方差矩阵s;
[0024]
s2:计算协方差矩阵s的特征向量e1,e2,
…
,ei特征值,t=1,2,
…
,i;
[0025]
s3:利用以下公式投影数据到特征向量的空间之中:
[0026][0027]
其中,bvi是原样本中第i个维度的值。
[0028]
有益效果:与现有技术相比,本发明的有益效果:本发明采用特征融解决单一特征难以有效识别股市起伏的规律,采用多个特征将会造成特征冗余,信息源的增加会导致高维数据集信息爆炸问题;本发明采用皮尔森相关性分析的pca特征融合方法,其中皮尔森相关性分析法注重特征之间的关联性,弥补了传统融合方法不考虑特征之间关联性的不足;pca实现了特征的降维,解决了维度爆炸的问题;即可以凝练特征,利用尽可能少的维度代表尽可能多的信息。
附图说明
[0029]
图1为本发明的流程图。
具体实施方式
[0030]
下面结合附图对本发明作进一步详细说明。
[0031]
本发明一种基于多特征融合生成对抗网络的股票收盘价预测方法,如图1所示,具体包括以下步骤:
[0032]
步骤1:获取中国平安银行的股票数据,共采集了2000年1月4日到2021年1月22日共5461个日股票数据,并对实验数据进行预处理。对数据进行量纲处理,即归一化;按照8:2划分训练集测试集。
[0033]
步骤2:选取开盘价、成交量、最高价、最低价,以及由以上基础因素计算得来的相对强弱指数rsi、随机震荡指标kd、累积/派发线ad、真实波动幅度均值atr等多个特征作为数据源。
[0034]
步骤3:选取n日为窗口滚动划分数据集,将得到的数据集为多特征数据源,收盘价的滚动数据集作为真实序列。
[0035]
步骤4:构建包括生成器和判别器的生成对抗网络,其中生成器是由门控循环单元构成,用于生成股票数据;判别器由卷积神经网络构成,用于区分真假数据。
[0036]
门控神经单元与lstm类似,但是门控神经单元比lstm少了输出门,它们仅由更新门和重置门组成。门控神经单元与lstm都能够捕获数据中的序列信息,但是由于门控神经单元由较少的参数组成,所以训练时间较短。经过许多学者验证,门控神经单元在小型数据集上比lstm表现更好。本发明涉及数据属于小型数据集,因此选用门控神经单元作为生成器。
[0037]
生成器是由三层门控神经单元与三个全连接层组成,共计六层。第一层为1024个神经元,第二层为512个神经元,第三层为256个神经元,学习率为0.0006,并且每一层都设置dropout防止过拟合。接下来的三层全连接网络,输出维度分别设置为128、64、n,n*1的序列作为生成器的最终输出。
[0038]
卷积神经网络主要借鉴于生物的神经系统,各个神经元之间局部连接,实现对输入特征的提取。卷积神经网络是由卷积层、池化层和全连接层构成。其中卷积层主要是通过
共享权值来实现对特征的提取,其数学表达式为:
[0039][0040]
式中σ为激活函数,c为偏置参数,l表示局部感受野的长,m表示局部感受野的宽,w
l,m
是权重参数,α
j+l,k+m
表示卷积层的输入数据。
[0041]
由于卷积神经网络在空间数据上运行良好,这一点对于时间序列数据也是适用的,故本发明选取卷积神经网络作为判别器。判别器是由两个卷积层与一个全连接层组成,卷积核与步长均为[2,2],激活函数为leakyrelu,学习率为0.0006,负数部分线性函数的梯度均为0.01,全连接层输出维度为1,激活函数为sigmoid。
[0042]
步骤5:从多特征数据源依次取出数据作为输入,先进行皮尔森相关性分析法分析,得到相关性矩阵,然后将相关性矩阵利用pca进行数据降维,得到特征矩阵,最后将特征矩阵输入生成对抗网络进行训练。
[0043]
皮尔森相关系数(pearson correlation coefficient),用来反映两个随机变量之间的线性相关程度。要理解皮尔森相关系数,首先要理解协方差(covariance)。协方差可以反映两个随机变量之间的关系,如果一个变量跟随着另一个变量一起变大或者变小,那么这两个变量的协方差就是正值,就表示这两个变量之间呈正相关关系,反之相反,公式如下。
[0044][0045]
如果协方差的值是个很大的正数,可以得到两个可能的结论:
[0046]
a)两个变量之间呈很强的正相关性;
[0047]
b)两个变量之间并没有很强的正相关性,协方差的值很大是因为x或y的标准差很大。
[0048]
协方差能体现两个随机变量之间的关系,但是却没法衡量变量之间相关性的强弱。因此,为了更好地度量两个随机变量之间的相关程度,引入了皮尔森相关系数。可以看到,皮尔森相关系数就是用协方差除以两个变量的标准差得到的:
[0049][0050]
其中,cov为两个变量的协方差,分母为两个变量标准差的乘积,μx表示x的平均值,μy表示y的平均值,e为期望。
[0051]
pca(principal components analysis)即主成分分析,也称主分量分析或主成分回归分析法,是一种无监督的数据降维方法。pca步骤如下:
[0052]
1)计算矩阵x的样本的协方差矩阵s;
[0053]
2)计算协方差矩阵s的特征向量e1,e2,
…
,ei特征值,t=1,2,
…
,i;
[0054]
3)利用以下公式投影数据到特征向量张成的空间之中:
[0055][0056]
其中,bvi值是原样本中对应维度的值。
[0057]
pca的目标是寻找r(r《n)个新变量,使它们反映事物的主要特征,压缩原有数据矩
阵的规模,将特征向量的维数降低,挑选出最少的维数来概括最重要特征。每个新变量是原有变量的线性组合,体现原有变量的综合效果,具有一定的实际含义。这r个新变量称为“主成分”,它们可以在很大程度上反映原来n个变量的影响,并且这些新变量是互不相关的,也是正交的。通过主成分分析,压缩数据空间,将多元数据的特征在低维空间里直观地表示出来。
[0058]
步骤6:将真实的收盘价序列记为“真”,生成器生成的收盘价序列记为“假”,将“假”序列与“真”序列分别输入判别器,输出真伪的判断结果,根据判断结果进行反复训练,直至达到纳什均衡,训练结束。
[0059]
本发明采用了python作为算法的实现语言,选取中国平安银行(股票代码为000001)的股票数据,该数据来自tushare财经数据接口工具包,其中采集了2000年1月4日到2021年1月22日共5461个日股票数据。具体模型参数设置如表1所示。
[0060]
表1模型参数设置
[0061]
参数设置步长[2,2]卷积核[2,2]学习率0.0006损失函数categorical_crossentropy生成器激活函数leakyrelu判别器激活函数sigmoid负数部分线性函数的梯度0.01
[0062]
本发明共设计3个对比试验,分别是gru、gan与多特征融合gan,从mae、rmse、r2-score三个评价指标进行比较,本发明明显具有更好的效果,能利用尽可能少的维度代表尽可能多的信息。
[0063]
上述实施方式只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1