一种基于企业需求的智能匹配招商策略系统及方法与流程
1.本发明涉及到智能招商技术领域,特别涉及一种基于企业需求的智能匹配招商策略系统及方法。
背景技术:
2.精准招商是提升区域经济核心竞争力、适应招商活动规律性的必然选择。如何改进我们的招商引资工作,实施精准招商,优化产业结构,是目前所要研究的重点。其中最重要的就是精准招商问题,如何对企业需求评估来获取企业需求匹配的产业、政策、区位、建筑结构化数据,通过这些数据来建立企业需求评分模型,再对企业需求特征状况进行分类和预测,这些是我们最关心的事情。
3.现实社会中,仍然存在很多因为绩效、信息不对称等因素的影响,导致各地盲目招商,不充分考虑招商的精准度与产业的契合度,最终造成招商企业不能带动当地经济的发展,甚至需要政府的扶持,阻碍了当地经济的发展。精准招商的核心内容是提高招商的针对性,避免招商活动的随意性,降低招商风险,使招进的企业更符合地方经济发展要求。
4.一篇申请号:201811058230.8的发明专利申请,公开了一种基于投资合作载体环境评价指数的企业选址系统,包括选址信息收集单元:用于引导用户录入期望地址信息,gis单元:用于生成推荐企业选址区域的地图,载体查询单元:用于提供推荐选址方案外的其他招商载体信息查询服务,选址单元:用于分析企业选址区域,产业集群分析评价数据库:用于存储产业集群分析评价指数,选址要素数据库:用于存储选址要素分值,企业基础信息数据库:用于按指定的划分区域存储企业的产业门类、企业类型、企业销售额和企业纳税额。其显著效果是:能够通过载体环境指数计算单元对投资、投技、投才、投智、投平台、投合作六种投资方式进行划分,分别设计集群评价模块和载体资源评价模块,如果投资方式为投资或投技,则通过集群评价模块计算产业集群评价指数,如果投资方式为投才、投智、投平台或投合作,则通过载体资源评价模块计算营商环境分析指数,对产业集群评价指数或营商环境分析指数进行排序,选出3个分数高的载体环境推荐各企业,企业选址的方案更加科学和准确。
5.但是,上述申请号:201811058230.8的发明专利申请,主要应用开源算法,算法逻辑相对单一,求规范决策时线性推导不易求出正理想和负理想解,从而无法实现快速精准获取企业匹配数据,难以高效搭建招商策略评分模型。
技术实现要素:
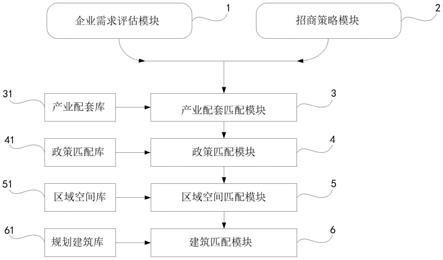
6.针对现有技术存在的问题,本发明提供了一种基于企业需求的智能匹配招商策略系统及方法,使用该智能匹配招商策略系统及方法后,在企业需求精准匹配数据的获取方面,基于bp神经网络优化改进lm-bp神经网络算法,并通过企业需求画像来匹配区域产业价值特征分析、匹配区域政策特征分析、匹配区域区位优势特征分析、匹配区域建筑适配特征分析,通过改进后的随机森林算法获取当地区域产业价值、政策、区位优势、建筑资源、政策
优势、区位优势、建筑优势各类模型、指标来搭建出更高效匹配的企业需求评分模型,利用丰富的算法逻辑能够更有效地计算企业需求评估,通过招商企业综合评价确保精准招商。
7.为解决上述技术问题,本发明采用的技术方案是:
8.提供一种基于企业需求的智能匹配招商策略系统,包括:企业需求评估模块、招商策略模块、产业配套匹配模块、政策匹配模块、区域空间匹配模块和建筑匹配模块;
9.所述企业需求评估模块,用以通过lm-bp神经网络对区域产业价值特征分析、政策特征分析、区位特征分析、建筑特征分析深度学习后,获取企业需求匹配的产业、政策、区位、建筑结构化数据;
10.所述招商策略模块,用以对企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,构建企业需求招商策略报告评分模型,建立基于随机森林改进的企业需求评分模型,对企业需求特征状况进行分类和预测;
11.所述产业配套匹配模块,用以通过产业配套库分析企业在所属各自细分产业中本地招商区域产业规模、产业链相关企业总数、规上企业数量、客户及供应商情况并提供企业产业集聚效应、供销关系效应参考值,从而匹配并选择适合企业的最优产业;
12.所述政策匹配模块,用以通过政策匹配库分析适配企业的政策,通过企业发展阶段创业期、成长期、成熟期适配的通用性政策、企业所有细分产业适配的产业类政策、培育企业前景的政策推荐,使得招商业务人员跟进企业的具体需求并在政策匹配模块中推荐标记,从而匹配并选择适合企业的最优政策;
13.所述区域空间匹配模块,用以通过匹配区域空间库的数据格式化后匹配企业需求量化评价打分并通过企业需求匹配宏观区位、中观区位、微观区位、用地规划、交通物流、生活配套进行适应性评价,从而匹配并选择适合企业的最优区域空间;
14.所述建筑匹配模块,用以通过匹配规划建筑库选择适合企业最优建筑载体,通过建筑基础信息、建筑结构、节能环保、防火防爆、配套设备、入住成本来对建筑载体做出适应性评价,从而匹配并选择适合企业的最优建筑规划。
15.本发明为了解决其技术问题,所采用的进一步技术方案是:
16.进一步地说,在所述企业需求评估模块中,所述企业需求匹配的产业结构化数据包括:产业规模、价值链客户市场、产业链配套和企业配套;所述企业需求匹配的政策结构化数据包括:产业政策、人才政策和金融政策;所述企业需求匹配的区位结构化数据包括:交通物流、配套资源和规划要素;所述企业需求匹配的建筑结构化数据包括:建筑基础要素、节能环保、荷载、防火防爆和使用成本。
17.进一步地说,步骤1所述lm-bp神经网络的具体计算步骤如下:
18.步骤1.1:初始化网络结构参数,误差允许值为ε,常数u和b,初始化权值和阈值向量,令k=0,u=u0,计算精度是ε和最大学习次m;
19.步骤1.2:将企业需求画像指标矩阵的训练数据作为输入向量输入到lm-bp神经网络中去;
20.步骤1.3:计算网络输出及误差指标函数e;
21.步骤1.4:计算雅各比矩阵j[w(k)];其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量;
[0022]
步骤1.5:计算δw;其中,δw为阈值改变量;
[0023]
步骤1.6:若e《ε,则转到步骤1.8,否则转到步骤1.5;
[0024]
步骤1.7:以新的权值和阀值向量w(k+1)来计算误差函数e,
[0025]
w(k+1)=w(k)-{j
t
[w(k)]j[w(k)]}-1
j[w(k)]e[w(k)]
[0026]
若e[w(k+1)]小于e[w(k)],则令k=k+1,u=u*b,转到步骤1.2,否则u=u/b,转到步骤1.5;其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量,w(k+1)表示新的第k+1次迭代的阀值和权值构成的向量;
[0027]
步骤1.8:lm-bp神经网络计算结束。
[0028]
进一步地说,在步骤1.1中,b的取值范围为:0《b《1,当k=0,u=u0时,计算精度ε和最大学习次m。
[0029]
进一步地说,在步骤1.4和步骤1.7中,通过雅各比矩阵j[w(k)]的变形,计算出j
t
(w),计算j
t
(w)的公式为:
[0030][0031]
进一步地说,步骤2所述建立基于随机森林改进的企业需求评分模型的步骤包括:
[0032]
步骤2.1:企业需求数据预处理;
[0033]
步骤2.2:计算企业需求矩阵;
[0034]
步骤2.3:数据加权抽样;
[0035]
步骤2.4:特征选择法选取企业需求最优需求特征子集;
[0036]
步骤2.5:算法参数优化;
[0037]
步骤2.6:产生评估结果。
[0038]
进一步地说,在步骤2.1中,所述企业需求数据预处理包括min-max标准化处理和z-score标准化处理;
[0039]
所述min-max标准化处理为通过对企业需求数据中的离线数据进行线性变换,使得所述企业需求数据在线性变换后的数据处于[0-1]之间;
[0040]
所述z-score标准化处理为将企业需求数据转换为均值为0且标准差为1的高斯分布。
[0041]
进一步地说,在步骤2.2中,所述计算企业需求矩阵的具体步骤为:设x={b1,b2,
……
,bl}表示由m个特征的l个样本组成的合集,y={y1,y2,
……
,yl}表示类别合集,则企业需求数据可以构建矩阵为:
[0042][0043]
其中矩阵l的大小为l(m+1),+1表示类别的集合,bi={xi1,xi2,
……
,xim}代表bi表样本的m个特征值,xij代表样本bi的第j个特征值;
[0044]
在企业需求矩阵l中,包括少数样本l
″
和多数样本l
′
,取少数样本l
″
中q个样本,构成的矩阵形式为:
[0045][0046]
少数样本l
″
中有q个样本,总样本为l个,则多数样本l
′
中有(l-q)个样本数,则其矩阵形式为:
[0047][0048]
进一步地说,在步骤2.3中,所述数据加权抽样的具体步骤包括:
[0049]
步骤2.3.1:将原始的企业需求数据分为训练集l和训练集l1;
[0050]
步骤2.3.2:将训练集l划分两个子集,分别为多数类样本l
′
和少数类样本l
″
;
[0051]
步骤2.3.3:采样过程中,先对多数类样本l
′
进行加权抽样,在多数类样本l
′
中挑出少数类样本l
″
大小相近的样本,计算挑出少数l
″
样本占比l
′
比重,并计算l
″
占所有l样本比重,然后对权重进行加权选取最后的训练样本;
[0052]
步骤2.3.4:重复步骤2.3.3多次,直到挑选到平衡样本;
[0053]
步骤2.3.5:挑出平衡样本进行划分,划分为训练集和测试集。
[0054]
进一步地说,在步骤2.4中,输入为原始企业需求数据集d={(x1,y1),(x2,y2),
……
,(xn,yn)},xi∈rm,且yn∈{-1,1};设定g1,g2;
[0055]
输出为最优特征子集f;
[0056]
所述特征选择法选取企业需求最优需求特征子集的具体选取步骤包括:
[0057]
步骤2.4.1:设定m个企业需求特征i=1,2,3,4,
…
,m;
[0058]
步骤2.4.2:利用以下公式计算每个企业需求特征相应的值;
[0059]
设定d为样本数据集,x,y为样本任意属性,n为数据集d中的类别数量,则x的信息熵为:
[0060][0061]
其中p(xi)为特性属性x取值为xi的概率;
[0062]
特征属性y给定的条件下特征属性x的条件熵为:
[0063][0064]
其中p(yi)为特性属性y取值为yj的概率,p(xi|yi)为特性属性y取值为yj的情况下,特性属性x取值为xi的概率;
[0065]
上述公式得到的信息熵为:
[0066]
gain(x、y)=info(x)-info(x|y)
[0067]
选择信息增益最大的特征作为数据集d的分裂属性,创建一个节点,使用该特征作为标记,对特征每个值创建分支,据此对样本的企业需求进行划分;
[0068]
步骤2.4.3:利用以下公式分别计算每个特征与类别变量yn的熵比较值un;
[0069]
步骤2.4.4:若un大于等于g1,则特征xn在选定的最优特征子集f中,即xn∈f;
[0070]
对特征进行排序,对集合f内选定的特征进行度量,确定特征xi及xj间相关值s;
[0071]
步骤2.4.5:当s小于等于g2,则跟进步骤(3)中信息熵比较值un大小对集合f中的特性进行删除;
[0072]
步骤2.4.6:得到最优特征子集。
[0073]
进一步地说,在步骤2.5中,所述算法参数优化的具体优化步骤包括:
[0074]
步骤2.5.1:设置需要优化参数搜索范围和步长;
[0075]
步骤2.5.2:根据步骤2.5.1进一步计算两个参数s和c的平均绝对误差值,利用平均绝对误差值得到两个参数s和c的个数具体范围;
[0076]
步骤2.5.3:根据步骤2.5.2中得到的参数s、c的取值范围,以s*c组合利用以下过程计算随机森林oob值,获取准确率;
[0077]
在对样本进行每次抽样训练时,未被抽到的样本数据,标记为集合oobi,将在未抽样的数据集oobi被错误的分类个数,标记为errornumoob,最后随机森林oob值的误差定义为:
[0078][0079]
即泛化误差为:
[0080][0081]
步骤2.5.4:根据oob值挑选s*c组合确定的最优参数,若随机森林oob值满足要求,
输出s*c组合,否则改变搜索范围及步长,继续搜索,直到满足最终条件。
[0082]
进一步地说,在步骤2.6中,所述基于随机森林改进的企业需求评分模型通过步骤2.1至步骤2.5产生最优评估结果,作为评估参考依据,提供给产业园区招商人员判断企业是否适配园区招商策略。
[0083]
还提供一种用于企业智能匹配招商策略系统的方法,包括如下步骤:
[0084]
s1:企业需求评估模块通过lm-bp神经网络对区域产业价值特征分析、政策特征分析、区位特征分析、建筑特征分析深度学习后,获取企业需求匹配的产业、政策、区位、建筑结构化数据;
[0085]
s2:招商策略模块对企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,构建企业需求招商策略报告评分模型,建立基于随机森林改进的企业需求评分模型,对企业需求特征状况进行分类和预测;
[0086]
s3:产业配套匹配模块通过产业配套库分析企业在所属各自细分产业中本地招商区域产业规模、产业链相关企业总数、规上企业数量、客户及供应商情况并提供企业产业集聚效应、供销关系效应参考值,从而匹配并选择适合企业的最优产业;
[0087]
s4:政策匹配模块通过政策匹配库分析适配企业的政策,通过企业发展阶段创业期、成长期、成熟期适配的通用性政策、企业所有细分产业适配的产业类政策、培育企业前景的政策推荐,使得招商业务人员跟进企业的具体需求并在政策匹配模块中推荐标记,从而匹配并选择适合企业的最优政策;
[0088]
s5:区域空间匹配模块通过匹配区域空间库的数据格式化后匹配企业需求量化评价打分并通过企业需求匹配宏观区位、中观区位、微观区位、用地规划、交通物流、生活配套进行适应性评价,从而匹配并选择适合企业的最优区域空间;
[0089]
s6:建筑匹配模块通过匹配规划建筑库选择适合企业最优建筑载体,通过建筑基础信息、建筑结构、节能环保、防火防爆、配套设备、入住成本来对建筑载体做出适应性评价,从而匹配并选择适合企业的最优建筑规划。
[0090]
本发明的有益效果是:
[0091]
一、本发明的基于企业需求的智能匹配招商策略系统及方法在企业需求精准匹配数据的获取方面,基于bp神经网络优化改进lm-bp神经网络算法,并通过企业需求画像来匹配区域产业价值特征分析、匹配区域政策特征分析、匹配区域区位优势特征分析、匹配区域建筑适配特征分析,通过改进后的随机森林算法进一步获取当地区域产业价值、政策、区位优势、建筑资源、政策优势、区位优势、建筑优势各类模型、指标来搭建出更高效匹配的企业需求评分模型,利用丰富的算法逻辑能够更有效地计算企业需求评估,通过招商企业综合评价确保精准招商;
[0092]
二、本发明的基于bp神经网络改进lm-bp神经网络算法进行优化处理,levenberg-marquardt(简称lm)算法同时具备梯度法和牛顿法的优点,为了减轻非最优点的奇异问题,使目标函数接近最优点的时候利用二阶导数在极值点附近的特性近似二次性,以加快寻优收敛过程,比梯度法、bp算法速度快很多,优化大数据分析处理的效率,通过对bp神经网算法改进的lm-bp神经网络,对区域产业价值特征分析、政策特征分析、区位特征分析、建筑特征分析深度学习后,获取企业需求精准匹配的产业、政策、区位、建筑结构化数据,能够助力企业深度学习挖掘企业需求并根据需求获取适配的当地资源;
[0093]
三、本发明主要功能基于企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,运用机器学习、统计学构建企业需求招商策略报告评分模型,跟进企业需求特征,对各个特征之间进行挖掘,挖掘不同特征之间关系,建立基于随机森林改进的评分模型,对企业需求特征状况进行分类和预测,权重指标匹配度多且高的企业为精准适配招商企业,由于随机森林算法实现较为简单、训练速度快、泛化能力强、鲁棒性强,因此将改进后的随机森林算法应用于企业需求评分模型的构建,随机森林改进型的企业需求评分模型主要包括企业需求数据预处理、企业需求矩阵、数据加权抽样、特征选择法选取企业需求最优需求特征子集、算法参数优化、产生评估结果,基于随机森林改进型的企业需求评分模型,通过上述步骤,为产业园区招商人员判断企业是否适配园区招商策略提供了有效的评估参考依据。
[0094]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
[0095]
图1是本发明所述的一种基于企业需求的智能匹配招商策略系统的功能架构图;
[0096]
图2是本发明所述的企业需求评估模块中的产业结构化数据框图(以一类、二类指标为例);
[0097]
图3是本发明所述的bp神经网络的具体原理及算法流程示意图;
[0098]
图4是本发明所述的基于bp神经网络改进后的lm-bp神经网络算法流程示意图;
[0099]
图5是本发明所述的随机森林算法的具体体原理及算法流程示意图;
[0100]
图6是本发明所述的建立基于随机森林改进的企业需求评分模型的流程示意图之一;
[0101]
图7是本发明所述的数据加权抽样的流程示意图;
[0102]
图8是本发明所述的特征选择法选取企业需求最优需求特征子集的流程示意图;
[0103]
图9是本发明所述的随机森林算法的参数优化的流程示意图;
[0104]
图10是本发明所述的一种用于企业智能匹配招商策略系统的方法的流程示意图;
[0105]
图11是本发明所述的建立基于随机森林改进的企业需求评分模型的流程示意图之二;
[0106]
附图中各部分标记如下:
[0107]
企业需求评估模块1、招商策略模块2、产业配套匹配模块3、产业配套库31、政策匹配模块4、政策匹配库41、区域空间匹配模块5、区域空间库51、建筑匹配模块6和规划建筑库61。
具体实施方式
[0108]
以下通过特定的具体实施例说明本发明的具体实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的优点及功效。本发明也可以其它不同的方式予以实施,即,在不背离本发明所揭示的范畴下,能予不同的修饰与改变。
[0109]
实施例1:
[0110]
一种基于企业需求的智能匹配招商策略系统,如图1所示,包括:企业需求评估模
块1、招商策略模块2、产业配套匹配模块3、政策匹配模块4、区域空间匹配模块5和建筑匹配模块6;
[0111]
企业需求评估模块1,用以通过lm-bp神经网络对区域产业价值特征分析、政策特征分析、区位特征分析、建筑特征分析深度学习后,获取企业需求匹配的产业、政策、区位、建筑结构化数据;
[0112]
招商策略模块2,用以对企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,构建企业需求招商策略报告评分模型,建立基于随机森林改进的企业需求评分模型,对企业需求特征状况进行分类和预测;
[0113]
产业配套匹配模块3,用以通过产业配套库31分析企业在所属各自细分产业中本地招商区域产业规模、产业链相关企业总数、规上企业数量、客户及供应商情况并提供企业产业集聚效应、供销关系效应参考值,从而匹配并选择适合企业的最优产业;
[0114]
政策匹配模块4,用以通过政策匹配库41分析适配企业的政策,通过企业发展阶段创业期、成长期、成熟期适配的通用性政策、企业所有细分产业适配的产业类政策、培育企业前景的政策推荐,使得招商业务人员跟进企业的具体需求并在政策匹配模块2中推荐标记,从而匹配并选择适合企业的最优政策;
[0115]
区域空间匹配模块5,用以通过匹配区域空间库51的数据格式化后匹配企业需求量化评价打分并通过企业需求匹配宏观区位、中观区位、微观区位、用地规划、交通物流、生活配套进行适应性评价,从而匹配并选择适合企业的最优区域空间;
[0116]
建筑匹配模块6,用以通过匹配规划建筑库61选择适合企业最优建筑载体,通过建筑基础信息、建筑结构、节能环保、防火防爆、配套设备、入住成本来对建筑载体做出适应性评价,从而匹配并选择适合企业的最优建筑规划。
[0117]
企业需求评估模块主要功能基于企业需求精准匹配数据,企业对当地产业、政策、区位、建筑的需求画像,通过对bp神经网算法改进的lm-bp神经网络,对区域产业价值特征分析、政策特征分析、区位特征分析、建筑特征分析深度学习后,获取企业需求精准匹配的产业、政策、区位、建筑结构化数据。
[0118]
如图2所示,在企业需求评估模块中,企业需求匹配的产业结构化数据包括:产业规模、价值链客户市场、产业链配套和企业配套;企业需求匹配的政策结构化数据包括:产业政策、人才政策和金融政策;企业需求匹配的区位结构化数据包括:交通物流、配套资源和规划要素;企业需求匹配的建筑结构化数据包括:建筑基础要素、节能环保、荷载、防火防爆和使用成本。
[0119]
主要的一类、二类指标为(三类指标过多暂不做列举):
[0120]
a、产业:
[0121]
产业规模:产业产值、规模以上工业营收规模、产业链相关企业、高新技术企业、上市企业;
[0122]
价值链客户:同类型企业、同类型高新技术企业、同类型规上企业、同类型企业评价规模、下游企业、下游企业规模;
[0123]
产业链配套:上游企业、上游企业规模、区域品牌推广平台等级/规模、企业研发中心、产业配套服务平台;
[0124]
企业配套:人才培训机构等级/规模、金融支持资金规模、专业中介服务规模、一站
式代理服务、一网通办、政企直通车、人才公寓;
[0125]
b、政策:
[0126]
产业发展政策:产业结构政策、产业组织政策、产业区域布局政策;
[0127]
税收政策:企业所得税政策、个人所得税政策、增值税政策;
[0128]
人才政策:人才落户政策、人才补贴政策、人才住发政策;
[0129]
金融政策:研发政策补贴、创新政策补贴、税收政策补贴;
[0130]
c、区位:
[0131]
交通物流:距离机场、距离高铁/火车站、距离国道/省道/高速公路、距离港口/码头、政府机构距离、物流;
[0132]
配套资源:居住、商业、医疗、教育、绿地、生活服务;
[0133]
规划要素:建园时间、地块性质、占地面积、准入产业、容积率、建筑属性、建筑分类、租售比例;
[0134]
d、建筑:
[0135]
建筑基础要素:总建筑面积、建筑占地面积、停车位、单层建筑面积、建筑内容、非机动车停车位、楼层、层高等;
[0136]
节能环保:安全防护距离、辐射强度、震动、噪声声级限制、防腐;
[0137]
荷载:永久荷载、可变荷载、偶然荷载;
[0138]
防火防爆:耐火等级、耐火极限、防火间距;
[0139]
使用成本:建筑可获性、租金、物业管理费、万元产值水耗、万元产值能耗。
[0140]
对bp神经网络算法改进的lm-bp神经网络原理介绍:
[0141]
lm算法同时具备梯度法和牛顿法的优点,为了减轻非最优点的奇异问题,使目标函数接近最优点的时候利用二阶导数在极值点附近的特性近似二次性,以加快寻优收敛过程。比梯度法、bp算法速度快很多,优化大数据分析处理的效率。
[0142]
具体介绍:
[0143]
定义误差函数为
[0144][0145]
其中w是神经网络阀值和权值构成的向量;ei=(w)是误差。根据高斯-牛顿法计算方法有:
[0146]
w(k+1)=w(k)-[j
t
(wk)j(wk)]-1
j(wk)e(wk)
[0147]
其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量,w(k+1)表示新的第k+1次迭代的阀值和权值构成的向量。
[0148]
lm算法是一种改进的高斯-牛顿法,如下:
[0149]
w(k+1)=w(k)-[j
t
(wk)j(wk)+μki]-1
j(wk)e(wk)
[0150]
其中i是单位矩阵,j是雅各比矩阵,uk是一个比例系数。lm算法关键一步就是雅各比矩阵的计算,用bp算法的变形计算,如下:
[0151][0152]
如果比例系数u=0则等同高斯-牛顿算法;如果比例系数取值非常大lm算法接近梯度算法。每次迭代一步,u就减小一些。于是在接近误差目标的时候,更与高斯-牛顿算法接近,计算快精度高。u是一种试探性参数,对于一个给定的参数u,如果计算的阀值改变量δw能使误差函数e(w)降低,即u降低。反之u增加。lm算法由利用了二阶导数的信息,计算速度比梯度快很多。实践测试数据证明,lm-bp算法计算速度比传统bp梯度下降高几十倍。
[0153]
因bp神经网络已公开开源,bp神经网络本身具体的原理、算法逻辑该专利技术方案中不做具体介绍,如图3所示;如图4所示,主要介绍优化改进的部分,lm-bp神经网络的具体计算步骤包括如下步骤:
[0154]
步骤1.1:初始化网络结构参数,误差允许值为ε,常数u和b,初始化权值和阈值向量,令k=0,u=u0,计算精度是ε和最大学习次m;
[0155]
步骤1.2:将企业需求画像指标矩阵的训练数据作为输入向量输入到lm-bp神经网络中去;
[0156]
步骤1.3:计算网络输出及误差指标函数e;
[0157]
步骤1.4:计算雅各比矩阵j[w(k)];其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量;
[0158]
步骤1.5:计算δw;其中,δw为阈值改变量;
[0159]
步骤1.6:若e《ε,则转到步骤1.8,否则转到步骤1.5;
[0160]
步骤1.7:以新的权值和阀值向量w(k+1)来计算误差函数e,
[0161]
w(k+1)=w(k)-{j
t
[w(k)]j[w(k)]}-1
j[w(k)]e[w(k)]
[0162]
若e[w(k+1)]小于e[w(k)],则令k=k+1,u=u*b,转到步骤1.2,否则u=u/b,转到步骤1.5;其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量,w(k+1)表示新的第k+1次迭代的阀值和权值构成的向量;
[0163]
步骤1.8:lm-bp神经网络计算结束。
[0164]
以上通过lm-bp神经网络计算得出企业需求精准匹配的产业、政策、区位、建筑结构化数据,通过招商策略模块对企业需求画像匹配的指标和权值进行评分。
[0165]
在步骤1.1中,b的取值范围为:0《b《1,当k=0,u=u0时,计算精度ε和最大学习次m。
[0166]
在步骤1.4和步骤1.7中,通过雅各比矩阵j[w(k)]的变形,计算出j
t
(w),计算j
t
(w)的公式为:
[0167][0168]
招商策略模块的功能介绍:
[0169]
主要功能基于企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,运用机器学习、统计学构建企业需求招商策略报告评分模型,跟进企业需求特征,对其各个特征之间进行挖掘,挖掘不同特征之间关系,建立基于随机森林改进的企业需求评分模型,对企业需求特征状况进行分类和预测,权重指标匹配度多且高的企业为精准适配招商企业。
[0170]
算法原理及逻辑介绍:
[0171]
如图5所示,随机森林算法的基础组成单元为决策树,该算法的主要思想为在原始样本集s中采用有放回地重复去随机抽取n个样本生成新的样本集合,然后根据自助样本集生成n个分类树构成随机森林,最后的分类结果按分类树投票多少进行决策。
[0172]
由于随机森林算法实现较为简单、训练速度快、泛化能力强、鲁棒性强,因此,本专利技术将改进后的随机森林算法应用于企业需求评分模型的构建。
[0173]
基于随机森林改进型的企业需求评分模型主要由6个部分构成:企业需求数据预处理、企业需求矩阵、数据加权抽样、特征选择法选取企业需求最优需求特征子集、算法参数优化、产生评估结果,如图11所示。
[0174]
步骤2建立基于随机森林改进的企业需求评分模型的步骤包括:
[0175]
步骤2.1:企业需求数据预处理;
[0176]
企业需求数据较复杂,包括对当地产业、政策、区位、建设需求各指标匹配分析,在上一步企业需求匹配模块已做了初步匹配筛选,因测试发现经常存在缺失、异常、冗余数据,为了减少企业需求数据中的噪声数据给评分逻辑带来评估困难,也为了满足计算的要求和结果有效性,在建立评分模型前仍需对数据进行预处理。本技术方案中使用的预处理方法,如图11所示,主要包括:
[0177]
(1)min-max标准化
[0178]
主要通过对离线数据进行线性变换,结果处于[0-1]之间,公式为:
[0179][0180]
其中min_value是数据样本最小值,max_value是数据样本中的最大值,new_value(x)是样本数据经过min-max标准化处理后的新数据值。
[0181]
(2)z-score标准化
[0182]
主要对原始数据的均值(mean)和标准差(standard deviation)进行计算,然后进
行z-score处理。目标将数据转换为mean为0且standard deviation为1的高斯分布。公式为:
[0183][0184]
其中所有数据样本集mean为u(data),所有数据样本集standard deviation为o(data),z(new_data)为数据样本集z-score处理后的数据值。
[0185]
因企业需求数据集中存在非数值特征,对该特征采用one-hot编码进行处理,通过以下公式进行:
[0186][0187]
其中,a、b分布表示两个特征属性,ra,b表示两个特征属性的关联度,n为元组的个数,ai、bi分别为a、b上的值,amean、bmean分别为a、b上的均值,aibi分别为ab的叉积合,σaσb为ab的标准差,ra,b值越大,表明两个特征相关度越高,同时ra,b值越高,则特征属性a或b可以作为冗余特性属性删除。
[0188]
步骤2.2:计算企业需求矩阵;
[0189]
在步骤2.2中,计算企业需求矩阵的具体步骤为:设x={b1,b2,
……
,bl}表示由m个特征的l个样本组成的合集,y={y1,y2,
……
,yl}表示类别合集,则企业需求数据可以构建矩阵为:
[0190][0191]
其中矩阵l的大小为l(m+1),+1表示类别的集合,bi={xi1,xi2,
……
,xim}代表bi表样本的m个特征值,xij代表样本bi的第j个特征值;
[0192]
在企业需求矩阵l中,包括少数样本l
″
和多数样本l
′
,取少数样本l
″
中q个样本,构成的矩阵形式为:
[0193][0194]
少数样本l
″
中有q个样本,总样本为l个,则多数样本l
′
中有(l-q)个样本数,则其矩阵形式为:
[0195][0196]
步骤2.3:数据加权抽样;
[0197]
随机森林算法默认采用bootstrap采样方法,该方法会产生较大的误差,也会破坏原始数据的结构,导致评分极度不平衡,数据不平衡后导致有可能将企业需求匹不适配的企业误认为招商适配企业。为提高评分模型精确度,将对原始bootstrap采样方法进行改造,即根据权重进行采样。
[0198]
因此,在步骤2.3中,数据加权抽样的具体步骤包括:
[0199]
步骤2.3.1:将原始的企业需求数据分为训练集l和训练集l1;
[0200]
步骤2.3.2:将训练集l划分两个子集,分别为多数类样本l
′
和少数类样本l
″
;
[0201]
步骤2.3.3:采样过程中,先对多数类样本l
′
进行加权抽样,在多数类样本l
′
中挑出少数类样本l
″
大小相近的样本,计算挑出少数l
″
样本占比l
′
比重,并计算l
″
占所有l样本比重,然后对权重进行加权选取最后的训练样本;
[0202]
步骤2.3.4:重复步骤2.3.3多次,直到挑选到平衡样本;
[0203]
步骤2.3.5:挑出平衡样本进行划分,划分为训练集和测试集。
[0204]
基于上述数据加权抽样后,接下来对企业需求多数类l
′
进行抽取,假设多少类样本l
′
中每个类别包含样本数为h(k1),h(k2),h(k3),
…
,h(kn),其中k1,k2,
…
kn表示多少样本l
′
类别的分布情况,那么ki在多数样本l
′
中被抽样的权重占比为:
[0205][0206]
根据上述公式计算出多样本中被抽中少数样本的权重,则少数样本中ki被抽样的整体权重为:
[0207][0208]
根据上诉假设少数样本个数为q,那么多样本中kj的加权抽样权重为:
[0209][0210]
步骤2.4:特征选择法选取企业需求最优需求特征子集;
[0211]
在步骤2.4中,输入为原始企业需求数据集d={(x1,y1),(x2,y2),
……
,(xn,yn)},xi∈rm,且yn∈{-1,1};设定g1,g2;
[0212]
输出为最优特征子集f;
[0213]
特征选择法选取企业需求最优需求特征子集的具体选取步骤,如图8所示,包括:
[0214]
步骤2.4.1:设定m个企业需求特征i=1,2,3,4,
…
,m;
[0215]
步骤2.4.2:利用以下公式计算每个企业需求特征相应的值;
[0216]
设定d为样本数据集,x,y为样本任意属性,n为数据集d中的类别数量,则x的信息熵为:
[0217][0218]
其中p(xi)为特性属性x取值为xi的概率;
[0219]
特征属性y给定的条件下特征属性x的条件熵为:
[0220][0221]
其中p(yi)为特性属性y取值为yj的概率,p(xi|yi)为特性属性y取值为yj的情况下,特性属性x取值为xi的概率;
[0222]
上述公式得到的信息熵为:
[0223]
gain(x,y)=info(x)-info(x|y)
[0224]
选择信息增益最大的特征作为数据集d的分裂属性,创建一个节点,使用该特征作为标记,对特征每个值创建分支,据此对样本的企业需求进行划分;
[0225]
步骤2.4.3:利用以下公式分别计算每个特征与类别变量yn的熵比较值un;
[0226]
步骤2.4.4:若un大于等于g1,则特征xn在选定的最优特征子集f中,即xn∈f;
[0227]
对特征进行排序,对集合f内选定的特征进行度量,确定特征xi及xj间相关值s;
[0228]
步骤2.4.5:当s小于等于g2,则跟进步骤(3)中信息熵比较值un大小对集合f中的特性进行删除;
[0229]
步骤2.4.6:得到最优特征子集。
[0230]
步骤2.5:算法参数优化;
[0231]
传统的随机森林算法存在以下缺点:
[0232]
(1)算法参数复杂:随机森林在训练之前设置参数较多,主要包括n_estimators
(决策树个数)、树的最大深度、最大特征数max_feature等参数,因预先设置,参数若不合理会严重影响企业需求最终评估精度。如果参数设置太小,容易出现欠拟合;如果参数设置太大,容易出现过拟合;
[0233]
(2)决策树个数过多后,训练时间会过长;决策树个数过少后,训练时间短,影响预测精度。如何平衡两者关系也是大量数据训练中面临的挑战;
[0234]
随机森林算法参数选择的改进:
[0235]
引入网格搜索策略对随机森林中n_estimators(决策树个数)、最大特征数max_feature参数进行寻优;假设n_estimators(决策树个数)、最大特征数max_feature两个参数分别为s、c,用s*c分别对随机森林分类器进行训练,在步骤2.5中,算法参数优化的具体优化步骤,如图9所示,包括:
[0236]
步骤2.5.1:设置需要优化参数搜索范围和步长;
[0237]
步骤2.5.2:根据步骤2.5.1进一步计算两个参数s和c的平均绝对误差值,利用平均绝对误差值得到两个参数s和c的个数具体范围;
[0238]
步骤2.5.3:根据步骤2.5.2中得到的参数s、c的取值范围,以s*c组合利用以下过程计算随机森林oob值,获取准确率;
[0239]
在对样本进行每次抽样训练时,未被抽到的样本数据,标记为集合oobi,将在未抽样的数据集oobi被错误的分类个数,标记为errornumoob,最后随机森林oob值的误差定义为:
[0240][0241]
即泛化误差为:
[0242][0243]
步骤2.5.4:根据oob值挑选s*c组合确定的最优参数,若随机森林oob值满足要求,输出s*c组合,否则改变搜索范围及步长,继续搜索,直到满足最终条件。
[0244]
以上通过引入网格搜索策略来寻找随机森林的最优参数,可以减少运行时间,减少算法复杂度,提供算法分类精度,优化流程如图6所示。
[0245]
步骤2.6:产生评估结果;
[0246]
在步骤2.6中,基于随机森林改进的企业需求评分模型通过步骤2.1至步骤2.5产生最优评估结果,作为评估参考依据,提供给产业园区招商人员判断企业是否适配园区招商策略。
[0247]
实施例2:
[0248]
一种用于企业智能匹配招商策略系统的方法,如图10所示,包括以下步骤:
[0249]
s1:企业需求评估模块通过lm-bp神经网络对区域产业价值特征分析、政策特征分析、区位特征分析、建筑特征分析深度学习后,获取企业需求匹配的产业、政策、区位、建筑结构化数据;
[0250]
其中,对bp神经网络算法改进的lm-bp神经网络原理介绍:
[0251]
lm算法同时具备梯度法和牛顿法的优点,为了减轻非最优点的奇异问题,使目标函数接近最优点的时候利用二阶导数在极值点附近的特性近似二次性,以加快寻优收敛过程。比梯度法、bp算法速度快很多,优化大数据分析处理的效率;
[0252]
具体介绍:
[0253]
定义误差函数为
[0254][0255]
其中w是神经网络阀值和权值构成的向量;ei=(w)是误差。根据高斯-牛顿法计算方法有:
[0256]
w(k+1)=w(k)-[j
t
(wk)j(wk)]-1
j(wk)e(wk)
[0257]
其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量,w(k+1)表示新的第k+1次迭代的阀值和权值构成的向量。
[0258]
lm算法是一种改进的高斯-牛顿法,如下:
[0259]
w(k+1)=w(k)-[j
t
(wk)j(wk)+μki]-1
j(wk)e(wk)
[0260]
其中i是单位矩阵,j是雅各比矩阵,uk是一个比例系数。lm算法关键一步就是雅各比矩阵的计算,用bp算法的变形计算,如下:
[0261][0262]
如果比例系数u=0则等同高斯-牛顿算法;如果比例系数取值非常大lm算法接近梯度算法。每次迭代一步,u就减小一些。于是在接近误差目标的时候,更与高斯-牛顿算法接近,计算快精度高。u是一种试探性参数,对于一个给定的参数u,如果计算的阀值改变量δw能使误差函数e(w)降低,即u降低。反之u增加。lm算法由利用了二阶导数的信息,计算速度比梯度快很多。实践测试数据证明,lm-bp算法计算速度比传统bp梯度下降高几十倍。
[0263]
因bp神经网络已公开开源,bp神经网络本身具体的原理、算法逻辑该专利技术方案中不做具体介绍,如图3所示,主要介绍优化改进的部分,如图4所示,lm-bp神经网络的具体计算步骤包括如下步骤:
[0264]
步骤1.1:初始化网络结构参数,误差允许值为ε,常数u和b,初始化权值和阈值向量,令k=0,u=u0,计算精度是ε和最大学习次m;
[0265]
步骤1.2:将企业需求画像指标矩阵的训练数据作为输入向量输入到lm-bp神经网络中去;
[0266]
步骤1.3:计算网络输出及误差指标函数e;
[0267]
步骤1.4:计算雅各比矩阵j[w(k)];其中,w(k)代表第k次神经网络迭代的阀值与
权值构成的向量;
[0268]
步骤1.5:计算δw;其中,δw为阈值改变量;
[0269]
步骤1.6:若e《ε,则转到步骤1.8,否则转到步骤1.5;
[0270]
步骤1.7:以新的权值和阀值向量w(k+1)来计算误差函数e,
[0271]
w(k+1)=w(k)-{j
t
[w(k)]j[w(k)]}-1
j[w(k)]e[w(k)]
[0272]
若e[w(k+1)]小于e[w(k)],则令k=k+1,u=u*b,转到步骤1.2,否则u=u/b,转到步骤1.5;其中,w(k)代表第k次神经网络迭代的阀值与权值构成的向量,w(k+1)表示新的第k+1次迭代的阀值和权值构成的向量;
[0273]
步骤1.8:lm-bp神经网络计算结束;
[0274]
以上通过lm-bp神经网络计算得出企业需求精准匹配的产业、政策、区位、建筑结构化数据,通过招商策略模块对企业需求画像匹配的指标和权值进行评分。
[0275]
在步骤1.1中,b的取值范围为:0《b《1,当k=0,u=u0时,计算精度ε和最大学习次m。
[0276]
在步骤1.4和步骤1.7中,通过雅各比矩阵j[w(k)]的变形,计算出j
t
(w),计算j
t
(w)的公式为:
[0277][0278]
s2:招商策略模块对企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,构建企业需求招商策略报告评分模型,建立基于随机森林改进的企业需求评分模型,对企业需求特征状况进行分类和预测;
[0279]
招商策略模块的功能介绍:
[0280]
主要功能基于企业需求画像和匹配的当地产业、政策、区位、建筑资源进行评分,运用机器学习、统计学构建企业需求招商策略报告评分模型,跟进企业需求特征,对其各个特征之间进行挖掘,挖掘不同特征之间关系,建立基于随机森林改进的企业需求评分模型,对企业需求特征状况进行分类和预测,权重指标匹配度多且高的企业为精准适配招商企业。
[0281]
算法原理及逻辑介绍:
[0282]
如图5所示,随机森林算法的基础组成单元为决策树,该算法的主要思想为在原始样本集s中采用有放回地重复去随机抽取n个样本生成新的样本集合,然后根据自助样本集生成n个分类树构成随机森林,最后的分类结果按分类树投票多少进行决策。
[0283]
由于随机森林算法实现较为简单、训练速度快、泛化能力强、鲁棒性强,因此,本专利技术将改进后的随机森林算法应用于企业需求评分模型的构建。
[0284]
基于随机森林改进型的企业需求评分模型主要由6个部分构成:企业需求数据预
处理、企业需求矩阵、数据加权抽样、特征选择法选取企业需求最优需求特征子集、算法参数优化、产生评估结果。
[0285]
步骤2建立基于随机森林改进的企业需求评分模型的步骤包括:
[0286]
步骤2.1:企业需求数据预处理;
[0287]
企业需求数据较复杂,包括对当地产业、政策、区位、建设需求各指标匹配分析,在上一步企业需求匹配模块已做了初步匹配筛选,因测试发现经常存在缺失、异常、冗余数据,为了减少企业需求数据中的噪声数据给评分逻辑带来评估困难,也为了满足计算的要求和结果有效性,在建立评分模型前仍需对数据进行预处理。本专利技术中使用的预处理方法主要包括:
[0288]
(1)min-max标准化
[0289]
主要通过对离线数据进行线性变换,结果处于[0-1]之间,公式为:
[0290][0291]
其中min_value是数据样本最小值,max_value是数据样本中的最大值,new_value(x)是样本数据经过min-max标准化处理后的新数据值。
[0292]
(2)z-score标准化
[0293]
主要对原始数据的均值(mean)和标准差(standard deviation)进行计算,然后进行z-score处理。目标将数据转换为mean为0且standard deviation为1的高斯分布。公式为:
[0294][0295]
其中所有数据样本集mean为u(data),所有数据样本集standard deviation为o(data),z(new_data)为数据样本集z-score处理后的数据值。
[0296]
因企业需求数据集中存在非数值特征,对该特征采用one-hot编码进行处理,通过以下公式进行:
[0297][0298]
其中,a、b分布表示两个特征属性,ra,b表示两个特征属性的关联度,n为元组的个数,ai、bi分别为a、b上的值,amean、bmean分别为a、b上的均值,aibi分别为ab的叉积合,σaσb为ab的标准差,ra,b值越大,表明两个特征相关度越高,同时ra,b值越高,则特征属性a或b可以作为冗余特性属性删除。
[0299]
步骤2.2:计算企业需求矩阵;
[0300]
在步骤2.2中,计算企业需求矩阵的具体步骤为:设x={b1,b2,
……
,bl}表示由m个特征的l个样本组成的合集,y={y1,y2,
……
,yl}表示类别合集,则企业需求数据可以构建矩阵为:
[0301][0302]
其中矩阵l的大小为l(m+1),+1表示类别的集合,bi={xi1,xi2,
……
,xim}代表bi表样本的m个特征值,xij代表样本bi的第j个特征值;
[0303]
在企业需求矩阵l中,包括少数样本l
″
和多数样本l
′
,取少数样本l
″
中q个样本,构成的矩阵形式为:
[0304][0305]
少数样本l
″
中有q个样本,总样本为l个,则多数样本l
′
中有(l-q)个样本数,则其矩阵形式为:
[0306][0307]
步骤2.3:数据加权抽样;
[0308]
随机森林算法默认采用bootstrap采样方法,该方法会产生较大的误差,也会破坏原始数据的结构,导致评分极度不平衡,数据不平衡后导致有可能将企业需求匹不适配的企业误认为招商适配企业。为提高评分模型精确度,将对原始bootstrap采样方法进行改造,即根据权重进行采样。
[0309]
因此,在步骤2.3中,如图7所示,数据加权抽样的具体步骤包括:
[0310]
步骤2.3.1:将原始的企业需求数据分为训练集l和训练集l1;
[0311]
步骤2.3.2:将训练集l划分两个子集,分别为多数类样本l
′
和少数类样本l
″
;
[0312]
步骤2.3.3:采样过程中,先对多数类样本l
′
进行加权抽样,在多数类样本l
′
中挑出少数类样本l
″
大小相近的样本,计算挑出少数l
″
样本占比l
′
比重,并计算l
″
占所有l样本比重,然后对权重进行加权选取最后的训练样本;
[0313]
步骤2.3.4:重复步骤2.3.3多次,直到挑选到平衡样本;
[0314]
步骤2.3.5:挑出平衡样本进行划分,划分为训练集和测试集。
[0315]
基于上述数据加权抽样后,接下来对企业需求多数类l
′
进行抽取,假设多少类样本l
′
中每个类别包含样本数为h(k1),h(k2),h(k3),
…
,h(kn),其中k1,k2,
…
kn表示多少样本l
′
类别的分布情况,那么ki在多数样本l
′
中被抽样的权重占比为:
[0316][0317]
根据上述公式计算出多样本中被抽中少数样本的权重,则少数样本中ki被抽样的整体权重为:
[0318][0319]
根据上诉假设少数样本个数为q,那么多样本中kj的加权抽样权重为:
[0320][0321]
步骤2.4:特征选择法选取企业需求最优需求特征子集;
[0322]
在步骤2.4中,输入为原始企业需求数据集d={(x1,y1),(x2,y2),
……
,(xn,yn)},xi∈rm,且yn∈{-1,1};设定g1,g2;
[0323]
输出为最优特征子集f;
[0324]
特征选择法选取企业需求最优需求特征子集的具体选取步骤包括:
[0325]
步骤2.4.1:设定m个企业需求特征i=1,2,3,4,
…
,m;
[0326]
步骤2.4.2:利用以下公式计算每个企业需求特征相应的值;
[0327]
设定d为样本数据集,x,y为样本任意属性,n为数据集d中的类别数量,则x的信息熵为:
[0328][0329]
其中p(xi)为特性属性x取值为xi的概率;
[0330]
特征属性y给定的条件下特征属性x的条件熵为:
[0331][0332]
其中p(yi)为特性属性y取值为yj的概率,p(xi|yi)为特性属性y取值为yj的情况下,特性属性x取值为xi的概率;
[0333]
上述公式得到的信息熵为:
[0334]
gain(x,,y)=info(x)-info(x|y)
[0335]
选择信息增益最大的特征作为数据集d的分裂属性,创建一个节点,使用该特征作
为标记,对特征每个值创建分支,据此对样本的企业需求进行划分;
[0336]
步骤2.4.3:利用以下公式分别计算每个特征与类别变量yn的熵比较值un;
[0337]
步骤2.4.4:若un大于等于g1,则特征xn在选定的最优特征子集f中,即xn∈f;
[0338]
对特征进行排序,对集合f内选定的特征进行度量,确定特征xi及xj间相关值s;
[0339]
步骤2.4.5:当s小于等于g2,则跟进步骤(3)中信息熵比较值un大小对集合f中的特性进行删除;
[0340]
步骤2.4.6:得到最优特征子集。
[0341]
步骤2.5:算法参数优化;
[0342]
传统的随机森林算法存在以下缺点:
[0343]
(1)算法参数复杂:随机森林在训练之前设置参数较多,主要包括n_estimators(决策树个数)、树的最大深度、最大特征数max_feature等参数,因预先设置,参数若不合理会严重影响企业需求最终评估精度。如果参数设置太小,容易出现欠拟合;如果参数设置太大,容易出现过拟合;
[0344]
(2)决策树个数过多后,训练时间会过长;决策树个数过少后,训练时间短,影响预测精度。如何平衡两者关系也是大量数据训练中面临的挑战;
[0345]
随机森林算法参数选择的改进:
[0346]
引入网格搜索策略对随机森林中n_estimators(决策树个数)、最大特征数max_feature参数进行寻优;假设n_estimators(决策树个数)、最大特征数max_feature两个参数分别为s、c,用s*c分别对随机森林分类器进行训练,在步骤2.5中,如图9所示,算法参数优化的具体优化步骤包括:
[0347]
步骤2.5.1:设置需要优化参数搜索范围和步长;
[0348]
步骤2.5.2:根据步骤2.5.1进一步计算两个参数s和c的平均绝对误差值,利用平均绝对误差值得到两个参数s和c的个数具体范围;
[0349]
步骤2.5.3:根据步骤2.5.2中得到的参数s、c的取值范围,以s*c组合利用以下过程计算随机森林oob值,获取准确率;
[0350]
在对样本进行每次抽样训练时,未被抽到的样本数据,标记为集合oobi,将在未抽样的数据集oobi被错误的分类个数,标记为errornumoob,最后随机森林oob值的误差定义为:
[0351][0352]
即泛化误差为:
[0353][0354]
步骤2.5.4:根据oob值挑选s*c组合确定的最优参数,若随机森林oob值满足要求,输出s*c组合,否则改变搜索范围及步长,继续搜索,直到满足最终条件。
[0355]
以上通过引入网格搜索策略来寻找随机森林的最优参数,可以减少运行时间,减少算法复杂度,提供算法分类精度,优化流程如图6所示。
[0356]
步骤2.6:产生评估结果;
[0357]
在步骤2.6中,基于随机森林改进的企业需求评分模型通过步骤2.1至步骤2.5产生最优评估结果,作为评估参考依据,提供给产业园区招商人员判断企业是否适配园区招商策略。
[0358]
s3:产业配套匹配模块通过产业配套库分析企业在所属各自细分产业中本地招商区域产业规模、产业链相关企业总数、规上企业数量、客户及供应商情况并提供企业产业集聚效应、供销关系效应参考值,从而匹配并选择适合企业的最优产业;
[0359]
s4:政策匹配模块通过政策匹配库分析适配企业的政策,通过企业发展阶段创业期、成长期、成熟期适配的通用性政策、企业所有细分产业适配的产业类政策、培育企业前景的政策推荐,使得招商业务人员跟进企业的具体需求并在政策匹配模块中推荐标记,从而匹配并选择适合企业的最优政策;
[0360]
s5:区域空间匹配模块通过匹配区域空间库的数据格式化后匹配企业需求量化评价打分并通过企业需求匹配宏观区位、中观区位、微观区位、用地规划、交通物流、生活配套进行适应性评价,从而匹配并选择适合企业的最优区域空间;
[0361]
s6:建筑匹配模块通过匹配规划建筑库选择适合企业最优建筑载体,通过建筑基础信息、建筑结构、节能环保、防火防爆、配套设备、入住成本来对建筑载体做出适应性评价,从而匹配并选择适合企业的最优建筑规划。
[0362]
以上所述仅为本发明的实施例,并非因此以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1