一种类别无关的自动结账产品计数方法
1.本发明属于零售商品自动结账领域,具体涉及一种类别无关的自动结账产品计数方法。
背景技术:
2.自动结账系统越来越多的被应用于日常生活,如自动货柜和无人便利店。而自动结账任务本质上是准确预测任意产品组合中每种产品的存在和数量。有了自动结账系统,顾客只需将选定的物品放在结账柜台上,基于人工智能的系统就能识别这些物品的类别和数量,并自动处理购买。然后它将生成一个购物清单,告知顾客每个类别的产品数量和需要支付的费用。
3.然而自动结账任务面临着几个挑战。其中一个主要的挑战就是产品类别的大规模性。为了解决这个问题,一些现有方法[wei x s,cui q,yang l,et al.rpc:a large-scale retail product checkout dataset[j].arxiv preprint arxiv:1901.07249,2019.][li c,du d,zhang l,et al.data priming network for automatic check-out[c]//proceedings of the 27th acm international conference on multimedia.2019:2152-2160.][yang y,sheng l,jiang x,et al.increaco:incrementally learned automatic check-out with photorealistic exemplar augmentation[c]//proceedings of the ieee/cvf winter conference on applications of computer vision.2021:626-634.]采用了带有边界框注解的对象检测方法来预测产品类别和数量。然而,边界框注释的获取是很耗时的,也需要大量的人力。同时,所提供的边界框可能无法完全覆盖要检测的目标对象,特别是存在遮挡的情况下。其次,自动结账任务的另一个挑战是产品类别的细粒度属性。在自动结账任务中,可能有多个产品类别同属于一个元类别。这些产品可能在外观上极为相似,但其内容却不尽相同。第三,与一般的物体检测和识别任务不同,多类别产品计数需要解决领域差距问题。具体来说,单品图像是在受控条件下拍摄的,而结账图像是在放置各种产品的结账平台上拍摄的。多类别产品计数算法必须能够适应源域和目标域之间的差异。自动结账任务的最后一个挑战是在现实的结账场景中持续更新产品。因此,最好有一种方法能够根据新的产品类别不断地更新现有的模型,而不需要从头开始训练模型。
[0004]
虽然一些现有方法[wei x s,cui q,yang l,et al.rpc:a large-scale retail product checkout dataset[j].arxiv preprint arxiv:1901.07249,2019.][li c,du d,zhang l,et al.data priming network for automatic check-out[c]//proceedings of the 27th acm international conference on multimedia.2019:2152-2160.][yang y,sheng l,jiang x,et al.increaco:incrementally learned automatic check-out with photorealistic exemplar augmentation[c]//proceedings of the ieee/cvf winter conference on applications of computer vision.2021:626-634.]采用了带有边界框注解的对象检测方法来预测产品类别和数量,但是这些方法存在以下不足:1)边界框注释获取成本大,可能无法完全覆盖要检测的目标对象;2)方法没有针对细粒度属性进行优化。
技术实现要素:
[0005]
本发明的目的在于提供一种类别无关的自动结账产品计数方法。
[0006]
实现本发明目的的技术方案为:一种类别无关的自动结账产品计数方法,包括以下步骤:
[0007]
步骤1,使用一种计数分治策略作为自监督方法生成预训练模型,用于初始化计数模块参数;
[0008]
步骤2,利用注意力模块通过结账图像中的位置信息和细节信息以捕获细粒度特征,利用域适应模块对结账图像域和单品图像域进行判别,通过梯度反转层使域判别器混淆此二域;
[0009]
步骤3,将单品图像类别特征图和结账图像特征图拼接后输入计数模块,进行对应类别的定位和计数,同时进行增量学习的实验设定,以验证方法的类别无关性。
[0010]
一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的类别无关的自动结账产品计数方法。
[0011]
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的类别无关的自动结账产品计数方法。
[0012]
本发明与现有技术相比,其显著优点为:(1)本发明仅使用点级别的注释信息对对结账图像中的各类产品进行定位和计数,降低了注释信息的获取成本。(2)使用计数分治法作为自监督方法预训练模型以初始化计数模块参数,提高了网络的准确率。(3)该网络可以在常规实验设定和增量学习实验设定中取得较好结果,验证了本发明的类别无关性。
附图说明
[0013]
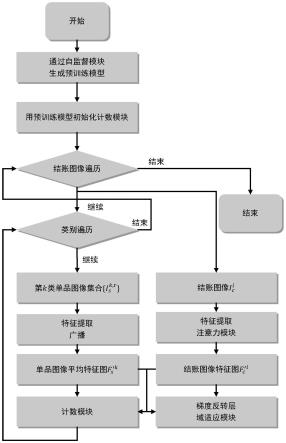
图1为本发明一种类别无关的自动结账产品计数方法流程图。
[0014]
图2为本发明一种类别无关的自动结账产品计数方法流程可视化图。
[0015]
图3为本发明一种类别无关的自动结账产品计数方法增量学习实验流程图。
具体实施方式
[0016]
本发明提出一种类别无关的自动结账产品计数方法,包括以下步骤:把结账图像输入基于分治法构建的自监督模块,即图像各部分计数和应与全局计数和相等,为后续的计数模块生成一个供其初始化参数的预训练模型;分别对单品图像和结账图像提取特征,按照一定规则选取的单品图像的特征向量在全局平均聚合后广播到结账图像特征图相同大小;同时结账图像特征图被送入注意力模块以增强细粒度特征,该模块包含一个关注空间信息的布局注意力子模块和一个关注通道信息的细节注意力子模块;单品图像特征图和结账图像特征图被同时输入域适应模块,经过一个梯度反转层后进行域判别,以混淆源域和目标域;同时单品图像特征图和结账图像特征图被拼接为一个长特征图输入计数模块,根据热力图中的不同响应值进行计数以得到结账图像中各类实例的数量。本发明充分利用点级别注释信息,根据不同类别单品图像与结账图像的热力图响应不同来进行计数,同时使用自监督方法初始化模型参数,通过注意力模块捕获细粒度特征,应用梯度反转层进行域适应,针对自动结账任务提出了一种类别无关的产品计数方法,在常规实验设置和增量实验设置中均取得了较好结果。
[0017]
下面结合附图对本发明的技术方案进行详细说明。
[0018]
结合图1、图2以及图3,一种类别无关的自动结账产品计数方法,包括以下步骤:
[0019]
步骤1,使用一种计数分治策略作为自监督方法生成预训练模型,用于初始化计数模块参数;
[0020]
所述的使用计数分治策略作为自监督方法,对结账图像分块后分别计数,局部计数和与全局计数相同;自监督方法根据技术分治策略设计,将输入的结账图像均匀的分为若干块,对每一块和完整的结账图像分别计数,得到各块的局部计数与全图的全局计数,按照局部计数和等于全局计数的条件优化预训练模型。
[0021]
步骤2,利用注意力模块通过结账图像中的位置信息和细节信息以捕获细粒度特征,利用域适应模块对结账图像域和单品图像域进行判别,通过梯度反转层使域判别器混淆此二域,解决零售商品数据的细粒度属性和域差异问题;
[0022]
对于第i张结账图像h和w分别表示图像的高度和宽度,经过特征提取模块后可以得到特征图π是特征提取网络的参数,该特征图输入注意力模块可以得到增强后的特征图f
′
ci
:
[0023][0024]
att
layout
(f)=σ(conv([f
gap
(f):f
gmp
(f)])),
[0025]
att
detail
(f)=σ(f
mlp
(f
gap
(f))+f
mlp
(f
gmp
(f))).
[0026]
其中att
layout
(
·
)和att
detail
(
·
)分别代表布局和细节两个注意力子模块,f为一个任意的特征图,σ是sigmoid函数,conv(
·
)是一个核大小为7
×
7的卷积操作,[:]是拼接操作,f
gap
(
·
)和f
gmp
(
·
)分别是全局平均汇合(global average pooling)与全局最大汇合(global maximum pooling)操作,f
mlp
(
·
)是一个包含一层隐藏层的多层感知机(multi-layer perceptron)。
[0027]
在单品图像方面,对同一类产品随机采样ns张图像,表示为张图像,表示为k是产品类别总数,r=1,
…
,ns,h和w分别表示图像的高度和宽度。提取特征后得到特征向量θ是特征提取网络的参数,而第k类单品图像经过广播操作后得到的特征图是播操作后得到的特征图是f
′
sk
的大小与f
′
ci
保持一致。
[0028]
将f
′
ci
和f
′
sk
同时输入域适应模块。先经过一个梯度反转层,再让域判别器进行判别,最终混淆结账图像域和单品图像域,从而实现域适应。
[0029]
步骤3,将单品图像类别特征图和结账图像特征图拼接后输入计数模块,进行对应类别的定位和计数,同时进行增量学习的实验设定,以验证方法的类别无关性。
[0030]
将通过步骤2得到的结账图像特征图f
′
ci
和单品图像特征图f
′
sk
输入计数模块,对结账图像中的第k类产品进行定位和计数。
[0031]f′
ci
和f
′
sk
先拼接成一个长特征图,然后被送入沙漏网络,根据输出热力图的不同热力值对第k类产品进行定位和计数:
[0032]
[0033]
其中hg(
·
)是沙漏网络。
[0034]
增量学习的实验设定为:从类别中随机选取一些类别作为未知类,先用已知类数据训练完整的网络模型,然后用该模型测试包含所有已知类和未知类的测试数据集和仅包含已知类的测试数据集,对比两者的结果,如图3所示。
[0035]
本发明的效果可通过以下仿真实验进一步说明:
[0036]
仿真条件
[0037]
仿真实验采用一个零售商品结账图像数据集(retail product checkout dataset)[wei x s,cui q,yang l,et al.rpc:a large-scale retail product checkout dataset[j].arxiv preprint arxiv:1901.07249,2019.]。该数据集含有单品图像53739张,分辨率是2592
×
1944,结账图像30000张(6000张验证集,24000张测试集),分辨率是1800
×
1800。产品共有200个类,分别从属于17个大类。
[0038]
仿真实验均在linux操作系统下采用python完成。训练和测试时的图像分辨率都设置为512
×
512,批量大小设置为4,训练时使用sgd优化器,动量0.9,权重衰减0.0001,学习率初始化为0.01,在第20轮时学习率变为原来的0.1倍,总轮数为80,nc和ns分别是6000和8。
[0039]
本发明采用四种评价指标,其分别为:结账准确率(check-out accuracy,cacc),平均计数距离(average counting distance,acd),平均类别计数距离(mean category counting distance,mccd),平均类别交并比(mean category intersection of union,mciou)。
[0040]
仿真内容
[0041]
本发明采用零售商品结账图像数据集rpc检验算法的自动结账性能。为测试本发明算法的性能,将提出的类别无关的自动结账产品计数方法(自监督多类计数方法,self-supervised multi-class counting,s2mc2)与rpc[wei x s,cui q,yang l,et al.rpc:a large-scale retail product checkout dataset[j].arxiv preprint arxiv:1901.07249,2019.],dpnet[li c,du d,zhang l,et al.data priming network for automatic check-out[c]//proceedings of the 27th acm international conference on multimedia.2019:2152-2160.],increaco[yang y,sheng l,jiang x,et al.increaco:incrementally learned automatic check-out with photorealistic exemplar augmentation[c]//proceedings of the ieee/cvf winter conference on applications of computer vision.2021:626-634.]进行比较。
[0042]
另外还进行了增量设置实验,随即选取17大类中的一个小类作为未知类,其他183类作为已知类,用已知类的数据训练本方法的网络,然后用已知类和完整数据分别测试,并与之前包含增量实验的方法increaco进行比较。
[0043]
仿真实验结果分析
[0044]
表1为rpc数据集在不同的自动结账算法下的评价指标对比结果。实验结果表明本发明的算法优于其他自动结账算法,能比较准确的对结账图像中的产品进行定位和计数,cacc比之前较好的dpnet的结果高了1.61%。
[0045]
表1rpc数据集的自动结账评价指标对比
[0046][0047]
表2为rpc数据集在不同的自动结账算法的增量设置实验下的评价指标对比结果。其他方法的实验数据均来自于increaco。(183+17)表示使用lwf[li z,hoiem d.learning without forgetting[j].ieee transactions on pattern analysis and machine intelligence,2017,40(12):2935-2947.]方法进行增量训练。实验结果表明本发明的算法优于increaco算法,没有表现出明显的灾难性遗忘现象。183类训练在200类数据集上测试的cacc比在183类数据集上测试的cacc只降低了2.23%,而increaco的结果分别是31.23%和4.46%。
[0048]
表2rpc数据集的自动结账增量设置实验评价指标对比
[0049]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1