一种自顶向下的自然图像恰可察觉失真阈值估计方法
1.本发明涉及一种自然图像恰可察觉失真(just noticeable distortion,jnd)阈值估计技术,尤其是涉及一种自顶向下的自然图像恰可察觉失真阈值估计方法,其基于自顶向下的设计思路,并利用klt(karhunen-lo
é
ve transform)变换技术,实现自然图像的恰可察觉失真阈值估计。
背景技术:
2.恰可察觉失真(just noticeable distortion,jnd)是指人类视觉系统(human visual system,hvs)所无法感知的视觉信号最大变化幅值。它反映了人类视觉系统(hvs)对于视觉信息变化的敏感性和视觉信号中潜在的感知冗余。这使得它在许多图像/视频感知处理等任务中都具有广泛的应用,包括图像/视频压缩、图像/视频增强、信息隐藏以及图像/视频评价等。正是由于它广泛的应用,因此自然图像的恰可察觉失真(jnd)阈值估计得到了广泛关注与研究。
3.现有的恰可察觉失真(jnd)阈值估计模型可以分成两大类:基于像素域的恰可察觉失真(jnd)阈值估计模型和基于变换域的恰可察觉失真(jnd)阈值估计模型。基于像素域的恰可察觉失真(jnd)阈值估计模型主要考虑亮度适应性(luminance adaption,la)、对比度掩蔽(contrast masking,cm)和模式复杂度(pattern complexity,pc)等因素。基于变换域的恰可察觉失真(jnd)阈值估计模型将图像转换至一个特定的变换域,并估计对于每一个子带的恰可察觉失真(jnd)阈值,其主要考虑对比度敏感度函数(contrast sensitivity function,csf)等因素。从设计思路上来看,现有的基于像素域的恰可察觉失真(jnd)阈值估计模型与基于变换域的恰可察觉失真(jnd)阈值估计模型大体上是相同的,具体而言,首先对具有不同影响的视觉掩蔽效应(如la、cm、pc、csf)进行建模,然后将不同的视觉掩蔽效应模型进行融合得到最终的恰可察觉失真(jnd)阈值估计模型。这样的设计思路可以被视为是一种自底向上的策略,即从底部有贡献的若干影响因素开始考虑推导得到最终的恰可察觉失真(jnd)阈值估计模型。然而,这样的设计思路存在一些固有的局限:首先,由于缺乏对人类视觉系统(hvs)特性的深层次全面认知,因此很难将所有潜在相关的影响因素全部考虑进来;第二,被考虑进来的影响因素也往往很难准确地通过简单的数学模型进行刻画;第三,不同的影响因素之间的相互关系也很难进行建模。因此,现有的恰可察觉失真(jnd)阈值估计模型往往难以取得令人满意的效果,尽管人们可以通过实验发掘更多的影响因素和与之对应的视觉掩蔽效应,同时以更准确的数学模型对它们进行建模,但是这样的工作是无止尽的。因此,如何同时克服以上这些缺点,设计一个更为先进的恰可察觉失真(jnd)阈值估计模型具有十分重要的意义。
技术实现要素:
4.本发明所要解决的技术问题是提供一种自顶向下的自然图像恰可察觉失真阈值估计方法,其能够很好地反映人类视觉系统的视觉掩蔽特性,并能够很好地刻画自然图像
的视觉感知冗余度,进而能够为各种视觉信号感知处理任务提供有效指导。
5.本发明解决上述技术问题所采用的技术方案为:一种自顶向下的自然图像恰可察觉失真阈值估计方法,其特征在于包括以下步骤:
6.步骤1:将待处理的一幅自然图像作为源图像;然后将源图像转换为灰度图像,记为iy;其中,源图像为rgb彩色图像,源图像和iy的宽度均为w且高度均为h;
7.步骤2:将iy分割成num个互不重叠的尺寸大小为的图像块;然后对iy中的每个图像块进行向量化处理,得到iy中的每个图像块对应的列向量,将iy中的第n个图像块对应的列向量记为xn;再将iy中的所有图像块对应的列向量拼接构成一个向量化矩阵,记为x,x=[x1,x2,
…
,xn,
…
,x
num
];其中,设定w和h均能够被整除,k的取值为42或52或62或72或82或92或102,1≤n≤num,x1表示iy中的第1个图像块对应的列向量,x2表示iy中的第2个图像块对应的列向量,x
num
表示iy中的第num个图像块对应的列向量,x1、x2、xn、x
num
的维数均为k
×
1,x的维数为k
×
num,符号“[]”为向量或矩阵的表示形式;
[0008]
步骤3:计算x的协方差矩阵,记为c;然后利用特征值分解技术对c进行处理,得到c的k个特征值和对应的k个特征向量;接着对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序,将c的k个特征向量按其排序结果构成的矩阵作为从x中提取到的先验信息;其中,c的维数为k
×
k,特征向量为列向量,特征向量的维数为k
×
1,从x中提取到的先验信息中的每一列为c的1个特征向量,从x中提取到的先验信息的维数为k
×
k;
[0009]
步骤4:将从x中提取到的先验信息作为iy的klt核,记为p;然后根据p和x,计算iy的klt系数矩阵,记为q,q=(p)
t
x;再将q表示为q=[q1,q2,
…
,qk,
…
,qk]
t
;其中,p的维数为k
×
k,q的维数为k
×
num,1≤k≤k,q1表示q中的第1维klt谱分量,q2表示q中的第2维klt谱分量,qk表示q中的第k维klt谱分量,qk表示q中的第k维klt谱分量,q1、q2、qk、qk的维数均为num
×
1;
[0010]
步骤5:计算q中的每一维klt谱分量的klt系数能量,将qk的klt系数能量记为ek,然后计算q中的每一维klt谱分量的归一化klt系数能量,将qk的归一化klt系数能量记为归一化klt系数能量记为再计算q中的每一维klt谱分量的累积归一化klt系数能量,将qk的累积归一化klt系数能量记为的累积归一化klt系数能量记为最后将q中的所有klt谱分量的累积归一化klt系数能量组成累积归一化klt系数能量向量,记为e
cum
,其中,qk(n)表示qk中的第n个元素的值,1≤ζ≤k,e
ζ
表示q中的第ζ维klt谱分量q
ζ
的klt系数能量,表示q1的归一化klt系数能量,表示q2的归一化klt系数能量,e
cum
的维数为1
×
k,表示q1的累积归一化klt系数能量,表示q2的累积归一化klt系数能量,表示qk的累积归一化klt系数能量;
[0011]
步骤6:将e
cum
作为输入代入感知无失真临界点计算模型中,计算得到iy的感知无失真临界点,记为l;然后根据l构建感知无失真系数重建矩阵,记为失真临界点,记为l;然后根据l构建感知无失真系数重建矩阵,记为接着采用重建得到感知无失真系数矩阵,记为重建得到感知无失真系数矩阵,记为再将表示为其中,l为正整数,1≤l≤k,的维数为k
×
num,中的“=”为赋值符号,q
l
表示q中的第l维klt谱分量,q
l
的维数为num
×
1,至均为全0向量,的维数均为num
×
1,的维数为k
×
num,表示中的第1维感知无失真系数向量,表示中的第2维感知无失真系数向量,表示中的第n维感知无失真系数向量,表示中的第num维感知无失真系数向量,的维数均为k
×
1;
[0012]
步骤7:按步骤2中的向量化处理的逆操作,将中的每一维感知无失真系数向量转换成尺寸大小为的图像块,将转换成的图像块作为第n个图像块;然后将中的所有感知无失真系数向量转换成的图像块拼接成图像作为感知无失真临界图像,记为i
l
;再根据iy和i
l
,计算恰可察觉失真阈值图,记为m,将m中坐标位置为(a,b)的像素点的像素值记为m(a,b),m(a,b)=|iy(a,b)-i
l
(a,b)|;其中,1≤a≤w,1≤b≤h,iy(a,b)表示iy中坐标位置为(a,b)的像素点的像素值,i
l
(a,b)表示i
l
中坐标位置为(a,b)的像素点的像素值,符号“| |”为取绝对值符号。
[0013]
所述的步骤2中,xn的获取过程为:按z字型扫描方式将iy中的第n个图像块中的所有像素点的像素值排列成一列构成xn。
[0014]
所述的步骤3中,c的计算公式为:其中,上标“t”表示向量或矩阵的转置,表示对x按行取均值得到的均值向量,表示对x按行取均值得到的均值向量,的维数为k
×
1。
[0015]
所述的步骤4中,p=[p1,p2,
…
,pk],其中,p1表示对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序后的第1个特征向量,p2表示对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序后的第2个特征向量,pk表示对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序后的第k个特征向量,p1、p2、pk的维数均为k
×
1。
[0016]
所述的步骤6中,感知无失真临界点计算模型的获取过程为:
[0017]
步骤6_1:选取s幅高清图像,将每幅高清图像转换为灰度图像;然后按照步骤2至步骤4的过程,以相同的方式获取每幅高清图像的灰度图像的klt系数矩阵,将第i幅高清图像的灰度图像的klt系数矩阵记为q'i,将q'i表示为q'i=[q'
i,1
,q'
i,2
,
…
,q'
i,k
,
…
,q'
i,k
]
t
;其中,s≥100,高清图像为rgb彩色图像,高清图像的宽度为w'且高度为h',w'和h'均能够被
整除,高清图像的灰度图像分割的图像块的尺寸大小为1≤i≤s,q'i的维数为k
×
num',num'表示高清图像的灰度图像分割的图像块的总个数,q'
i,1
表示q'i中的第1维klt谱分量,q'
i,2
表示q'i中的第2维klt谱分量,q'
i,k
表示q'i中的第k维klt谱分量,q'
i,k
表示q'i中的第k维klt谱分量,q'
i,1
、q'
i,2
、q'
i,k
、q'
i,k
的维数均为num'
×
1;
[0018]
步骤6_2:构建每幅高清图像的灰度图像对应的k个感知系数重建矩阵,将第i幅高清图像的灰度图像对应的第k个感知系数重建矩阵记为清图像的灰度图像对应的第k个感知系数重建矩阵记为然后重建每幅高清图像的灰度图像对应的k个感知系数矩阵,将第i幅高清图像的灰度图像对应的第k个感知系数矩阵记为将表示为其中,的维数为k
×
num',num',中的“=”为赋值符号,至均为全0向量,均为全0向量,的维数均为num'
×
1,的维数为k
×
num',p'i表示第i幅高清图像的灰度图像的klt核,p'i的维数为k
×
k,1≤n'≤num',n'为正整数,表示中的第1维感知系数向量,表示中的第2维感知系数向量,表示中的第n'维感知系数向量,表示中的第num'维感知系数向量,的维数均为k
×
1;
[0019]
步骤6_3:按步骤2中的向量化处理的逆操作,将每幅高清图像的灰度图像对应的每个感知系数矩阵中的每一维感知系数向量转换成尺寸大小为的图像块;然后将每幅高清图像的灰度图像对应的每个感知系数矩阵中的所有感知系数向量转换成的图像块拼接成一幅图像,将第i幅高清图像的灰度图像对应的第k个感知系数矩阵中的所有感知系数向量转换成的图像块拼接成的图像作为第i幅高清图像的灰度图像对应的第k幅重建图像,记为其中,的宽度为w'且高度为h';
[0020]
步骤6_4:召集d位志愿者,每位志愿者以肉眼观察的方式依次对比每幅高清图像的灰度图像与其对应的各幅重建图像,每位志愿者从每幅高清图像的灰度图像对应的k幅重建图像中确定一幅重建图像作为该灰度图像对应的感知无失真临界图像,同时将确定的重建图像的序号作为该灰度图像对应的感知无失真临界点;对于第d位志愿者及第i幅高清图像的灰度图像,第d位志愿者以肉眼观察的方式依次对比第i幅高清图像的灰度图像与其
对应的第1幅重建图像、第2幅重建图像、
……
、第k幅重建图像,一旦第d位志愿者无法区分第i幅高清图像的灰度图像与其对应的其中一幅重建图像时停止对比过程,假设该幅重建图像为第i幅高清图像的灰度图像对应的第k幅重建图像那么将作为第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界图像,同时将数值k作为第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,记为第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,记为然后将所有志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点构成的向量记为ji,其中,d>1,1≤d≤d,中的“=”为赋值符号,ji的维数为1
×
d,表示第1位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,表示第2位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,表示第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点;
[0021]
步骤6_5:计算所有志愿者观察下每幅高清图像的灰度图像对应的感知无失真临界点构成的向量中的所有感知无失真临界点的均值和标准差,将ji中的所有感知无失真临界点的均值和标准差对应记为和然后在所有志愿者观察下每幅高清图像的灰度图像对应的感知无失真临界点构成的向量中剔除离群值,对于ji,若不满足则判定为离群值,将从ji中剔除,将剔除离群值后得到的向量记为
[0022]
步骤6_6:计算所有志愿者观察下每幅高清图像的灰度图像对应的感知无失真临界点构成的向量剔除离群值后所有感知无失真临界点的均值,将中的所有感知无失真临界点的均值记为然后获取每幅高清图像的灰度图像对应的感知无失真临界点,将第i幅高清图像的灰度图像对应的感知无失真临界点记为ji,其中,符号为向上取整运算符号;
[0023]
步骤6_7:计算每幅高清图像的灰度图像的klt系数矩阵中的每一维klt谱分量的klt系数能量,将q'i中的q'
i,k
的klt系数能量记为u
i,k
,然后计算每幅高清图像的灰度图像的klt系数矩阵中的每一维klt谱分量的归一化klt系数能量,将q'i中的q'
i,k
的归一化klt系数能量记为的归一化klt系数能量记为再计算每幅高清图像的灰度图像对应的感知无失真临界点处的累积归一化klt系数能量,将第i幅高清图像的灰度图像对应的感知无失真临界点ji处的累积归一化klt系数能量记为
最后将所有高清图像的灰度图像对应的感知无失真临界点处的累积归一化klt系数能量构成一个向量,记为u
cum
,其中,q'
i,k
(n')表示q'
i,k
中的第n'个元素的值,1≤ζ≤k,u
i,ζ
表示q'i中的第ζ维klt谱分量q'
i,ζ
的klt系数能量,表示q'i中的q'
i,1
的归一化klt系数能量,表示q'i中的q'
i,2
的归一化klt系数能量,表示q'i中的的归一化klt系数能量,表示q'i中的第ji维klt谱分量,u
cum
的维数为1
×
s,表示第1幅高清图像的灰度图像对应的感知无失真临界点j1处的累积归一化klt系数能量,表示第2幅高清图像的灰度图像对应的感知无失真临界点j2处的累积归一化klt系数能量,表示第s幅高清图像的灰度图像对应的感知无失真临界点js处的累积归一化klt系数能量;
[0024]
步骤6_8:计算u
cum
中的所有累积归一化klt系数能量的均值和标准差,对应记为和然后根据和得到感知无失真临界点计算模型,描述为:其中,l表示iy的感知无失真临界点。
[0025]
所述的步骤6_1中,q'i的获取过程为:
[0026]
步骤6_1a:将第i幅高清图像的灰度图像记为i'
y,i
;接着将i'
y,i
分割成num'个互不重叠的尺寸大小为的图像块;然后对i'
y,i
中的每个图像块进行向量化处理,得到i'
y,i
中的每个图像块对应的列向量,将i'
y,i
中的第n'个图像块对应的列向量记为x'
i,n'
;再将i'
y,i
中的所有图像块对应的列向量拼接构成一个向量化矩阵,记为x'i,x'i=[x'
i,1
,x'
i,2
,
…
,x'
i,n'
,
…
,x'
i,num'
];其中,k的取值为42或52或62或72或82或92或102,1≤n'≤num',x'
i,1
表示i'
y,i
中的第1个图像块对应的列向量,x'
i,2
表示i'
y,i
中的第2个图像块对应的列向量,x'
i,num'
表示i'
y,i
中的第num'个图像块对应的列向量,x'
i,1
、x'
i,2
、x'
i,n'
、x'
i,num'
的维数均为k
×
1,x'i的维数为k
×
num';
[0027]
步骤6_1b:计算x'i的协方差矩阵,记为c'i;然后利用特征值分解技术对c'i进行处理,得到c'i的k个特征值和对应的k个特征向量;接着对c'i的k个特征向量按对应的k个特征值从大到小的降序方式进行排序,将c'i的k个特征向量按其排序结果构成的矩阵作为从x'i中提取到的先验信息;其中,c'i的维数为k
×
k,特征向量为列向量,特征向量的维数为k
×
1,从x'i中提取到的先验信息中的每一列为c'i的1个特征向量,从x'i中提取到的先验信息的维数为k
×
k;
[0028]
步骤6_1c:将从x'i中提取到的先验信息作为i'
y,i
的klt核,记为p'i;然后根据p'i和x'i,计算i'
y,i
的klt系数矩阵q'i,q'i=(p'i)
t
x'i;其中,p'i的维数为k
×
k,q'i的维数为k
×
num'。
[0029]
与现有技术相比,本发明的优点在于:
[0030]
1)本发明方法从恰可察觉失真的定义出发,将恰可察觉失真阈值估计问题转换成感知无失真临界图像的估计问题,感知无失真临界图像是指人类视觉系统恰好无法察觉失真的失真图像,感知无失真临界图像与源图像相比仍然是失真的,但从感知的层面上来讲其失真是不能被人眼察觉的,因此,可以将源图像减去感知无失真临界图像得到源图像对应的恰可察觉失真阈值图,这种方式可以有效避免传统的恰可察觉失真阈值估计模型复杂且不准确的hvs视觉掩蔽因素建模及其融合所带来的误差,从而能够更准确地反映人类视觉系统的视觉掩蔽特性和刻画自然图像的视觉感知冗余度,进而能够为各种视觉信号感知处理任务提供有效指导。利用本发明方法估计得到的恰可察觉失真阈值图进行引导图像加噪和jpeg压缩,在保持主观感知质量几乎完全一致的前提下,采用本发明方法可以隐藏更多的噪声和节省更多的比特率。
[0031]
2)本发明方法利用klt变换技术估计源图像的感知无失真临界图像,不依赖于特定的图像处理任务,具有更好的普适性。首先对源图像进行klt变换,根据累积归一化klt系数能量的收敛特性找到源图像的感知无失真临界点,在感知无失真临界点的条件下,进行klt逆变换即可重建得到源图像的感知无失真临界图像,以这种方式得到的感知无失真临界图像具有普遍性,可以很好地应用于不同的视觉信息感知处理任务中。
附图说明
[0032]
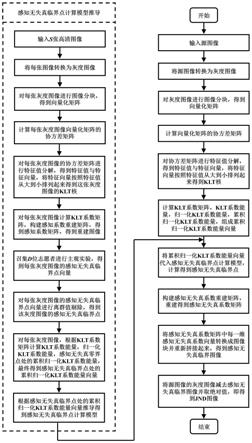
图1为本发明方法的总体流程框图;
[0033]
图2a为第1幅源图像img1;
[0034]
图2b为第2幅源图像img2;
[0035]
图2c为第3幅源图像img3;
[0036]
图2d为第4幅源图像img4;
[0037]
图2e为图2a、图2b、图2c、图2d各自对应的累积归一化klt系数能量曲线;
[0038]
图3a为源图像i03;
[0039]
图3b为采用本发明方法对图3a所示的源图像进行处理得到的恰可察觉失真阈值图;
[0040]
图3c为使用图3b引导生成的在psnr=26db条件下的加噪图像;
[0041]
图3d为图3c中框内部分的放大图;
[0042]
图4a为源图像i01直接采用jepg压缩的结果;
[0043]
图4b为源图像i01采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩结果;
[0044]
图4c为源图像i01采用wu2017方法得到的恰可察觉失真阈值图引导的jpeg压缩结果;
[0045]
图5为本发明方法与wu2017方法的增益gain平均值随着质量因子qp的变化曲线。
具体实施方式
[0046]
以下结合附图实施例对本发明作进一步详细描述。
[0047]
本发明提出的一种自顶向下的自然图像恰可察觉失真阈值估计方法,其总体流程
框图如图1所示,其包括以下步骤:
[0048]
步骤1:将待处理的一幅自然图像作为源图像;然后将源图像转换为灰度图像,记为iy;其中,源图像为rgb彩色图像,源图像和iy的宽度均为w且高度均为h,iy中坐标位置为(a,b)的像素点的像素值iy(a,b)的计算公式为:iy(a,b)=0.299ir(a,b)+0.587ig(a,b)+0.114ib(a,b),1≤a≤w,1≤b≤h,ir(a,b)表示源图像的红色通道中坐标位置为(a,b)的像素点的像素值,ig(a,b)表示源图像的绿色通道中坐标位置为(a,b)的像素点的像素值,ib(a,b)表示源图像的蓝色通道中坐标位置为(a,b)的像素点的像素值。
[0049]
步骤2:将iy分割成num个互不重叠的尺寸大小为的图像块;然后对iy中的每个图像块进行向量化处理,得到iy中的每个图像块对应的列向量,将iy中的第n个图像块对应的列向量记为xn;再将iy中的所有图像块对应的列向量拼接构成一个向量化矩阵,记为x,x=[x1,x2,
…
,xn,
…
,x
num
];其中,设定w和h均能够被整除,k的取值为42或52或62或72或82或92或102,一般情况下取82,1≤n≤num,x1表示iy中的第1个图像块对应的列向量,x2表示iy中的第2个图像块对应的列向量,x
num
表示iy中的第num个图像块对应的列向量,x1、x2、xn、x
num
的维数均为k
×
1,x的维数为k
×
num,符号“[]”为向量或矩阵的表示形式。
[0050]
在本实施例中,步骤2中,xn的获取过程为:按z字型扫描方式将iy中的第n个图像块中的所有像素点的像素值排列成一列构成xn。
[0051]
在图像处理领域中,对图像块进行向量化处理为常规技术手段,即将图像块中的所有像素点的像素值按一定的顺序(如按行扫描的顺序,先扫描第一行,再扫描第二行,依此类推,即z字型扫描方式)排列构成一个列向量;多个列向量拼接成向量化矩阵时,可按图像块的先后顺序来拼接,如向量化矩阵的第1列为第1个图像块对应的列向量,向量化矩阵的最后一列为第num个图像块对应的列向量。
[0052]
步骤3:计算x的协方差矩阵,记为c;然后利用现有的特征值分解技术对c进行处理,得到c的k个特征值和对应的k个特征向量;接着对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序,将c的k个特征向量按其排序结果构成的矩阵作为从x中提取到的先验信息;其中,c的维数为k
×
k,特征向量为列向量,特征向量的维数为k
×
1,从x中提取到的先验信息中的每一列为c的1个特征向量,从x中提取到的先验信息的维数为k
×
k。
[0053]
在本实施例中,步骤3中,c的计算公式为:其中,上标“t”表示向量或矩阵的转置,表示对x按行取均值得到的均值向量,表示对x按行取均值得到的均值向量,的维数为k
×
1。
[0054]
步骤4:将从x中提取到的先验信息作为iy的klt(karhunen-lo
é
ve transform)核,记为p;然后根据p和x,计算iy的klt系数矩阵,记为q,q=(p)
t
x;再将q表示为q=[q1,q2,
…
,qk,
…
,qk]
t
;其中,p的维数为k
×
k,q的维数为k
×
num,1≤k≤k,q1表示q中的第1维klt谱分量,q2表示q中的第2维klt谱分量,qk表示q中的第k维klt谱分量,qk表示q中的第k维klt谱分
量,q1、q2、qk、qk的维数均为num
×
1。
[0055]
在本实施例中,步骤4中,p=[p1,p2,
…
,pk],其中,p1表示对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序后的第1个特征向量,p2表示对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序后的第2个特征向量,pk表示对c的k个特征向量按对应的k个特征值从大到小的降序方式进行排序后的第k个特征向量,p1、p2、pk的维数均为k
×
1。
[0056]
步骤5:计算q中的每一维klt谱分量的klt系数能量,将qk的klt系数能量记为ek,然后计算q中的每一维klt谱分量的归一化klt系数能量,将qk的归一化klt系数能量记为归一化klt系数能量记为再计算q中的每一维klt谱分量的累积归一化klt系数能量,将qk的累积归一化klt系数能量记为的累积归一化klt系数能量记为最后将q中的所有klt谱分量的累积归一化klt系数能量组成累积归一化klt系数能量向量,记为e
cum
,其中,qk(n)表示qk中的第n个元素的值,1≤ζ≤k,e
ζ
表示q中的第ζ维klt谱分量q
ζ
的klt系数能量,表示q1的归一化klt系数能量,表示q2的归一化klt系数能量,e
cum
的维数为1
×
k,表示q1的累积归一化klt系数能量,表示q2的累积归一化klt系数能量,表示qk的累积归一化klt系数能量;图2a给出了第1幅源图像img1,图2b给出了第2幅源图像img2,图2c给出了第3幅源图像img3,图2d给出了第4幅源图像img4,图2e给出了图2a、图2b、图2c、图2d各自对应的累积归一化klt系数能量曲线。从图2e中可以看见,第1维klt谱分量的累积归一化klt系数能量是最大的,并且累积归一化klt系数能量随着klt谱分量索引的增加而增加。随着klt谱分量索引的增加,累积归一化klt系数能量逐渐趋向于饱和,最终变成1。不同图像对应的累积归一化klt系数能量曲线虽然有相同的趋势但并不完全一致。
[0057]
步骤6:将e
cum
作为输入代入感知无失真临界点计算模型中,计算得到iy的感知无失真临界点,记为l;然后根据l构建感知无失真系数重建矩阵,记为失真临界点,记为l;然后根据l构建感知无失真系数重建矩阵,记为接着采用重建得到感知无失真系数矩阵,记为重建得到感知无失真系数矩阵,记为再将表示为其中,l为正整数,1≤l≤k,的维数为k
×
num,中的“=”为赋值符号,q
l
表示q中的第l维klt谱分量,q
l
的维数为num
×
1,至均为全0向量,的维数均为num
×
1,的维数为k
×
num,表示中的第1维感知无失真系数向量,表示中的第2维感知无失真系数向量,表示中的第n维感知无失真
系数向量,表示中的第num维感知无失真系数向量,的维数均为k
×
1。
[0058]
在本实施例中,步骤6中,感知无失真临界点计算模型的获取过程为:
[0059]
步骤6_1:选取s幅高清图像,将每幅高清图像转换为灰度图像;然后按照步骤2至步骤4的过程,以相同的方式获取每幅高清图像的灰度图像的klt系数矩阵,将第i幅高清图像的灰度图像的klt系数矩阵记为q'i,将q'i表示为q'i=[q'
i,1
,q'
i,2
,
…
,q'
i,k
,
…
,q'
i,k
]
t
;其中,s≥100,在实验中可取s=500,高清图像为rgb彩色图像,高清图像的宽度为w'且高度为h',w'和h'均能够被整除,高清图像的灰度图像分割的图像块的尺寸大小为1≤i≤s,q'i的维数为k
×
num',num'表示高清图像的灰度图像分割的图像块的总个数,q'
i,1
表示q'i中的第1维klt谱分量,q'
i,2
表示q'i中的第2维klt谱分量,q'
i,k
表示q'i中的第k维klt谱分量,q'
i,k
表示q'i中的第k维klt谱分量,q'
i,1
、q'
i,2
、q'
i,k
、q'
i,k
的维数均为num'
×
1。
[0060]
在本实施例中,步骤6_1中,q'i的获取过程为:
[0061]
步骤6_1a:将第i幅高清图像的灰度图像记为i'
y,i
;接着将i'
y,i
分割成num'个互不重叠的尺寸大小为的图像块;然后对i'
y,i
中的每个图像块进行向量化处理,得到i'
y,i
中的每个图像块对应的列向量,将i'
y,i
中的第n'个图像块对应的列向量记为x'
i,n'
;再将i'
y,i
中的所有图像块对应的列向量拼接构成一个向量化矩阵,记为x'i,x'i=[x'
i,1
,x'
i,2
,
…
,x'
i,n'
,
…
,x'
i,num'
];其中,k的取值为42或52或62或72或82或92或102,一般情况下取82,1≤n'≤num',x'
i,1
表示i'
y,i
中的第1个图像块对应的列向量,x'
i,2
表示i'
y,i
中的第2个图像块对应的列向量,x'
i,num'
表示i'
y,i
中的第num'个图像块对应的列向量,x'
i,1
、x'
i,2
、x'
i,n'
、x'
i,num'
的维数均为k
×
1,x'i的维数为k
×
num'。
[0062]
步骤6_1b:计算x'i的协方差矩阵,记为c'i;然后利用现有的特征值分解技术对c'i进行处理,得到c'i的k个特征值和对应的k个特征向量;接着对c'i的k个特征向量按对应的k个特征值从大到小的降序方式进行排序,将c'i的k个特征向量按其排序结果构成的矩阵作为从x'i中提取到的先验信息;其中,c'i的维数为k
×
k,特征向量为列向量,特征向量的维数为k
×
1,从x'i中提取到的先验信息中的每一列为c'i的1个特征向量,从x'i中提取到的先验信息的维数为k
×
k。
[0063]
步骤6_1c:将从x'i中提取到的先验信息作为i'
y,i
的klt核,记为p'i;然后根据p'i和x'i,计算i'
y,i
的klt系数矩阵q'i,q'i=(p'i)
t
x'i;其中,p'i的维数为k
×
k,q'i的维数为k
×
num'。
[0064]
步骤6_2:构建每幅高清图像的灰度图像对应的k个感知系数重建矩阵,将第i幅高清图像的灰度图像对应的第k个感知系数重建矩阵记为清图像的灰度图像对应的第k个感知系数重建矩阵记为然后重建每幅高清图像的灰度图像对应的
k个感知系数矩阵,将第i幅高清图像的灰度图像对应的第k个感知系数矩阵记为将表示为其中,的维数为k
×
num',num',中的“=”为赋值符号,至均为全0向量,均为全0向量,的维数均为num'
×
1,的维数为k
×
num',p'i表示第i幅高清图像的灰度图像的klt核,p'i的维数为k
×
k,1≤n'≤num',n'为正整数,表示中的第1维感知系数向量,表示中的第2维感知系数向量,表示中的第n'维感知系数向量,表示中的第num'维感知系数向量,的维数均为k
×
1。
[0065]
步骤6_3:按步骤2中的向量化处理的逆操作,将每幅高清图像的灰度图像对应的每个感知系数矩阵中的每一维感知系数向量转换成尺寸大小为的图像块;然后按步骤2中图像块分割时的先后顺序将每幅高清图像的灰度图像对应的每个感知系数矩阵中的所有感知系数向量转换成的图像块拼接成一幅图像,将第i幅高清图像的灰度图像对应的第k个感知系数矩阵中的所有感知系数向量转换成的图像块拼接成的图像作为第i幅高清图像的灰度图像对应的第k幅重建图像,记为其中,的宽度为w'且高度为h'。
[0066]
步骤6_4:召集d位志愿者,每位志愿者以肉眼观察的方式依次对比每幅高清图像的灰度图像与其对应的各幅重建图像,每位志愿者从每幅高清图像的灰度图像对应的k幅重建图像中确定一幅重建图像作为该灰度图像对应的感知无失真临界图像,同时将确定的重建图像的序号作为该灰度图像对应的感知无失真临界点;对于第d位志愿者及第i幅高清图像的灰度图像,第d位志愿者以肉眼观察的方式依次对比第i幅高清图像的灰度图像与其对应的第1幅重建图像、第2幅重建图像、
……
、第k幅重建图像,一旦第d位志愿者无法区分第i幅高清图像的灰度图像与其对应的其中一幅重建图像时停止对比过程,假设该幅重建图像为第i幅高清图像的灰度图像对应的第k幅重建图像那么将作为第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界图像,同时将数值k作为第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,记为第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,记为然后将所有志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点构成的向量记为ji,其中,d>1,在实验中可取d=30,1≤d≤d,中的“=”为赋值符号,ji的维数为1
×
d,表示第1位志愿者观察下第i幅高清图像的灰度
图像对应的感知无失真临界点,表示第2位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点,表示第d位志愿者观察下第i幅高清图像的灰度图像对应的感知无失真临界点。
[0067]
步骤6_5:计算所有志愿者观察下每幅高清图像的灰度图像对应的感知无失真临界点构成的向量中的所有感知无失真临界点的均值和标准差,将ji中的所有感知无失真临界点的均值和标准差对应记为和然后在所有志愿者观察下每幅高清图像的灰度图像对应的感知无失真临界点构成的向量中剔除离群值,对于ji,若不满足则判定为离群值,将从ji中剔除,将剔除离群值后得到的向量记为
[0068]
步骤6_6:计算所有志愿者观察下每幅高清图像的灰度图像对应的感知无失真临界点构成的向量剔除离群值后所有感知无失真临界点的均值,将中的所有感知无失真临界点的均值记为然后获取每幅高清图像的灰度图像对应的感知无失真临界点,将第i幅高清图像的灰度图像对应的感知无失真临界点记为ji,其中,符号为向上取整运算符号。
[0069]
步骤6_7:计算每幅高清图像的灰度图像的klt系数矩阵中的每一维klt谱分量的klt系数能量,将q'i中的q'
i,k
的klt系数能量记为u
i,k
,然后计算每幅高清图像的灰度图像的klt系数矩阵中的每一维klt谱分量的归一化klt系数能量,将q'i中的q'
i,k
的归一化klt系数能量记为的归一化klt系数能量记为再计算每幅高清图像的灰度图像对应的感知无失真临界点处的累积归一化klt系数能量,将第i幅高清图像的灰度图像对应的感知无失真临界点ji处的累积归一化klt系数能量记为处的累积归一化klt系数能量记为最后将所有高清图像的灰度图像对应的感知无失真临界点处的累积归一化klt系数能量构成一个向量,记为u
cum
,其中,q'
i,k
(n')表示q'
i,k
中的第n'个元素的值,1≤ζ≤k,u
i,ζ
表示q'i中的第ζ维klt谱分量q'
i,ζ
的klt系数能量,表示q'i中的q'
i,1
的归一化klt系数能量,表示q'i中的q'
i,2
的归一化klt系数能量,表示q'i中的的归一化klt系数能量,表示q'i中的第ji维klt谱分量,u
cum
的维数为1
×
s,表示第1幅高清图像的灰度图像对应的感知无失真
临界点j1处的累积归一化klt系数能量,表示第2幅高清图像的灰度图像对应的感知无失真临界点j2处的累积归一化klt系数能量,表示第s幅高清图像的灰度图像对应的感知无失真临界点js处的累积归一化klt系数能量;
[0070]
步骤6_8:计算u
cum
中的所有累积归一化klt系数能量的均值和标准差,对应记为和然后根据和得到感知无失真临界点计算模型,描述为:其中,l表示iy的感知无失真临界点。
[0071]
步骤7:按步骤2中的向量化处理的逆操作,将中的每一维感知无失真系数向量转换成尺寸大小为的图像块,将转换成的图像块作为第n个图像块;然后按步骤2中图像块分割时的先后顺序将中的所有感知无失真系数向量转换成的图像块拼接成图像作为感知无失真临界图像,记为i
l
;再根据iy和i
l
,计算恰可察觉失真阈值图,记为m,将m中坐标位置为(a,b)的像素点的像素值记为m(a,b),m(a,b)=|iy(a,b)-i
l
(a,b)|;其中,1≤a≤w,1≤b≤h,iy(a,b)表示iy中坐标位置为(a,b)的像素点的像素值,i
l
(a,b)表示i
l
中坐标位置为(a,b)的像素点的像素值,符号“||”为取绝对值符号。
[0072]
为了进一步说明本发明方法的可行性和有效性,对本发明方法进行实验。
[0073]
第一部分实验是恰可察觉失真阈值估计模型引导的加噪图像生成实验。输入一张源图像,利用本发明方法获得对应的恰可察觉失真阈值图,对源图像的红色通道、绿色通道、蓝色通道分别进行恰可察觉失真阈值图引导加噪,将源图像的红色通道对应的加噪图像记为将中坐标位置为(a,b)的像素点的像素值记为中坐标位置为(a,b)的像素点的像素值记为将源图像的绿色通道对应的加噪图像记为将中坐标位置为(a,b)的像素点的像素值记为中坐标位置为(a,b)的像素点的像素值记为将源图像的蓝色通道对应的加噪图像记为将中坐标位置为(a,b)的像素点的像素值记为中坐标位置为(a,b)的像素点的像素值记为最终可以得到源图像的加噪图像;其中,1≤a≤w,1≤b≤h,ir(a,b)表示源图像的红色通道中坐标位置为(a,b)的像素点的像素值,m(a,b)表示恰可察觉失真阈值图中坐标位置为(a,b)的像素点的像素值,n(a,b)表示维数为w
×
h的随机二值矩阵中下标为(a,b)处的元素的值,n(a,b)为+1或-1,θ为噪声大小的调节参数,通过改变θ的值可以控制所注入的噪声量,ig(a,b)表示源图像的绿色通道中坐标位置为(a,b)的像素点的像素值,ib(a,b)表示源图像的蓝色通道中坐标位置为(a,b)的像素点的像素值。
[0074]
在此设置s=500、d=60、k=64,控制得到的源图像的加噪图像的psnr在26db左
右。psnr即峰值信噪比,是一种现有的图像质量评价指标。选取20幅源图像进行实验。用现有的6种jnd阈值图生成方法进行对比研究,6种jnd阈值图生成方法分别是:第1种,yang2005(x.yang,w.lin,z.lu,e.ong,and s.yao,“motion-compensated residue pre-processing in video coding based on just-noticeable-distortion profile,”ieee transactions on circuits and systems for video technology,vol.15,no.6,pp.742
–
752,2005.(基于恰可察觉失真模型的视频编码运动补偿残差预处理));第2种,zhang2005(x.zhang,w.lin,and p.xue,“improved estimation for just-noticeable visual distortion,”signal processing,vol.85,no.4,pp.795
–
808,2005.(恰可察觉视觉失真的改进估计));第3种,wu2013(j.wu,g.shi,w.lin,a.liu,and f.qi,“just noticeable difference estimation for images with free-energy principle,”ieee transactions on multimedia,vol.15,no.7,pp.1705
–
1710,2013.(依据自由能量原则的图像恰可察觉失真估计));第4种,wu2017(j.wu,l.li,w.dong,g.shi,w.lin,and c.-c.j.kuo,“enhanced just noticeable difference model for images with pattern complexity,”ieee transactions on image processing,vol.26,no.6,pp.2682
–
2693,2017.(依据模式复杂度的图像增强恰可察觉失真模型));第5种,jakhetiya2018(v.jakhetiya,w.lin,s.jaiswal,k.gu,and s.c.guntuku,“just noticeable difference for natural images using rms contrast and feed-back mechanism,”neurocomputing,vol.275,pp.366
–
376,2018.(依据rms对比度和反馈机制的自然图像恰可察觉失真));第6种,chen2020(z.chen and w.wu,“asymmetric foveated just-noticeable-difference model for images with visual field inhomogeneities,”ieee transactions on circuits and systems for video technology,vol.30,no.11,pp.4064
–
4074,2020.(依据视野不均匀性的图像非对称漏斗状的恰可察觉失真模型))。对于每幅源图像,利用本发明方法及现有的6种jnd阈值图生成方法分别得到恰可察觉失真阈值图;然后获取每幅源图像的加噪图像,即针对每幅源图像可以得到峰值信噪比近似相同的7幅加噪图像。
[0075]
表1利用本发明方法与现有的6种jnd阈值图生成方法后得到的加噪图像的实验对比
[0076]
[0077][0078]
召集30位志愿者,进行主观实验。要求每位志愿者比较每幅源图像及其相应的7幅加噪图像,并对加噪图像进行0到-1之间的评分,若评分为0,则表示加噪图像与源图像的视觉质量非常接近;若评分为-1,则表示加噪图像的视觉质量相比于源图像非常糟糕。每幅加噪图像均能收到30个评分,去除离群值后再取平均值即得到这幅加噪图像的主观评分,记为mos值,mos值越高代表加噪图像视觉质量越好。此外,运用已有的图像质量客观评价算法ms-ssim(z.wang,e.p.simoncelli,and a.c.bovik,“multiscale structural similarity for image quality assessment,”in the thrity-seventh asilomar conference on signals,systems computers,2003,vol.2,2003,pp.1398
–
1402vol.2.(多尺度结构相似度用于图像质量评价))对加噪图像进行质量评价,ms-ssim值越高代表加噪图像质量越好。对于每幅加噪图像的mos值与ms-ssim值列在表1中。
[0079]
在表1中,i01代表第1幅源图像,一共有20幅源图像参与实验,因此依次标记为i01至i20。图3a给出了源图像i03,图3b给出了采用本发明方法对图3a所示的源图像进行处理得到的恰可察觉失真阈值图,图3c给出了使用图3b引导生成的在psnr=26db条件下的加噪图像,图3d给出了图3c中框内部分的放大图,从图3d中可以看出几乎看不见噪声存在,视觉质量较好。如表1所示,采用本发明方法得到的恰可察觉失真阈值图引导生成的加噪图像无
论在单幅加噪图像的ms-ssim值上还是在ms-ssim平均值上均超过了采用其它方法得到的恰可察觉失真阈值图引导生成的加噪图像。在i12这幅源图像对应的加噪图像上,采用本发明方法得到的恰可察觉失真阈值图引导生成的加噪图像的mos值仅低于采用chen2020方法得到的恰可察觉失真阈值图引导生成的加噪图像,但高于采用其它方法得到的恰可察觉失真阈值图引导生成的加噪图像。并且在其他源图像对应的加噪图像上,采用本发明方法得到的恰可察觉失真阈值图引导生成的加噪图像的mos值与mos平均值均高于其它方法。这个实验说明,在保持加噪量一致的前提下,采用本发明方法得到的恰可察觉失真阈值图引导生成的加噪图像拥有更好的视觉效果,能将噪声引导注入至视觉所不易察觉的地方。因此,本发明方法能够更准确地反映hvs视觉掩蔽特性,刻画其视觉感知冗余度。
[0080]
第二部分实验是恰可察觉失真阈值图引导的jpeg压缩实验。
[0081]
依据jpeg压缩模型的要求,按照相同的顺序对源图像的红色通道、绿色通道、蓝色通道及利用本发明方法获得对应的恰可察觉失真阈值图进行图像块划分,将源图像的红色通道、绿色通道、蓝色通道及利用本发明方法获得对应的恰可察觉失真阈值图分别分割成个互不重叠的尺寸大小为8
×
8的图像块。
[0082]
以图像块为单位,对源图像的红色通道、绿色通道、蓝色通道分别进行恰可察觉失真阈值图引导的平滑处理。
[0083]
以图像块为单位,对源图像的红色通道中的第j个图像块进行恰可察觉失真阈值图中的第j个图像块引导的平滑处理的计算公式为:以图像块为单位,对源图像的绿色通道中的第j个图像块进行恰可察觉失真阈值图中的第j个图像块引导的平滑处理的计算公式为:以图像块为单位,对源图像的蓝色通道中的第j个图像块进行恰可察觉失真阈值图中的第j个图像块引导的平滑处理的计算公式为:其中,其中,表示源图像的红色通道中的第j个图像块经平滑处理后得到
的图像块中坐标位置为(a',b')的像素点的像素值,1≤a'≤8,1≤b'≤8,i
r,j
(a',b')表示源图像的红色通道中的第j个图像块中坐标位置为(a',b')的像素点的像素值,mj(a',b')表示恰可察觉失真阈值图中的第j个图像块中坐标位置为(a',b')的像素点的像素值,表示源图像的红色通道中的第j个图像块中的所有像素点的像素值的平均值,表示源图像的绿色通道中的第j个图像块经平滑处理后得到的图像块中坐标位置为(a',b')的像素点的像素值,i
g,j
(a',b')表示源图像的绿色通道中的第j个图像块中坐标位置为(a',b')的像素点的像素值,表示源图像的绿色通道中的第j个图像块中的所有像素点的像素值的平均值,表示源图像的蓝色通道中的第j个图像块经平滑处理后得到的图像块中坐标位置为(a',b')的像素点的像素值,i
b,j
(a',b')表示源图像的蓝色通道中的第j个图像块中坐标位置为(a',b')的像素点的像素值,表示源图像的蓝色通道中的第j个图像块中的所有像素点的像素值的平均值。平滑处理完成后,将图像块按照图像块分割时的顺序重新拼接回去得到平滑处理完的红色通道、绿色通道、蓝色通道,最终得到经过平滑处理后的平滑图像。
[0084]
设置质量因子(编码量化参数)qp=1,进行jpeg压缩。对输入的源图像进行jpeg压缩,得到源图像的jpeg压缩图像,计算源图像的jpeg压缩图像的压缩比特率和psnr值,对应记为bitrate1和psnr1;对源图像的平滑图像进行jpeg压缩,得到源图像的平滑图像的jpeg压缩图像,计算源图像的平滑图像的jpeg压缩图像的压缩比特率和psnr值,对应记为bitrate2和psnr2。计算比特率节省百分比和psnr损失百分比,对应记为δbitrate和δpsnr,psnr,然后计算增益,记为gain,δbitrate越大代表节省比特率越多,δpsnr越小代表psnr损失越少。若增益gain越大则代表损失尽可能少的psnr,换取尽可能大的压缩比特率节省,代表恰可察觉失真阈值图引导的图像压缩性能越好。
[0085]
表2采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩与采用wu2017方法得到的恰可察觉失真阈值图引导的jpeg压缩的实验对比
[0086][0087][0088]
在此设置s=500、d=60、k=64。选取在第一部分实验中所采用的20幅源图像进行实验,选取wu2017方法作为对比方法。图4a给出了源图像i01直接采用jepg压缩的结果,图4b给出了源图像i01采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩结果,图4c给出了源图像i01采用wu2017方法得到的恰可察觉失真阈值图引导的jpeg压缩结果。图4a、图4b、图4c各自中右边的框为对左边的框的局部放大。比较图4a、图4b、图4c中右边的框,可以看到源图像i01采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩结果的视觉效果与源图像i01直接采用jepg压缩的结果相近,其视觉质量几乎没有降低,但是源图像i01采用wu2017方法得到的恰可察觉失真阈值图引导的jpeg压缩结果却出现了非常明显的模糊,其视觉质量相较于源图像i01直接采用jepg压缩的结果相差较大。对于各源图像的实验数据如表2所示。可以看到采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩尽管在比特率节省方面低于wu2017方法,但是在psnr损失方面却少于wu2017方法。并且除了在i11源图像上,采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩增益gain稍弱于wu2017方法,在其它所有源图像上的增益gain以及增益gain的平均值上均强于wu2017方法。进一步地,改变质量因子qp值,并测试本发明方法与wu2017方法在20幅源图像
上的平均增益,画出折线图,如图5所示,可以看到在每一个qp值上,本发明方法的平均增益均高于wu2017方法。这个实验说明,采用本发明方法得到的恰可察觉失真阈值图引导的jpeg压缩在尽可能降低压缩比特率的前提下,能够尽可能地保证压缩后图像的视觉质量。因此,本发明方法能够更准确地反映hvs视觉掩蔽特性,刻画其视觉感知冗余度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1