任务执行方法、装置、电子设备及计算机存储介质与流程
1.本公开涉及计算机技术领域,尤其涉及云计算、大数据、计算机视觉、以及深度学习等人工智能技术领域。
背景技术:
2.随着计算机技术的发展,在深度学习、机器学习、图像处理、数据计算等多种场景边,计算机任务可拆分成多个子任务进行并行执行。然而任务执行处理时,可利用的资源数量有限,如何利用优先的资源更为快速、高效地执行任务,是需要不断改进的一个问题。
技术实现要素:
3.本公开提供了一种任务执行方法、装置、电子设备及计算机存储介质。
4.根据本公开的一方面,提供了一种任务执行方法,包括:
5.获取可用资源的信息;
6.根据可用资源的信息,确定执行目标任务的子任务的第一并行数量;
7.根据第一并行数量,调整子任务。
8.根据本公开的另一方面,提供了一种任务执行装置,包括:
9.资源信息获取模块,用于获取可用资源的信息;
10.第一并行数量确定模块,用于根据可用资源的信息,确定执行目标任务的子任务的第一并行数量;
11.调整模块,用于根据第一并行数量,调整子任务。
12.根据本公开的另一方面,提供了一种电子设备,包括:
13.至少一个处理器;以及
14.与该至少一个处理器通信连接的存储器;其中,
15.该存储器存储有可被该至少一个处理器执行的指令,该指令被该至少一个处理器执行,以使该至少一个处理器能够执行本公开任一实施例中的方法。
16.根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,该计算机指令用于使计算机执行本公开任一实施例中的方法。
17.根据本公开的另一方面,提供了一种计算机程序产品,包括计算机程序/指令,该计算机程序/指令被处理器执行时实现本公开任一实施例中的方法。
18.根据本公开的技术,能够确定可用资源的信息,根据可用资源的信息确定目标任务的子任务能够并行执行的数量,即第一并行数量,根据确定的第一并行数量调整子任务,从而,在各种计算机任务的执行场景下,能够根据可用资源实行子任务的并行数量的弹性伸缩调整,实现可用资源有效利用率的最大化,同时也能够利用可用资源将子任务执行速度调整至最大。
19.应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
附图说明
20.附图用于更好地理解本方案,不构成对本公开的限定。其中:
21.图1是根据本公开一实施例的任务执行方法示意图;
22.图2是根据本公开另一实施例的任务执行方法示意图;
23.图3是根据本公开一示例的任务执行方法示意图;
24.图4是根据本公开一示例的任务执行框架示意图;
25.图5是根据本公开一实施例的任务执行装置示意图;
26.图6是根据本公开另一实施例的任务执行装置示意图;
27.图7是根据本公开又一实施例的任务执行装置示意图;
28.图8是根据本公开又一实施例的任务执行装置示意图;
29.图9是根据本公开又一实施例的任务执行装置示意图;
30.图10是根据本公开又一实施例的任务执行装置示意图;
31.图11是根据本公开又一实施例的任务执行装置示意图;
32.图12是用来实现本公开实施例的任务执行方法的电子设备的框图。
具体实施方式
33.以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
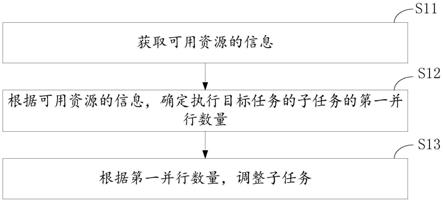
34.根据本公开的实施例,提供了一种任务执行方法,图1是根据本公开实施例的任务执行方法的流程示意图,该方法可以应用于任务执行装置,例如,该装置可以部署于终端或服务器或其它处理设备执行的情况下,可以执行可用资源信息的获取、并行数量的确定等步骤。其中,终端可以为用户设备(ue,user equipment)、移动设备、蜂窝电话、无绳电话、个人数字处理(pda,personal digital assistant)、手持设备、计算设备、车载设备、可穿戴设备等。在一些可能的实现方式中,该方法还可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。如图1所示,任务执行方法包括:
35.步骤s11:获取可用资源的信息;
36.步骤s12:根据可用资源的信息,确定执行目标任务的子任务的第一并行数量;
37.步骤s13:根据第一并行数量,调整子任务。
38.本实施例中,可用资源的信息,可以用于表示可用资源的数量,即可用资源的数量信息。具体可以表示可用资源所能够支持的子任务进行运行的数量。比如,当前可用资源足以共用1-10个子任务进行运行。
39.可用资源可以是用于运行子任务的资源。比如,内存、缓存、cpu(central processing unit,中央处理器)、磁盘、硬盘等软件资源、硬件资源中的至少一种。
40.本实施例中,目标任务可以是任意一种计算机处理任务或者计算机计算任务。比如图像处理、数据计算、数据传输、数据获取、数据存储、模型训练、机器学习、深度学习等中的至少任意一种。
41.目标任务可以是当前系统运行的多个任务之一,或者是当前系统即将新增的多个
任务之一。也可以是当前系统中唯一处于运行状态的任务,或者是当前系统即将新增的任务。
42.执行目标任务的子任务,可以是为实现目标任务而运行的至少一个任务。子任务的内容可以等同于目标任务本身,比如,在一种具体实现方式中,目标任务可以为机器学习任务,为了实现机器学习的目的,可同时启动至少一个子任务,每个子任务用于对至少一个机器学习模型进行训练,在完成训练之后,从至少一个子任务对应的至少一个机器学习模型中,选择训练效果最佳的模型,作为执行目标任务而得到的模型。
43.在另一种具体实现方式中,子任务也可以是目标任务拆分的多个部分。比如,目标任务包括不分先后顺序的多个步骤,每个步骤可构成一个子任务,在不区分先后顺序的多个步骤执行完毕后,根据各子任务的执行结果,得到最终的结果,作为目标任务的执行结果。
44.执行目标任务的子任务的第一并行数量,可以是现有的可用资源能够支持同时运行的子任务的数量。
45.根据第一并行数量,调整子任务,可以是调整子任务并行的数量,使得子任务并行的数量与第一并行数量相符合。
46.本实施例中,目标任务的子任务,可以是目标任务的至少一个子任务。在目标任务的子任务存在多个的情况下,多个子任务可以同属于一个类别,也可以属于不同类别。在目标任务的子任务不属于同一个类别的情况下,第一并行数量可以包括针对每个子类别可运行的子任务的数量。
47.在一种可能的实现方式中,目标任务的每个子任务可运行于一定的介质中,比如可在pod中运行。每个目标任务可以对应启动多个pod,每个pod中可运行至少一个容器(container),容器中可启动用于执行子任务的进程。
48.本公开实施例中,pod(就像在鲸鱼荚或者豌豆荚中)可以是一组(一个或多个)容器的持有模块或者运行模块;这些容器共享存储、网络、以及怎样运行这些容器的声明。pod中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。pod所建模的是特定于应用的“逻辑主机”,其中包含一个或多个应用容器,这些容器是相对紧密的耦合在一起的。在非云环境中,在相同的物理机或虚拟机上运行的应用类似于在同一逻辑主机上运行的云应用。
49.本公开实施例可应用于多种需要执行计算机相关处理任务的场景,比如,机器学习、深度学习等模型训练场景。
50.在机器学习场景下,传统的机器学习训练任务,通常需要大量的人工干预,主要体现在调优算法的选择,参数调节等方面。自动机器学习(automatic machine learning,automl)可以看作是构建了一系列高级的控制系统,来操作机器学习模型,使得模型可以自动化地学习到合适的参数并有良好的性能,同时无需人工的干预,完全自动化。
51.一般情况下,在自动机器学习过程中,对于单次automl任务,其任务的并发数量(并行数量)是事先固定的,比如可以是用户自己配置或是完全固定的参数。在大多数场景下,固定参数的实现比较简单,但是完全忽略了所处环境的资源因素,很难实现可用资源的最大利用。如果automl子任务的并发数量太少,automl任务可能会运行的非常慢,如果automl子任务的并发数量太多又可能导致automl任务因为集群资源不足而等待。
52.本实施例中,能够确定可用资源的信息,根据可用资源的信息确定目标任务的子任务能够并行执行的数量,即第一并行数量,根据确定的第一并行数量调整子任务,从而,在各种计算机任务的执行场景下,能够根据可用资源实行子任务的并行数量的弹性伸缩调整,实现可用资源有效利用率的最大化,同时也能够利用可用资源将子任务执行速度调整至最大。
53.在一种实施方式中,根据可用资源的信息,确定执行目标任务的子任务的第一并行数量,如图2所示,包括:
54.步骤s21:确定当前执行目标任务的子任务的第二并行数量;
55.步骤s22:在可用资源的信息表示能够增加新的子任务的情况下,按照预设的调整步长,上调第二并行数量;
56.步骤s23:将上调后的第二并行数量作为第一并行数量。
57.本实施例中,第二并行数量可以是目标任务所包括的处于运行状态的子任务的数量。
58.可用资源的信息表示能够增加新的子任务,可以是可用资源的信息比较充足,能够在第二并行数量的子任务的基础上,进一步运行更多数量的子任务。
59.按照预设的调整步长,上调第二并行数量,具体比如可以是在第二并行数量的基础上,增加调整步长。比如,调整步长为1,则在第二并行数量的基础上加1。
60.本实施例中,在根据可用资源的信息,能够增加新的子任务的情况下,按照预设的调整步长上调第二并行数量,从而避免一次性增加过多的子任务而导致可用资源骤然不足。
61.在一种实施方式中,根据可用资源的信息,确定执行目标任务的子任务的第一并行数量,包括:
62.在可用资源的信息表示不足以供当前数量的子任务使用的情况下,按照预设的调整步长,下调第二并行数量;
63.将下调后的第二并行数量作为第一并行数量。
64.在具体实现方式中,下调第二并行数量时的调整步长可以与上调第二并行数量时的调整步长相同或不同。
65.本实施例中,在可用资源不足时,可下调第二并行数量,从而避免始终采用同一种并行数量同时运行两个以上子任务而导致资源不足甚至导致子任务运行失败。
66.在另一种可能的实现方式中,可根据可用资源的信息,确定具体能够上调或下调的数据,从而不受步长限制,实现更为精准的调整。具体实现时,可在上调并行数量时,采用较为保守的数据估计策略,在可用资源较为充足的情况下,少量上调第二并行数量。在下调并行数量时,采用一般的数据估计策略,在资源较为不充足的情况下,将第二并行数量下调适量个数。
67.在一种可能的实现方式中,第一并行数量、第二并行数量均为正整数。
68.在一种具体的实现方式中,在可用资源的信息表示不足以供当前数量的子任务使用的情况下,按照预设的调整步长,下调第二并行数量,或者在可用资源的信息表示能够增加新的子任务的情况下,按照预设的调整步长,上调第二并行数量,可包括:直接确定第一并行数量,即可直接确定可用资源能够支持同时运行的子任务的数量,在第一并行数量和
第二并行数量不相等的情况下,确定上调或下调的第二并行数量。
69.在一种具体实现方式中,按照调整步长上调或下调第二并行数量,可以是按照设定的步长对第二并行数量执行一次调整,还可以是可执行多次调整直至满足设定条件。
70.在一种实施方式中,根据第一并行数量,调整子任务,包括:
71.在第一并行数量大于当前执行目标任务的子任务的第二并行数量的情况下,启动新的子任务。
72.本实施例中,在确定可增加子任务的情况下,直接启动新的子任务,从而根据可用资源情况实时新增子任务,提高可用资源的利用率。
73.在一种实施方式中,根据第一并行数量,调整子任务,包括:
74.在第一并行数量小于当前执行目标任务的子任务的第二并行数量的情况下,待当前执行目标任务的子任务运行完毕之后,根据第一并行数量启动新的子任务。
75.本实施例中,当前执行目标任务的子任务运行完毕,可以当前执行的子任务中至少一个子任务运行完毕,也可以当前执行的所有子任务均执行完毕。
76.待当前执行目标任务的子任务运行完毕之后,根据第一并行数量启动新的子任务,可以是在前执行目标任务的子任务中一个子任务运行完毕之后,拒绝启动新的子任务直至剩余子任务的数量小于第二并行数量。
77.待当前执行目标任务的子任务运行完毕之后,根据第一并行数量启动新的子任务,还可以是在当前执行目标任务的所有子任务均运行完毕之后,按照第二并行数量,重新启动至少一个目标任务的子任务。
78.本实施例中,能够在确定需要减少子任务的并行数量的情况下,仍然允许当前运行的子任务继续运行,从而避免子任务重复执行而使得调整并行数量无法起到提高资源利用率的效果。
79.在一种实施方式中,任务执行方法还包括:
80.监测到目标任务的变更事件的情况下,将目标任务加入任务队列;
81.在目标任务从任务队列中出队的情况下,执行根据可用资源的信息,确定执行目标任务的子任务的第一并行数量的步骤。
82.本实施例中,目标任务的变更事件可以是目标任务的子任务增加、子任务减少、子任务完成、目标任务启动、目标任务停止等任何可能导致目标任务的子任务数量发生改变的事件。
83.本实施例中,在发生可能导致目标任务的子任务数量变化的变更事件的情况下,将目标任务加入任务队列,与多个其它任务进行排序,在排至目标任务时,获取可用资源的信息,针对目标任务进行子任务的第二并行数量的确定,从而能够减少对其它任务的干扰。
84.在一种实现方式中,目标任务可以与其它任务类型相同,也可以与其它任务类型不同。在确定第一并行数量时,可结合目标任务的类型、目标任务的子任务的类型中的至少一种进行计算。
85.在一种实施方式中,将目标任务加入任务队列,还包括:
86.确定目标任务在任务队列中对应的顺序;
87.根据顺序,将目标任务加入任务队列。
88.本实施例中,可根据目标任务的优先级,确定目标任务在队列中对应的顺序。
89.本实施例中,可在发生变更事件的情况下,根据优先级或者其它信息确定目标任务在任务队列中的顺序,从而能够在目标任务比较紧急、变动较小的情况下,以较快的速度为目标任务确定并行数量,保证重要的任务优先执行。
90.在一种实施方式中,任务执行方法还可包括:
91.在缓存中更新可用资源的信息。
92.本公开一种具体示例中,任务执行装置可通过下述模块实现各种必要的功能:
93.automl controller(automl控制器):可以用于统一管理所有automl任务,及根据automl任务的单次作业生成任务进行下发,以及所有automl任务或子任务的生命周期管理。
94.tuner service(调整服务模块):可以用于启动调优算法服务,接收来自automl controller的请求,根据不同算法或配置提供对应的模型的超参数组合建议。
95.meta service(元服务模块):可以用于持久化任务的元数据,比如对automl任务(experiment)、单次作业(run)等进行元数据持久化存储或者设置操作。上述experiment可以是单次automl自动学习任务。上述run可以是单次automl任务下通常会包含多次作业的运行,experiment的一次运行可以称为run。
96.针对单次基本的automl运行,workflow(操作流程)如下:
97.创建automl任务(可通过人工或者其它方式),automl controller负责处理用户的automl任务请求,根据automl任务设置的并发数量、调优算法等配置向对应的tuner service请求特定数量的超参数组合,然后组装并下发真正运行的runs,同时维护runs的状态及上层experiment相应的状态至meta service,并按需将runs的结果汇报给tuner service,以指导tuner service更好地给出下一轮组的超参数组合建议。在本公开示例中,目标任务的执行过程可以包括上述过程。
98.本公开实施例可应用于自动机器学习场景,实现自动机器学习的弹性伸缩。本公开示例的任务执行方法的实现,可基于容器化的环境,以已有的automl自动学习服务为基础,在其之上提供根据集群资源情况动态伸缩任务的能力。
99.在具体实现方式中,本公开示例的场景可为大规模容器化基础设施平台kubernetes。本示例中,kubernetes可以是主流的集群管理和任务分发管理平台。目前主流的机器学习平台底层也都基于或者支持kubernetes。
100.本示例中,kubernetes的主要功能可以包括:调整运行中automl任务并发度的能力,可设置暴露动态修改automl任务并发度的能力(超参数搜索,图像任务、训练任务)的接口即可,比如通过http(hyper text transfer protocol,超文本传输协议)/rpc(remote procedure call,远程过程调用)接口均可实现。
101.本示例中,kubernetes的主要功能还可以包括:根据集群资源动态伸缩automl任务的并发数量。
102.在具体示例中,automl jobs(automl任务)可属于新增kubernetes自定义资源,对应到单次automl任务,用户可配置最小和/或最大并发数量。在具体实现方式中,如图4所示,可通过下述组件实现并发数量的调整:
103.cache(缓存)41:在组件中会维护一层cache,可以是新增加的只读缓冲区,运行机制是监听集群内所有pod和/或nodes(节点)/automl job(任务)资源。用户可通过
kubernetes的接口服务器(api server)下发了任务列表(list)和条件(watch)到缓存41。kubernetes的接口服务器可通过etcd(一种键值存储系统)进行信息存储。
104.session(会话控制模块)42:运行计时线程(timed thread),可用于计算和/或更新automl任务并发数的周期,通常可以定时执行。在会话控制模块42内真正执行的动作可成为action,可用来计算任务并发数量。会话控制模块42可以管理多个任务的队列,任务出队(pop)后,计算并行数量(compute parallelism),计算后通知到任务的服务(notify service),对任务进行状态更新(update job status)。
105.plugins(插入模块)43:也可称为customizable plugins(可定制的插入模块),可以在session计算的各个周期内的各个执行阶段,可能存在许多可扩展的点,可通过插件化函数的机制来提供扩展,从而提高并发数量。本示例中,插入模块具体可以包括通知插件(notify plugin)44、弹性插件(elastic plugin)45、任务顺序插件(joborder plugin)46。
106.本示例中,可通过通知插件43运行,在actions执行完之后,由通知服务(notify service)对目标任务进行特征,可通过plugins扩展实现通知服务的功能。比如,plugins通过调用暴露动态修改automl任务并发度的能力的接口,实现通知服务的功能。通知服务可通过automl服务利用回调函数(callback function)进行回调。
107.在本公开一种示例中,上述组件的基本工作流如图3所示,包括:
108.步骤s31:通过kubernetes提供的informer(通知)机制监听pod和/或nodes和/或automl任务等所需要的可用资源,构建统一的cache层。
109.步骤s32:对于每个automl任务资源事件,排入优先级处理队列,利用自定义的joborder plugin(任务顺序插件)决定任务出队顺序。通常决定顺序的因素有入队时间、优先级等。比如,可采用如图4所示的任务顺序插件46。
110.步骤s33:确定从队列出队的automl任务。
111.步骤s34:获取该automl任务下正在运行的pod,根据pod更新automl任务资源的状态。
112.步骤s35:根据自定义的elastic plugin(弹性插件),结合cache中的集群资源情况及automl任务中定义的min(最小)和/或max(最大)并发度配置,计算出并发度,并更新automl任务资源的状态。elastic plugin可采用如图4所示的弹性插件45。
113.本示例中,在automl job资源的状态发生变化的情况下,可调用notify service去通知需要被通知的服务。比如,可设置如图4所示的通知插件44,用于通知已有的automl服务去更新automl任务的并发数。
114.一般情况下,如果依赖提前设置好的任务并发数来控制单轮次同时可以发起的任务数量,这个约束使得整个automl任务无法感知底层资源情况,即无法根据资源情况动态地去调整并发数。当集群资源不足时,过大的并发数会使得任务之间资源发生抢占,无法快速完成任务;而当集群资源充足时,过小的并发数又会使得集群资源无法充分利用。因此,根据本公开示例提供的方法,能够弹性地调整automl任务的并发数量,对合理高效利用可用资源起到了重要的作用。从而,本公开示例可通过监听集群资源,动态地为每个automl设置合理的并发数,来最大化集群的资源利用率。
115.本公开实施例还提供一种任务执行装置,如图5所示,包括:
116.资源信息获取模块51,用于获取可用资源的信息;
117.第一并行数量确定模块52,用于根据可用资源的信息,确定执行目标任务的子任务的第一并行数量;
118.调整模块53,用于根据第一并行数量,调整子任务。
119.在一种实施方式中,如图6所示,第一并行数量确定模块包括:
120.第二并行数量确定单元61,用于确定当前执行目标任务的子任务的第二并行数量;
121.上调单元62,用于在可用资源的信息表示能够增加新的子任务的情况下,按照预设的调整步长,上调第二并行数量;
122.上调执行单元63,用于将上调后的第二并行数量作为第一并行数量。
123.在一种实施方式中,如图7所示,第一并行数量确定模块还包括:
124.下调单元71,用于在可用资源的信息表示不足以供当前数量的子任务使用的情况下,按照预设的调整步长,下调第二并行数量;
125.下调执行单元72,用于将下调后的第二并行数量作为第一并行数量。
126.在一种实施方式中,如图8所示,调整模块包括:
127.第一调整单元81,用于在第一并行数量大于当前执行目标任务的子任务的第二并行数量的情况下,启动新的子任务。
128.在一种实施方式中,如图9所示,调整模块包括:
129.第二调整单元91,用于在第一并行数量小于当前执行目标任务的子任务的第二并行数量的情况下,待当前执行目标任务的子任务运行完毕之后,根据第一并行数量启动新的子任务。
130.在一种实施方式中,如图10所示,任务执行装置还包括:
131.监听模块101,用于监测到目标任务的变更事件;
132.加入模块102,用于在监测到所述目标任务的变更事件的情况下,将目标任务加入任务队列;
133.第一并行数量确定触发模块103,用于在目标任务从任务队列中出队的情况下,执行根据可用资源的信息,确定执行目标任务的子任务的第一并行数量的步骤。
134.在一种实施方式中,如图11所示,加入模块包括:
135.顺序单元111,用于确定目标任务在任务队列中对应的顺序;
136.顺序执行单元112,用于根据顺序,将目标任务加入任务队列。
137.本公开的技术方案中,所涉及的用户个人信息的获取,存储和应用等,均符合相关法律法规的规定,且不违背公序良俗。
138.根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。
139.图12示出了可以用来实施本公开的实施例的示例电子设备120的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。
140.如图12所示,设备120包括计算单元121,其可以根据存储在只读存储器(rom)122中的计算机程序或者从存储单元128加载到随机访问存储器(ram)123中的计算机程序,来执行各种适当的动作和处理。在ram 123中,还可存储设备120操作所需的各种程序和数据。计算单元121、rom 122以及ram 123通过总线124彼此相连。输入/输出(i/o)接口125也连接至总线124。
141.设备120中的多个部件连接至i/o接口125,包括:输入单元126,例如键盘、鼠标等;输出单元127,例如各种类型的显示器、扬声器等;存储单元128,例如磁盘、光盘等;以及通信单元129,例如网卡、调制解调器、无线通信收发机等。通信单元129允许设备120通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。
142.计算单元121可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元121的一些示例包括但不限于中央处理单元(cpu)、图形处理单元(gpu)、各种专用的人工智能(ai)计算芯片、各种运行机器学习模型算法的计算单元、数字信号处理器(dsp)、以及任何适当的处理器、控制器、微控制器等。计算单元121执行上文所描述的各个方法和处理,例如任务执行方法。例如,在一些实施例中,任务执行方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元128。在一些实施例中,计算机程序的部分或者全部可以经由rom 122和/或通信单元129而被载入和/或安装到设备120上。当计算机程序加载到ram 123并由计算单元121执行时,可以执行上文描述的任务执行方法的一个或多个步骤。备选地,在其他实施例中,计算单元121可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行任务执行方法。
143.本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、芯片上系统的系统(soc)、负载可编程逻辑设备(cpld)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。
144.用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
145.在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或快闪存储器)、光纤、便捷式紧凑盘只读存储器(cd-rom)、光学储存设备、磁储存设备、或
上述内容的任何合适组合。
146.为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(阴极射线管)或者lcd(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。
147.可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(lan)、广域网(wan)和互联网。
148.计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,也可以为分布式系统的服务器,或者是结合了区块链的服务器。
149.应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。
150.上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1