基于CPU+GPU异构的高并发序列比对计算加速方法与流程
基于cpu+gpu异构的高并发序列比对计算加速方法
技术领域
1.本发明涉及生物序列比对领域,特别涉及基于cpu+gpu异构的高并发序列比对计算加速方法。
背景技术:
2.生物序列比对是计算机领域经典的文本比对问题在生物领域的应用。随着不断涌现的新型分子生物学技术的发展 ,随之而来的比如基因变异、rna表达、蛋白质和基因相互作用等分子生物学研究需要研究人员采用高通量的方法去解释。这对高性能计算提出了新的挑战。高通量测序时代的挑战不再是数据的产生,而是数据存储,处理和分析。第三代测序技术的发展将进一步加快测序速度,同时产生较长的测序片段,对序列比对技术的发展提出了更高的要求。与此同时,计算机硬件平台也在近几年飞速发展, 不断推陈出新,新的多核平台和众核平台不断出现,众核处理器加速设备如gpu使高性能计算机的性能快速提高,gpu异构平台正成为构建高性能计算机的重要方式。这也使得计算机体系结构变得越来越复杂,给计算程序的优化带来了新的难题。
3.同时,在生物序列比对领域中,采用cpu+gpu异构平台的方式对算法进行加速时一个常见的处理方式。
4.比如,文献《基于gpgpu的生物序列快速比对》(第一作者马海晨,发表于期刊《计算机工程》第38卷第4期,2012年2月),是在cpu-gpu 异构平台下,提出一种高效的生物序列比对方案。该方案利用gpu的并行处理能力,通过对读延迟、写延迟、重组函数及数据传输进行优化,在opencl 框架下重构smith
‑ꢀ
waterman 算法,加快生物序列比对速度。即该文献主要是对sw算法(即smith
‑ꢀ
waterman 算法)进行优化。
5.再比如,工程硕士论文《生物序列分析算法的cpu_gpu异构并行优化关键技术研究》(作者万文,国防科学技术大学研究生院,2012年3月),其核心思想同样是基于cpu和gpu构建的异构系统,主要是对sw算法(即smith-waterman算法)进行优化。
6.上述技术方案,都是对某个具体算法(例如sw算法、fm-index算法)进行优化或者改进,这些技术方案均是聚焦于算法本身,利用gpu的特性,来解决数据并行的问题,通过对所采用具体算法的改进,来达到生物序列比对速度提升的目的,其缺点在于:在进行生物序列比对时,要先找到一段比较精确的匹配子段作为seed,对于不同的reads,其包含的smem长度、位置、数量都有很大的不同;当在gpu平台用采用每个线程处理一个reads的任务划分方式时,这会造成不同线程之间严重的不同步,包含较短smem的reads需要等待包含较长smem的reads查找完毕, 而对于包含较短smem的reads,其包含的smem的个数又更多,这样包含较长smem的reads又反过来需要等待包含较短smem的reads,这种互相等待的情况导致计算资源利用率极低,加速效果非常有限。上述技术方案聚焦于数据并行的问题(进一步加大数据并行的能力),并不能克服所述缺点。
7.同样,由于bwa-mem的这种与输入数据高度相关的seeding方式,每个reads包含的seed数量、长度都会有很大不同,这又会影响下一个模块中根据seed生成chain的过程,导
致生成chain的模块的不同线程同步性很差,进一步限制了加速效果。由于算法的运行特征与输入数据高度相关,这些方法无法同时适合不同特征的输入数据。 gpu平台对于同一warp内指令一致性的要求使bwa-mem算法的加速效果受到了严重限制。因此,对于原有的bwa-mem算法同样不能解决上述问题。
技术实现要素:
8.本发明的目的在于克服现有技术的缺点与不足,提供基于cpu+gpu异构的高并发序列比对计算加速方法。
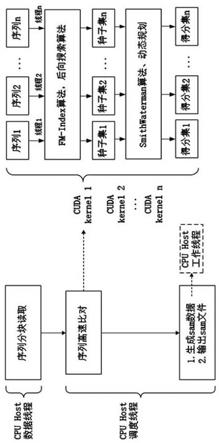
9.本发明的目的通过以下的技术方案实现:基于cpu+gpu异构的高并发序列比对计算加速方法,包含以下步骤:bwa-mem算法代码重构步骤:对于bwa-mem算法,简化其数据结构并优化部分循环及逻辑判断语句,使其适合在gpu架构上运行;cpu上任务并发处理步骤:在cpu上,对于待比对的序列集,首先根据gpu的处理线程数来设定序列的数据块大小,完成序列集的划分,第一次形成多个并发任务;然后cpu数据线程分块读取序列数据,接着进行序列数据对比;gpu上数据并发处理步骤:在gpu上,运行代码重构后的bwa-mem算法,用以完成序列数据对比的数据并发;gpu上任务并发处理步骤:在gpu上,对于序列数据对比的数据并发处理过程中产生的种子集和链,将相同或相邻的长度、位置、数量的种子集划分为同一数据块,链做同样处理,由此完成种子集与链的划分,第二次形成多个并发任务。
10.所述序列数据对比的数据并发处理过程中产生的种子集和链,是指序列数据对比过程中,寻找待比对序列片段和参考序列的所有相同公共子字符串,将其中最小长度不小于设定值的相同公共子字符串作为“种子”,多个“种子”的集合,即为“种子集”;然后,将在参考序列上位置靠近的种子当成“链”,存储在一起,并按种子长度从大到小的顺序,给每个链上的种子进行排序。
11.所述寻找待比对序列片段和参考序列的所有相同公共子字符串,是通过使用bwa-mem算法中的fm-index算法和后向搜索算法来完成的。
12.所述序列数据对比是通过开启两个调度线程以流水线形式来处理的:初始化一个主机线程等待,另一个主机线程分步骤一、二进行工作;当工作的主机线程进行到步骤二时,等待线程激活,等待的主机开始处理步骤一;所述步骤一为:获取内存数据后,调度gpu进行找种子、扩展任务,并把gpu计算得到的种子的扩展得分集作为中间数据从gpu内存拷贝到主机内存;所述步骤二为:生成sam数据并输出文件。
13.所述代码重构后的bwa-mem算法是通过全局工作列表来支持其异步执行, gpu为每个序列比对分析任务分配一个本地工作列表,并发比对分析任务共用一个远程工作列表;在系统运行期间,gpu周期性地报告产生和消耗的工作项;一旦工作项的总数为零,处理终止;gpu中包含三个线程:接收线程、发送线程和工作线程,前两个线程用于gpu 之间的通信,最后一个线程用于本地工作项的处理;每个gpu接收到来自上一个设备的远程工作项,交给接收线程来完成工作项的分流;工作线程和接收线程都会提交gpu kernel来完成它们
的工作,接收线程的kernel提交到独立的流上,并被分配更高的优先级。
14.所述简化bwa-mem算法的数据结构,是指使用cuda语言对数据结构进行了重构,去掉数据结构中的复杂结构,所述复杂结构包括多级指针、结构体。
15.所述优化bwa-mem算法的部分循环及逻辑判断语句,是指对部分循环进行等效展开,对逻辑判断语句进行重构。
16.所述多个并发任务所对应形成数据划分块,通过数据调度器及设定的调度规则将最需要访问的数据划分块优先载入缓存中。
17.所述序列数据包括单端或双端dna测序片段数据。
18.所述加速方法以数据流水线传输的方式实现高效的异步通信:在多gpu节点中,cpu和gpu之间通过前端总线相连接;前端总线连接到连接器上以支持cpu-gpu、gpu-gpu之间的通信; gpu1和gpu2、gpu3和gpu4之间可以直接数据传输,gpu2和gpu3之间的数据传输要经过cpu,因此分为两个阶段:gpu2先发送数据到主存,然后gpu3 再从主存中拉取信息;gpu包含输入、输出两个内存拷贝引擎,以及一个执行引擎,因此支持两路内存拷贝和代码执行并发进行;序列比对算法执行过程中,在gpu的接收端设计多个接收buffer,实现了流水线的接收器;一段数据传输完成后,gpu对其进行处理的同时可以立刻开始下一段数据的传输;异步程序通过细粒度同步点来保证正确性;所采用的异步通信机制为 future/promise 机制或者event 机制。
19.所述第二次形成多个并发任务,包括grid和block维度划分,以及序列与线程的划分;其中所述 grid和block维度划分,是在gpu中,根据cuda编程模型,grid中的各个block会被分配到gpu的各个流多处理器中执行;在维度选择时优先考虑block维度设计,grid—般越大越好;block维度设计需要根据实际计算中每个sm中使用的寄存器、共享存储器数量与硬件每个sm上可用的资源量来确定;所述序列与线程的划分,是指:每个序列分配一个线程进行运算;对于每一个数据划分块的处理,不同的分析任务可能具有不同的工作负载,通过gpu kernel的线程配置来解决,gpu中的计算是由多个线程块组成的grid 完成的,线程块则由多个线程组成;待处理顶点越多的图分析任务,配置越多的线程进行处理。
20.所述bwa-mem算法包括:fm-index 查找算法、后向搜索算法、smith-waterman 算法和动态规划;通过mem_chain模块完成smem的查找和chain的生成,而chain2aln 模块则负责将chain的两端利用smith-waterman算法进行拓展,找到最佳比对位置;mem _chain模块中又包含mem_ collect_intv模块和generate_chain模块,其中mem_collect_intv模块从read中查找最大精确匹配 ,而generate_chain模块将距离符合条件的mem构成chain;所述bwa-mem算法采用多kernel并行框架。
21.本发明与现有技术相比,具有如下优点和有益效果:1、本发明对cpu+gpu的异构系统进行深入研究,通过设计任务并行+数据并行的方式,能够让bwa-mem算法的特征与gpu加速设备的特征紧密结合,充分利用gpu强大的并发运算能力,为bwa-mem序列比对算法提供优异的性能,序列对比高并发处理效率较高。
22.任务并行+数据并行,具体为:第一次任务并行+第二次任务并行+一次数据并行,其中,第一次任务并行发生在cpu上,第二次任务并行发生在gpu上,一次数据并行发生在
gpu上,且第二次任务并行发生在数据并行的任务流之中。
23.2、本发明设计了数据访问异步模型,数据流水线传输的方式实现高效的异步通信,然后通过全局工作列表支持并发比对算法的异步执行。
24.3、本发明的设计了比对算法及任务并发的策略。该策略包括:fm-index、smith-watermen算法和grid、block维度、序列与线程高并发的策略。
25.4、本发明设计了数据驱动的并发执行机制,通过数据划分策略异步加载到gpu缓存中,服务多个计算任务,充分利用总体线程的访问开销,提高gpu资源利用率。
附图说明
26.图1为双线程两步流水线架构图。
27.图2为多 gpu 节点树形拓扑结构图。
28.图3为分布式工作列表的工作示意图。
29.图4为优化后的chain存储格式的示意图。
30.图5为bwa-mem算法中,数据结构重构后的多线程并行化模式。
31.图6为bwa-mem算法的流程图。
32.图7为比对算法数据流执行机制的示意图。
33.图8为数据并发执行架构图。
34.图9为种子扩展示意图图10为比对得分矩阵反对角线元素并行计算示意图。
35.图11为原版bwa和异构版bwa运行耗时对比图。
具体实施方式
36.下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
37.基于cpu+gpu异构的高并发序列比对计算加速方法,包含以下内容:数据访问异步模型设计,数据流水线传输的方式实现高效的异步通信,然后通过全局工作列表支持并发比对算法的异步执行。
38.比对算法及任务并发的策略。该策略包括:fm-index、smith-watermen算法和grid、block维度、序列与线程高并发的策略。
39.数据驱动的并发执行机制,通过数据划分策略异步加载到gpu缓存中,服务多个计算任务,充分利用总体线程的访问开销,提高gpu资源利用率。
40.具体包括:1、数据访问异步模型设计1.1 异步线程如图1,为了进行并行处理,大规模的序列数据需要进行划分。目前的序列划分策略由单独cpu数据线程分块读取序列数据(单端或双端dna测序片段数据)存入主机内存,读取的数据块大小是根据gpu的处理线程数来设定,假设使用tesla v100 gpu,拥有80个计算单元,每个计算单元上最高可运行1024个线程,每次每张卡可以处理80 x 1024 = 81920个计算任务。然后主机开启两个调度线程以流水线形式来处理序列比对计算任务,初始化一
个主机线程等待,另一个主机线程获取内存数据后,调度gpu进行找种子、扩展任务,并把gpu计算得到的中间数据(种子的扩展得分集)从gpu内存拷贝到主机内存,并开始处理步骤二,生成sam数据(cpu工作多线程)并输出文件。当前面的线程进入步骤二的同时,等待线程激活,开始处理步骤一。这样以流水线的形式运行异构系统,始终保持主机和gpu处于繁忙的状态,达到最优的性能效果。
41.算法1cpu流水线执行机制的伪代码实现procedureexecutor1(r,s)whilerhasunprocessedrnforsomesamplesdo
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
//数据线程读取序列划分块到主机内存
ꢀꢀꢀꢀꢀꢀꢀꢀ
foreachs∈ssdorn←
scheduler(r,s)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
endfor
ꢀꢀꢀꢀ
endwhileendprocedureprocedureexecutor2(rn,g)
ꢀꢀꢀ
whilerhasunprocessedrnforsomegpusdo
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
//调度线程流水线步骤1任务gs←
getgpus(rn,g)//获得处理rn的任务集合
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
foreachg∈gsdoparallelprocess(g,rn,d)//cudakernel异步处理序列任务
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
endfor
ꢀꢀꢀꢀꢀ
endwhileendprocedureprocedureexecutor3(d,j) whileshasunprocessedsnforsomejobsdo//调度线程流水线步骤2任务js←
getdatas(d,j)//获得处理d的任务集合
ꢀꢀꢀꢀ
foreachj∈jsdoparallelprocess(j,d,s)//工作线程并行处理任务
ꢀꢀꢀꢀ
endforforeachj∈jsdooutput(j,s
new
)//同步任务输出sam文件
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
endforendwhileendprocedure1.2异步通信在多gpu节点中,cpu和gpu之间通过前端总线相连接。前端总线连接到pci-express或者nvlink等连接器上以支持cpu-gpu、gpu-gpu之间的通信。如图2所示,gpu1和2、gpu3和4之间可以直接数据传输。gpu2和3之间的数据传输要经过cpu,因此分为两个阶
段,gpu2 先发送数据到主存,然后gpu3 再从主存中拉取信息。gpu 包含两个内存拷贝引擎(输入和输出),和一个执行引擎,因此支持两路内存拷贝和代码执行并发进行。序列比对算法执行过程中,为了进一步提高通信效率,系统在gpu的接收端设计多个接收buffer,实现了流水线的接收器。一段数据传输完成后,gpu对其进行处理的同时可以立刻开始下一段数据的传输,提高了gpu的计算通信覆盖率。
42.异步程序需要细粒度同步点来保证正确性。为了最小化同步开销,系统使用两种低延迟的异步通信机制。一种是 future/promise 机制,例如数据段的传输请求返回一个future 对象阻塞后续操作,表示传输尚未完成。一旦数据传输完毕,便可立即对其进行处理。另一种是 event 机制,在 cuda 流中插入事件,便可对 event 之前提交的所有操作进行同步。
43.异步执行由于每个 gpu 的在全局内存中只存储了序列的一个子集,每个gpu只能处理本地序列相关的工作项。因此对于每个gpu来说,工作项分为本地工作和远程工作两种,在系统中分别用localwork和remotework对象表示。其中工作项的属性包括序列id 和序列属性,还有一个任务id属性,用于区分不同的比对分析任务。系统实现了一个分布式的工作列表来协助序列比对算法的异步执行。分布式工作列表维护了一个待处理工作项的全局列表。每个工作项可能会产生新的工作项加入到工作列表中,例如,工作线程遍历每一个序列种子集,为种子集分组创建了一个新的工作项。在分布式工作列表的实现中,全局协作和工作项计数集中在主机中管理,工作项分布式存储在各gpu的全局内存中。其中,gpu为每个比对分析任务分配一个本地工作列表,并发比对分析任务共用一个远程工作列表。在系统运行期间,gpu周期性地报告产生和消耗的工作项。一旦工作项的总数为零,处理终止。如图3中所示,从单个gpu的角度描述了分布式工作列表的实现。gpu中包含三个线程:接收线程、发送线程和工作线程。前两个用于gpu 之间的通信,最后一个用于本地工作项的处理。下面详细介绍分布式工作列表的工作流程。每个gpu接收到来自上一个设备的远程工作项,交给接收线程来完成工作项的分流。工作线程和接收线程都会提交gpu kernel来完成它们的工作,接收线程的kernel提交到独立的流上,并被分配更高的优先级。这样做的目的是防止本地计算任务阻塞异步通信任务,提高系统的性能和响应性。
44.本地工作列表是一个由数组实现的循环队列,避免在运行时动态分配内存的开销。如图3所示每个本地工作列表包含两个生产者和一个消费者。接收线程和工作线程会为本地工作列表添加工作项,而只有工作线程会消耗工作项。本地工作列表包含一个内存数组和三个域:start,end和pending。通过增加start的值表示工作项的消耗。为了避免消耗没准备好的数据项,先通过原子操作增加pending的值,为要添加的工作项保留空间。当生产者添加工作项之后,再把end的值与pending进行同步。为了避免多个生产者的写冲突,工作线程产生的新工作项通过减少start值的方式添加到本地工作列表中。向本地工作列表中添加工作项时,kernel中的多个线程对本地工作列表进行写操作,原子操作的开销很大。系统使用warp-aggregated atomic解决这个问题。具体而言,每个warp中的线程先计算添加的工作项的总数和各自的偏移,然后用原子操作保留写数据的空间,最后再执行写操作。这样线程之间的原子操作变成了warp之间的原子操作,大大减少了原子操作的开销。
45.存储设计与优化
cuda设备与主机端进行数据传输时,只能够对支持位拷贝的数据进行传输。也就是说,对于包含指针变量的结构体,指针的指针等数据结构,无法直接在设备和主机端进行传输。因此需要对数据结构进行调整,将需要在设备与主机端传输的数据选取出来,将这些数据独立分配为一块连续的存储空间,加快数据传输速度。以保存生成chain的数据结构为例,优化后的chain存储模式分别如图4所示。
46.基于gpu内部的6种存储器存储空间,根据数据的数据量和访问特点来设计优化其存储位置。bwa-mem的kernel中使用的数据表1所示。
47.表12、比对算法及任务并发的策略设计与实现2.1 bwa-mem算法并行化bwa-mem算法使用的都是原程序的算法,这样能保证输出结果高精度,在将cpu代码重构为gpu内核代码的过程中,使用cuda语言,并对数据结构进行了重构,去掉多级指针、结构体等复杂结构,还对部分循环进行等效展开,对逻辑判断语句进行重构,使其更适合在gpu架构上运行计算。
[0048] bwa-mem的主要算法有fm-index 查找算法、后向搜索算法、smithwaterman 算法和动态规划。其中mem_chain和chain2a ln这两个模块是整个bwa-mem序列比对的两个最重要的热点。mem_chain算法主要完成smem的查找和chain的生成,而chain2aln 模块则负责将chain的两端利用smith-waterman算法进行拓展,找到最佳比对位置。mem _chain模块中又包含两个重要模块:mem_ collect_intv和generate_chain。其中mem_collect_intv模块从read中查找最大精确匹配(mem) ,而generate_chain模块将距离符合条件的mem构成chain。由于整个算法流程要经过多个模块,为了能够使程序在gpu上有更好的性能,设计了图5所示的多kernel并行框架。bwa-mem算法的流程如图6。
[0049]
查找算法 如果字符串w是x的一个子字符串,则w在x中每次出现的位置将是在后缀数组的区间内。这是因为所有的后缀以w为前缀排列在一起。基于这个观察,我们定义:r(w)= min{k:w是xs(k)的前缀} (1)r(w)= max{k:w是xs(k)的前缀} (2)bwt转换和后缀数组如下所示:
其中,如果w是一个空字符串,则r(w)=1,r(w)=n
−
1。区间[r(w),r(w)]称为w的sa区间,并且w在x中出现的所有位置集合为{s(k):r(w)≤k≤r(w)}。例如在bwt转换和后缀数组中,字符串“ac”的sa区间为[2,3]。此区间内的后缀数组值是0和3,表示原字符串中所有出现的“ac”的位置。知道后缀数组中的区间,我们就可以得到它在原字符串中的位置。因此,序列比对等价于搜索sa区间匹配查询的x的子字符串。对于精确匹配问题,我们只能找到一个这样的sa区间;对于不精确匹配问题,可能存在是很多的sa区间。
[0050] 向后搜索算法设c(a)为x[0,n
−
2]中按字典顺序排列的符号数小于a∈∑并且o(a,i)为a在b[0,i]中出现的次数。ferraginaandmanzini(2000)证明了如果w是x的子串:那么就有r(aw)≤r(aw)当且仅当aw是x的子串。这个结论使得可以测试w是否是x的子字符串,并且能在o(|w|)时间中统计出w的出现次数,通过从w的最后往前迭代计算r和r这个过程被称为后向搜索。值得注意的是,公式(3)和(4)实际上实现了自顶向下遍历x的前缀树,如果我们知道它的父节点的区间,我们就可以在常数时间内计算出一个子节点的sa区间。在这个意义上,后向搜索等价于字符串在前缀树中的精确匹配,但没有显式地将前缀树放入内存中。
[0051]
算法、动态规划 在经过上面的算法找到dna测序片段在参考序列中的所有符合要求的“种子”(dna测序片段在参考序列上的超级最大精确匹配的子串)后,就进入到“种子扩展”阶段,此阶段需要计算两个字符串的比对得分矩阵,用到smithwaterman算法、动态规划过程。
[0052] smithwaterman算法步骤:(1)初始化算法分数矩阵h,使行i表示字符ai,列j表示字符bj(2)计算矩阵中每一项的hi,j:
其中,pen_match是两个字符相同时的奖励分,pen_missmatch是两个字符不相同时的惩罚分,si,j为奖惩得分,pen_gap(si,-)为待匹配序列插入或删除罚分(假设参考序列为横向的“行”序列),pen_gap(-,tj)为参考序列插入或删除罚分。
[0053]
计算得分矩阵:计算二维矩阵上的元素hi,j时,需要先计算出它左侧、左上角、顶部的三个元素,因此,计算得分矩阵的过程也是一个动态规划过程,它将更大更复杂的原始问题划分成更小更容易求解的子问题,在得到子问题的最优解后,对它们组合,并得到原始问题的最优解。
[0054]
2.4任务划分并行化任务划分涉及到两方面的工作,分别是grid、block维度划分和序列与线程的划分。对于 grid和block维度划分,根据cuda编程模型,grid中的各个block会被分配到gpu的各个流多处理器(stream multiprocessor,sm) 中执行。在维度选择时优先考虑block维度设计,grid—般越大越好。block维度设计需要根据实际计算中每个sm中使用的寄存器、共享存储器数量与硬件每个sm上可用的资源量来确定。接下来是reads与线程的划分。在比对过程中reads具有天然的无关性,即不同reads之间完全独立,只需要参考序列信息,不需要其他reads的信息。因此采用最直观的处理方法,每个reads分配一个线程进行运算。对于每一个数据划分块的处理,不同的分析任务可能具有不同的工作负载,通过gpu kernel的线程配置来解决,gpu中的计算是由多个线程块组成的grid 完成的,线程块则由多个线程组成。待处理顶点越多的图分析任务,配置越多的线程进行处理。
[0055]
3、数据驱动的并发执行机制3.1数据流模型设计数据驱动的并发执行机制的设计实现,举例形式化的算法说明数据驱动gpu并发计算和计算结果输出。数据加载部分主要包括数据划分块的策略和任务状态的加载,并发处理部分包括并发分析任务对同一出划分的处理及数据同步输出。
[0056]
当一个gpu的接收线程接收到来自cpu的远程工作项时,根据任务id把这些工作项添加到各任务的本地工作列表中,然后触发各任务的工作线程进行处理。为了充分利用并发任务数据访问的关联性,系统提出了数据驱动的并发任务执行模型,核心思想是:并发分析任务共享相同的数据分块的访问顺序,每次载入一个数据分块组和多个任务特定数据到gpu缓存中,触发多个计算任务并发处理。当所有相关任务处理完成后才会载入下一个数据划块。
[0057]
以图7为例,假如当前 gpu 中有fm-index、smithwaterman两个计算任务,它们都需要访问数据划分块1和划分块2完成计算,系统首先把数据分块组载入缓存中,触发两个任务进行处理,然后再载入下一批数据分块组。这样只需要对分析数据进行一次访问,就完
成了并发分析任务,减少了总数据访问开销。
[0058]
算法2 gpu高并发执行机制的伪代码实现procedure executor(r,j)
ꢀꢀꢀꢀꢀ
while r has unprocessed r
n for some jobs do
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
//调度加载数据划分块ri←
scheduler(r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
//获得处理ri的任务集合
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀjs
←
getjobs(ri,j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
//并行处理数据集
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for each j ∈ j
s doparallelprocess(j,r
i,
sj)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
end for
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
//同步任务的数据集
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for each j ∈ j
s dodatas(j,s
new
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
end for
ꢀꢀꢀꢀꢀꢀꢀ
end whileend procedure举例说明序列比对算法,对数据驱动的并发比对任务执行模型进行详细说明。假设比对算法需要访问的数据表示为d=(t,r,n,q)。其中t表示序列的id集,r表示read的序列集,n表示序列的名称集,q表示read的质量集。在该模型中,每个序列比对算法的序列结构数据r=( t,r,n,q),现有比对算法的集合j,加载处理的序列结构数据r ∈ri ,其中ri是r的第i个序列划分块,js表示比对算法的一个子集。
[0059]
该执行模型如算法2所示。当仍在待处理的序列划分块时,利用cpu的调度线程加载一个划分块到gpu缓存中,然后获得需要对其进行处理的比对分析任务,并触发它们进行并行处理。当该划分块处理完成后,将计算的序列得分集进行输出,然后进入下一循环,直到所有序列划分块处理完成。
[0060]
数据划分和加载为了进行并行处理,大规模的数据按需要进行划分。目前的数据划分策略主要基于一至性的划分,允许通过在多个设备上分配这些节点的负载来实现更好的负载均衡。不同的数据集采用不同的划分方法,包括序列集划分、链和种子集划分。基本的划分规则如下:其中序列的数据块大小是根据gpu的处理线程数来设定,链与种子集的数据块以相等或相邻的长度、位置、数量来划分。因此缓解了并行计算水桶效应的影响,可以加速收敛,减少同步开销,减少消息数据的存储开销。
[0061]
数据划分块处理的顺序不会影响算法的正确性。为了最大化并发分析任务数据访问的时间和空间关联性,系统还提供一个数据调度器,将最需要访问的划分块优先载入缓存中用于处理。每一个待访问的数据划分块gi,系统动态地分配一个优先级 pi。拥有最高优先级的划分块先被载入到缓存中处理,从而提高缓存的利用率。基本的调度规则如下:首先,当一个数据划分块需要被关联任务处理时,则它应该被赋予最高的优先级,在先加载到
缓存中,其次,一个数据划分块应该拥有更高的优先级,如果它是同一样本的最后数据段。这是因为,最后一个样本数据最终结果文件的线程等时间减少,因此也消耗更少的缓存空间。
[0062]
数据并发处理如图8,每当载入一个或多个数据划分块到缓存中,触发相关的并发分析任务进行处理。新提交的任务只需把初始的工作项发送到相应的设备中,等待被触发处理。当并发分析任务的数目特别大,以至于单个gpu的线程不够用,则对它们分批处理。首先载入第一批数据块到缓存中,触发相应的分析任务进行处理;这一步骤完成后,保存划分块输出的结果到缓存里,触发下一批分析任务进行处理;只有当所有并发分析任务计算完成后,才会载入下一个或多个数据划分块。对于每多个数据划分块的处理,不同的分析任务可能具有不同的工作负载,这导致硬件资源的低利用率。系统设计通过gpu kernel的线程配置来解决,gpu中的计算是由多个线程块组成的grid完成的,线程块则由多个线程组成。待处理数据越多的分析任务,配置越多的线程进行并行化处理。
[0063]
具体的运行算例如下所示:4.1 测试平台、数据集介绍本次测试使用的平台系统是centos linux release 7.8,内核版本是3.10.0-1127,cpu是intel(r) xeon(r) gold 6240 cpu @ 2.60ghz,两个cpu,每个cpu有18核心,每核心2线程,cpu线程总数是72个,主机内存总数为125gib。主机搭载两个nvidia tesla v100 gpu异构处理器,gpu板上内存总数是32gib,gpu驱动程序版本是410.48,cuda版本是10.0。
[0064]
测试数据使用的是随机抽样的临床外显双端dna测序数据,两个fastq待比对数据文件,每个文件大小都是11.79gib,总共有23.58gib。
[0065]
数据计算流程主机端,先读取输入的命令行参数,解析参数,得到输入文件名、输出文件名、参考序列文件名、用到的gpu、线程数等信息,然后读取参考序列相关数据,包括sa数组、bwt数组、参考序列索引等。当上述工作完成后,开启一个read_input线程专门用于读取输入文件,由于读取文件操作一般来说比计算操作要快很多,因此,我们采用的策略是最大读取四批数据(一批数据量大小是gpu一次能处理的最大数据量大小),具体为:每次读取完一批数据后,将g_seqindex(已读取的数据批次索引)加一,比较g_seqindex和g_currindex(当前正在处理的数据批次索引),当g_seqindex比g_currindex还大4个时,read_input线程睡眠100毫秒(让出cpu资源以供其它任务处理)后继续检测,直到任务调度线程从主机内存拷贝出待处理数据并将g_currindex加一后,结束此检测,继续读取文件中的后续数据批次,这样read_input线程就保证了始终不占用过多的主机内存。
[0066]
接下来,主机端初始化cuda资源,上传参考序列相关数据和比对参数数据到gpu,然后分配接收gpu返回数据的主机内存,最后开启两个主机流水线任务调度线程。其中一个任务调度线程进入流水线步骤一,从内存取出一批待比对数据,保险起见(计算比读取快的情况),比较g_currindex和g_seqindex,当g_currindex比g_seqindex大时,将调度线程睡眠50毫秒(让出cpu资源以供其它任务处理)后继续检测,直到read_input线程读取文件并将g_seqindex加一后,结束此检测,并将g_currindex加一,然后将待比对数据拷贝到gpu内
存,启动gpu内核开始计算种子、种子扩展得分等异步任务。此时另一个任务调度线程则处于等待状态。
[0067]
gpu内核包括seeding(找种子)和extending(扩展)两个功能。其中seeding基本都是内存操作,使用fm-index算法(通过sa数组和bwt数组等寻找子字符串在原字符串中的位置索引)和后向搜索算法(公式(3)和公式(4)),寻找待比对dna片段和参考序列的所有相同公共子字符串,要求其最小长度不小于19(默认值),将其作为“种子”,然后,将在参考序列上位置靠近的种子当成“链”,存储在一起,并按种子长度从大到小的顺序,给每个链上的种子进行排序。
[0068]
最后每个read会得到与之对应的一批种子链,每个种子链上,都包含有多个种子,如果不对其整理,后续一个gpu线程处理一个read的所有种子,则gpu同一warp内指令一致性的要求会导致处理速度取决于处理最慢的read,这就有点像水桶的“短板效应”。为了解决这个问题,经过仔细分析,计算出每个read需要扩展部分的总长度,具体做法是将read长度减去每个seed长度,得到每个seed需要扩展的长度,然后求和。得到每个read需要扩展部分的总长度之后,先找出需要扩展总长度最大的那一个(最短的那块“板”),然后以此为基准,把需要扩展的总长度之和靠近这个值的read分到同一个组,例如read1、read2、read3需要扩展的总长度分别为10000、13000、30000,则将read1、read2分到一个组,read3分到另一个组,然后以组为单位分配gpu处理线程,去做extending。
[0069]
extending则较多涉及到计算,属于计算密集型任务,它主要使用smithwaterman算法和动态规划算法,对前面找到的种子链上的种子进行“扩展”,即找到真实的匹配情况,如图9所示,对比对序列accacgttaagcga的一个种子acgttaa进行扩展,则只需要(1)分别找出种子在参考序列和比对序列以外的部分;(2)运用smithwaterman算法对待扩展部分进行局部比对打分。
[0070]
由于smithwaterman算法计算量很大(实际运算时,未经优化则需要计算三个矩阵),为了充分发挥gpu并行计算的特性,观察得分矩阵的元素计算顺序,每个矩阵元素的计算,仅仅只依赖于本元素的左侧、左上角、上侧三个元素的数值,与其它元素的数值无关,因此,它也是一个动态规划的过程,则矩阵的反对角线上的元素,没有相互依赖关系,由这一特点发现,矩阵反对角线上的元素,刚好可以利用gpu来进行并行计算,如图10所示,即:先分配足够大的gpu线程数(例如和比对目标序列长度数相同),第一个时钟周期,gpu线程并行计算第一条反对角线上的所有元素,第二个时钟周期,gpu线程并行计算第二条反对角线上的所有元素,依此类推,直到计算完整个矩阵的元素。在此计算过程中,不断记录并更新最大得分值和取得此得分值时所对应的参考序列位置和比对目标序列位置,最后将最终得分和对应的相关位置信息,存储到gpu内存中。
[0071]
在对一个链的种子进行扩展时,并不是这个链的所有种子都必须进行扩展的,原因是有可能有些种子扩展后,其扩展结果会覆盖还未进行扩展的种子,所以,每个种子进行扩展计算之前,先要根据gpu内存中已有的扩展结果进行判断,如果已有扩展结果未覆盖当前种子,则对当前种子进行扩展,否则跳过当前种子,继续处理链中的其它种子。
[0072]
当一批比对序列全部处理完成后,所有的得分集全部写入到了gpu内存中,gpu的本次计算任务完成,任务调度线程将gpu内存中的计算结果拷贝到主机内存,并开始进行流水线的第二个步骤,而与此同时,另一个等待的任务调度线程激活,开始处理下一批比对序
列数据。从此刻起,流水线的两个步骤同时进行。
[0073]
在流水线步骤二中,主要有两个任务,任务一是根据流水线步骤一的比对得分集,开启多个主机工作线程来生成最终比对结果,比对结果是sam格式的字符串,其中包括比对序列在参考序列上的最优匹配位置或次优匹配位置,以及比对质量,具体比对情况(cigar值)等等信息。任务二则是在任务一完成之后,输出sam数据到文件。
[0074]
测试结果及分析本次测试,主机端分别使用5、10、20、30个线程,分别在相同条件下运行原程序和本异构程序,得到的运行耗时对比如图11所示。从对比结果可以看到,随着主机线程数增多,原版和异构版的总体耗时时间在减少,并且在主机线程小于等于20个时,异构版耗时减少很明显,但主机线程超过20时,异构版耗时不再减少,而是在某个值附近波动,例如从20线程提升到30线程时,异构版耗时并没有很明显的减少,反而还增加了一点,这可能是其它因素比如初始化资源时读取参考文件、中途输出文件等微小波动造成的。异构版并没有随着主机线程的增多而一直减少耗时,是因为,不管多少主机线程,gpu都处于满载状态,主机线程比较少时,流水线步骤一的计算速度比流水线步骤二的计算速度快,但随着主机线程的增加,则只能加快流水线步骤二的生成sam数据的速度,并且主机线程在20个左右时,流水线步骤一和流水线步骤二的计算速度接近,达到了最优的处理速度,此时整体处理速度也是最优。而原版这边,增加主机线程时,可以同步增加处理的数据量,并且基本不受其它约束,所以耗时还在减少。在整体耗时要少和使用主机资源要少的前提下,当异构版的主机线程为20个时,原版20线程耗时是异构版的13倍,原版30线程耗时是异构版的9到10倍,可见提速是很明显的。
[0075]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1