一种基于机器学习的单点风速短临风速外推方法与流程
1.本发明涉及风速预测技术领域,具体涉及一种基于机器学习的单点风速短临风速外推方法。
背景技术:
2.时间序列是指将同一的统计指标的数值按其先后发生的时间顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。常用的时间序列模型有ar模型(autoregressive model:自回归模型)、ma模型(moving average model:滑动平均模型)、arma模型(auto-regressive and moving average model:自回归滑动平均模型)和arima模型(autoregressive integrated moving average model:自回归积分滑动平均模型)等。随着机器学习的发展,svm(support vector machine)、dt(decision tree)、lstm(long short-term memory)等机器学习和深度学习方法也慢慢的应该用到了时间序列外推当中。集成算法的提出,更加提高了准确性更高的机器学习模型,目前rf(random forest)、adaboost(adaptive boosting)等机器学习算法的提出给基于时间序列外推提供了新的思路。
3.目前,随着国家对新能源,风能发电的重视,在包括陆地和海上的不同地区建立了风电场进行发电,如何准确预测风速,对组织风电厂发电策略,功率预测,电力交易都有着一定的指导意义。但是现有的预测方法的准确性均较低。预测风速的准确性直接影响风电厂发电策略,因此亟需一种预测准确性较高的短临风速的外推方法。
技术实现要素:
4.为了解决现有短临风速预测风速不够准确的问题,本发明提供一种基于机器学习的单点风速短临风速外推方法。
5.本发明为解决技术问题所采用的技术方案如下:
6.一种基于机器学习的单点风速短临风速外推方法,包括如下步骤:
7.s1、获得历史风速样本,将历史风速样本分成训练样本集和测试样本集;
8.s2、取训练样本集中的历史风速样本得到多个时间序列,不同时间序列之间的时间长度不同,不同时间序列中的历史风速样本的样本总量相同;
9.s3、训练载有集成机器学习算法的模型得到初级集成机器学习模型,所述模型训练的输入为一个时间序列;
10.s4、采用测试样本集测试初级集成机器学习模型得到测试结果;
11.s5、待所有初级集成机器学习模型测试完成后,选取最优测试结果对应的初级集成机器学习模型作为集成机器学习模型,最优测试结果对应的时间序列的n作为集成机器学习模型的输入长度,所述n为在历史风速样本的时间分辨率下时间序列实际长度的间隔点数;
12.s6、将满足输入长度的历史风速数据作为集成机器学习模型的输入,集成机器学
习模型输出预测的短临风速。
13.本发明的有益效果是:
14.本发明的一种基于机器学习的单点风速短临风速外推方法的选取了最优时间序列的集成机器学习短临风速预报模型进行外推,该模型有较强的鲁棒性,并在样本数量不多的情况下也可以表现出相对优异的结果,并且优于传统方法。为陆地,特别是海上风电场的短临预报提供了一种较为泛化的策略,提升了风速预报效果。
附图说明
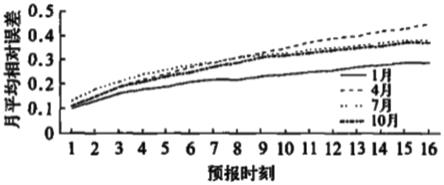
15.图1为传统的单点风速短临风速外推方法的不同预报时刻的平均相对误差图。
16.图2为本发明的一种基于机器学习的单点风速短临风速外推方法采用80%样本作为训练样本集得到的不同预报时刻的平均相对误差图。
17.图3为本发明的一种基于机器学习的单点风速短临风速外推方法采用50%样本作为训练样本集得到的不同预报时刻的平均相对误差图。
18.图4为本发明的一种基于机器学习的单点风速短临风速外推方法采用25%样本作为训练样本集得到的不同预报时刻的平均相对误差图。
具体实施方式
19.下面结合附图和实施例对本发明做进一步详细说明。
20.一种基于机器学习的单点风速短临风速外推方法,包括如下步骤:
21.s1、基于测风塔或海上风电场等的历史实况数据获得历史风速样本,将历史风速样本分成训练样本集和测试样本集;将历史风速样本分成训练样本集和测试样本集;
22.s2、取训练样本集中的历史风速样本得到多个时间序列,不同时间序列之间的时间长度不同,不同时间序列中的历史风速样本的样本总量相同;
23.s3、训练载有集成机器学习算法的模型得到初级集成机器学习模型,所述模型训练的输入为一个时间序列;即以每个时间序列分别作为载有集成机器学习算法的模型的输入进行模型训练,得到多个初级集成机器学习模型;每个时间序列对应一个初级集成机器学习模型;
24.s4、采用测试样本集测试初级集成机器学习模型得到测试结果;
25.s5、待所有初级集成机器学习模型测试完成后,根据所有的测试结果选取最优测试结果,再选取最优测试结果对应的初级集成机器学习模型作为集成机器学习模型,最优测试结果对应的时间序列的n作为集成机器学习模型的输入长度,n表示在历史风速样本的时间分辨率r
t
下时间序列实际长度的间隔点数;
26.s6、将满足输入长度的历史风速数据作为集成机器学习模型的输入,集成机器学习模型输出预测的短临风速。
27.上述s2中每个时间序列的n的确定方法为:
28.li表示时间序列的实际长度,设初始时间序列实际长度li为ls,i小时间隔递增,最长的时间序列实际长度li为l
max
,n=(60/r
t
)
×
ls+(60/r
t
)
×i×
j,其中j∈[0,(l
max-ls)/i],且j为整数,r
t
表示历史风速样本的时间分辨率。ls为本发明欲预测的短临风速的时间长度。不同时间序列之间的时间长度不同具体为:不同时间序列的li不同,不同时间序列的间隔
点数n也不同。
[0029]
上述s3中,时间序列的n作为载有集成机器学习算法的模型的训练输入x,本发明欲预测的短临风速的时间长度作为载有集成机器学习算法的模型的训练样本模型的训练输入y。
[0030]
上述s4中每个初级集成机器学习模型的测试过程为:
[0031]
s4.1、利用待测试的初级集成机器学习模型预测测试样本集中所有测试样本对应的预测结果,计算预测结果和与其对应的观测结果(该预测结果对应的测试样本集中测试样本)之间的平均误差me、均方根误差rmse、平均绝对误差mae、平均相对误差mre和相关系数co。
[0032][0033][0034][0035][0036][0037]
其中,fi为第i个预测结果;oi为第i个实际观测结果,即第i个测试样本;为预测结果的平均值;为实际观测的平均值,即测试样本的平均值;n表示测试样本集的测试样本总数,i∈[1,n],i为整数。
[0038]
s4.2、根据s4.1得到的me、rmse、mae和mre,计算步骤s2得到所有时间序列中的某一个时间序列对应的median(mae)得到mae
mp
,计算n
p
对应的median(rmae)得到rmae
mp
,计算n
p
对应的median(mre)得到mre
mp
,计算n
p
对应的median(abs(me))得到abs(me)
mp
,median()表示中位数函数,abs()表示绝对值函数;以作为s4.3的比较基准。
[0039]
s4.3、对于除外s4.2的时间序列外每个时间序列,根据其在s4.1中得到的mae、计算其mae小于mae
mp
的测试样本的数量占测试样本集的百分比得到第一百分比;对于除外s4.2的时间序列外每个时间序列,根据其在s4.1中得到的rmae、计算其rmae小于rmae
mp
的测试样本的数量占测试样本集的百分比得到第二百分比;对于除外s4.2的时间序列外每个时间序列,根据其在s4.1中得到的mre、计算其mre小于mre
mp
的测试样本的数量占测试样本集的百分比得到第三百分比;对于除外s4.2的时间序列外每个时间序列,根据其在s4.1中得到的me、计算其me绝对值小于abs(me)
mp
的测试样本的数量占测试样本集的百分比得到第四百分比;对于除外s4.2的时间序列外每个时间序列,根据其在s4.1中得到的co、计算其co大于y的测试样本的数量占测试样本集的百分比得到第五百分比,y表示常数且0<y<1,y为预设值,例如y=0.5。计算除外n
p
外每个n的第一百分比、第二百分比、第三百分比、第四百
分比和第五百分比的总和criteria,总和作为测试结果,也就是作为测试评价准则。
[0040]
s5中最优测试结果为除s4.2中时间序列外的每个时间序列对应的测试结果中的最大值。
[0041]
下面举例具体阐述本发明的外推方法。基于测风塔或海上风电场等的实况数据的时间分辨率r
t
,通过下述多指标命中频率法(即s4.1~s4.3)来计算选取最优的样本长度,通过集成机器学习模型的方法来预报为来4小时的风速,得到与实况时间分辨率间隔相同的风速值。
[0042]
选取集成机器学习算法(boost系列)包括不限于xgboost(极端梯度提升extreme gradient boosting)、catboost(gradient boosting+categorical features基于梯度提升决策树的机器学习方法)、lightgbm(light gradient boosting machine)、adaboost,本实施方式中选取adaboost作为模型用来进行短临风速预报。
[0043]
将历史风速样本随机分割成80%和20%,80%部分作为训练样本集,20%部分作为测试样本集。选取不同的时间长度的时间序列n作为训练样本模型的x,4小时时间序列的实际长度作为训练样本y,用载有集成机器学习算法的模型将上述训练样本集的样本切成不同时间序列实际长度放入模型进行建模,根据建模结果,计算测试样本集中样本的预测结果与观测结果之间的平均误差(me),均方根误差(rmse),平均相对误差(mre),平均相对误差(mae),相关系数(co)。
[0044]
时间长度的选取策略为以4小时长度为初始实际长度,2小时间隔递增,72小时为最长时间序列,即以时间间隔10分钟为例,n=[24,36,48,60,72,84,96,108,120,132,144,156,168,180,192,204,216,228,240,252,264,276,288,300,312,324,336,348,360,372,384,396,408,420,432],对于不同时间序列来说,样本数总量应该保证相同。时间序列n为(60/时间分辨率)
×
4+(60/时间分辨率)
×2×
j,j∈[0,34]。
[0045]
对于不同时间序列模型来说,均计算得到有me(即men)、mae(即maen)、rmse(即rmsen)、co(即con)、mre(即mren)有五个评价指标,为了对模型进行一个综合评价,需要计算一个综合指标。当n=24的时候(即s4.2中选择了n为24的时间序列),对所有测试样本计算预测结果与观测结果之间的mae、rmse、mre和abs(me),并计算上述评价指标的中位数,用n=[36,48,60,72,84,96,108,120,132,144,156,168,180,192,204,216,228,240,252,264,276,288,300,312,324,336,348,360,372,384,396,408,420,432]的评价指标与n=24的mae
mp
、rmae
mp
、mre
mp
、abs(me)
mp
进行比较,计算n为除了24以外的不同值时其mae、rmse、mre、abs(me)小于n=24的mae(即mae
24
)的中位数、rmse(即rmse
24
)的中位数、mre(即mre
24
)的中位数、abs(me)(即abs(me
24
))的中位数的样本占所有测试样本的百分比;计算所有co大于0.5的占总样本的百分比;即:percent(rmsei《median(rmse24)),percent(maei《median(mae24)),percent(mrei《median(mre24)),percent(abs(mei)《median(abs(me24)))和percent(coi》0.5)),计算criteriai={percent(rmsei《median(rmse24))+percent(maei《median(mae24))+percent(mrei《median(mre24))+percent(abs(mei)《median(abs(me24)))+percent(coi》0.5))},i∈[36,48,60,72,84,96,108,120,132,144,156,168,180,192,204,216,228,240,252,264,276,288,300,312,324,336,348,360,372,384,396,408,420,432]。
[0046]
寻找criteriai最大值所对应的n,即为最优长度,即用时间序列的n作为最终的外
推模型输入长度,以criteriai最大值所对应的初级集成机器学习模型作为集成机器学习模型。将满足输入时间长度的历史风速数据作为集成机器学习模型的输入,集成机器学习模型输出预测的短临风速,即未来4小时的风速。
[0047]
下面以实际应用的例子进行详述选取如东海上风电场的2018年全年激光测风雷达39m高度的平均风速作为历史风速样本;数据集时间间隔为10min,时间长度为一年,6*24*365=52560,最终筛选了36194有效样本。并将这36194个样本分成:训练样本集和测试样本集合(80%比20%),即:
[0048]
训练样本集:x_train(29275:n)y_train(29275:24)
[0049]
测试样本集:x_test(7319:n)y_test(7319:24)
[0050]
针对不同地时间长度的时间序列进行建模,并计算criteria,最终得到n=192时,criteria最大。选取n=192的时间序列所训练的模型作为最终模型,并通过交叉验证优化超参数进而得到优化后的最终模型。为了检验模型的准确能力和鲁棒性,以及考虑到在实际的应用条件下,针对单点风电场历史数据量统计较少,可能无法满足数据提供年级别的数据,本研究对数据进行了不同训练样本量的实验,分别用了一年的25%、50%和80%进行对比,为保证实验的可比性,需要保证测试赝样本均为相同的20%,即测试样本集的样本完全相同,而25%,50%和80%均从80%训练样本集中提取。选取了n=[96,108,120,132,144,156,168,180,192]的时间序列的结果进行训练,结果用平均相对误差mre进行比较,并与传统方法进行比较。图1为传统方法预测单点短临风速的平均相对误差图,图2为本发明的方法采用80%历史样本数据作为训练样本集的预测单点短临风速的平均相对误差图,图3为本发明的方法采用50%历史样本数据作为训练样本集的预测单点短临风速的平均相对误差图,图4为本发明的方法采用25%历史样本数据作为训练样本集的预测单点短临风速的平均相对误差图。针对短临预报未来4小时,传统的做法(时间分辨率为15分钟)相对误差在10%~30%(甚至50%),本发明(时间分辨率为10分钟)的相对误差大概6%~12%。即使是训练样本在25%的条件下,本发明预测的相对误差大概在7.5%~20%,也优于传统统计方法。
[0051]
因此,本发明的一种基于机器学习的单点风速短临风速外推方法的选取了最优时间序列的集成机器学习短临风速预报模型进行外推,该模型有较强的鲁棒性,并在样本数量不多的情况下也可以表现出相对优异的结果,并且优于传统方法。为陆地,特别是海上风电场的短临预报提供了一种较为泛化的策略,提升了风速预报效果。
[0052]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1