一种边缘环境下基于温度矩阵的数据放置方法
1.本发明涉及边缘计算领域中的数据放置方法,特别是涉及一种边缘环境下基于温度矩阵的数据放置方法。
背景技术:
2.数据规模呈现爆炸式增长趋势,使得云存储得到了广泛的应用。但同样存在网络延迟,功耗成本等问题。边缘计算的出现让数据接近于网络边缘,使得它成为网络计算的一个很好的补充。然而,无论是在云计算还是边缘计算领域,以往的研究中仅仅针对技术、架构进行的放置优化。而对数据本身的时空特性常常容易被忽略。
3.服务供应商作为盈利型企业,利益最大化是他们非常关心的问题。因此供应商希望在保证用户的服务要求的同时尽可能的降低自己的运营成本,在边缘计算环境中进行数据放置成为当前研究的热门之一。边缘服务的出现能够有效的为应用提供实时、高带宽、低延迟的访问。目前已有结合边缘环境中对内容放置的研究,但缺少基于边缘环境下对于数据放置的各个目标的优化研究,且大多数的研究多是针对算法方面的优化,缺少与数据本身时空特性的结合。
技术实现要素:
4.本发明所要解决的技术问题是提供一种边缘环境下基于温度矩阵的数据放置方法,能够结合数据本身的时空特性进行优先放置。
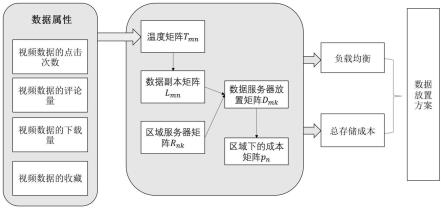
5.本发明解决其技术问题所采用的技术方案是:提供一种边缘环境下基于温度矩阵的数据放置方法,包括以下步骤:
6.(1)建立同一数据块在不同区域下的数据温度计算模型,得到数据温度值;
7.(2)记录数据在不同区域下的温度值,得到数据温度矩阵;
8.(3)定义用来记录不同区域下的服务器的区域服务器矩阵r
nk
;
9.(4)根据所述数据温度矩阵对数据进行副本选择放置,得到数据副本矩阵;
10.(5)利用所述数据副本矩阵和所述区域服务器矩阵r
nk
得到数据服务器矩阵;
11.(6)根据所述数据服务器放置矩阵结合所述区域服务器矩阵r
nk
得到区域下的数据放置成本矩阵集合;
12.(7)利用匈牙利算法对所述数据放置成本矩阵集合进行数据优化放置,获得在当前问题场景下最优的数据放置方案。
13.所述步骤(1)具体包括:
14.(11)根据点击观看次数、评论量、下载量和收藏量计算每个数据块的重要程度;
15.(12)根据所述每个数据块的重要程度计算每个数据块的相对权重;
16.(13)根据所述每个数据块的相对权重和数据温度的变化特征定义建立数据温度计算模型,并根据所述数据温度计算模型计算当前数据的温度值。
17.所述步骤(11)中通过xi=0.8*(dc+d
t
+dd)+0.2*df计算每个数据块的重要程度,其
中,xi为第i个数据块的重要程度,dc为第i个数据块的点击观看次数,d
t
为第i个数据块的评论量,dd为第i个数据块的下载量,df为第i个数据块的收藏量。
18.所述步骤(12)中通过计算每个数据块的相对权重,其中,wi为第i个数据块的相对权重,xi为第i个数据块的重要程度,m表示数据块的总数。
19.所述步骤(13)中数据温度计算模型为h=w*h0*e-kt
,其中,h表示当前数据的温度值,w表示当前数据块的相对权重,h0表示当前数据的初始温度,k表示衰减系数,t表示时间周期。
20.所述步骤(4)具体为:根据所述数据温度矩阵按照区域温度高低进行选择适合的数据;根据延迟计算公式得到满足延迟的数据副本矩阵其中,将数据m在区域中满足延迟的放置区域记为1,否则记为0。
21.所述步骤(5)中数据服务器矩阵其中,将数据m在某区域服务器k中放置记为1,否则记为0。
22.所述步骤(6)中所述数据放置成本矩阵集合表示为pn=[p1,p2,p3,...,pn],其中,c
k,m
表示为服务器k存储数据块m的成本值。
[0023]
有益效果
[0024]
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明首先提供了一种数据温度矩阵的计算方法。第一阶段提出基于温度矩阵的副本选择算法,根据温度矩阵有效筛选适合的数据减少不必要的资源消耗,同时进行延迟计算,得到满足延迟的数据副本矩阵。基于数据副本矩阵,第二阶段通过改进的匈牙利算法,基于数据副本矩阵和区域服务器矩阵得到的数据服务器矩阵以及同时得到的成本矩阵。通过判断每个区域下的数据块和服务器个数,采用改进的匈牙利算法考虑负载均衡和成本得到满足延迟的数据优化放置方案。给出的数据放置方案既能够满足用户的服务质量要求,又能够有效降低成本。
附图说明
[0025]
图1是本发明实施方式的流程图;
[0026]
图2是本发明实施方式在不同数据块块数下于一实施例中的成本对比图;
[0027]
图3是本发明实施方式在不同数据块块数下于一实施例中的负载率对比图。
具体实施方式
[0028]
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人
员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
[0029]
本发明的实施方式涉及一种边缘环境下基于温度矩阵的数据放置方法,如图1所示,包括以下步骤:
[0030]
步骤a,建立并计算同一数据块在不同区域下的数据温度计算模型,作为数据副本选择判断标准。
[0031]
本步骤具体为:
[0032]
步骤a1、每个数据块di的重要程度xi由点击观看次数,评论量,下载量,收藏量进行评估计算,其中点击观看次数,评论量和下载量占0.8,收藏量占0.2比重,如下所示:
[0033]
xi=0.8*(dc+d
t
+dd)+0.2*df[0034]
上式中,dc是用户访问视频数据的点击次数;d
t
是用户对视频数据的评论量;dd表示用户对视频的下载量;df是用户对视频的收藏;
[0035]
步骤a2、计算每个数据块di的相对权重wi,其是由步骤a1得到的该数据的重要程度xi相对其他数据所有重要程度的比值所决定,如下所示:
[0036][0037]
上式中,是由该数据的重要程度相对其他数据所有重要程度的比值所决定,其中,m为数据块的总数;
[0038]
步骤a3、根据步骤a2计算得到的数据的相对权重wi和数据温度的变化特征定义当前数据温度值,如下所示:
[0039]
h=w*h0*e-kt
[0040]
上式中,h为当前数据的温度值,w表示当前数据块的相对权重,h0表示初始温度,k为衰减系数,t表示时间周期。
[0041]
步骤b,基于步骤a构建数据温度矩阵,记录数据在不同区域下的温度值,如下所示
[0042][0043]
上式中,t
mn
表示存储数据在不同区域下的温度值,即数据m在区域n下的温度值。
[0044]
步骤c,定义区域服务器矩阵r
nk
用来记录不同区域下的服务器,如下所示:
[0045][0046]
步骤d,对数据进行副本选择放置。具体包括:
[0047]
步骤d1、使用步骤b计算得到的每个数据块在不同区域下的温度矩阵,按照区域温度高低进行适合的数据选择;
[0048]
步骤d2、根据延迟计算公式,得到满足延迟的数据副本矩阵l
mn
,如下所示:
[0049]
[0050]
上式中,将数据m在区域中满足延迟的放置区域记为1,否则记为0。
[0051]
步骤e,利用数据副本矩阵l
mn
和步骤c定义的区域服务器矩阵r
nk
得到数据服务器矩阵d
mk
,如下所示:
[0052][0053]
上式中,将数据m在某区域服务器k中放置记为1,否则记为0。
[0054]
步骤f,对步骤e得到的数据服务器矩阵d
mk
结合步骤c得到的区域服务器矩阵r
nk
,得到区域下的数据放置成本矩阵集合pn=[p1,p2,p3,...,pn];其中,c
k,m
表示为服务器k存储数据块m的成本值。
[0055]
步骤g,利用匈牙利算法对步骤f生成的数据放置成本矩阵集合进行数据优化放置,获得在当前问题场景下最优的数据放置方案。
[0056]
图2是本发明实施方式在不同数据块块数下于一实施例中的成本对比图;图3是本发明实施方式在不同数据块块数下于一实施例中的负载率对比图。通过图2和图3可以发现本发明有效的保证数据放置的负载均衡和成本效益。
[0057]
不难发现,本发明提供了温度概念及其计算模型,在此基础上构建了数据温度矩阵,以及提出一种基于温度矩阵的数据副本选择算法,可以得到满足延迟的数据副本放置方案;同时又提出基于数据副本矩阵的匈牙利算法能够在满足用户延迟的同时,有效的保证数据放置的负载均衡和成本效益。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1