一种Kubernetes资源巡检方法、系统及设备与流程
一种kubernetes资源巡检方法、系统及设备
技术领域
1.本发明涉及云原生体系下的容器编排领域,尤其涉及一种kubernetes资源巡检方法、系统及设备。
背景技术:
2.当升级完一个基础软件,例如kubelet,或者在选择的节点上创建完macvlan对应虚拟设备后,往往需要在每个节点上进行验证检查,通常的做法是在对应的节点上存在常驻的管理pod,定时针对不同的资源做巡检,上述检查,通常在很长一段时间内只需要执行一次,或者在需要时临时触发,在这种情况下,当需要巡检的资源较多时,常驻的管理pod,会消耗较多的cpu、内存或网络等资源。
3.因此,如何减少云原生系统中资源巡检的次数及巡检消耗的集群资源,是目前亟待解决的问题。
技术实现要素:
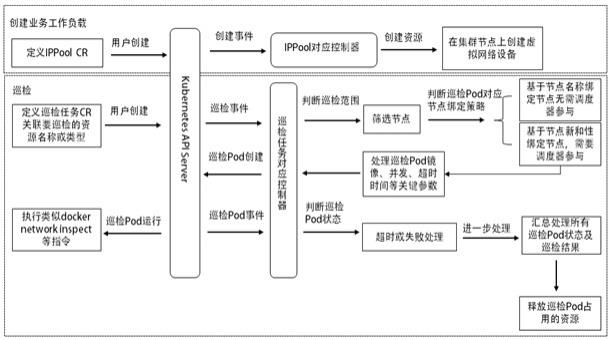
4.有鉴于此,本发明提供了一种kubernetes资源巡检方法、系统及设备,以减少资源巡检次数及巡检消耗的集群资源。具体而言,本发明提供了如下技术方案:一方面,本发明提供了一种kubernetes资源巡检方法,所述方法包括:步骤1、向kubernetes api server提交crd创建请求,初始化巡检管理中相应的crd,并部署巡检核心管理控制器;巡检核心管理控制器用于监听巡检任务cr;步骤2、根据crd创建请求创建业务工作负载,并设置与crd对应的ippool控制器监听cr资源,以完成目标巡检资源的创建;步骤3、向kubernetes api server提交创建巡检任务cr的请求,当巡检任务cr创建完成后,则处于等待调度状态;步骤4、巡检核心管理控制器通过与kubernetes api server建立长连接的方式获取巡检任务请求,执行对巡检任务cr的巡检。
5.优选的,步骤2中,目标巡检资源的创建,可以通过以下方式:向kubernetes api server提交业务工作负载对应的crd创建请求,并部署业务工作负载对应管理控制器,业务工作负载对应管理控制器监听业务工作负载对应的cr资源(例如ippool实例),创建工作负载,以完成目标巡检资源的创建。
6.优选的,所述步骤1中,所述巡检核心管理控制器通过incluster模式与kubernetes api server建立长连接。
7.优选的,所述步骤2中,在接收到虚拟网络创建请求时,所述ippool控制器将校验ip子网是否合法,并同时校验待创建的虚拟网络是否已存在,以保证对应的node节点上创建对应的虚拟网络。
8.优选的,所述步骤2中,与crd对应的ippool控制器与宿主机共享网络协议栈。
9.优选的,所述步骤3中,所述巡检任务cr的信息包括:镜像定义、容器运行对应的命
令、并发参数、超时时间、失败重试次数。
10.优选的,所述步骤4中,执行对巡检任务cr的巡检,具体包括:步骤401、获取巡检任务cr实例的信息;步骤402、判断巡检任务cr实例是否存在管理标签,如不存在,则补全管理标签,并更新巡检任务cr实例的标签,进入下一步;如存在,则直接进入下一步;步骤403、判断巡检任务cr实例是否已完成,若已完成,则汇总巡检结果,并释放资源,完成巡检;否则,进入下一步;步骤404、判断巡检任务cr实例的起始时间是否已设置,若无,则设置起始时间为当前时间,若已设置,则进入下一步;步骤405、判断巡检任务cr实例中phase是否已设置,若无,则将phase状态设置为运行中;若已设置,则进入下一步;步骤406、获取巡检任务cr实例所管理的全部巡检pod实例;步骤407、获取巡检任务cr实例所管理的全部巡检pod对应的node与巡检pod的映射表;步骤408、获取集群中所有的node列表,作为候选node列表;步骤409、基于巡检pod实例的状态,对获取到的巡检任务cr实例所管理的全部巡检pod实例进行过滤分类,并将对应的巡检pod加入到对应类型的巡检pod列表;所述巡检pod列表的类型包括failed类、active类、succeeded类;步骤410、遍历候选node列表中的所有node,并基于node与巡检pod列表中对应的匹配项的匹配处理,以筛选出waitingforrunpod node列表,作为新的巡检pod调度的node列表,并同时获取需要被清理的巡检pod实例;步骤411、判断巡检任务cr实例状态中的phase,若phase对应状态为phasefailed,则更新更新重新调度延时,重新进入队列,并等待下一次处理;否则进入下一步;步骤412、判断巡检任务cr实例中spec对应的phase的状态,若spec对应的phase的状态为paused,且巡检任务cr实例状态中的phase状态为phaserunning或phasepaushed,则更新重新调度延时,重新进入队列,并等待下一次处理;否则进入下一步;步骤413、判断巡检任务cr实例中spec对应的phase的状态,若spec对应的phase的状态为非paused,且巡检任务cr实例状态中的phase状态为phasepaushed,则更新重新调度延时,重新进入队列,并等待下一次处理;否则进入下一步;步骤414、判断巡检任务cr实例状态是否为失败,若为失败,则针对巡检任务cr实例对应的巡检pod进行清理或重新进入队列或继续巡检处理;若为非失败,则当delete pod列表不为空时,清理delete pod列表对应的巡检pod,释放集群资源,否则执行下一步;步骤415、如果巡检任务cr实例的deletiontimestamp未设置,且waitingforrunpod node列表不为空,则进行巡检pod调度处理;步骤416、巡检pod在对应的node上运行以执行巡检命令,并监控巡检pod,在监控中基于获取的巡检任务cr实例,执行对应的巡检任务cr实例的状态处理;步骤417、获取巡检任务pod的执行情况及巡检任务pod所属巡检任务cr实例,并将获取到的巡检任务cr实例信息发送至步骤401,并执行步骤401的对应操作。
11.优选的,所述步骤410中,所述的匹配处理包括:
步骤4101、若匹配项存在,则针对匹配子项逐项匹配;当满足全部匹配子项的条件时,则将对应的node加入desired node列表;若任一匹配子项的条件不满足,且巡检pod的deletiontimestamp已设置,则将该node加入delete pod列表,以准备清理对应的巡检pod;步骤4102、若匹配项不存在,则初始化巡检pod实例,针对匹配子项逐项匹配,当满足全部匹配子项的条件时,则将对应的node加入waitingforrunpod node列表。
12.优选的,所述匹配子项包括以下子项的任意组合:匹配子项1:host匹配处理;匹配子项2:nodeselector 匹配处理;匹配子项3:node taints 匹配处理;匹配子项4:node unschedulable 匹配处理;匹配子项5:当前node上已调度的pod数量限定匹配。
13.优选的,所述步骤414进一步包括:若判断巡检任务cr实例状态为失败,则设置如下处理策略:failfast、typepause、continue,相应的处理策略如下:failfast:即中断当前巡检任务cr实例处理,同时巡检任务cr实例满足超时条件,则清理巡检任务cr实例对应的巡检pod,释放资源;typepause:即暂停当前巡检任务cr实例处理,更新重新调度延时,重新进入队列,等待下一次处理;continue:即继续当前巡检任务cr实例处理,直至所有巡检pod运行完成。
14.优选的,所述步骤415中,所述进行巡检pod调度处理具体包括:若当前处理active状态的巡检pod个数大于并发参数,上报阈值超限事件,中断当前处理;或者若当前处理active状态的巡检pod个数小于等于并发参数,则计算真正的并发值;基于所述真正的并发值并发地创建巡检pod。
15.优选的,所述计算真正的并发值采用以下方式:batchsize = min(parallelism-active, waiting)其中,waiting为waitingforrunpod node列表长度,parallelism为设置的并发值,active为active类型关联的巡检pod列表长度,函数min为取参数值当中的最小值。
16.此外,本发明还提供了一种kubernetes资源巡检系统,所述系统包括:部署模块,用于向kubernetes api server发送crd创建请求,并初始化巡检管理中相应的crd,并在集群中部署巡检核心管理控制器;核心管理控制器,用于监听巡检任务cr;巡检资源创建模块,用于根据crd创建请求创建业务工作负载,并设置与crd对应的ippool控制器监听cr资源,以完成目标巡检资源的创建;巡检任务创建模块,用于向kubernetes api server提交创建巡检任务cr的请求,并创建巡检任务cr,当巡检任务cr创建完成后,则处于等待调度状态;巡检模块,用于通过调动巡检核心管理控制器与kubernetes api server建立长连接的方式获取巡检任务请求,执行对巡检任务cr的巡检。
17.优选的,所述巡检模块包括:巡检任务cr事件接入单元,用于获取巡检任务cr实例的信息;判断单元,判断巡检任务cr实例是否存在管理标签,如不存在,则通知处理单元补全管理标签,并更新巡检任务cr实例的标签;判断巡检任务cr实例是否已完成;判断巡检任
务cr实例的起始时间是否已设置,若无,则通知处理单元设置起始时间为当前时间;判断巡检任务cr实例中phase是否已设置,若无,则通知处理单元将phase状态设置为运行中;判断巡检任务cr实例状态中的phase对应的状态,以及巡检任务cr实例中spec对应的phase的状态;处理单元,获取巡检任务cr实例所管理的全部巡检pod实例、巡检任务cr实例所管理的全部巡检pod对应的node与巡检pod的映射表,以及获取集群中所有的node列表,作为候选node列表;基于巡检pod实例的状态,对获取到的巡检任务cr实例所管理的全部巡检pod实例进行过滤分类,并将对应的巡检pod加入到对应类型的巡检pod列表;以及遍历候选node列表中的所有node,并基于node与巡检pod列表中对应的匹配项的匹配处理,以筛选出waitingforrunpod node列表,作为新的巡检pod调度的node列表,并同时获取需要被清理的巡检pod实例;以及判断巡检任务cr实例状态是否为失败,若为失败,则针对巡检任务cr实例对应的巡检pod进行清理或重新进入队列或继续巡检处理;若为非失败,则当delete pod列表不为空时,清理delete pod列表对应的巡检pod,释放集群资源;如果巡检任务cr实例的deletiontimestamp未设置,且waitingforrunpod node列表不为空,则进行巡检pod调度处理;巡检pod在对应的node上运行以执行巡检命令,并监控巡检pod,在监控中基于获取的巡检任务cr实例,执行对应的巡检任务cr实例的状态处理;以及判断巡检任务cr实例的状态是否为已完成,若是,释放资源。
18.又一方面,本发明还提供了一种kubernetes资源巡检设备,所述设备包括处理器、存储设备,所述存储器存储可由处理器读取的指令;所述处理器用于调用所述存储器中的指令,以执行如上所述的kubernetes资源巡检方法。
19.与现有技术相比,本方案接收创并创建业务工作负载;创建核心管理控制器crd;部署核心管理控制器operator;创建核心管理控制器cr;部署核心管理控制器operator接收巡检请求后在设定的node范围内,保证每个node上有且只有一个相同类型的巡检pod运行,并且在运行过程中实现对巡检执行情况的监控,且在运行完成后,能够确保巡检pod的回收并释放资源,有效减少集群资源的占用。
附图说明
20.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
21.图1为本发明实施例的巡检执行流程图;图2为本发明实施例的执行步骤示意图。
具体实施方式
22.下面结合附图对本发明实施例进行详细描述。应当明确,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
23.本领域技术人员应当知晓,下述具体实施例或具体实施方式,是本发明为进一步解释具体的发明内容而列举的一系列优化的设置方式,而该些设置方式之间均是可以相互结合或者相互关联使用的,除非在本发明明确提出了其中某些或某一具体实施例或实施方式无法与其他的实施例或实施方式进行关联设置或共同使用。同时,下述的具体实施例或实施方式仅作为最优化的设置方式,而不作为限定本发明的保护范围的理解。
24.实施例1:在一个具体的实施例中,如图1、2所示,其示出了本技术实施例提供的一种kubernetes资源巡检方法的流程图,该方法的具体步骤可以通过如下方式来实现:步骤1,向kubernetes api server提交crd(custom resource definition,即自定义资源)创建请求,初始化巡检管理相应的crd。其中,kubernetes api server是kubernetes中的一个组件,用来接收资源创建/更新/删除等相关的请求。
25.在crd初始化完成后,在kubernetes集群中部署巡检核心管理控制器,具体的在执行层面上,即在集群中部署各个巡检核心管理控制器对应的计算机程序。
26.巡检核心管理控制器对应的程序启动后,优选的,通过incluster模式与kubernetes api server建立长连接,并监听(即执行watch功能)巡检任务对应的cr(custom resource,即定制资源)。
27.此时,巡检核心管理控制器处于就绪状态,等待接收处理巡检请求。
28.步骤2,创建目标巡检资源。根据crd创建请求创建业务工作负载,在一个具体的实施方式中,如图1中所示的,此处我们自定义一类业务工作负载实例ippool。
29.在一个更为优选的方式中,此处的ippool可以是自定义的cr,cr中可以定义如网络名称、网络类型、子网网段、掩码、网关、是否支持ipv6等关键要素,此时cr的示例可以具体如下:apiversion: network.tiduyun.com/v1alpha1kind: ippoolmetadata:name: network1spec:type: macvlannetwork: 192.168.0.0gateway: 192.168.0.1interface: eth0mask: 255.255.255.0ippool控制器是对应crd实现,它会监听 ippool对应的cr资源,并保证在对应的node节点上创建对应的虚拟网络,在接收到虚拟网络创建请求时,ippool控制器会校验ip子网是否合法,同时校验待创建的虚拟网络是否已存在。
30.此处,我们对于业务工作负载ippool的具体执行就一个具体的实施方式进行解释:ippool控制器会在kubernetes集群中的每个node上以incluster的模式运行一个实例,它与kubernetes api server建立长连接,监听 ippool对应的cr资源,当接收到
ippool对应的cr资源变动事件时,每个ippool控制器实例会按事件类型(例如创建或删除)做如下分支处理(以下分支基于network1这个cr实例说明):[创建分支] 当ippool对应的cr资源变动事件类型为创建时,通过docker标准network api,以rest(即通过http协议)接口方式作如下请求处理:[创建子分支1]查询虚拟设备network1是否存在,如果存在,中止处理流程,否则进行[创建子分支2];[创建子分支2]校验spec中的network、gatway及mask是否合法,interface是否存在;[创建子分支3]执行创建。[删除分支] 当ippool对应的cr资源变动事件类型为删除时,如查询虚拟设备network1是否存在,如果存在,中止处理流程,否则,执行删除操作。通过以上例举的设置操作,ippool控制器可实现与crd的一一对应,并保证在对应的node节点上创建对应的虚拟网络,且在期间校验ip子网及校验是否已存在该虚拟网络。
[0031]
这里需要说明的是,对应的ippool控制器与宿主机共享网络协议栈,在一个更为优选的实施方式中,ippool对应虚拟设备的创建示例可以如下:docker network create
ꢀ‑
d macvlan
ꢀ‑‑
subnet=192.168.0.0/23
ꢀ‑‑
gateway=192.168.0.1
ꢀ‑
o parent=eth0 network1上述示例创建了一个名称为network1,网络类型为macvlan的虚拟网络,在选定的node范围内,每个node都会存在上述虚拟网络。
[0032]
至此,目标巡检资源创建完成。
[0033]
步骤3,向kubernetes api server提交创建巡检任务cr的请求。
[0034]
在一个更为优选的实施方式中,巡检任务cr的具体定义可以包括:镜像定义、容器运行对应的命令、并发参数、超时时间、失败重试次数等,在具体的实现上,巡检任务cr的类型可以定义为inspectionjob类型,即在具体的运行环境或程序语言环境中,巡检任务cr的计算机程序表示可以采用inspectionjob,在本实施例中,也可以将inspectionjob代替所述的巡检任务cr,以方便对本方案的详细阐述。
[0035]
当巡检任务cr创建完成后,巡检任务cr就会处于等待调度状态。
[0036]
步骤4,如步骤1所述,巡检核心管理控制器已处于就绪状态,等待接收处理巡检请求,当步骤3对应的巡检任务cr(即inspectionjob)创建后,巡检核心管理控制器通过与kubernetes api server的长连接获取巡检任务请求,这一步对应图1中的巡检流程。
[0037]
在一个更为优选的实施方式 ,参考图1所示,该巡检流程阶段包括:步骤401、巡检任务cr事件接入单元,根据从kubernetes api server获取到的事件信息,获取巡检任务cr的实例详细信息。
[0038]
步骤402、判断单元,判断巡检任务cr实例是否存在管理标签,管理标签包括:名称及uid等,如不存在,巡检核心管理控制器会补全标签,更新巡检任务cr的实例标签配置,进入下一步。如存在,则直接进入下一步。
[0039]
步骤403、判断单元,判断巡检任务cr实例是否已完成,在一个更为优选的实施方式中,该判断可以是满足状态条件列表(即conditions列表)中的任一条件即视为完成,该些条件为:1、已完成,即complete==true,或者2、执行失败,即failed==true;如巡检任务cr实例状态为已完成时,则汇总巡检结果,释放资源;如果实例状态为未完成时,则进入下一步。
[0040]
步骤404、判断单元,判断巡检任务cr实例状态中的起始时间是否已设置,如无,设
置为当前时间;如已设置,则进入下一步骤。
[0041]
步骤405、判断单元,判断巡检任务cr的实例状态中phase是否已设置,如无,则将phase标志位设置为running,即运行中;如已设置,则进入下一步骤。
[0042]
步骤406、处理单元,获取巡检任务cr的实例所管理的所有巡检pod实例。
[0043]
步骤407、处理单元,获取巡检任务cr的实例所管理的所有巡检pod对应的node与巡检pod的映射表,在一个更为优选的实施方式中,该映射表中,键(即key)可以设置为nodename,值(即value)可以设置为巡检pod实例,需要说明的是,对于首次创建的巡检任务cr实例,该映射表为空。
[0044]
步骤408、处理单元,获取node列表,此处会获取集群所有node,获取到的node列表作为下一步筛选的候选node列表。
[0045]
步骤409、处理单元,将获取到的巡检任务cr实例所管理的所有巡检pod实例进行过滤分类,在一个更为优选的实施方式中,分类类别可以设置为三类,类别包括:active、failed、succeeded。
[0046]
如巡检pod状态为:succeeded,归为succeeded类别,并加入succeeded类型关联的巡检pod列表。如巡检pod状态为:failed,归为failed类别,并加入failed类型关联的巡检pod列表。如巡检pod的deletiontimestamp(即删除标识时间戳)属性已定义,在当前判断分支下如果超过重启次数,则归为failed类别,并加入failed类型关联的巡检pod列表,否则归为active类别,并加入active类型关联的巡检pod列表。
[0047]
步骤410、处理单元,处理候选node列表,遍历所有候选node,尝试根据nodename获取node与巡检pod的映射表中对应的匹配项,并进行匹配处理,以实现:已存在的巡检pod及其对应node的关联映射表筛选,并用于新的巡检pod调度的node列表,即waitingforrunpod node列表,同时获取到需要被清理的巡检pod实例。
[0048]
在一个更为优选的实施方式中,上述的匹配处理可以通过以下方式执行:步骤4101、[分支条件1]如匹配项存在,则执行:[匹配子项1]host匹配处理,即当前匹配的巡检pod中的spec.nodename未指定或与当前的nodename一致,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。
[0049]
[匹配子项2]nodeselector匹配,即根据当前巡检pod声明的nodeselector labels匹配node,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。nodeselector,即节点标签选择器,基于node上的标签筛选对应的node,标签,即labels,以key/value的方式存在。
[0050]
[匹配子项3] node taints匹配,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。taints即污点,node设置了污点后,pod将不会调度到当前node,除非pod定义容忍这个污点。
[0051]
[匹配子项4] node unschedulable匹配,根据巡检pod的spec.tolerations及node的spec.unschedulable匹配,如上述两项指标值为false,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。unschedulable即node不可调度,将阻止新 pod 调度到该节点之上,但不会影响任何已经在其上的 pod。tolerations即容忍,设置了容忍的pod将可以被调度到存在污点的node上。
[0052]
[匹配子项5]巡检pod resources匹配,如当前node上已调度的pod数量超过允许值,当前匹配不通过,中断当前处理,继续处理下一候选node;如巡检pod所需的cpu、内存、存储资源超过当前node上可分配的资源上限,中断当前处理,继续处理下一候选node;如上述检查通过,继续下一匹配项处理。resources即资源,包括如下匹配维度:1.node上允许调度的pod数量;2.pod所需cpu/内存资源是否超过node当前可分配的值等。
[0053]
如当前巡检pod及匹配到的node满足上述所有匹配子项条件,则将匹配到的node加入desired node列表。在一个更为优选的实施方式中,desired node列表是对候选node列表进一步筛选后得到的现有已有的巡检pod及node对应的关联映射列表,其中key为node name,value为pod实例,后续的巡检任务状态判断依据于此列表,比如:巡检任务是否完成等,后续不会针对该列表中的node作任何处理,即该列表为只读。
[0054]
如当前巡检pod不能匹配上述任一子项,且巡检pod的deletiontimestamp(即删除标识时间戳)已设置,意味着当前巡检pod需要被清理,则将匹配到的node加入delete pod列表。
[0055]
此处需要说明的是,该步骤4101中上述的匹配子项1-5的匹配判断顺序,可以基于实际逻辑需要或者用户习惯进行顺序上单独调整或修改,并且本实施例中的上述顺序仅为便于表述而设置,本领域技术人员理解,上述的顺序并不能作为匹配子项判断的顺序上的限定或限制来理解,即对上述匹配子项1-5中的匹配判断顺序上的任何调整,都应当视为落入本发明的保护范围之内。
[0056]
步骤4102、[分支条件2] 如匹配项不存在,初始化巡检pod实例结构,进入[分支条件1]下的所有匹配子项,如当前巡检pod及匹配到的node满足上述所有匹配子项条件,加入waitingforrunpod node列表,若不满足条件,则继续下一个node匹配处理,最坏的情况是最后获取到的waitingforrunpod node列表为空,即没有满足条件的node用于调度。此处,更为优选的,获取到的waitingforrunpod node列表用于后一巡检pod的调度,巡检核心控制管理器将按照调度一定的算法为新创建的巡检pod分配对应的node。
[0057]
此处具体的[分支条件1]的判断为:[匹配子项1]host匹配处理,即当前匹配的巡检pod中的spec.nodename未指定或与当前的nodename一致,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。
[0058]
[匹配子项2]nodeselector匹配,即根据当前巡检pod声明的nodeselector labels匹配node,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。nodeselector,即节点标签选择器,基于node上的标签筛选对应的node,标签,即labels,以key/value的方式存在。
[0059]
[匹配子项3] node taints匹配,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。taints即污点,node设置了污点后,pod将不会调度到当前node,除非pod定义容忍这个污点。
[0060]
[匹配子项4] node unschedulable匹配,根据巡检pod的spec.tolerations及node的spec.unschedulable匹配,如上述两项指标值为false,当前匹配通过,继续下一匹配项处理,否则中断当前处理,继续处理下一候选node。unschedulable即node不可调度,将阻止新 pod 调度到该节点之上,但不会影响任何已经在其上的 pod。tolerations即容忍,
设置了容忍的pod将可以被调度到存在污点的node上。
[0061]
[匹配子项5]巡检pod resources匹配,如当前node上已调度的pod数量超过允许值,当前匹配不通过,中断当前处理,继续处理下一候选node;如巡检pod所需的cpu、内存、存储资源超过当前node上可分配的资源上限,中断当前处理,继续处理下一候选node;如上述检查通过,继续下一匹配项处理。resources即资源,包括如下匹配维度:1.node上允许调度的pod数量;2.pod所需cpu/内存资源是否超过node当前可分配的值等。
[0062]
此处需要说明的是,该步骤4102中上述的匹配子项1-5的匹配判断顺序,可以基于实际逻辑需要或者用户习惯进行顺序上单独调整或修改,并且本实施例中的上述顺序仅为便于表述而设置,本领域技术人员理解,上述的顺序并不能作为匹配子项判断的顺序上的限定或限制来理解,即对上述匹配子项1-5中的匹配判断顺序上的任何调整,都应当视为落入本发明的保护范围之内。
[0063]
综上所述,经过上述的处理后,处理单元可以完成了如下数据筛选:已存在的巡检pod及其对应node的关联映射表筛选;可以用于新的巡检pod调度的node列表,即waitingforrunpod node列表;需要被清理的巡检pod实例。
[0064]
步骤411、判断单元,如果巡检任务cr(即inspectionjob)实例对应的状态中的phase为phasefailed,此处可能是并发处理冲突,或状态临时不可用,则更新重新调度延时,重新进入队列,等待下一次处理;否则进入下一判断或处理单元。此处,phase即阶段,用来标识pod生命周期的不同阶段,在一个更为优选的实施方式中,其枚举值可设置为:phasecompleted、phaserunning、phasepaused及phasefailed等。
[0065]
对于重新调度延时,当巡检任务cr实例状态为phasefailed时,巡检核心控制管理器会按一定的延时尝试重试,该延时即为:重新调度延时。
[0066]
步骤412、判断单元,如果巡检任务cr(即inspectionjob)实例spec中对应的phase为paused,且状态中的phase为phaserunning或phasepaushed,此处意味着当前巡检任务暂停,则更新重新调度延时,重新进入队列,等待下一次处理;否则进入下一判断或处理单元。此处,spec全称为specification,即规格定义。
[0067]
步骤413、判断单元,如果巡检任务cr(即inspectionjob)实例spec中对应的phase为非paused,且巡检任务cr实例状态中的phase为phasepaushed,此处意味着当前巡检任务继续,更新重新调度延时,重新进入队列,等待下一次处理;否则进入下一判断或处理单元。
[0068]
步骤414、处理单元,判断巡检任务cr(即inspectionjob)实例状态是否为失败,根据前述处理单元获取的failed类型关联的巡检pod列表,如果该列表长度大于0,意味着至少一个巡检pod巡检失败了,在一个更为优选的实施方式中,如果存在pod巡检失败,则可以设置如下几种处理失败处理策略:failfast、typepause、continue,分支条件判断如下:[分支条件1]如果失败处理策略为 failfast,即中断当前巡检任务cr(即inspectionjob)实例处理,同时巡检任务cr(即inspectionjob)实例满足deadlineexceeded(即超过时限)条件,则清理巡检任务cr(即inspectionjob)实例对应的巡检pod,释放集群资源;[分支条件2]如果失败处理策略为 typepause,即暂停当前巡检任务cr(即inspectionjob)实例处理,更新重新调度延时,重新进入队列,等待下一次处理;[分支条件3]如果失败处理策略为 continue,即继续当前巡检任务cr(即
inspectionjob)实例处理,直至所有巡检pod运行完成(成功或失败)。
[0069]
处理单元,巡检任务cr(即inspectionjob)实例状态是否为非失败情况下,如果前述对应的delete pod列表不为空,清理delete pod列表对应的巡检pod,释放集群资源。若对应的delete pod列表为空,意味着当前时刻没有需要清理的pod,则继续执行后续的处理。
[0070]
步骤415、处理单元,如果巡检任务cr(即inspectionjob)实例deletiontimestamp(即删除标识时间戳)未设置且之前处理的waitingforrunpod node列表不为空,进行巡检pod调度处理,分支条件判断如下:[分支条件1]如果当前处理active状态的巡检pod个数大于并发参数,上报阈值超限事件,中断当前单元处理逻辑。
[0071]
[分支条件2]如当前处理active状态的巡检pod个数小于并发参数(此处,batchsize是计算出来的,若巡检pod个数等于并发参数, min(parallelism-active, waiting)的结果为0,则没有意义),计算真正的并发值,算法如下:定义变量waiting为waitingforrunpod node列表长度;定义变量parallelism为设置的并发值;定义变量active为active类型关联的巡检pod列表长度;定义变量batchsize为计算后的并发值;函数min为取参数值当中的最小值,则:batchsize = min(parallelism-active, waiting)巡检核心管理控制器通过计算出的batchsize,并发地开启线程或协程创建巡检pod,巡检pod的核心配置为spec.affinity,巡检核心管理控制器会将需要创建的巡检pod与选定的node通过node affinity的方式绑定,从而达到在每个node上只有一个相同类型的巡检pod运行的目的,同时巡检核心管理控制器会设置巡检pod的owner reference为自身,在这之后,巡检核心管理控制器会请求kubernetes api server,进行巡检pod的创建。
[0072]
步骤416、处理单元,巡检pod在对应的node上运行,运行容器里定义好的巡检命令,如本示例中的:docker network inspect network1,当虚拟网络network1不存在时,该指令执行返回码会为非0的整数,非0的整数意味着巡检失败。
[0073]
此外,更为优选的,处理单元进行巡检pod监控,巡检核心管理控制器通过与kubernetes api server的长连接,获取巡检pod的状态,通过巡检pod的owner reference获取对应的巡检任务cr(即inspectionjob)实例,提交至巡检任务cr(即inspectionjob)实例相应队列,并进行相应分支流程的巡检任务cr(即inspectionjob)实例状态处理。此处,owner reference,即资源所属对象的引用,这里指的是巡检pod所属巡检任务cr实例信息。
[0074]
步骤417、处理单元,判断巡检任务cr(即inspectionjob)实例状态是否为已完成,在一个更为优选的实施方式中,此处定义变量status表达巡检任务cr(即inspectionjob)实例状态,并进行状态判断:分支条件如下:[分支条件1] 如desired node列表为空,意味着巡检任务cr(即inspectionjob)实例对应巡检任务pod已全部运行完成,设置status为:phasecompleted;[分支条件2] 遍历desired node列表,获取所有巡检任务pod,如所有巡检任务
pod的状态为已完成,设置status为: phasecompleted;[分支条件3] 如failed类型关联的巡检pod列表不为空,意味着至少有一个巡检任务pod的状态为失败, 设置status为: phasefailed;[处理单元1] 如status为:phasecompleted,更新巡检任务cr(即inspectionjob)实例状态为:phasecompleted,此处具体的流程为:巡检核心管理控制器请求kubernetes api server,将当前巡检任务cr(即inspectionjob)实例的状态更新为已完成,同时汇总所有巡检任务pod执行情况,该步骤完成后,跳转至步骤401,重复步骤401及其后续步骤。由于当前步骤已设置好了巡检任务cr(即inspectionjob)实例对应的状态及属性,会有选择的执行步骤401及其后续步骤对应的处理单元或分支判断,此处主要对应了步骤414中的delete pod列表处理,即清理巡检任务pod,从而达到释放资源的效果。
[0075]
[处理单元2] 如status为: phaserunning(此时未完成,正在进行中),更新巡检任务cr(即inspectionjob)实例状态为:phaserunning,此处具体的流程为:巡检核心管理控制器请求kubernetes api server,将当前巡检任务cr(即inspectionjob)实例的状态更新为已完成,该步骤完成后,跳转至步骤401,重复步骤401及其后续步骤对应的处理单元或分支判断。
[0076]
[处理单元3] 如status为: phasefailed(此时未完成,正在进行中),更新巡检任务cr(即inspectionjob)实例状态为:phasefailed,此处具体的流程为:巡检核心管理控制器请求kubernetes api server,将当前巡检任务cr(即inspectionjob)实例的状态更新为已完成,该步骤完成后,跳转至步骤401,重复步骤401及其后续步骤对应的处理单元或分支判断。
[0077]
实施例2在又一个特定的实施例中,本发明的方案还可以通过一种kubernetes资源巡检系统的方式来实现,在一个优选的实施方式中,该系统可以设置为包括:部署模块,用于向kubernetes api server发送crd创建请求,并初始化巡检管理中相应的crd,并在集群中部署巡检核心管理控制器;核心管理控制器,用于监听巡检任务cr;巡检资源创建模块,用于根据crd创建请求创建业务工作负载,并设置与crd对应的ippool控制器监听cr资源,以完成目标巡检资源的创建;巡检任务创建模块,用于向kubernetes api server提交创建巡检任务cr的请求,并创建巡检任务cr,当巡检任务cr创建完成后,则处于等待调度状态;巡检模块,用于通过调动巡检核心管理控制器与kubernetes api server建立长连接的方式获取巡检任务请求,执行对巡检任务cr的巡检。
[0078]
在更为优选的一个实施方式中,该巡检模块包括:巡检任务cr事件接入单元,用于获取巡检任务cr实例的信息;判断单元,判断巡检任务cr实例是否存在管理标签,如不存在,则通知处理单元补全管理标签,并更新巡检任务cr实例的标签;判断巡检任务cr实例是否已完成;判断巡检任务cr实例的起始时间是否已设置,若无,则通知处理单元设置起始时间为当前时间;判断巡检任务cr实例中phase是否已设置,若无,则通知处理单元将phase状态设置为运行中;判断巡检任务cr实例状态中的phase对应的状态,以及巡检任务cr实例中spec对应的phase的状
态;处理单元,获取巡检任务cr实例所管理的全部巡检pod实例、巡检任务cr实例所管理的全部巡检pod对应的node与巡检pod的映射表,以及获取集群中所有的node列表,作为候选node列表;基于巡检pod实例的状态,对获取到的巡检任务cr实例所管理的全部巡检pod实例进行过滤分类,并将对应的巡检pod加入到对应类型的巡检pod列表;以及遍历候选node列表中的所有node,并基于node与巡检pod列表中对应的匹配项的匹配处理,以筛选出waitingforrunpod node列表,作为新的巡检pod调度的node列表,并同时获取需要被清理的巡检pod实例;以及判断巡检任务cr实例状态是否为失败,若为失败,则针对巡检任务cr实例对应的巡检pod进行清理或重新进入队列或继续巡检处理;若为非失败,则当delete pod列表不为空时,清理delete pod列表对应的巡检pod,释放集群资源;如果巡检任务cr实例的deletiontimestamp未设置,且waitingforrunpod node列表不为空,则进行巡检pod调度处理;巡检pod在对应的node上运行以执行巡检命令,并监控巡检pod,在监控中基于获取的巡检任务cr实例,执行对应的巡检任务cr实例的状态处理;以及判断巡检任务cr实例的状态是否为已完成,若是,释放资源。
[0079]
更为优选的,巡检核心管理控制器通过incluster模式与kubernetes api server建立长连接。
[0080]
当系统接收到虚拟网络创建请求时,所述ippool控制器将校验ip子网是否合法,并同时校验待创建的虚拟网络是否已存在,以保证对应的node节点上创建对应的虚拟网络。
[0081]
在一个更为优选的实施方式中,与crd对应的ippool控制器与宿主机共享网络协议栈。
[0082]
为便于对巡检任务cr的监听及巡检操作,所述巡检任务cr的信息包括:镜像定义、容器运行对应的命令、并发参数、超时时间、失败重试次数等。
[0083]
本方案在又一种特定的实施方式下,可以通过设备的方式来实现,该设备可以包括执行上述实施例1中各个或几个步骤的相应模块,或者搭载实施例2中所提供的kubernetes资源巡检系统。因此,可以由相应模块执行上述各个实施方式的每个步骤或几个步骤,并且该电子设备可以包括这些模块中的一个或多个模块。模块可以是专门被配置为执行相应步骤的一个或多个硬件模块、或者由被配置为执行相应步骤的处理器来实现、或者存储在计算机可读介质内用于由处理器来实现、或者通过某种组合来实现。
[0084]
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本方案的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本方案的实施方式所属技术领域的技术人员所理解。处理器执行上文所描述的各个方法和处理。例如,本方案中的方法实施方式可以被实现为软件程序,其被有形地包含于机器可读介质,例如存储器。在一些实施方式中,软件程序的部分或者全部可以经由存储器和/或通信接口而被载入和/或安装。当软件程序加载到存储器并由处理器执行时,可以执行上文描述的方法中的一个或多个步骤。备选地,在其他实施方式中,处理器可以通过其他任何适当的方式
(例如,借助于固件)而被配置为执行上述方法之一。
[0085]
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,可以具体实现在任何可读存储介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。
[0086]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random access memory,ram)等。
[0087]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1