一种基于事件数据驱动的视频去模糊方法
1.本发明涉及视频去模糊领域,具体说的是一种基于事件数据驱动的视频去模糊方法。
背景技术:
2.视频作为计算机视觉通信中的一个重要数据源,由于物体的运动而不可避免地存在模糊,从而影响主观感受质量以及更深层次的应用。由于在模糊过程中运动信息的显著损失,从运动模糊图像中恢复清晰的视频序列并不可行。最近,一种称为事件摄影机的新传感器被推荐用于记录和捕捉微秒级的场景强度变化,对事件摄像机来说,快速运动可以作为高时间速率的事件被捕获,从而为探索视频去模糊的解决方案提供了新的机会。传统相机的拍摄过程需要一个曝光时间,这个帧率极大地限制了事件捕获的延迟,如果物体存在高速运动,就会产生模糊;并且过曝现象也很常见,在光线极差或者亮度极高时,相机获取的信息有限,丢失了应有的细节。
3.由于卷积神经网络(cnns)的成功,基于事件驱动的去模糊技术已被广泛开发并取得了相对较好的性能。然而,这些方法仍有一些局限性。一方面,现有的视频去模糊网络直接利用事件作为额外先验,而不考虑不同事件之间的相关性。这些网络通过将强度变化压缩为一个时间步长来实现一个独立的特征映射,因此时间信息将丢失,并且无法充分利用事件的高时间分辨率。另一方面,大部分网络只是将模糊帧和事件的特征图连接起来作为卷积神经网络的输入,忽略了丰富的亮度变化信息以及事件和视频帧之间的空间一致性。此外,现有的视频去模糊网络通常基于视频中连续模糊帧的假设,并设计基于卷积神经网络和基于循环神经网络的架构,其中编码器-解码器体系结构是作为基本主干的最流行的选择。然而,一个常见的事实是,模糊并不是连续出现在视频中,即模糊中的某些帧视频非常清晰。这些锐利的帧实际上可以被用来帮助恢复模糊的帧,但在现有的视频去模糊方法中,它们被难以区分地处理,也会导致锐利的纹理丢失。事件驱动的恢复优化方法在很大程度上依赖于事件的使用,其中设计了各种架构。在这些方法中,用于利用事件的模块不容易与现有的图像和视频去模糊方法合作,从而限制了视频去模糊和事件驱动去模糊的原则框架的发展,这些问题限制了基于事件的视频去模糊原理研究的进一步发展。
技术实现要素:
4.本发明为了克服现有方法的不足之处,提供一种基于事件数据驱动的视频去模糊方法,以期能在不同情景的视频去模糊任务中达到更好的去模糊性能,从而有效提升去模糊效果。
5.本发明为解决上述技术问题,采用如下技术方案:
6.本发明为一种基于事件数据驱动的视频去模糊方法的特点是按如下步骤进行:
7.步骤1获取训练视频数据和对应的事件序列,并对事件序列进行分割:
8.步骤1.1获取训练视频数据集:
9.获取真实的模糊视频图像集,记为x={x1,x2,
…
,xi,
…
,xn},其中,xi表示第i张模糊图像,i=1,2,
…
,n,n为模糊图像的帧数量;
10.获取真实的清晰视频图像集,记为y={y1,y2,
…
,yi,
…
,yn},其中,yi表示第i张清晰图像,i=1,2,...,n,n为正常图像的总数;
11.令i={x,y}表示训练图像数据集;
12.步骤1.2对事件序列进行分割:
13.获取真实的模糊图像集x的真实事件序列;
14.将真实的模糊视频图像集x输入事件仿真器中并生成合成的事件序列;
15.根据真实的模糊视频图像集x中所包含的帧数量n,将真实事件序列和合成的事件序列分别划分成相同数量n的分段序列,记为e={e1,...,ei,...,en},ei表示第i张模糊图像xi所对应的真实和合成的事件序列,i=1,2,...,n,n为事件序列的总数;
16.步骤2构建视频去模糊神经网络,包括:编码网络、时间记忆模块、空间融合模块、解码网络;
17.步骤2.1、所述编码网络由m个残差模块和m个下采样层交替排列组成,其中,残差模块具有m个卷积层及其对应的跳线连接,卷积核大小为均为ks,步长均为s,各卷积层之间依次连接有leakrelu层和批归一化层;
18.所述第i张模糊图像xi经过所述编码网络的处理后,生成m个不同尺度的图像特征其中,u
im
表示第i张模糊图像xi在第m个尺度的图像特征;
19.步骤2.2、所述时间记忆模块包括一个公用的卷积层、两个专用的卷积层、记忆单元;
20.第i-1个事件序列e
i-1
和第i+1个事件序列e
i+1
输入公用的卷积层中进行处理,得到两者的公共特征,再分别经过两个专用的卷积层的处理,相应得到第i-1个事件序列e
i-1
的键和值以及第i+1个事件序列e
i+1
的键和值;
21.所述记忆单元将第i-1个事件序列e
i-1
的键和值以及第i+1个事件序列e
i+1
的键和值进行拼接后,再分别输入两个卷积核为1
×
1的卷积层中,输出两个卷积结果后再通过乘积运算得到第i个事件序列ei与相邻事件序列e
i-1
和e
i+1
的关联特征图;最后将所述关联特征图与第i个事件序列ei相加后,得到第i个事件特征图ci;
22.步骤2.3、所述空间融合模块包括m+1个下采样层、m个上采样层、一个卷积核为1
×
1的卷积层和融合单元;
23.所述m个不同尺度的图像特征输入所述空间融合模块中,并分别通过m个下采样层的处理,从而将m个不同尺度的图像特征调整为相同比例的图像特征,再经过一个卷积核为1
×
1的卷积层后获得第i个特征图fi;
24.所述第i个事件特征图ci通过第m+1个下采样层的处理后,得到下采样后的第i个事件特征图ci′
;
25.所述融合单元利用式(1)对所述下采样后的第i个事件特征图ci′
和第i个特征图fi进行处理,从而得到第i个融合特征图feati中第p个像素点的特征进而得到第i个融合特征图feati:
[0026][0027]
式(1)中,p、q是位置索引,表示第i个事件特征图ci′
在p位置处的特征值,f
iq
表示第i个特征图fi在q位置处的特征值,s为特征图的像素点总数;g(
·
)表示卷积操作;f(
·
,
·
)表示乘积函数,并有:
[0028][0029]
式(2)中,θ(
·
)和均表示卷积操作;
[0030]
所述第i个融合特征图feati分别经过m个上采样层的处理后,获得m个不同尺度的映射特征其中,v
im
表示第i张模糊图像xi在第m个尺度的图像特征;
[0031]
步骤2.4、所述解码网络由m个残差模块和m个上采样层交替排列组成,其中,残差模块具有m个卷积层及其对应的跳线连接,卷积核大小为均为ks,步长均为s,各卷积层之间依次连接有leakrelu层和批归一化层;
[0032]
所述m个不同尺度的映射特征经过所述解码网络的上采样层处理,获得m个尺度一致的特征图并进行拼接之后,再经过一个卷积操作,从而生成清晰图像
[0033]
步骤3、利用式(3)构建反向传播的损失函数l:
[0034][0035]
式(3)中,k为生成清晰图像的像素点数,为第i个模糊图像经过神经网络生成的去模糊图像的第k个像素点,为清晰视频图像集中第i个图像切片对应的第k个像素点;
[0036]
步骤4、基于真实的模糊图像集x及其分段序列e对视频去模糊神经网络进行训练,并计算损失函数l,同时使用自适应矩估计优化方法以学习率lrs来更新静态检测网络权值,当训练迭代次数达到设定的次数或损失误差达小于所设定的阈值时,训练停止,从而得到最优的去模糊模型;以所述最优的去模糊网络对模糊视频图像进行处理,并获得对应的清晰图像。
[0037]
与现有技术相比,本发明的有益效果在于:
[0038]
1、本发明利用事件数据驱动视频去模糊任务,在参数量少的情况下,能够实现很好的端到端的去模糊效果,并且相比现有的分割方法,减少了参数的数量,在不同数据集上具有更好的鲁棒性。实验结果表明,本发明提出的方法在gopro数据集和hqf数据集上优于最先进的方法。
[0039]
2、本发明通过注意力机制来感知相邻事件序列之间的时间关联性。为了利用事件提供的高时间分辨率信息,时间记忆模块用于计算不同事件的长期相关性,以恢复时间事件相关性,最终的去模糊网络基于这两个块构建,并以端到端的方式进行训练;查询与键之间的相似性被用来测量与当前事件的时间非局部对应关系,这将生成相应的值以感知时间变化;通过乘积运算获得t时刻事件和相邻事件序列的关联矩阵,并用于融合事件特征,通过这种方式记录不同事件之间的时间关系,更加充分地利用连续事件序列对图像去模糊的先验信息。
[0040]
3、本发明使用非局部空间融合操作将图像特征和事件特征融合。借助事件数据提供的亮度先验信息,计算图像信息和事件信息的非局部特征,以确定每个帧和事件之间的空间一致性。通过对空间及通道全局关系的建模,深层次挖掘输入特征的全局信息,从而提升了图像的去模糊性能,增加了模型的可解释性。
附图说明
[0041]
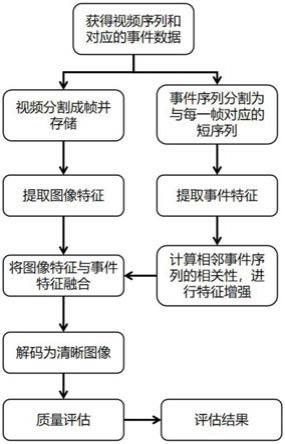
图1为发明方法流程图;
[0042]
图2为本发明的基于事件数据驱动的视频去模糊方法结构图;
[0043]
图3为本发明中时间记忆模块的结构图;
[0044]
图4为本发明中空间融合模块的结构图。
具体实施方式
[0045]
本实施例中,一种基于事件数据驱动的视频去模糊方法,具体流程参见图1,是综合考虑时间数据与视频序列的特征,并通过非局部的方式对两种数据进行融合,以达到去模糊效果,整个方法的算法结构图参见图2。具体的说,该方法是按照如下步骤进行:
[0046]
步骤1获取训练视频数据和对应的事件序列,并对事件序列进行分割:
[0047]
步骤1.1获取训练视频数据集:
[0048]
获取真实的模糊视频图像集,记为x={x1,x2,...,xi,...,xn},其中,xi表示第i张模糊图像,i=1,2,...,n,n为模糊图像的帧数量;
[0049]
获取真实的清晰视频图像集,记为y={y1,y2,...,yi,...,yn},其中,yi表示第i张清晰图像,i=1,2,...,n,n为正常图像的总数;
[0050]
令i={x,y}表示训练图像数据集;
[0051]
步骤1.2对事件序列进行分割:
[0052]
获取真实的模糊图像集x的真实事件序列;
[0053]
将真实的模糊视频图像集x输入事件仿真器中并生成合成的事件序列;
[0054]
根据真实的模糊视频图像集x中所包含的帧数量n,将真实事件序列和合成的事件序列分别划分成相同数量n的分段序列,记为e={e1,...,ei,...,en},ei表示第i张模糊图像xi所对应的真实和合成的事件序列,i=1,2,...,n,n为事件序列的总数;
[0055]
本实施例中,采用gopro数据集训练和评估模型,包括30个不同场景的视频序列,选取其中25个场景用于训练模型,其余的用于评估模型;
[0056]
步骤2构建视频去模糊神经网络,包括:编码网络、时间记忆模块、空间融合模块、解码网络;
[0057]
步骤2.1、编码网络由m个残差模块和m个下采样层交替排列组成,其中,残差模块具有m个卷积层及其对应的跳线连接,卷积核大小为均为d
×
d,步长均为s,各卷积层之间依次连接有leakrelu层和批归一化层;
[0058]
第i张模糊图像xi经过编码网络的处理后,生成m个不同尺度的图像特征其中,u
im
表示第i张模糊图像xi在第m个尺度的图像特征;
[0059]
本实施例中,如图2所示,m取3,卷积核大小为3
×
3,步长为1,每层卷积核数分别为64、128、256;卷积层之间通过跳连结构实现不同层之间的空间信息共享,使得高层输出图
像带有低级的细节特征,充分提取特征图的空间尺度特征,提升去模糊的质量;
[0060]
步骤2.2、时间记忆模块包括一个公用的卷积层、两个专用的卷积层、记忆单元,所述时间记忆模块的具体结构如图3所示;
[0061]
第i-1个事件序列e
i-1
(前邻近事件序列)和第i+1个事件序列e
i+1
(后邻近事件序列)输入公用的卷积层中进行处理,得到两者的公共特征,再分别经过两个专用的卷积层的处理,相应得到第i-1个事件序列e
i-1
的键和值以及第i+1个事件序列e
i+1
的键和值;
[0062]
记忆单元将第i-1个事件序列e
i-1
的键和值以及第i+1个事件序列e
i+1
的键和值进行拼接后,再分别输入两个卷积核为1
×
1的卷积层中,输出两个卷积结果后再通过乘积运算得到第i个事件序列ei与相邻事件序列e
i-1
和e
i+1
的关联特征图;最后将关联特征图与第i个事件序列ei相加后,得到第i个事件特征图ci;
[0063]
步骤2.3、空间融合模块包括m+1个下采样层、m个上采样层、一个卷积核为1
×
1的卷积层和融合单元;本实施例中,m取3,并提供更多尺度的输入视角来感知输入图像的整体结构,所述空间融合模块的具体结构如图4所示;
[0064]
m个不同尺度的图像特征输入空间融合模块中,并分别通过m个下采样层的处理,从而将m个不同尺度的图像特征调整为相同比例的图像特征,再经过一个卷积核为1
×
1的卷积层后获得第i个特征图fi;
[0065]
第i个事件特征图ci通过第m+1个下采样层的处理后,得到下采样后的第i个事件特征图ci′
;
[0066]
融合单元利用式(1)对下采样后的第i个事件特征图ci′
和第i个特征图fi进行处理,得到第p个像素点的特征从而得到第i个融合特征图feati:
[0067][0068]
式(1)中,p、q是位置索引,表示第i个事件特征图ci′
在p位置处的特征值,f
iq
表示第i个特征图fi在q位置处的特征值,其中s为特征图的像素点总数;g(
·
)表示卷积操作;f(
·
,
·
)表示乘积函数,并有:
[0069][0070]
式(2)中,θ(
·
)和均表示卷积操作;
[0071]
第i个融合特征图feati分别经过m个上采样层的处理后,获得m个不同尺度的映射特征其中,v
im
表示第i张模糊图像xi在第m个尺度的图像特征;
[0072]
步骤2.4、解码网络由m个残差模块和m个上采样层交替排列组成,其中,残差模块具有m个卷积层及其对应的跳线连接,卷积核大小为均为d
×
d,步长均为s,各卷积层之间依次连接有leakrelu层和批归一化层;本实施例中,m取3,卷积核大小为3
×
3,步长为1,每层卷积核数分别为256、128、64;
[0073]
m个不同尺度的映射特征经过解码网络的处理后,每一个映射特征均会经过一个上采样层,获得m个尺度一致的特征图,拼接之后,再经过一个卷积操作获得生成的清晰图像
[0074]
步骤3、利用式(3)构建反向传播的损失函数l,在二范数空间中最小化生成结果与真实
[0075]
前景标注图像之间的损失,在低频信息段提高生成结果的质量:
[0076][0077]
式(3)中,k为图像的像素点数,为第i个模糊图像经过神经网络生成的去模糊图像的第k个像素点,为清晰视频图像集中第i个图像切片对应的第k个像素点;
[0078]
步骤4、基于真实的模糊图像集x及其分段序列e对视频去模糊神经网络进行训练,并计算损失函数l,并使用自适应矩估计优化方法以学习率lrs来更新静态检测网络权值,本实例中学习率lrs取5e-5,当训练迭代次数达到设定的次数或损失误差达小于所设定的阈值时,训练停止,从而得到最优的去模糊模型;以最优的去模糊网络对模糊视频图像进行处理,并获得对应的清晰图像。
[0079]
实施例
[0080]
为了验证本发明方法中的有效性,本实施例中选用了常用的gopro数据集和hqf数据集用于训练和测试。
[0081]
该方法是基于gopro数据集进行训练的,该数据集由合成事件、2103对模糊帧和清晰的真实背景帧组成。为了获得事件数据,使用v2e生成相应的事件序列,同时考虑到高斯分布n(0.18,0.03)中像素级的不同合同阈值。对于真实世界事件的评估,使用hqf数据集,包括真实世界捕获的真实事件数据,davis240c是一种基于动态事件的视觉传感器,用于报告亮度变化。模糊帧是使用与gopro数据集相同的策略生成的。在gopro测试数据集上进行测试时,帧对的数量是1111。
[0082]
本发明中采用结构相似度(psnr)和峰值信噪比(ssim)作为评价指标。
[0083]
本实施例中选用五种方法和本发明方法进行效果对比,所选方法分别是ledvi,esl-net,csd,stfan,red-net,stra为发明方法。
[0084]
根据实验结果可得出结果如表1和表2所示:
[0085]
表1本发明方法与选用的五种对比方法在hqf数据集上进行去模糊的实验结果
[0086] ledviesl-netcsdstfanred-netstrapsnr22.2225.4224.7124.1725.7227.54ssim0.6870.7540.7240.7110.7630.834
[0087]
表2本发明方法与选用的五种对比方法在gopro数据集上进行去模糊的实验结果
[0088] ledviesl-netcsdstfanred-netstrapsnr22.8622.5927.5428.0728.9829.73ssim0.7330.7500.8340.8360.8490.927
[0089]
实验结果显示在两种不同的数据集上,本发明方法与其它五种方法相比效果都要更好,从而证明了本发明提出方法的可行性。实验表明本发明提出方法能有效利用单帧图像的空间特性及帧之事件序列间的时间连续特性,完成模糊视频的去模糊任务。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1