一种数据收集方法及装置与流程
1.本发明涉及数据采集领域,尤其是涉及一种用于人机交互类ai模型训练的数据收集方法及装置。
背景技术:
2.现在学术界和业界已经推出了许多公开可用的问答数据集。但是这些数据都针对单轮的问答体验,在实际使用中,多轮检索可以提供更精确的答案和更加友好的用户体验。人机交互允许用户通过输入自然语言(例如通过打字,说话,手势或执行其他类型的表达)与机器进行通信。为了达到这个目的,多轮检索系统需要对于问答搜索的上下文进行理解,从而可以更加精确的推理出用户的意图并且给出更加相关的检索答案。多轮检索系统本质上也可以被理解为多轮对话机器人,这里的对话是一种广泛意义上的人机交互。
3.然而,由于数据收集的高昂成本,市面上还没有任何基于多轮的会话搜索数据集,因此关于多轮检索的成熟系统非常稀少。通常,许多企业系统在构建多轮检索系统时遇到的一些困难可能包括以下方面。例如,可用于训练的对话数据可能太稀疏。构建人机交互系统的挑战之一是在特定域中收集足够的对话数据。有些领域域,包括天气,股票,体育,餐馆等可能存在存留数据,但是企业可能从事特定行业,因此可能有兴趣采用针对一个或多个特定域的人机交互系统。但是,可能很难为特定企业的目标操作收集高质量的对话数据,这可能需要针对一个或多个特定域中的每个域唯一的大量数据。必须提供足够大量的数据来训练对话机器人。
4.此外,企业可能要求高精度。人机交互系统可能需要在特定业务中以高精度响应客户。如果人机交互系统提供了错误的信息,则可能会带来严重的影响。因此,许多将由企业使用的人机交互系统都是通过基于规则或基于对话流的方法构建的,其中仅允许用户遵循预定义的方案。否则,人机交互系统可能无法生成正确的响应。在需要复杂对话或专业领域知识(例如法律,医学或销售)的业务中应用人机交互系统也非常困难。
技术实现要素:
5.本发明主要是解决现有技术所存在的缺乏基于多轮对话的数据集的技术问题,提供一种高效、高精度的人机交互类数据收集方法及装置。
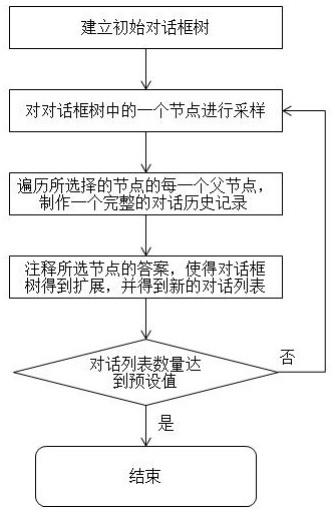
6.本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种数据收集方法,包括以下步骤:s01、建立初始对话框树;s02、对对话框树中的一个节点进行采样,并使采样获得的数据样本内容多样化;s03、遍历步骤s02中所选择的节点的每一个父节点,制作一个完整的对话历史记录;s04、注释步骤s02所选节点的答案,使得对话框树得到扩展,并得到新的对话列表,对话列表包括步骤s03中制作的对话历史记录以及本步骤中注释的答案;
s05、重复步骤s02-s04,直至对话列表的数量达到预设值;所述步骤s02具体为:s201、对用户配置文件进行采样:根据现有对话数据,计算当前用户的概率分布p(ui|di),ui是当前轮次用户档案的分布,di是当前轮次对话数据,i是当前轮的轮次,i》1,计算公式如下:p(ui|di)=p(u
i-1
|d
i-1
)p(u
i-1
|α0)α0是超参数;采用贝叶斯推理的方法从后验分布中以一系列事件的形式进行采样,参与变量包括上一次采样的对话数据d
i-1
和用户档案分布u
i-1
以及上一轮的用户分布概率p(u
i-1
|d
i-1
);由此得到本轮的用户档案分布ui和本轮的对话数据di;基于当前用户的概率分布确定本轮对话的内容分布:式中,u指ui中具体一个用户的属性,是本轮对话的内容;s202、重复步骤s201直至对话的总轮次超过聚类阈值(收集的对话记录数量超过聚类阈值)之后,运行对话内容聚类,公式如下:式中,α和β为超参数,在聚类之前,先利用gibbs采样算法对真实的概率分布进行近似,获得w、z、π和θ,公式如下:π~dir(β)θ~dir(α)w~mulit(π)z~mulit(θ)式中,dir为狄利克雷分布采样,mulit为多重正态分布采样;聚类结束后判断对话的总轮次是否达到目标阈值,如果达到目标阈值则进入步骤s203,否则跳转到步骤s201继续采样;s203、计算所采集的数据的系统困惑度,如果系统困惑度小于困惑度阈值,则进入步骤s204,否则本次采样结束;s204、基于测试人员的结果和每组数据的困惑度采样,公式如下:h是熵,x是当轮对话内容,z是下一轮对话内容;~ppl(x)为针对x的困惑度采样结果;然后跳转到步骤s203。
7.首先,本方案尽可能地手动使对话框流动,或者可以使用所有现有工具,例如dialogflow(google)。本技术使用基于流的方法的原因是为了解决冷启动问题。如果数据
收集是从一开始就没有任何骨干对话框,则将存在数据偏差问题。根据收集的数据数,每个步骤将有不同的采样方法。其次,本技术对树中的一个节点进行采样,以使其多样化并解决对话框偏差问题。第三,本技术通过遍历每个父节点来制作一个基于所选节点的完整对话历史记录。第四,本技术给注释者标注答案以扩展树。本技术重复此过程,直到有足够的数据点并将这些数据用于最终训练。对每个步骤采样的数据点都略有不同,每个步骤将基于收集的数据点的数量。
8.作为优选,所述步骤s203中,计算所采集的数据的系统困惑度具体为:通过ai模型对于所采集的数据进行预测,并将预测的概率分布和正确答案进行对比,从而得到困惑度。
9.高困惑度的数据将有更大的概率被选择出来。
10.作为优选,首轮用户档案的分布u1、首轮对话数据d1和首轮的用户分布概率p(u1|d1)从初始对话框树中直接得到。
11.作为优选,当会话被标上重复标记后,采样引擎减少该会话后期被采样的概率;当会话被标记为特别对话后,采样引擎提高此会话采样的优先级。
12.作为优选,所述聚类阈值为10000-20000。
13.作为优选,所述目标阈值为100000-200000。
14.聚类阈值和目标阈值可以根据需要进行设定,从而使得整个流程在效率和精度上获得均衡。
15.一种数据收集装置,运行有如上所述的数据收集方法,包括:用户页面:包含用户个人资料和对话历史记录的会话分配给用户页面;用户角色注释者读取用户个人资料、说明以及给定的对话历史记录;用户角色注释者在个人资料中假装一个人,并通过打字或讲话进行响应;用户角色注释者提交语音后,用户页面上展示新的会话;提交的对话将保存到会话数据库中,并且已保存的会话将在专家页面上采样;新会话将提供给用户角色注释者;此新会话包含完全不同的对话历史记录和用户配置文件,用户角色注释者会再次读取指令,用户配置文件和对话历史记录;专家页面:包含对话历史记录的会话分配给专家页面;专家角色注释者在专家页面上响应;专家页面包括快捷按钮、以前的系统操作以及元数据库中的产品列表;阅读对话历史记录后,专家角色注释者做出响应;专家页面向专家角色注释者提供建议;如果正确的答案在建议中,专家角色注释者将选择其中之一;否则,专家角色注释者在控制面板中找到或在文本框中键入;基于此选择,装置估算当前性能,并根据当前性能选择不同的采样策略;提交后,将显示新的对话框历史记录;测试页面:测试页面提供了一个简单的用户界面,带有用于测试器的文本输入框;当对话数据的数量足以训练模型并且性能超过特定数量时,将开始测试器模式;通过专家从模型建议中选择建议的比率来获得性能;测试人员提供两种反馈:话语水平反馈和对话水平反馈;“点赞”为正向提供话语水平反馈,反之亦然;对话水平反馈是通过李克特量表评估人机交互系统的总体性能:自然性,智能性和总体得分。
16.评估页面:评估者页面提供了来自真实用户的对话日志;评估者查看对话框的每一轮之后,他们单击“点赞”以记录特别好的响应,并单击“差评”来记录错误的答复;这些反
馈将保存在反馈数据库中,以通过应用强化学习训练来改进模型。
17.本发明带来的实质性效果是,实现了最大程度地提高探索未知搜索流分布的效率,并积极推荐下一批数据供人工注释者进行标记,最大程度地减少人类注释中的冗余。
附图说明
18.图1是本发明的一种数据收集方法流程图;图2是本发明的一种采样过程流程图。
具体实施方式
19.下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
20.实施例:建立人机交互系统的主流方法是使用wizard-of-oz(woz)。在woz方法论中,通过两位人类用户角色扮演的方式来收集潜在的对话数据。其中一个人扮演机器,另一个扮演人类用户,通过woz软件界面进行数据收集。虽然woz仍然是目前主流的对话数据收集方法,woz方法也有很多缺点,例如,在使用语音识别系统讲话时,用户经常会感到需要修改其自然的讲话方式,以便让机器可以理解用户的意图。因此,当用户认为沟通伙伴是机器时,他们的使用的话语会和当是和人交流时的语言存在差异。另外,woz数据速度非常缓慢,因为必须要将两人进行配对才能开始数据收集,并且很多收集的许多对话都是重复的,不添加任何新信息。
21.此外,众包平台也和数据收集紧密相关。对于大多数开发人员而言,建立众包采购流程并获得可用的结果并非易事。研究人员(请求者)必须克服以下难题才能完成数据收集:学习如何使用众包界面,学习如何创建易于理解且有吸引力的任务,确定任务应采取的正确形式(模板),将要评估的对话系统连接到众包平台,向工人付款,评估工人的生产质量,获得可靠的最终结果。为了解决连接问题,研究人员使用网页链接他们的对话系统,依靠众包web 界面来呈现任务,然后将工作人员发送到对话系统,最后将他们带回该界面以进行收集他们的生产和时间表付款。此处连接问题就是这些障碍的一个例子。研究人员还面临评估形式的选择。测试的类型可能会有所不同。
22.现有众包方法可以通过招募大量的数据标注人员从而实现短期内收集到一个大型数据集。但是,这种方法的效率其实非常低下。一个标注人员一次只能选择扮演一个角色,例如扮演机器或者扮演用户,并且可能因为重复回答类似的问题,产生的数据缺乏多样性,更多是机械重复有限的模式。针对这些问题,本技术发明了一种新型的异步数据收集方法,让多个标注人员可以同时进行多对多的协作,快速创建大型数据集。通过这种机制,工人无需实时配对,并且可以在可用时间内独自工作,因此,该框架使工作人员摆脱了时间限制,并提高了工作效率。为了进一步优化数据收集效率,本技术提出了一种智能采样方法,该智能采样选择一个数据点以使对话数据更加多样化,并避免重复和不必要的数据点。本方案的原理主要基于2大原则。
23.1.通过人工构建对话流程来描绘对话的主干道。
24.2.通过智能的数据采样,对于对话流中的薄弱点进行集中学习。
25.交互流程的初始化:传统的多圈对话是基于手工对话流程图的构造。但是,此设计范例意味着开发人员需要为每个可能的用户输入及其前面的对话上下文指定响应。但是,
域越复杂,存在的场景就越多。实际上,导致对话成功完成的路径数量随着应用程序域的复杂性呈指数增长。这使得设计现实应用程序变得很困难(如果不是不可能的话)。但是,基于流的方法已成功应用于有限领域的商业应用中,因为当在现实世界中应用时,准确性非常重要。然而,数据驱动的方法是有前途的,并且具有很高的回想率,但是它也限制了某些人群收集的数据偏差问题。因此,本技术将基于流的方法与基于数据驱动的方法相结合。本技术使用基于流的方法来制作对话框的骨干,并应用了智能采样框架来处理长尾或意外对话框模式,这些模式很难手动绘制图形。
26.智能采样算法:对话框数据收集的目的是获取不同的数据点,因此可以防止模型遭受数据稀疏的困扰。多样的数据点意味着话语多样性(不同的对话流)和句子多样性(不同的表达方式但含义相同,例如,“hello”与“hi”)。因此,智能采样是通过对稀疏区域进行采样来为专家和用户提供会话,以通过收集各种数据点来改进模型。智能采样基本上是建立对话流程图以覆盖整个样本空间,从而给系统训练提供足够的场景和数据。
27.例如,对于s1(您的皮肤类型是什么),后面用户的回复会集中在几种回答上,例如我的皮肤类型是xx。而对于对话流的另一个点u2(您好),将会收集很多不同的响应。因此,智能采样算法应该把大量的精力预留给u2,以保证系统在u2这个节点收集到尽量可能多的样本。具体来说,本技术利用如下方法来进行判断:专家对于自动提示的接受程度:来自后台模型的建议多次被专家接受,那意味着这个数据点已经被掌握,当某个数据点,专家很少接受模型的自动提示时,需要对此进行更多的数据采样。
28.基于测试中对于回复的点赞反馈:当某一个对话数据获得很多点赞时,表明数据已足够。如果大部分测试人员对于数据进行差评回复这意味着需要对该数据点进行更多采样。
29.对于专家角色页面,智能采样控制器从所有用户轮数据中进行选择,并且把整个对话记录展现给专家。
30.现在将详细说明整个采样过程以及实施细节。如图1所示,数据收集方法包括以下流程:s01、建立初始对话框树;s02、对对话框树中的一个节点进行采样,并使采样获得的数据样本内容多样化;s03、遍历步骤s02中所选择的节点的每一个父节点,制作一个完整的对话历史记录;s04、注释步骤s02所选节点的答案,使得对话框树得到扩展,并得到新的对话列表,对话列表包括步骤s03中制作的对话历史记录以及本步骤中注释的答案;s05、重复步骤s02-s04,直至对话列表的数量达到预设值。
31.首先,本技术尽可能地手动使对话框流动,或者可以使用所有现有工具,例如dialogflow(google)。本技术使用基于流的方法的原因是为了解决冷启动问题。如果数据收集是从一开始就没有任何骨干对话框,则将存在数据偏差问题。在初始图中,根据收集的数据数,每个步骤将有不同的采样方法。其次,本技术对树中的一个节点进行采样,以使其多样化并解决对话框偏差问题。第三,本技术通过遍历每个父节点来制作一个基于所选节点的完整对话历史记录。第四,本技术给注释者标注答案以扩展树。本技术重复此过程,直
到有足够的数据点并将这些数据用于最终训练。本技术对每个步骤采样的数据点都略有不同。每个步骤将基于收集的数据点的数量。
32.如图2所示,采样过程具体为:第一步:为了获得对话框数据的各种用户配置文件类型,将对用户配置文件进行采样:例如,客户端需要将用户配置文件(键,值)对放入(例如,“痘痘类型”:[白头,黑头,脓疱,丘疹,囊肿,结节]),“年龄”:[《10,10-20,20-30,30-40,》40])。希望根据现有对话数据,获得当前用户的概率分布p(ui|di),ui是当前轮次用户档案的分布,di是当前轮次对话数据,i是当前轮的轮次,i》1,假设有n个数据点d1,
…
,dn。这里每一个d 都是一个向量特征,比如对话轮数,用户配置值等。获得如上概率分布后,就可以对下一个用户配置进行采样。
[0033]
p(ui|di)=p(u
i-1
|d
i-1
)p(u
i-1
|α0)其中α0是一个超参数。为了从这个分布中进行采样,本技术采用贝叶斯推理的方法从后验分布中以一系列事件的形式进行采样。上一次采样的对话数据di-1和用户档案分布ui-1以及上一轮的用户分布概率p(ui-1|di-1);由此得到本轮的用户档案分布ui和本轮的对话数据di;这里的先验分布是通过历史数据,或者行业专家的专业知识进行设定的。通过这个方法,可以确定本轮对话使用什么样的用户配置,以此推进一个对话的发展。
[0034]
第二步:在此步骤中,数据的分布将是非常的长尾,因此采样策略将基于对话框的长度和对话框的簇id。在收集了n个以上的对话框(设置为n=10000)会话之后,本技术将运行对话内容聚类。其中k 是话题的数量,n 是一个对话中的词数量,是对话的数量。
[0035]
为了通过上述公式实现聚类,本技术利用gibbs采样算法对真实的概率分布进行近似:π~dir(β)θ~dir(α)w~mulit(π)z~mulit(θ)在使用gibbs采样后,聚类结果将符合θ分布。因此smart woz也将一个基于θ分布的算法。聚类结束后判断对话的总轮次是否达到目标阈值,如果达到目标阈值则进入下一步,否则跳转回上一步骤继续采样。
[0036]
第三步,计算所采集的数据的系统困惑度,如果系统困惑度小于困惑度阈值,则进入下一步骤,否则本次采样结束。
[0037]
第四步:采样将基于测试人员的结果以及每组数据的困惑度,ppl(x) 的计算公式如下:
h是熵,x是当轮对话内容,z是下一轮对话内容;~ppl(x)为针对x的困惑度采样结果;然后跳转到第三步。
[0038]
也就是说,利用上述公司,高困惑度的数据将有更大的概率被选择出来,因此第四步的方法是一种主动学习的方式,最快的收集足够的训练数据。
[0039]
专家可以控制特定会话的采样频率。例如,如果专家认为他们已经收到太多相同的会话,则可以单击此会话上的“重复标记”按钮。智能采样引擎会减少在会话后期被采样的概率。另一方面,如果专家认为本次会议非常重要。他们可以将其记录为特别对话,以加快此会话的速度。
[0040]
提议的数据收集过程包括几个用户界面:用户角色页面,专家角色页面测试者页面,评估者页面。它需要数据收集团队来划分用户角色和专家角色。在数据收集过程中,该模型会自动在用户角色和专家角色之间进行训练。在数据收集过程中,经过训练的模型为专家角色注释者建议响应候选者。
[0041]
用户页面(user-role page):包含用户个人资料和对话历史记录的会话将分配给“用户角色页面”。用户角色注释者读取用户个人资料和说明。用户角色注释者读取给定的对话历史记录。用户角色注释者在个人资料中假装一个人,并通过打字或讲话进行响应。
[0042]
用户角色人员提交语音后,智能采样器将进行新的会话。提交的对话将保存到会话数据库中,并且已保存的会话将在专家角色页面上采样。新会话将提供给用户角色。此新会话包含完全不同的对话历史记录和用户配置文件,因此用户角色注释者会再次读取指令,用户配置文件和对话历史记录。
[0043]
专家页面(expert-role page):智能采样器会将包含对话历史记录的会话分配给用户角色页面。专家角色页面具有几个控制面板,专家角色注释者可以快速响应以加快数据收集速度:例如快捷按钮,以前的系统操作以及元数据库中的产品列表。专家角色人的整个过程类似于用户角色人。阅读对话历史记录后,专家角色人必须做出响应。由于智能采样器是在收集的对话框中自动进行训练的,因此向专家角色注释器提供了一些建议。如果正确的答案在建议中,专家角色将选择其中之一。否则,他可以在控制面板中找到或在文本框中键入。基于此选择,智能采样器将估算当前性能,并根据当前性能选择不同的采样策略。提交后,将显示新的对话框历史记录。
[0044]
测试页面(tester page):测试页面提供了一个简单的用户界面,带有用于测试器的文本输入框。测试人员的目标是评估当前模型,并尝试分解当前的漫游器,以使模型能够处理并很好地应对数据库中看不见且未包含的域外语音。因此,当对话数据的数量足以训练模型并且性能超过特定数量(例如50%)时,将开始测试器模式。可以通过专家从模型建议中选择建议的比率来获得性能。测试人员提供两种反馈:话语水平反馈和对话水平反馈。
[0045]“点赞”为正向提供话语水平反馈,反之亦然。通过添加这些数据,可以将使用“点赞”的数据更自信地用于操作选择。经验不足的数据可用于为专家提供解决方案。这些负面样本在训练时被用作负面奖励。对话级别的反馈是通过李克特量表评估人机交互系统的总体性能:自然性,智能性和总体得分。
[0046]
评估页面(evaluator page):评估者页面提供了来自真实用户的对话日志。评估
者查看对话框的每一轮之后,他们单击“点赞”以记录特别好的响应,并单击“差评”来记录错误的答复。这些反馈将保存在反馈数据库中,以通过应用强化学习训练来改进模型。
[0047]
效果说明:首先,实施例比较了常规对话集合和本方案纸件的数据集合数量和速度。给出了如何使用本技术的数据收集框架的说明,并要求4个注释者使用每种方法:异步方法(本方案)和同步方法(常规的方法),每天使用1周,每天最多5个小时,然后对数字进行计数每个方法的数据点数。结果表明,使用本方法,标注员完成了更多的数据点。原因是注释者需要等待另一伙伴一起使用常规方法进行一个对话,并且他们必须等待另一方加入。
[0048]
实施例还比较了数据收集的平均速度。本方法比传统方法(每个数据点101秒)快246%(每数据点41秒),因为各方无需等待另一方的响应。41秒的原因是注释者有时不知道如何回答,他们在数据收集过程中互相询问。此外,他们在回答和搜索数据库中要回答的内容时必须了解以前的历史记录,因此响应时间可能会延迟,并且比预期的要长,但是使用本方法时,数据收集的速度明显更快。实验证明,本方案可以大幅度提高数据的多样性,减少重复数据的比率。
[0049]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
[0050]
尽管本文较多地使用了采样、聚类、页面等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1