一种基于可信执行保护的先重删除后加密的安全重删除存储系统的制作方法
1.本发明属于大规模数据管理技术改进领域,尤其涉及一种基于可信执行保护的先重删除后加密的安全重删除存储系统。
背景技术:
2.在面对数据量快速增长时,将数据存储在公有云服务上提供了一种可行的低开销的,大规模的数据管理解决方案
1.。为了防止数据隐私泄露,客户往往要求端到端的加密保护,这样他们的数据将在存储到不可信的公有云之前被加密
2.。但是,由于传统的对称加密算法会导致每一个用户使用一个不同的密钥去加密他们自己的数据,从而导致来自不同用户的数据会产生不同的加密数据,因此不支持跨用户的数据重删除。
3.文献中有许多关于如何在安全的数据重删除存储系统中无缝结合加密算法和数据重删除
[3]-[7]
,我们将它们统称为“先加密后重删除”(dae)。dae先在客户端对数据进行加密以确保数据的机密性,然后再云端应用跨用户的数据重删除,从而去除重复的加密数据以节省存储开销。为了在加密后仍然保留相同的内容,dae使用每个数据块内容派生的对称密钥对数据进行加密,这样重复的原数据块(称为明文数据块)总是用相同的密钥加密成相同的数据块(称为密文数据块),之后通过数据重删除去除相同的密文数据块。
[0004]
尽管dae很受欢迎,我们认为dae在密钥管理开销、与压缩不兼容以及安全性方面存在一些根本性的缺陷(见2.1)。由于dae总在重删除之前对每一个数据块生成一个密钥以进行加密,因此它不仅会不必要地为重复数据生成大量密钥,但是这些数据块会在之后重删除时被去除
[8]
。除此之外,这样还会导致额外的密钥存储开销来管理所有数据块的密钥。针对dae存储的不重复的密文数据块,由于其内容看起来是完全随机的,这样很难通过压缩进一步减少存储空间。此外,dae需要确定性的加密来保留对密文数据块进行重删除的能力。这种确定性加密的性质容易受到频率分析引起信息泄露
[9]-[10]
。
[0005]
dae的局限性促使我们探索一个简单但是未被探索的设计范式,称为“先重删除后加密”(dbe)。它首先对明文数据块进行重删除,然后使用与数据块内容无关的密钥加密剩余的不重复明文数据块。dbe与dae的主要区别在于它不需要对每一个数据块管理用于加密或者解密的密钥,从而解决了dae的局限性。但是,dbe在安全的数据重删除存储系统中仍未被探索的一个主要原因是明文数据块在重删除的时候不再受加密的保护。
[0006]
我们的主要的见解是dbe中重删除的过程可以受到可信执行技术的保护
[11]-[12]
。因此,我们提出了debe,它是一种基于dbe的可信执行保护的数据重删除系统。debe建立再intel sgx
[13]
上,它提供了一个称之为“飞地”的可信执行环境,用于实现安全的数据重删除。在sgx中实现debe的一个关键挑战是受限的飞地空间(例如,128mib[14])。因此,我们提出了基于频率的重删除,这是一种两阶段数据重删除解决方案,它可以在空间受限的飞地里面实现安全、轻量级的数据重删除。具体来说,debe首先在飞地内对高频出现的数据块执行重删除,这是基于我们观察到高频出现的数据块通常构成了很大一部分的重复数据块
(见4.1)。然后,它在飞地外对剩余的非频繁出现的数据块进行重删除。基于频率地重删除设计具有以下的关键优势:(1)高性能,因为它在第一阶段重删除时删除了大部分重复数据,从而减少了在飞地外对数据进行重删除时所引发的上下文切换开销
[14]
;(2)通过重删除和压缩实现较高的存储效率;(3)高安全性,由于它在飞地内对高频数据块进行重删除,从而保护了这些易受到频率分析攻击的数据块频率
[10]
。
[0007]
我们实现了debe原型并在局域网的环境下对其进行了评估。与当前主流的dae方法相比,debe实现了显著的性能提升(例如,在上传非重复和重复数据时,比dupless
[15]
的性能分别提高了9.83倍和13.44倍),并且还减少了信息泄露同时没有降低存储效率(例如,比ted
[10]
的相对熵减少了86.8%,但ted需要额外的存储开销)。
[0008]
重删除是现代存储系统中被广泛部署的数据减缩技术
[16]-[18]
。我们主要关注基于数据块的重删除技术,它以数据块为最小粒度进行重删除。具体而言,重删除存储系统首先将输入文件分割成大小不同的数据块。对于每个数据块,它通过计算其内容的加密哈希(例如,sha-256)作为该数据块的指纹,进而通过指纹来识别每个数据块。它维护了一个键值存储索引,称为指纹索引,用于跟踪所有现有已经存储的数据块的指纹,并且只存储不重复的数据块。同时,它还为每个文件存储一个清单文件,称为文件配表,用于追踪该文件中所有的数据块的信息,以便在将来对进行文件的重建。此外,重删除系统还会对非重复的数据块进行压缩来消除字节级的重复数据,进而节省更多的存储空间
[19]
。
[0009]
先加密后重删除(dae)无缝衔接了重删除和加密,以同时实现数据的机密性和存储空间的节省。在dae中,客户端首先对明文数据块进行加密并将密文数据块上传到云端,然后在云端对密文数据块进行重删除。dae中一种流行的加密算法是消息锁定加密(mle)
[4]
,它规定了数据块加密和解密的密钥是从每个数据块的内容产生的,因此相同的明文数据块总是被加密为相同的密文数据块,以进行密文数据块的重删除。mle的一个实例是收敛加密(ce)
[6]
,它根据每个数据块的指纹而生成相应的密钥。
[0010]
ce容易受到离线暴力攻击
[15]
,其中攻击者可以枚举所有明文数据块来产生相应的密钥,进而尝试解密密文数据块。如果解密成功,则可以推断出原始的明文数据块。dupless通过额外的服务器来辅助密钥的管理,其通过部署一个密钥服务器来防御ce中的离线暴力攻击,该服务器根据一个全局的机密(只能被该密钥服务器所拥有)和数据块的指纹来生成每个数据块的密钥。此外,dupless还利用遗忘式的伪随机函数(oprf)
[20]
实现密钥生成,以防止密钥服务器在密钥生成的过程中获取数据块的信息和其密钥。同时,dupless还会对客户端的密钥生成请求进行速度限制以防御恶意的客户端暴力地向密钥服务器发送针对不同明文数据块的密钥生成请求。
[0011]
局限性: dae是当前主流的构建安全的重删除存储系统的设计模式。然后,我们认为dae本身在三个方面有一定的局限性。
[0012]
局限性-1:较高的密钥管理开销。dae针对每个数据块生成一个密钥,导致其需要维护所有数据块的密钥而产生较大的密钥存储开销。此外,每个客户端都需要通过自己的主密钥对其所拥有的数据块的密钥进行加密。因此,密钥存储开销与数据块和客户端的数量成比例的增加,并且对于具有较高冗余的工作负载影响较大
[21]
,因为它们在重删除之后仅需要存储少量的非重复数据。此外,dupless在将数据块上传到云端之前对每个数据块生成了密钥,即使其中的重复数据块会在之后云端进行重删除时会被去除掉。由于dupless在
密钥生成的过程中使用oprf和速度限制,因此其密钥生成过程会有较大的性能开销。简而言之,dae在密钥存储和密钥生成方面都会产生较高的密钥管理开销。
[0013]
局限性-2:与压缩不兼容。在dae中,由于加密后的非重复数据块内容几乎是随机的,云端无法对非重复的加密数据块进一步压缩节省额外的存储空间。虽然客户端可以对明文数据块在加密前先进行压缩再上传加密后的压缩数据块,但是这样会泄露压缩数据块的长度并引入额外的安全风险
[22]
。
[0014]
局限性-3:安全风险。dupless中的服务器辅助密钥管理设计会导致密钥服务器称为单一的攻击点。如果对手破坏了密钥服务器并可以访问全局机密,其可以像ce一样通过离线暴力攻击推断出数据块的密钥。此外,dae本质上是确定性的,实现了明文数据块和密文数据块之间的一对一映射。攻击者可以发动频率分析,根据重删除存储系统中密文数据块的频率分布推断出原始的明文数据块
[9]
。
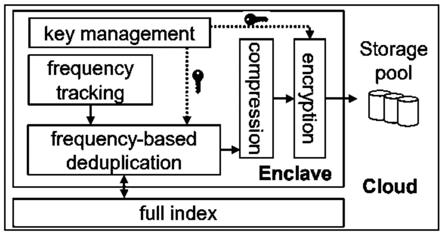
技术实现要素:
[0015]
本发明的目的在于提供一种基于可信执行保护的先重删除后加密的安全重删除存储系统,旨在解决上述的技术问题。
[0016]
本发明是这样实现的,一种基于可信执行保护的先重删除后加密的安全重删除存储系统,所述基于可信执行保护的先重删除后加密的安全重删除存储系统包括客户端、数据信道、控制信道及云端服务器,所述客户端通过数据通道及控制通道连接所述云端服务器,所述客户端,用于用户将自己的明文数据块通过数据信道上传至云端的飞地;所述云端服务器,用于维护全局的指纹索引来追踪所有客户端存储的数据块,并在飞地内去除重复的数据块,加密非重复的明文数据块,最终将密文数据块存储于存储池中;所述数据信道,用于传输由客户端发起的明文数据块,所述控制信道,用于传输存储的相关操作命令。
[0017]
本发明的进一步技术方案是:所述云端服务器中部署飞地、存储池及完整索引模块,所述飞地通讯连接所述飞地模块,所述飞地的输出端连接所述存储池的输入端,所述飞地,用于进行数据的重删除,在重删除的过程中保证明文数据块的保密性,会对非重复的明文数据块进行压缩,并对压缩的明文数据块进行加密;所述存储池,用于飞地将密文数据块存储在存储池中,所述完整索引模块,用于完整追踪所有非重复的数据块指纹。
[0018]
本发明的进一步技术方案是:所述飞地内部署包括基于频率的数据重删除单元、频率跟踪单元、密钥管理单元、压缩单元及加密单元,所述频率跟踪单元输出端连接所述基于频率的数据重删除单元的输入端,所述密钥管理单元的输出端分别连接所述基于频率的数据重删除单元的输入端及加密单元的输入端,所述基于频率的数据重删除单元的输出端连接所述压缩单元的输入端,所述压缩单元的输出端连接所述加密单元的输入端。
[0019]
本发明的进一步技术方案是:所述密钥管理单元包括数据密钥、查询密钥及会话密钥,所述数据密钥,用于加密和解密安全存储中压缩的非重复明文数据块;所述查询密钥,用于在查询飞地外的完整索引时保护明文数据块信息;所述会话密钥,用于每个客户端都维护一个与飞地的数据信道以进行安全数据通信,每个数据信道使用一个短期的会话密钥保护其数据信道,该密钥对单个通信会话保持有效。
[0020]
本发明的进一步技术方案是:所述频率跟踪单元,用于飞地追踪明文数据块的频率,以识别高频率出现和非高频率出现的数据块,进而实现基于频率的数据重删除。
[0021]
本发明的进一步技术方案是:所述基于频率的数据重删除单元根据数据块的频率将重删除分为两个阶段,并去除所有重复的明文数据块;所述基于频率的数据重删除单元包括第一阶段重删除及第二阶段重删除,所述第一阶段重删除,用于飞地维护一个较小的指纹索引,对最频繁出现的k个数据块进行重删除;所述第二阶段重删除,用于对第一阶段未被去除的重复数据块进行第二阶段重删除,包括非频繁出现的数据块和新出现的频繁数据块。
[0022]
本发明的进一步技术方案是:所述第一阶段重删除将明文数据块的指纹作为输入,从cm-sketch中获得明文数据块当前的估计频率;检查小顶堆的根结点,若当前的估计频率小于根结点的频率,则飞地跳过进一步查询哈希表的过程,并直接进行第二阶段重删除;若当前的估计频率打于根结点的频率,则飞地则使用它的指纹进一步查询哈希表。
[0023]
本发明的进一步技术方案是:所述第二阶段重删除中飞地使用查询密钥加密明文数据块的指纹,根据加密后的明文数据块指纹通过ocall查询飞地外的完整索引;如在完整索引中找到了加密指纹,则ocall返回加密后的数据块信息,该信息将在飞地内使用查询密钥进行解密,飞地将该数据块的地址和压缩后的大小更新到文件配表中;如加密指纹是完整索引的新指纹,则飞地将该数据块视为非重复的数据块,并为该数据块分配地址,压缩该数据块并记录其压缩后的大小。
[0024]
本发明的进一步技术方案是:所述密钥管理单元中飞地对重删除后的非重复明文数据块进行压缩,并将压缩后的非重复明文数据块加密为密文数据块将密文数据块写入到飞地内的容器缓冲区内,当缓冲区已满时,飞地将该缓冲区内容设置为不可变的并将其释放给云服务器进行持久化存储。
[0025]
本发明的进一步技术方案是:飞地为每个新上传的文件创建文件配表,文件配表中的每个条目都记录了数据块的地址以及该数据块压缩后的大小。当飞地更新文件配表时,不需要对重复的数据块再一次执行压缩以获得其压缩后的大小,因为压缩后的数据块大小以存储在top-k索引和完整索引中。
[0026]
本发明的有益效果是:该系统有效提高了存储效率,优化了性能。该系统结构简单,大大的节省了系统开销。与当前主流的方法相比,debe实现了显著的性能提升,在上传非重复和重复数据时,比dupless的性能分别提高了9.83倍和13.44倍,并且还减少了信息泄露同时没有降低存储效率,比ted的相对熵减少了86.8%,但ted需要额外的存储开销。
附图说明
[0027]
图1是本发明实施例提供的debe架构示意图。
[0028]
图2是本发明实施例提供的数据重复率与数据块频率的关系的示意图。
[0029]
图3是本发明实施例提供的飞地的架构的示意图。
[0030]
图4是本发明实施例提供的飞地内的频率追踪模块的示意图。
[0031]
图5是本发明实施例提供的top-k索引的设计的示意图。
[0032]
图6是本发明实施例提供的(实验一)整体性能示意图。
[0033]
图7是本发明实施例提供的(实验三)多客户端性能示意图。
[0034]
图8是本发明实施例提供的(实验四)数据块频率分布对性能的影响示意图。
[0035]
图9是本发明实施例提供的(实验五)不同数据重删除方法的对比示意图。
[0036]
图10是本发明实施例提供的(实验六)真实数据集上的上传和下载性能示意图。
[0037]
图11是本发明实施例提供的(实验七)不同重删除方法存储效率的比较示意图。
[0038]
图12是本发明实施例提供的(实验八)不同方法针对频率分析的安全性示意图。
具体实施方式
[0039]
如图1-12所示,本发明提供的基于可信执行保护的先重删除后加密的安全重删除存储系统,其详述如下:转向到“先重删除后加密”鉴于dae的局限性,我们研究了一种未被探索的设计范式,即在“先重删除后加密”(dbe)实现安全的数据重删除存储系统。它的主要思想是先对明文数据块进行重删除,删除掉重复的数据块,然后对非重复的明文数据块加密成密文数据块进行存储。
[0040]
与dae相比,dbe有许多天然的优势。首先,由于dbe先对明文数据块进行重删除,因此dbe可以像传统对称加密中那样使用与内容无关的密钥进行加密每个非重复的明文数据块(见1),从而不会影响对数据进行重删除。这避免了生成和存储由每个数据块内容派生出来的密钥,进而减少了密钥管理开销(即dae中的局限性-1得到了解决)。其次,dbe可以在对明文数据进行重删除之后对不重复的数据应用压缩,进一步节省存储开销,之后加密压缩之后的非重复数据块(即dae中的局限性-2得到了解决)。最后由于dbe可以使用与数据块内容无关的密钥进行加密,因为它不需要再像dupless那样为每个数据块生成密钥并使用密钥服务器,这避免了密钥服务器成为单一的攻击点(即dae中的局限性-3得到了解决)。
[0041]
然而,实现dbe的主要挑战是决定是否在客户端或者云端执行不再受加密保护的数据重删除。这里我们主要考虑三种情况:1)每个客户端为其自己的明文数据块维护一个本地的指纹索引。然后它加密非重复的明文数据块,并将产生的密文数据块上传到云端。但是,这种方法无法实现跨用户的数据重删除。
[0042]
2)在云端维护一个全局指纹索引来追踪所有客户端存储的数据块。每个客户端首先将自己的明文数据块的指纹提交到云端上,以查询它们是否可以进行重删除,之后客户端对非重复的数据块进行加密并将密文数据块上传到云端。这种方法也称为基于源的重删除
[23]
,但是它容易受到旁道攻击
[23]-[24]
,因为任何恶意的客户端都可以通过查询目标数据块是否可以进行重删除来推断其他客户端是否已经存储了某个目标数据块。
[0043]
3)每个客户端将所有的数据块上传到云端,然后云端根据所维护的所有客户端存储的数据块的全局指纹索引来进行数据重删除。这种方法也称为基于目标的数据重删除
[23]
,它对客户端隐藏了数据重删除的模式,并且可以安全抵御旁道攻击。但是,每个客户端不可避免地将其明文数据块暴露给了云端。
[0044]
因此,dbe在现有的文献中仍然没有被广泛探索,而现有的研究主要是集中在基于dae来实现安全的数据重删除存储系统。
[0045]
intel sgx在这项工作中,我们主要通过基于目标的数据重删除来实现dbe,并且展示了我们如何通过可信执行硬件来保护dbe。我们使用intel sgx
[13]
来实现可信执行,同时我们的设计也可以与其他支持可信执行的硬件(例如,arm trustzone
[25]
和amd sev
[26]
)一起使用。
[0046]
sgx基础:sgx是一组用于intel cpu的扩展指令集,用于在称为飞地页缓存(epc)的加密且受完整性保护的内存区域内实现可信执行环境。它通过硬件保护确保飞地内数据的机密性和完整性。它提供了两个接口来与飞地外不受信任的应用程序进行交互:1)飞地调用(ecalls),它允许应用程序安全地访问飞地内的内容,以及2)外部调用(ocalls),它允许在飞地内的代码调用外部的应用程序函数。
[0047]
挑战:由于飞地的资源限制,在sgx中实现dbe并非一件容易的事情。首先,epc大小是有限的(例如,最多128mib
[14]
)。当飞地的内存使用量超过epc的大小时,它会将未使用的内存页面加密并存放在未受保护的主内存中,并在将它们加载回epc时解密并验证被驱逐页面的完整性。这会导致昂贵的epc换页开销
[27]
。尽管最近的sgx设计支持高达1tib的epc大小,但是由于其缺乏完整性保护,所以只能提供较弱的安全性保障并未能得到广泛的部署
[28]
。其次,ecalls和ocalls都涉及昂贵的硬件操作(例如,刷新tlb条目),这会导致显著的上下文切换开销(例如,每个调用大约8000个cpu周期
[27]
)。因此,我们在设计dbe的时候必须解决有限的epc大小限制和飞地的上下文切换开销。clients:【计算机】客户端,data channel:数据通道,control channel:控制通道,cloud:云,enclave:飞地,storage pool:存储池。
[0048]
我们通过设计debe,一种基于intel sgx
[13]
的受可信执行保护的数据重删除存储系统,来为实现dbe提供一个案例。
[0049]
图1展示debe的架构。debe不像dupless那样需要维护一个专门的密钥服务器。我们考虑这样一个场景,其中多个客户端将数据存储到云服务器(或者简称为云)。debe执行基于目标的数据重删除以删除多个客户端的重复数据。目前,每个debe客户端都将其所有数据上传到云端进行数据重删除。尽管客户端可以先对其自己的数据在客户端先进行重删除以节省上传带宽而不引入旁道攻击
[23]
,但是我的设计目前不考虑这种假设。
[0050]
为了防止云服务器在进行数据重删除时访问任何一个明文数据块,debe在云服务器上部署了一个飞地,并在飞地内执行数据重删除。最初,每个客户端要与云建立两个安全的通信信道:1)与云服务器的控制信道,用于传输存储的相关操作命令;2)与飞地的数据信道,用于传输由客户端发起的明文数据块。我们使用传统的ssl/tls身份验证方式来防止对控制信道的篡改,而数据信道则是通过diffie-hellman密钥交换来设置的。
[0051]
当将文件上传到云端时,客户端首先将文件数据进行分割,产生大小固定或者可变的明文数据块。然后它通过控制信道向云端发送上传请求,并通过数据信道将所有明文数据块发送到飞地。飞地对接受到的明文数据块进行重删除和压缩,并将剩余的明文数据块加密为密文数据块,最后将密文数据块和文件配表存储到后面存储池。
[0052]
当要下载一个文件时,客户端首先通过控制信道想向云端发送下载请求。之后,飞地检索相应的文件配表和其所对应的密文数据块。最后,飞地对密文数据块进行解密,然后将其解压后通过数据信道返回给客户端。
[0053]
我们考虑一个诚实但是好奇的攻击者,它不修改系统协议,但是希望通过识别存储在云上的密文数据块所对应的原始明文数据块的内容来破坏数据的机密性。攻击者可以进入云服务器并访问存储在未受保护的主内存中的任何数据以及存储在存储池中的密文数据块。它还可以窃听向未受保护的主存储器发出的ocalls的内容(例如,ocalls使用的参数和不受信任的函数调用)。
[0054]
我们的威胁模型有如下假设。
[0055]
1)如果攻击者可以控制被攻击的客户端,则它可以访问该客户端所拥有的所有明文数据块。但是,由于debe执行基于目标的数据重删除,因此攻击者无法访问或者推断出其他未被攻击客户端的明文数据块。
[0056]
2)飞地是值得信赖且可靠的。它的真实性可以在第一次启动引导时通过远程证明进行验证
[13]
。任何针对sgx的拒绝服务攻击或者旁道攻击都可以受到现有解决方案的保护。
[0057]
3)云服务器支持远程审计数据的完整性,并且可以扩展成多云存储以实现数据的容错性。因为我们在实现时不考虑数据的完整性和容错性。
[0058]
debe旨在让多个客户端可以安全地将其存储的数据管理外包给公有云存储服务。它主要针对具有高冗余内容的存储工作负载(例如,定期备份和文件系统快照),可以通过数据重删除和压缩有效地减少存储开销。它旨在实现以下设计目标:1)高性能。debe的密钥管理开销明显低于dae的方法。考虑到飞地有限的epc大小和昂贵的上下文切换开销,debe会在sgx中产生有限的开销。
[0059]
2)较高的存储开销节省。debe应用数据重删除技术来去除跨多个用户重复的数据块。它支持精确的数据重删除,这意味着它可以删除所有重复的数据块。它还在对数据进行重删除之后对非重复的数据块进行压缩,以进一步节省额外的存储空间。
[0060]
3)保密性。debe保留的dae的安全性。尽管debe没有像dupless那样维护用于产生密钥的专属密钥服务器,但是它仍可以抵御离线暴力攻击。
[0061]
4)比dae更强的鲁棒性。debe通过消除使用密钥服务器来缓解dae中存在的单点攻击的问题。它还会减轻由针对dae频率分析而引起的信息泄露的问题。
[0062]
debe的核心是在飞地内部(部署在云服务器内)进行数据的重删除,同时在重删除的过程中保证明文数据块的保密性。为此,我们提出了基于数据块频率的数据重删除方式,以便支持在受到飞地资源限制的情况下实现安全的数据重删除。
[0063]
朴素的方法:为了识别飞地内的所有重复的数据块,一个简单的做法是在飞地内维护一个完整的指纹索引(或简称为完整索引),以便完整追踪所有非重复的数据块指纹。它通过检查飞地中的完整索引来执行数据的重删除,压缩非重复的数据块,并对压缩的数据块进行加密,最后存储。但是,对于大规模的外包存储,全局索引的大小会随着非重复数据块的数量线性增加。将完整索引保留在飞地内会导致飞地的内存使用量超过有限的epc大小,因此会导致显著的epc的换页开销。
[0064]
另一种简单的设计在飞地外管理完整的索引,这样飞地通过ocalls并以数据块的指纹作为输入,进而查询飞地外完整的索引以检查数据块是否已经存储。这种设计节省了epc的使用,但是会触发大量的ocalls以查询完整的索引,因此会导致昂贵的上下文切换。此外,云服务器上的攻击者可以监控飞地提交的ocalls信息并根据数据块的指纹信息推断存储的密文数据块信息(例如,通过频率分析)。
[0065]
我们的方法:我们提出基于频率的数据重删除,它可以支持在资源有限的飞地内实现安全的数据重删除。我们主要的依据是数据块的频率(即数据块重复出现的次数)在实际的备份工作负载中是高度倾斜的,因此很小部分数据块可能会产生大量的重复数据块。为了证明这一观察结果,我们对五个真实的备份数据集进行了分析。我们统计了给定数据
块的重复率(定义为从给定的数据块集合内产生的重复数据块的总大小与整个数据集中重复数据块数量之间的比率)。图2展示了重复率与数据块频率的关系(按频率降序排序)。例如,在vm数据集中,前5%的频繁出现的数据块大约贡献了97%的重复数据。这意味着如果我们维护一个较小的指纹索引来追踪这些前5%频繁出现的数据块,同时我们可以利用重删除去除大约97%的重复数据并实现较高的存储效率。
[0066]
根据我们观察的结果,基于频率的数据重删除的主要思想是将数据重删除的过程进行分解。它在飞地内管理一个较小的指纹索引,从而实现对出现频率较高的数据块进行重删除。除此之外,它还在飞地外维护了一个完整的指纹索引,以删除非频繁出现的数据块的副本。基于频率的数据重删除可以解决性能和安全的问题。从性能的角度,它只在飞地内维护了一个关于频繁出现数据块的较小的指纹索引,以去除大部分的重复数据块。因此,它减轻了epc的使用开销以及上下文切换开销,这是由于它仅需要针对非频繁出现的数据块调用ocalls在飞地外查询完整的索引。从安全的角度,由于高频率出现的数据块更容易受到频率分析的影响,我们仅在飞地内对高频率出现的数据块进行重删除。因此,云中的攻击者无法轻易获知高频率数据的频率,从而缓解由于频率分析造成的信息泄露。
[0067]
飞地架构和设计路线图:图3描述了debe中飞地的架构。初始化的时候,飞地需要在启动引导时配置一组密钥,并与每个客户端建立安全的数据信道。然后飞地记录从客户端数据信道接收到的每个明文数据块的频率。根据数据块的频率,基于频率的数据重删除会去除频繁出现数据块的重复项,并与飞地外的完整索引进行交互以去除非频繁出现数据块的重复项。飞地还会对非重复的明文数据块进行压缩,并对压缩的明文数据块进行加密。最后,飞地将密文数据块存储在存储池中。storage pool:存储池,cloud:云,enclave:飞地,full index:完整索引,frequency-based deduplication:基于频率的数据重删除,frequency tracking:频率跟踪,key management:密钥管理,compression:压缩,encryption:加密。
[0068]
密钥管理,飞地维护了一组密钥,用于数据重删除和压缩后数据块的安全存储以及与客户端的安全通信。
[0069]
数据密钥和查询密钥:飞地维护两个长期密钥,它们在飞地的整个生命周期内保持有效:1)用于加密和解密安全存储中压缩的非重复明文数据块的数据密钥,2)用于在查询飞地外的完整索引时保护明文数据块信息的查询密钥。在通过远程证明对飞地进行身份验证和启动引导之后,它会通过sgx的提供机密的机制初始化数据密钥和查询密钥。值得注意的是,仅使用两个密钥对数据块进行保护可显著降低dae的中基于每个数据块的密钥管理开销。
[0070]
会话密钥:每个客户端都维护了一个与飞地的数据信道以进行安全数据通信。每个数据信道使用一个短期的会话密钥保护其数据信道,该密钥对单个通信会话保持有效。它通过与云服务器的控制信道使用diffie-hellman密钥交换协议为数据信道建立会话密钥。会话密钥在客户端通信会话期保存在飞地中,会话完成后将被释放(控制信道和数据信道将会被一起释放)。
[0071]
对于每个客户端的主密钥:飞地还会要求每个客户端通过数据信道为每个存储请求提交一个主密钥。它使用主密钥来保护客户文件的文件配表,并确保客户端对文件所有权得到保障。与会话密钥类似,飞地只为每个通信会话保留客户端的主密钥,并且会在会话
结束时销毁主密钥,因此主密钥的存储开销也是有限的。
[0072]
频率追踪,飞地需要追踪明文数据块的频率,以识别高频率出现和非高频率出现的数据块,进而实现基于频率的数据重删除。为了减少epc的使用,飞地使用cm-sketch来跟踪每个数据块的近似频率,并且只使用固定大小的内存空间和较小错误率。图4显示了飞地如何在cm-sketch中实现频率追踪。cm-sketch是一个二维数组,其中有r行,每行有w个计数值。这里的一个关键的设计是如何以较小的计算开销将明文数据块映射到计数值。为此,我们在计算数据块指纹时使用加密哈希(例如,sha-256),这样我们可以将数据块指纹视为随机输入值,并将其直接映射到计数器。具体来说,对于每个明文数据块m,飞地将m的指纹划分为r个切片。它需要将第i个切片以w为模映射到第i行中的一个计数值,并将每个计数值递增1。这与传统的cm-sketch形成对比,后者使用独立的哈希函数将输入映射到不同行的计数器,因此会产生较高的计算开销。为了估计数据块的频率,飞地使用所映射的r个计数值中的最小值作为其估算的频率。默认情况下,我们将r设置为4,w设置为256k,每个计数值为4字节,因此cm-sketch整体占epc的使用量为4mib。
[0073]
基于频率的数据重删除,这里我们主要介绍基于频率的数据重删除设计,它根据数据块的频率将重删除分为两个阶段,并去除所有重复的明文数据块。
[0074]
第一阶段重删除:飞地维护了一个较小的指纹索引,称为top-k索引,以便对最频繁出现的k个数据块进行重删除。我们将一个小顶堆和一个哈希表组合以实现top-k索引,如图5所示。小顶堆区分了前k个频繁出现的数据块以及非频繁出现的数据块,使得小顶堆的根结点为当前k个频繁出现的数据块中频率最小的明文数据块。小顶堆中每个结点都存储了一个指向哈希表中某条记录的指针。另一方面,就像在传统数据重删除中一样,我们利用哈希表对重复出现的数据块进行检测。每一条哈希表中的记录存储了从数据块指纹到一组元素的映射:1)指向小顶堆中某个结点的指针(即小顶堆中的结点和哈希表中的记录相互映射),2)数据块的估计频率,3)数据块的地址(包括存储容器的id和容器内部的偏移量)以及4)压缩后数据块的大小。
[0075]
对于一个给定的明文数据块,为了执行第一阶段的重删除,飞地首先将明文数据块的指纹作为输入,从cm-sketch中获得明文数据块当前的估计频率。它首先检查小顶堆的根结点,如果当前的估计频率小于根结点的频率(即该数据块时非频繁出现的数据块),则飞地跳过进一步查询哈希表的过程,并直接进行第二阶段重删除;否则(即该数据块是频繁出现的数据块),飞地则使用它的指纹进一步查询哈希表。对于这种场景,我们有如下两种情况:1)如果在哈希表中找到了该指纹(即该数据块是重复的数据块),则飞地更新哈希表中其所对应的频率,并将该数据块的地址和压缩后的数据块大小添加到文件配表中。由于该数据块的频率被更新了,飞地还会根据小顶堆中指向哈希表中记录的指针来调整小顶堆。
[0076]
2)如果在哈希表中没有找到该指纹(即该数据块是一个新的频繁出现的数据块),则飞地在哈希表中创建一个新的记录,并将包含指向该哈希表新记录的指针的新节点插入到该小顶堆中。如果小顶堆中已经存储了k个节点,则飞地删除当前小顶堆中的根节点,并通过存储在该节点中指向哈希表中记录的指针删除哈希表中所对应的记录。由于该数据块可能之前已经被存储过了,所以飞地会对该数据块进行第二阶段重删除,并根据第二阶段
重删除的结果去更新数据块的地址和压缩后数据块的大小。
[0077]
我们可以表明top-k索引的空间使用开销比较小。假设一个数据块指纹是32字节(一个sha-256的哈希值),数据块的地址为12字节(一个8字节存储容器id和一个4字节的容器内部偏移量),压缩后数据块的大小占4字节。对于每个k个最频繁出现的数据块,每一个哈希表中的记录还需要额外存储一个4字节的频率和一个指向小顶堆中某节点的指针。由于我们用数组实现小顶堆,因此指向小顶堆中某节点的指针可以表示为4字节的整数。此外,小顶堆中每个节点还保留了一个指向哈希表中记录的8字节指针。总体而言,对于k个最频繁出现的数据块,top-k索引会对每个数据块分配64个字节(不包括哈希表内部实现的指针,这里我们使用c++标准库的哈希表作为实现)。例如,如果我们追踪512k个最频繁出现的数据块,top-k索引的epc内存使用量为32mib。
[0078]
我们进一步表明top-k索引的操作具有较低的时间复杂度。对于每个明文数据块,top-k索引可以在恒定的时间内返回当前小顶堆中数据块的最小频率(从根节点开始)。对于最频繁出现的数据块,top-k索引需要进一步检查哈希表(在恒定的时间内)并更新小顶堆。由于我们在哈希表每条记录中存储了指向对应小顶堆内节点的指针,因此我们可以直接在所对应的节点位置开始更新小顶堆,进而无需搜素整个小顶堆。因此,更新小顶堆的时间复杂度为o(logk)。
[0079]
第二阶段重删除:对于第一阶段没有被去除的重复数据块,debe会进行第二阶段重删除,这其中包括非频繁出现的数据块和新出现的频繁数据块。由于epc大小是有限的,debe在飞地外管理了一个完整索引。我们用一个哈希表实现完整索引,其中每条记录存储了从加密的明文数据块指纹到加密的数据块信息的映射(即数据块地址和其压缩后的大小都被查询密钥加密)。我们加密明文数据块指纹和数据块信息的主要原因是飞地外完整的索引不再受到飞地的保护,因此我们加密数据块的指纹和信息以防止云服务中的攻击者通过这些信息推断明文数据块的内容。
[0080]
给定一个明文数据块,为了执行第二阶段重删除,飞地使用查询密钥加密明文数据块的指纹(第一阶段没有去除的重复数据块),然后它根据加密后的明文数据块指纹通过ocall查询飞地外的完整索引。如果在完整索引中找到了加密指纹,则ocall返回加密后的数据块信息,该信息将在飞地内使用查询密钥进行解密,最后飞地将该数据块的地址和压缩后的大小更新到文件配表中;否则,如果加密指纹是完整索引的新指纹,则飞地将该数据块视为非重复的数据块,并为该数据块分配地址,压缩该数据块并记录其压缩后的大小。之后,飞地用查询密钥对数据块的地址和其压缩后的大小进行加密,并将它们的信息更新到完整索引中。因为我们预期在第一阶段重删除时已经删除了大部分重复项,所以这里由于ocalls引起的上下文切换开销是有限的。
[0081]
存储管理,容器存储:debe将数据块组织成固定大小的容器以降低i/o成本。具体来说,飞地对重删除后的非重复明文数据块进行压缩,并将压缩后的非重复明文数据块加密为密文数据块。之后,它将密文数据块写入到飞地内的容器缓冲区内,当缓冲区已满时,飞地将该缓冲区内容设置为不可变的并将其释放给云服务器进行持久化存储。此外,飞地为每个新上传的文件创建文件配表,文件配表中的每个条目都记录了数据块的地址以及该数据块压缩后的大小。当飞地更新文件配表时,它不需要对重复的数据块再一次执行压缩以获得其压缩后的大小,因为压缩后的数据块大小以及存储在了top-k索引和完整索引中。
为了保证文件的所有权,飞地使用客户端的主密钥对文件配表进行加密。由于飞地将容器(包含多个密文数据块)视为基本的i/o单元,并且数据块的大小存储在文件配表中(受到每个用户主密钥的保护),debe保证了压缩的安全性并且避免了将压缩后数据块的长度泄露给云服务器。
[0082]
另一种设计的可能时将容器视为基本的压缩单位(而不是数据块级的压缩)。具体来说,飞地首先将非重复的明文数据块写入到存储容器中,并对整个存储容器进行压缩,用数据密钥对压缩后容器进行加密。然而,这种设计会产生额外的数据恢复开销,因为飞地需要解压和解密这个容器,即使它只需要恢复该容器中的单个数据块。我们将如何有效设计容器级的压缩作为我们未来的工作。
[0083]
下载:为了下载文件,客户端首先通过安全数据信道将请求的文件名以及主密钥发送给飞地。飞地使用给定的文件名检索相应的文件配表,并使用客户端提供的主密钥进行解密。然后它解析解密后的文件配表从而获得数据块的地址以及压缩后数据块的大小。为了恢复所有的数据块,飞地将所需要的数据块的存储容器id暴露给云服务器并通过ocalls执行相应的i/o操作。一旦云服务器将容器提取到主内存中,飞地就可以根据其内部的偏移量访问密文数据块,并通过数据密钥解密密文数据块。最后,它将解压后的明文数据块通过数据信道发送给客户端。
[0084]
在恢复数据的过程中,飞地仅将存储容器的id暴露给了云服务器,而不是密文数据块的具体地址。因此,它可以防止云服务器中的攻击者通过统计密文数据块的访问次数来发起频率攻击。
[0085]
安全性讨论,我们讨论debe的安全性以呼应我们所考虑的威胁模型。我们主要考虑两种情况。
[0086]
情况一:快照攻击者一次性访问未受保护的内存和存储池中的数据内容。debe对客户端产生的明文数据块采取端到端的加密,并未存储在云服务器中的密文数据块提供了语义安全性。具体来说,它建立了一个安全的数据信道,通过会话密钥对客户端和飞地之间交换的所有明文数据块进行了加密。它在飞地内执行数据重删除(无法被云服务器察觉),并在存储密文数据块之前通过数据密钥将非重复的明文数据块加密为密文数据块。总的来说,debe在传输数据和存储数据的过程中均采用传统的对称加密,并实现了语义安全。
[0087]
情况二:持久的攻击者在数据重删除的过程中监听ocalls。debe通过在飞地内利用查询密钥对明文数据块指纹和数据块的信息进行加密,然后将它们作为ocalls的输入以查询飞地外的完整索引。因此,即使攻击者可以窃听ocall,它也无法从ocall推断出原始的输入。
[0088]
另一方面,一个潜在的信息泄露是持久的攻击者(在云服务器中驻留较长时间)可以在重删除的过程中了解到数据块的频率信息,因为在查询完整索引的过程中,飞地会将重复的数据块的指纹加密成相同的加密指纹。具体来说,攻击者可以通过监听ocalls来追踪加密指纹的频率分布,并启动频率分析来推断原始的明文数据块。然而,debe将此类信息泄露限制在了非频繁出现的数据块上。我们的评估表明,与最先进的方法ted(利用存储效率换取数据的安全性)相比,debe可以更有效地减少信息泄露。
[0089]
实现,我们在基于intel sgx sdk linux 2.7的linux上用c++实现了debe的原型。它使用openssl 1.1.1
[39]
和intel sgx ssl
[40]
实现加密相关的操作。我们当前的原型包含
17.5k行代码。
[0090]
每个客户端实现fastcdc[38]以实现变长分块,其中最小,平均和最大的数据块大小分别设置为4kib、8kib和16kib。存储容器的大小为4mib。我们实现了基于nist p-256椭圆曲线的diffie-hellman密钥交换协议,用于客户端和飞地之间的数据信道的会话密钥的管理。飞地通过sha-256计算明文数据块的指纹,并通过aes-256加密明文数据块和数据块指纹(当查询完整索引时)。sha-256和aes-256都使用intel新指令集进行硬件加速。我们还实现了lz4,用于在对数据块进行重删除之后进一步进行无损压缩。
[0091]
为了减轻上下文切换开销,debe以批处理的方式处理数据块(默认情况下将128个数据块作为一批)。此外,为了提升下载的性能,云服务器在内存中维护了一个lru缓存(默认大小为256mib)来保存最近访问的存储容器。对于飞地发出的每个存储容器的访问请求,云服务器会先检查缓存并且仅在存储容器不在缓存中的时候才从本地存储中读取存储容器。
[0092]
实验,我们将debe部署到由10gbe连接的多台机器组成的本地集群上。每台机器都有一个四核3.4ghz intel core i5-7500 cpu和32gib ram,并安装了ubuntu16.04。我们在不同的机器上部署一个或者多个客户端、一个密钥服务器(仅适用于dae)以及一个云存储服务器。云存储服务器配置了一个东芝dt01aca 1tib 7200转sata硬盘。默认情况下,debe将飞地中的top-k索引的k设置为512k。
[0093]
我们使用合成数据集和真实数据集来评估debe。我们总结了我们的评估结果如下。
[0094]
1)对比当前最先进的dae方法,debe将上传非重复数据和重复数据的速度分别提升了9.83倍和13.44倍(实验一)。其中基于频率的数据重删除只占总上传时间的5.9-12.0%(实验二)。debe在多客户端同时进行上传和下载(实验三)和各种合成的工作负载(实验四)的场景下依旧保持较高的性能。
[0095]
2)对于真实的工作负载,debe比最先进的重删除替代方案将速度提升了1.16-2.51倍(实验五),并在长期上传和下载的场景下(实验六)保持较高的性能。它还实现了较高的存储效率(实验七)并实现了低于频率分析的安全性(实验八)。
[0096]
数据集,合成数据集:我们考虑使用两个合成数据集进行评估。第一个数据集,即syn-unique,包括非重复和可压缩的数据块。具体来说,我们通过lz数据生成器为syn-unique生成一组2gib的可压缩文件,该生成器基于sdgen的算法合成可压缩数据。lz数据生成器采用两个参数作为输入:1)可压缩率,指定生成数据的可压缩性,以及2)用于生成数据的随机种子。我们将压缩比率设置为2以模拟真实世界中的备份工作负载,并改变随机种子以生成不同的合成文件。我们对每个合成文件执行切块,以确保其产生的数据块在所有文件中是全局唯一的。我们使用该数据集对处理非重复数据的场景下进行压力测试(实验一,实验二和实验三)。
[0097]
第二个数据集,即syn-freq,包括遵循某种目标频率分布的数据块集合。为此,我们构建了一个合成文件生成器。具体来说,我们生成的文件中的数据块会遵循zipf分布。我们的生成器将三个参数作为输入:1)原始数据块的数量,2)重删除率(即原始数据大小与非重复数据大小之间的比率),以及3)zipfian常数(更大的常数意味着频率分布更倾斜)。为了生成合成文件,我们的生成器根据非重复数据块的预期数量(即原始数据块的数量除以
重删除率)准备一组非重复的指纹。它根据均值为2且方差为0.25的正态分布为每个指纹分配压缩率。为了生成每个原始数据块,我们的生成器根据目标zipf分布从之前的指纹集中抽取一个指纹,并使用lz数据生成器以压缩比和指纹(作为随机种子)作为输入构建其内容。最后,我们为syn-freq生成一组合成文件,其中每个文件包含13107200个8kib原始数据块(即总共100gib)以及重删除率为5。这里非重复数据块的数量以及足够大,以至于top-k索引只能追踪一部分非重复的数据块。我们改变zipfian常数来研究频率分布的倾向程度对性能的影响(实验四)。
[0098]
真实数据集:我们考虑五个真实世界里面的备份工作负载来评估debe性能(实验五和实验六)、存储效率(实验七)和安全性(实验八):1)docker:来自docker hub的couchbase的docker镜像(从v4.1.0到v7.0.0);2)linux:linux源代码的快照(来自v2.6.131和v5.9之间的稳定版本);3)fsl:系统主目录文件快照,其中我们从2013年的九个用户中选取了42个主目录文件快照;4)ms:windows文件系统快照,其中我们选择了30个大小约为100gib的快照;5)vm:虚拟机快照。
[0099]
表一显示了五个真实世界数据集的统计数据。由于fsl、ms和vm仅包含数据块的指纹,因此我们会像syn-freq一样利用数据块指纹生成可压缩的数据块。
[0100]
表一:真实数据集的统计信息在合成数据集上的评估,为了在没有磁盘i/o开销影响的情况下检查可实现的最大性能,我们在每次测试之前将合成的文件加载到每个客户端的内存中,并让云服务器将所有的重删除后的数据存储在内存中。我们报告了五次运行结果的平均值,并包括了基于学生t分布的95%置信区间(折线图除外)。
[0101]
实验一(整体性能):我们评估整个系统上传(下载)的性能。我们考虑单个客户端连续两次上传相同的2gib文件,以分别研究上传非重复数据和重复数据的最大可实现性能。之后,我们让客户端会下载相同的文件。我们测试每个操作的上传(下载)速度。
[0102]
我们将debe与三种dae的方法进行了比较:1)dupless,它实现了基于oprf的服务器辅助密钥管理;2)ted,它基于密钥服务器使用轻量级的哈希计算生成每个数据块的密钥以及3)ce,收敛加密方案。为了研究debe的安全开销,我们还引入了针对明文数据块的重删除(plain),客户端将明文数据块上传到云服务器进行数据重删除和压缩,无需任何安全的保护。与debe和plain不同,dae的方案(即dupless、ted和ce)与压缩算法不兼容。为了公平比较,我们自己在c++中实现了所有的对比方案。
[0103]
图6显示了上传速度。debe的表现优于所有dae的方法。在上传非重复数据时,debe通过避免生成基于每个数据块内容的密钥,分别比dupless、ted和ce实现了9.83倍、1.28倍和1.22倍的速度上的提升。即使debe应用了压缩,它的压缩开销也被避免像dae的密钥生成
开销的性能提升所掩盖。上传重复数据时,debe变得更加高效,性能比dupless、ted和ce分别提高了13.44倍、1.71倍和1.65倍,主要是因为它避免了对重复数据块进行加密和压缩。与plain相比,debe在上传非重复数据和重复数据时分别只产生了13.6%和7.8%的性能开销。
[0104]
图6显示了下载速度。所有的dae的方法遵循了相同的下载模式,即客户端从云服务器中检索密文数据块和其所对应的密钥,然后解密相应的密文数据块,并重建原始文件。与dae的方法相比,由于ocalls将数据块读取到飞地中进行解密和解压,debe导致下载速度下降12.3%。此外,与plain相比,debe和dae的下载速度分别下降了38.1%和17.4%,因为它们需要对数据块进行解密。
[0105]
实验二(上传操作分解):我们对上传操作进行了分解。我们考虑和实验一相同的场景(即客户端连续两次从syn-unique上传相同的2gib文件)并在上传的不同步骤中测量客户端和飞地的计算时间:1)分块,客户端将输入文件进行分块产生明文数据块;2)安全传输,飞地与客户端交换会话密钥并且用会话密钥解密收到的密文;3)指纹计算,飞地计算每个明文数据块的指纹;4)频率追踪,飞地利用cm-sketch估计每个明文数据块的频率;5)第一阶段重删除,飞地通过top-k索引删除重复的明文数据块;6)第二阶段重删除,飞地通过ocalls查询飞地外的完整索引以删除剩余的重复数据块;7)压缩,飞地压缩非重复的明文数据块;8)加密,飞地使用数据密钥加密压缩后的明文数据块。
[0106]
表二显示了结果(通过测算每1mib上传的处理时间)。在第一次上传的时候(即上传非重复数据块),指纹计算和压缩是最耗时的步骤,因为它们对所有的数据块进行了复杂的计算。另一方面,基于频率的数据重删除(包括频率追踪、第一阶段重删除以及第二阶段冲删除)只需要占总时间的12.0%。由于在第一次上传之前云服务器并没有存储数据,因此每个数据块都被视为非重复的数据块并经过了第一阶段重删除和第二阶段重删除处理。在第二次上传的时候(即上传重复数据块),所有的重复数据块都在第一阶段重删除的时候被去除,因此不需要进行第二阶段重删除。在这种情况下,基于频率的数据重删除只需要占整个上传时间的5.9%。
[0107]
表二:上传操作计算时间的分解(每1mib上传的处理时间)实验三(多用户上传和下载):我们还评估了当多个客户端同时发出上传/下载请求时的性能。除了云服务器,我们还部署了10台机器,每台机器运行两个客户端实例以模拟多达20个客户端并发上传/下载的场景。每个客户端从syn-unique中上传一个2gib文件到云服务器,然后下载相同的2gib文件。我们将总上传(下载)速度衡量为总上传(下载)数据大小与所有客户端完成上传(下载)的总时间的比率。
[0108]
图7显示性能与客户端数量的关系。其中,总上传速度首先随着客户端数量的增加
而增加,当有10个客户端的时候,总上传速度达到了812.0mib/s。然后由于飞地中的资源竞争,当有20个客户端的时候,总上传速度下降到了752.8mib/s。总的下载速度也有类似的趋势,它先增加到733.0mib/s,最后下降到679.7mib/s。
[0109]
实验四(数据块频率分布的影响):我们评估debe在处理不同数据块频率分布的工作负载时的性能。我们配置了一个客户端来上传每个syn-freq中的数据块(不涉及分块的操作),并测量了飞地的计算速度(即包括表*中除分块外的步骤)。
[0110]
图8显示了top-k索引中不同k和zipfian常数的场景下的结果。较大的k意味着在所有zipifian常数的场景下性能较低,这是因为当飞地的内存开销超过64mib的时候,sgx会产生显著的换页开销。例如,当zipfian常数为1.05时,k=512k和k=1m的计算速度分别为317.5mib/s和158.6mib/s。此外,飞地的计算速度在数据块频率分布更倾斜的情况下(即更大的zipfian常数)而增加,这是因为最频繁的数据块贡献了更多的重复数据,从而减轻了查询完整索引的ocall开销。
[0111]
在真实数据集上的评估,实验五(不同重删除方法的性能):debe设计的关键时基于频率的数据重删除,我们将其与其他的设计方案进行了比较。我们主要考虑两种流行的内存高效的数据重删除方法,即基于相似性的数据重删除和基于局部性的数据重删除。两种方法都基于包含多个数据块的片段来产生一个特征,同时在飞地内维护了一个较小的特征索引。之后,它通过根据特征的相匹配情况将飞地外完整索引的一部分加载到飞地中来执行重删除。基于相似性的数据重删除根据每个片段中数据块指纹的最小值作为特征,而基于局部性的数据重删除则通过采样片段中数据块的指纹来生作为特征。我们参考之前的工作,我们选择片段的大小为10mib,对于基于局部性的数据重删除,其采样率为1/64。虽然这两种数据重删除的方法都旨在减轻普通数据删除方法中磁盘的i/o开销,但是我们的想法是它们也可以用于减少epc内存使用开销,然后它们只能支持近似精确的数据重删除。
[0112]
除了上述近似精确的数据重删除之外,我们还包括了简单的精确重删除作为基线进行比较。具体来说,in-enclave尝试在飞地内管理完整索引;当完整索引的大小增大并且无法放入到epc时,它会触发页面交换将未使用的epc页面逐出到普通内存中去。out-enclave在内存中管理完整内存,并通过ocalls查询完整索引检查重复数据块。为了公平比较,所有基线方法都会压缩非重复的数据块。我们按照创建时间的顺序上传每个真实备份数据集中的快照(见6.1)。我们像在实验四一样测量飞地的计算速度。
[0113]
图9显示了实验结果。debe通常优于其他所有方法。例如,在fsl中,debe相比于基于相似性、基于局部性、out-enclave和in-enclave分别实现了1.16倍、1.22倍、1.27倍和2.51倍的速度提升。这里的原因是基于相似性和基于局部性的方法是近似精确的数据重删除,它对一些重复的数据块进行了额外的压缩和加密,从而产生了额外的计算开销。此外,debe执行了第一阶段重删除并过滤掉了许多需要通过ocall查询飞地外完整索引的开销。尽管在工作负荷较小时(例如,docker和linux中前几个快照)in-enclave优于debe,但是由于其昂贵的换页开销,其性能在后续的快照中急剧下降。debe在飞地中维护一个轻量级的数据结构(cm-sketch和top-k索引)从而减轻换页开销。
[0114]
实验六(真实数据上传和下载):与实验一不同,我们根据真实数据集评估debe的上传和下载性能。其中,我们包含了云服务器的磁盘i/o并依次上传每个数据集中所有的快照,最后再下载它们。由于fsl、vm和ms只包含了可压缩的数据块,我们让客户端之间上传数
据块而不进行分块操作。
[0115]
图10显示了每个快照的上传和下载速度。上传速度逐渐提高,这是因为后续的快照包含了更多的重复数据块,debe避免对这些数据块进行压缩和加密。例如,在fsl中的debe上传第一个快照的速度为225.6mib/s,最后一个快照的速度为263.4mib/s。由于数据块的碎片化(即后续快照的数据块在重删除之后变得更加分散)增加了i/o开销,快照的下载速度会降低。例如fsl中第一个快照的下载速度为131.4mib/s,最后一个快照的下载速度下降到95.1mib/s。我们可以通过现有方法来减轻数据块的碎片化。我们将此问题作为未来工作。
[0116]
实验七(存储效率):我们将debe与实验五中近似精确的重删除的方法(即基于相似性的数据重删除和基于局部性的数据重删除)进行对比,以评估debe的存储效率。对于每种方法,我们考虑1)仅执行数据重删除而不压缩(d);2)执行数据重删除和压缩(dc),它执行数据重删除,然后对每个非重复的数据块进行压缩。我们将数据减缩率衡量为原始数据的大小与数据重删除(压缩)后的数据大小的比率。这里我们不考虑元数据的大小,因为它远小于原始文件数据的大小。
[0117]
图11比较了不同情况下存储每个快照之后的数据减缩率。正如预期的那样,debe优于近似精确的数据重删除。在fsl中,在存储完最后一个快照后,未压缩的debe实现了8.24倍的压缩(分别比基于相似度和基于局部性的数据重删除的方法高38.0%和10.1%)。除了数据重删除指纹,压缩还带来了额外的存储节省,特别时对于包含许多字节级代码冗余的linux。存储完所有的linux快照后,debe压缩后的数据减缩率为6.32倍,比未压缩的情况高145.9%。
[0118]
实验八(针对频率分析的安全性):我们研究了debe对频率分析的安全性。我们将不同debe的实例(即k=128k、256k和512k)与实验一中的dae方法ce和ted进行对比。ted以存储效率换取安全性,我们将其参数配置为允许牺牲15%的存储效率(即多存储15%的数据以增强安全性)。与ted一样我们使用kullback-leibler距离(kld),称为密文数据块的频率分布到均为分布的相对熵,来量化信息泄露;较小的kld意味着较少的信息泄露。debe在查询飞地外的完整索引时会导致信息泄露,我们根据ocalls中的加密指纹来计算其频率分布。
[0119]
图12显示了每个数据集中聚合所有快照的kld。所有debe的实例都实现了比ce和ted更小的kld,因为它在飞地中执行第一阶段重删除时完全保护了高频率的数据块。例如,在fsl中,当k为128k时,debe的kld为0.69(分别比ce和ted低72.6%和35.5%)。当我们将k增加到512k时,debe的kld进一步下降到0.62,因为在飞地中删除了更多高频率的数据块。此外,docker和linux中的kld比vm中的小。这里的原因是两个数据集中明文数据块的频率分布本质上是相对均匀的。尽管如此,debe在docker和linux中分别将ted的kld分别降低了42.6%和86.8%。
[0120]
dae方法:多种方法通过dae实现安全的数据重删除。除了2.1中描述的那些方法之外,一些方法是从安全角度设计的。随机mle[36]和imle[37]应用非确定性加密来预防频率泄露,但是它们使用了开销较大的加密原语(例如,非交互的零知识证明[36]、完全同态加密[37])。liu等人[35]建议通过分布式的密钥共享协议而产生密钥,而不依赖与专门的密钥服务器,但是它引入了不同客户端之间交互的性能开销。ted[10]通过设定牺牲的存储效率来缓解频率泄露的问题。相比之下,debe实现dbe以同时解决密钥管理开销和安全问题。
[0121]
sgx与安全数据重删除相结合:sgx已经被用于安全数据重删除。dang等人
[34]
使用sgx作为可信的代理,以节省安全数据重删除时的带宽。speed
[33]
对飞地内的重复计算任务进行重删除,以提高资源的利用率。you等人
[32]
利用sgx验证数据重删除时的所有权,以实现安全的数据重删除。segshare
[31]
在服务器端部署飞地,用于基于文件的安全数据重删除,但是它没有考虑基于数据块的数据重删除,同时没有解决指纹索引的问题。s2dedup
[30]
使用服务器端的飞地来消除用于产生密钥的可信密钥服务器,并通过在飞地内对数据块重新加密实现在飞地外对数据安全的重删除。相比之下,debe直接在飞地内执行数据重删除以保护明文数据块。sgxdedup
[29]
利用sgx来提高dae下客户端重删除的性能。上述基于sgx的数据重删除方法仍然是基于dae的。
[0122]
debe实现了一种尚未探索的设计范式,即先重删除后加密(dbe),用于实现安全的数据重删除存储系统。它利用intel sgx的特性,并应用基于频率的数据重删除在飞地中维护一个针对高频率出现的数据块的指纹索引。我们表明debe在系统性能、存储效率和安全性方面优于传统的基于先加密后重删除(dae)的方法。
[0123]
[1]data age 2025. https://www.seagate.com/ourstory/data-age-2025/.[2]data privacy will be the most important issue in the next decade. https://www.forbes.com/sites/marymeehan/2019/11/26/data-privacy-willbe-the-most-important-issue-in-the-nextdecade/.[3]a. adya, w. j. bolosky, m. castro, g. cermak, r. chaiken, j. r. douceur, j. howell, j. r. lorch, m. theimer, and r. p. wattenhofer. farsite: federated, available, and reliable storage for an incompletely trusted environment. in proc. of usenix osdi, 2002.[4]m. bellare, s. keelveedhi, and t. ristenpart. message-locked encryption and secure deduplication. in proc. of eurocrypto, 2013.[5]l. p. cox, c. d. murray, and b. d. noble. pastiche: making backup cheap and easy. in proc. of usenix osdi, 2002.[6]j. r. douceur, a. adya, w. j. bolosky, p. simon, and m. theimer. reclaiming space from duplicate files in a serverless distributed file system. in proc. of ieee icdcs, 2002.[7]p. shah and w. so. lamassu: storage-efficient host-side encryption. in proc. of usenix atc, 2015.[8]j. li, p. p. lee, y. ren, and x. zhang. metadedup: deduplicating metadata in encrypted deduplication via indirection. in proc. of ieee msst, 2019.[9]j. li, p. p. lee, c. tan, c. qin, and x. zhang. information leakage in encrypted deduplication via frequency analysis: attacks and defenses. acm trans. on storage, 16(1):1
–
30, 2020.[10]j. li, z. yang, y. ren, p. p. lee, and x. zhang. balancing storage efficiency and data confidentiality with tunable encrypted deduplication. in proc. of acm eurosys, 2020.
[11]i. anati, s. gueron, s. johnson, and v. scarlata. innovative technology for cpu based attestation and sealing. in proc. of acm hasp, 2013.[12]m. hoekstra, r. lal, p. pappachan, v. phegade, and j. del cuvillo. using innovative instructions to create trustworthy software solutions. in proc. of acm hasp, 2013.[13]intel(r) software guard extensions. https: //software.intel.com/content/www/us/en/ develop/documentation/sgx-developer-guide/top.html.[14]d. harnik, e. tsfadia, d. chen, and r. kat. securing the storage data path with sgx enclaves. https://arxiv.org/abs/1806.10883, 2018.[15]m. bellare, s. keelveedhi, and t. ristenpart. dupless: server-aided encryption for deduplicated storage. in proc. of usenix security, 2013.[16]a. duggal, f. jenkins, p. shilane, r. chinthekindi, r. shah, and m. kamat. data domain cloud tier: backup here, backup there, deduplicated everywhere! in proc. of usenix atc, 2019.[17]a. el-shimi, r. kalach, a. kumar, a. ottean, j. li, and s. sengupta. primary data deduplication-large scale study and system design. in proc. of usenix atc, 2012.[18]d. t. meyer and w. j. bolosky. a study of practical deduplication. in proc. of usenix fast, 2012.[19]k. srinivasan, t. bisson, g. r. goodson, and k. voruganti. idedup: latency-aware, inline data deduplication for primary storage. in proc. of usenix fast, 2012.[20] m. naor and o. reingold. number-theoretic constructions of efficient pseudo-random functions. journal of the acm, 51(2):231
–
262, 2004.[21]g. wallace, f. douglis, h. qian, p. shilane, s. smaldone, m. chamness, and w. hsu. characteristics of backup workloads in production systems. in proc. of usenix fast, 2012.[22]d. chen, m. factor, d. harnik, r. kat, and e. tsfadia. length preserving compression: marrying encryption with compression. in proc. of acm systor, 2021.[23]d. harnik, b. pinkas, and a. shulman-peleg. side channels in cloud services: deduplication in cloud storage. ieee security & privacy, 8(6):40
–
47, 2010.[24]m. mulazzani, s. schrittwieser, m. leithner, m. huber, and e. weippl. dark clouds on the horizon: using cloud storage as attack vector and online slack space. in proc. of usenix security, 2011.[25]s. pinto and n. santos. demystifying arm trustzone: a comprehensive survey. acm computing surveys, 51(6):1
–
36, 2019.[26]amd secure encrypted virtualization (sev). https: //
developer.amd.com/sev/.[27]s. arnautov, b. trach, f. gregor, t. knauth, a. martin, c. priebe, j. lind, d. muthukumaran, d. o’keeffe, m. l. stillwell, et al. scone: secure linux containers with intel sgx. in proc. of usenix osdi, 2016.[28]e. feng, x. lu, d. du, b. yang, x. jiang, y. xia, b. zang, and h. chen. scalable memory protection in the penglai enclave. in proc. of usenix osdi, 2021.[29]y. ren, j. li, z. yang, p. p. lee, and x. zhang. accelerating encrypted deduplication via sgx. in proc. of usenix atc, 2021.[30]m. miranda, t. esteves, b. portela, and j. paulo. s2dedup: sgx-enabled secure deduplication. in proc. of acm systor, 2021.[31]b. fuhry, l. hirschoff, s. koesnadi, and f. kerschbaum. segshare: secure group file sharing in the cloud using enclaves. in proc. of ieee/ifip dsn, 2020.[32]w. you and b. chen. proofs of ownership on encrypted cloud data via intel sgx. in proc. of acns, 2020.[33]h. cui, h. duan, z. qin, c. wang, and y. zhou. speed: accelerating enclave applications via secure deduplication. in proc. of ieee icdcs, 2019[34]h. dang and e.-c. chang. privacy-preserving data deduplication on trusted processors. in proc. of ieee cloud, 2017.[35]j. liu, n. asokan, and b. pinkas. secure deduplication of encrypted data without additional independent servers. in proc. of acm ccs, 2015.[36]m. abadi, d. boneh, i. mironov, a. raghunathan, and g. segev. message-locked encryption for lock dependent messages. in proc. of crypto, 2013.[37]m. bellare and s. keelveedhi. interactive message-locked encryption and secure deduplication. in proc. of pkc, 2015.[38]w. xia, y. zhou, h. jiang, d. feng, y. hua, y. hu, q. liu, and y. zhang. fastcdc: a fast and efficient content-defined chunking approach for data deduplication. in proc. of usenix atc, 2016.[39]cryptography and ssl/tls toolkit. www.openssl.org/.[40]intel(r) software guard extensions ssl. https:// github.com/intel/intel-sgx-ssl.针对大规模数据管理,云存储需要实现数据机密性和高存储效率。传统方法基于先加密后重删除的设计模式,先对数据进行加密,再对加密后的数据进行重删除操作。我们认为这种基于先加密后重删除的设计模式在性能、存储效率以及安全方面存在一定的缺陷。在本论文中,我们研究了一直未被探究的设计模式,即先重删除后加密。该设计模式先
对数据进行重删除,然后再对不重复的数据进行加密。虽然先重删除后加密的设计模式可以有效解决由于管理重复数据而引起的性能和存储效率的问题,但是重删除的过程不再受到加密的保护。为了解决这个问题,我们设计了debe,一种基于可信执行保护的先重删除后加密安全重删除存储系统,它主要利用intel sgx去保护数据重删除的过程。debe利用基于数据频率的重删除方法,它首先在资源有限的飞地对出现频率高的数据进行重删除,之后在飞地外对剩下的数据进行重删除。实验结果显示debe在性能、存储效率以及安全的方面优于现有的基于先加密后重删除的方法。
[0124]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1